STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech
In our paper, we propose STYLER, a non-autoregressive TTS framework with style factor modeling that achieves rapidity, robustness, expressivity, and controllability at the same time.

Abstract: Previous works on neural text-to-speech (TTS) have been addressed on limited speed in training and inference time, robustness for difficult synthesis conditions, expressiveness, and controllability. Although several approaches resolve some limitations, there has been no attempt to solve all weaknesses at once. In this paper, we propose STYLER, an expressive and controllable TTS framework with high-speed and robust synthesis. Our novel audio-text aligning method called Mel Calibrator and excluding autoregressive decoding enable rapid training and inference and robust synthesis on unseen data. Also, disentangled style factor modeling under supervision enlarges the controllability in synthesizing process leading to expressive TTS. On top of it, a novel noise modeling pipeline using domain adversarial training and Residual Decoding empowers noise-robust style transfer, decomposing the noise without any additional label. Various experiments demonstrate that STYLER is more effective in speed and robustness than expressive TTS with autoregressive decoding and more expressive and controllable than reading style non-autoregressive TTS. Synthesis samples and experiment results are provided via our demo page, and code is available publicly.
Please install the python dependencies given in requirements.txt.
pip3 install -r requirements.txt- Download VCTK dataset and resample audios to a 22050Hz sampling rate.
- We provide a bash script for the resampling. Refer to
data/resample.shfor the detail. - Put audio files and corresponding text (transcript) files in the same directory. Both audio and text files must have the same name, excluding the extension.
- You may need to trim the audio for stable model convergence. Refer to Yeongtae's preprocess_audio.py for helpful preprocessing, including the trimming.
- Modify the
hp.data_dirinhparams.py.
- Download WHAM! dataset and resample audios to a 22050Hz sampling rate.
- Modify the
hp.noise_dirinhparams.py.
- Unzip
hifigan/generator_universal.pth.tar.zipin the same directory.
First, download ResCNN Softmax+Triplet pretrained model of philipperemy's DeepSpeaker for the speaker embedding as described in our paper and locate it in hp.speaker_embedder_dir.
Second, download the Montreal Forced Aligner(MFA) package and the pretrained (LibriSpeech) lexicon file through the following commands. MFA is used to obtain the alignments between the utterances and the phoneme sequences as FastSpeech2.
wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.1.0-beta.2/montreal-forced-aligner_linux.tar.gz
tar -zxvf montreal-forced-aligner_linux.tar.gz
wget http://www.openslr.org/resources/11/librispeech-lexicon.txt -O montreal-forced-aligner/pretrained_models/librispeech-lexicon.txtThen, process all the necessary features. You will get a stat.txt file in your hp.preprocessed_path/. You have to modify the f0 and energy parameters in the hparams.py according to the content of stat.txt.
python3 preprocess.pyFinally, get the noisy data separately from the clean data by mixing each utterance with a randomly selected piece of background noise from WHAM! dataset.
python3 preprocess_noisy.pyNow you have all the prerequisites! Train the model using the following command:
python3 train.pyCreate sentences.py in data/ which has a python list named sentences of texts to be synthesized. Note that sentences can contain more than one text.
# In 'data/sentences.py',
sentences = [
"Nothing is lost, everything is recycled."
]Reference audio preparation has a similar process to training data preparation. There could be two kinds of references: clean and noisy.
First, put clean audios with corresponding texts in a single directory and modify the hp.ref_audio_dir in hparams.py and process all the necessary features. Refer to the Clean Data section of Train Preparation.
python3 preprocess_refs.pyThen, get the noisy references.
python3 preprocess_noisy.py --refsThe following command will synthesize all combinations of texts in data/sentences.py and audios in hp.ref_audio_dir.
python3 synthesize.py --ckpt CHECKPOINT_PATHOr you can specify single reference audio in hp.ref_audio_dir as follows.
python3 synthesize.py --ckpt CHECKPOINT_PATH --ref_name AUDIO_FILENAMEAlso, there are several useful options.
-
--speaker_idwill specify the speaker. The specified speaker's embedding should be inhp.preprocessed_path/spker_embed. The default value isNone, and the speaker embedding is calculated at runtime on each input audio. -
--inspectionwill give you additional outputs that show the effects of each encoder of STYLER. The samples are the same as theStyle Factor Modelingsection on our demo page. -
--contwill generate the samples as theStyle Factor Controlsection on our demo page.python3 synthesize.py --ckpt CHECKPOINT_PATH --cont --r1 AUDIO_FILENAME_1 --r2 AUDIO_FILENAME_1
Note that
--contoption is only working on preprocessed data. In detail, the audios' name should have the same format as VCTK dataset (e.g., p323_229), and the preprocessed data must be existing inhp.preprocessed_path.
The TensorBoard loggers are stored in the log directory. Use
tensorboard --logdir logto serve the TensorBoard on your localhost. Here are some logging views of the model training on VCTK for 560k steps.



-
There were too many noise data where extraction was not possible through
pyworldas in clean data. To resolve this,pysptkwas applied to extract log f0 for the noisy data's fundamental frequency. The--noisy_inputoption will automate this process during synthesizing. -
If MFA-related problems occur during running
preprocess.py, try to manually run MFA by the following command.# Replace $data_dir and $PREPROCESSED_PATH with ./VCTK-Corpus-92/wav48_silence_trimmed and ./preprocessed/VCTK/TextGrid, for example ./montreal-forced-aligner/bin/mfa_align $YOUR_data_dir montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt english $YOUR_PREPROCESSED_PATH -j 8
-
DeepSpeaker on VCTK dataset shows clear identification among speakers. The following figure shows the T-SNE plot of extracted speaker embedding in our experiments.
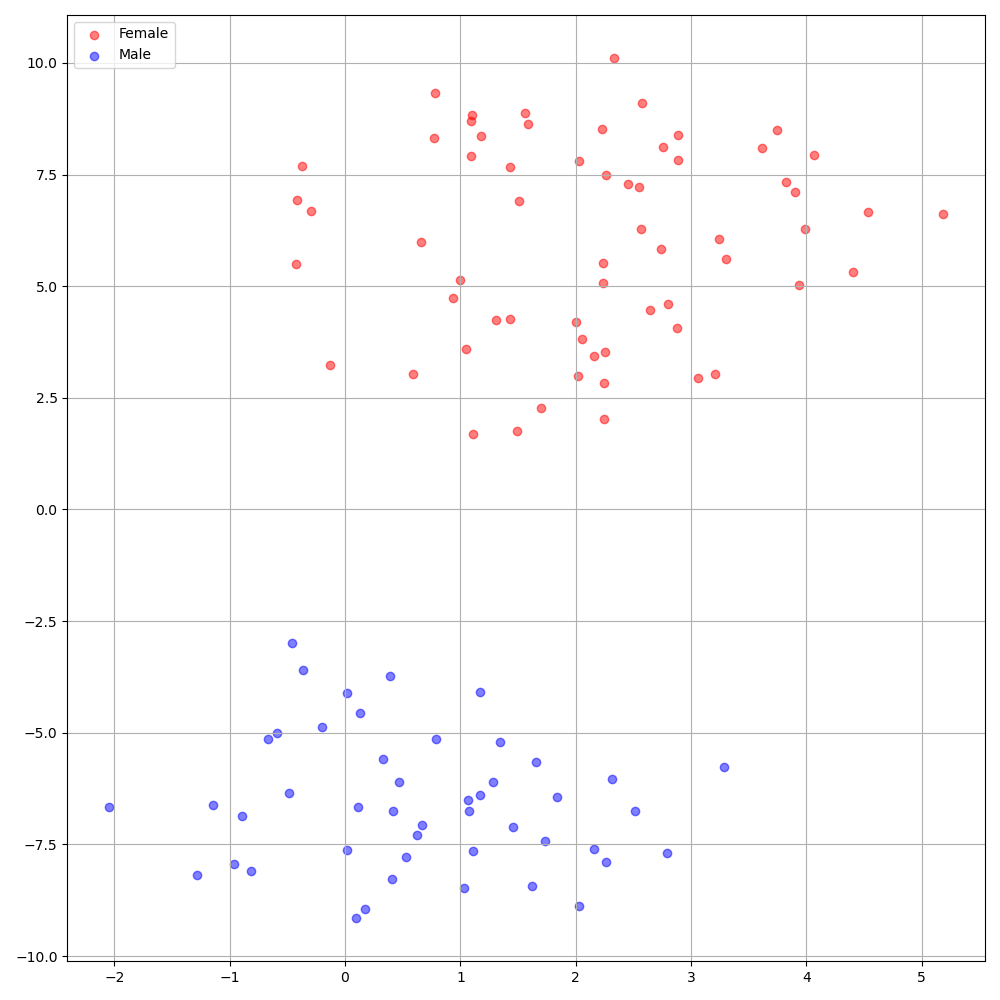
-
Currently,
preprocess.pydivides the dataset into two subsets: train and validation set. If you need other sets, such as a test set, the only thing to do is modifying the text files (train.txtorval.txt) inhp.preprocessed_path/.

If you would like to use or refer to this implementation, please cite our paper with the repo.
@article{lee2021styler,
title={STYLER: Style Modeling with Rapidity and Robustness via SpeechDecomposition for Expressive and Controllable Neural Text to Speech},
author={Lee, Keon and Park, Kyumin and Kim, Daeyoung},
journal={arXiv preprint arXiv:2103.09474},
year={2021}
}