cpt.mean(method="BinSeg") slower than expected/optimal for large number of data and changes
Closed this issue · 1 comments
hi @rkillick I computed timings of changepoint::cpt.mean(method="Binseg") for the L2 loss (square loss, normal change in mean with constant variance), https://github.com/tdhock/binseg-model-selection#22-mar-2022
I simulated several data sets with number of data points N in { 2^2=4, ..., 2^20 = 1,048,576 } and I set max.changes = N/2-1, then ran binary segmentation, see https://github.com/tdhock/binseg-model-selection/blob/main/figure-timings-data.R for details.
I observed timings consistent with cubic O(N^3) asymptotic time complexity, whereas worst case should be quadratic O(N^2) and best case should be log linear O(N log N).
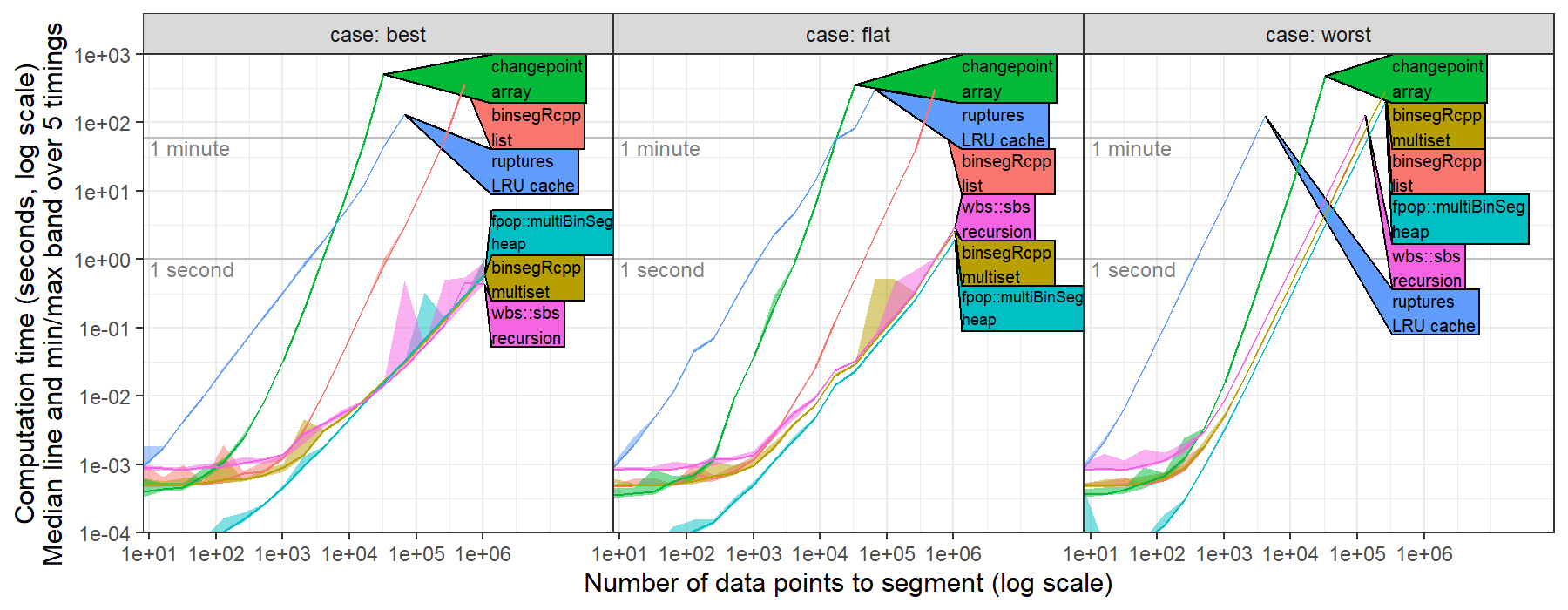
This is because the way BinSeg is currently coded it isn't super-efficient. Binary Segmentation, whilst conceptually simple, is not that simple to code efficiently as after the first split there could be several segments which are candidates for further splits. There is a tradeoff between keeping track of segments requiring calculation and just re-doing calculations. We could certainly improve the current code as it recalculates likelihood values after a changepoint is identified in a different segment. Pull requests for modifications always welcome!