自动阈值提取及分割的算法合集:目前已更新的8种算法
fig=imread('cameraman.tif');
figgray=rgb2gray(fig);
MethodName='Cluster_Kittler';
T=Cluster_treshold(reshape(double(figgray),[],1),'Method',MethodName);
MethodName为自动阈值分割方法包括: 'Cluster_Jawahar1','Cluster_Jawahar2','Cluster_Lloyd','Cluster_Ostu', 'Cluster_Kittler','Cluster_EM','Entropy_Kapur','Entropy_Yen'。
T_K=Cluster_treshold(reshape(double(figgray),[],1),'Method','Cluster_Kittler');
CM=zeros(size(figgray));CM(figgray>T_K)=1;
figure,imshow(CM);title(['Cluster_Kittler分割方法']);
[P_new,label]=Local_Yanowitz(figgray,hsize,MaxInterNum,InterTreshhold,GradTresh);
可调节参数包括:
- hsize 平滑滤波窗口,默认值是[3,3]
- MaxInterNum 迭代的最大次数,默认值1000
- InterTreshhold 迭代停止的阈值10e-6
- GradTresh 前景和背景的阈值,默认值是20
由于光照的影响,图像的灰度可能是不均匀分布的,此时单一阈值的方法分割效果不好。Yanowitz提出了一种局部阈值分割方法。结合边缘和灰度信息找到阈值表面(treshhold surface)。在阈值表面上的就是目标。

- step1:均值平滑图像
- step2:求平滑图像的梯度图
- step3:运用Laplacian算子,找到具有局部最大阈值的点,这些点的原始灰度值就是候选的局部阈值。
- step4 :采样候选点,灰度值替换。将平滑图像中的候选点灰度值替换为原始图像中的灰度值或者更大一点的值。这么做的目的是不会检测到虚假目标,因而会损失一部分真实的目标。
- step5:插值灰度点,得到阈值表面。 $$ lim_{n \to \infty}P_n(x,y)=P_{n-1}(x,y)+\frac{\beta\cdot R_n(x,y)}{4}

R(x,y)=P(x,y+1)+P(x,y-1)+P(x-1,y)+P(x+1,y)-4P(x,y)
$$
其中,只有当$\beta=0$时,残差消失(residual vanish)。$1< \beta <2$时收敛更快。$R(x,y)$为拉普拉斯算子,强迫任意点$R(x,y)=0$的几何意义是使得曲线光滑。光滑曲线的梯度是连续变化的,因而其二次导数为0。
- step6:阈值表面分割图像
- step7:校正。由于光照和噪声,阈值表面和原始原始灰度曲线可能相交如下图所示。可以看到分割结果中出现 “ghost” 目标,应该予以去除。去除的原理是,这些虚假的目标边缘梯度值应该较小。因而,可以根据分割的结果,标记所有连通区域,注意背景和目标应该分开标记。比较标记部分边缘在梯度图中的值,如果某个目标的边缘梯度的平均值不超过某个阈值,则去除这个目标。

[1]S. D. Yanowitz and A. M. Bruckstein, "A new method for image segmentation," Comput. Graph. Image Process. 46, 82–95 ,1989.
分水岭算法对噪声比较敏感,容易出现过分割。常见的处理过分割的方法包括 1). 预处理,图像降噪; 2). 应用标记 (marker)。选择标记需要用户的参与,图像结构的先验知识; 3). 区域融合
本节介绍,基于区域近邻图(Region Adjacency Graph ,RAG)融合的过分割后处理方法。此方法依赖于已分割的区域个数和噪声方差,个数越多效果越差,处理时间越长。最糟的情况是每个像素为1个区域。因而,为了减少分水岭分割的个数,需要对图像先降噪,再分水岭分割,最后区域融合
K个区域的RAG, G=(V,E),其中顶点集$V={1,2...,K}$,对应的边集合$E\subset{V \times V}$。每个顶点节点代表一个区域,边表示和邻近区域相连,边权重代表区域之间的相似度或代价,如图所示:

最相似的邻近区域有最小的代价,代价也就是相似度的计算方式如下:
$R_M=\{R_M^1,R_M^2,...,R_M^M\}$表示图像Y的M个区域集合。$R_M^k=\{p_{k,1},p_{k,2},...,p_{k,||R_M^k||}\}$是第k个区域$R_M^k$的样本集。$||R||$表示集合的基数,有限集的基数(cardinality )就是传统概念下的“个数”。 $\mu(R_M^k)$是每部分的均值:
最后的分割个数n由$\delta(\cdot)$决定,如果$\delta$小于某个阈值则迭代终止。阈值可以根据噪声分布来确定。
输入:K部分的RAG,K-RAG
迭代 util $min(\delta)>= Treshold$
- (K-i)-RAG的边集合中找到最相似的边(
$\delta$最小) - 融合最相似边对应的两个区域顶点,得到(K-i-1)-RAG
- 更新顶点和边集合
输出:(K-n)-RAG
demo_watershed.m 处理步骤:
- 对输入图像进行平滑滤波
- 求梯度图像,对梯度进行阈值
- 分水岭分割
- 区域融合 对此算法来说,梯度图像的阈值,影响着区域融合的效果和计算时间。更大的阈值意味着分水岭分割后区域个数越少,计算速度越快。但是过大的阈值会丢失边缘轮廓。 初始分水岭分割结果如图所示
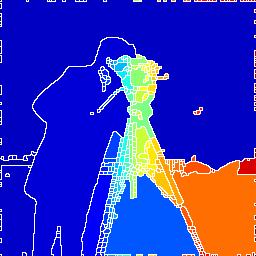
区域融合后的结果如图所示

[1]. Haris K, Efstratiadis S N, Maglaveras N, et al. Hybrid image segmentation using watersheds and fast region merging.[J]. IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society, 1998, 7(12):1684-1699.