This project is an example that how to implement fast-API and the pydiator-core. You can see the detail of the pydiator-core on this link https://github.com/ozgurkara/pydiator-core
uvicorn app.main:app --reload
coverage run --source app/ -m pytest
coverage report -m
coverage html
Pydiator is an in-app communication method.
It provides that developing the code as an aspect. Also, it supports clean architecture infrastructure
It is using design patterns such as chain of responsibility, mediator, singleton.
Pydiator provides which advantages to developers and project?
- Is testable
- Has Use case support
- Has Aspect programming (Authorization, Validation, Cache, Logging, Tracer etc.) support
- Has Clean architecture support
- Expandable architecture via pipeline
- Is independent framework
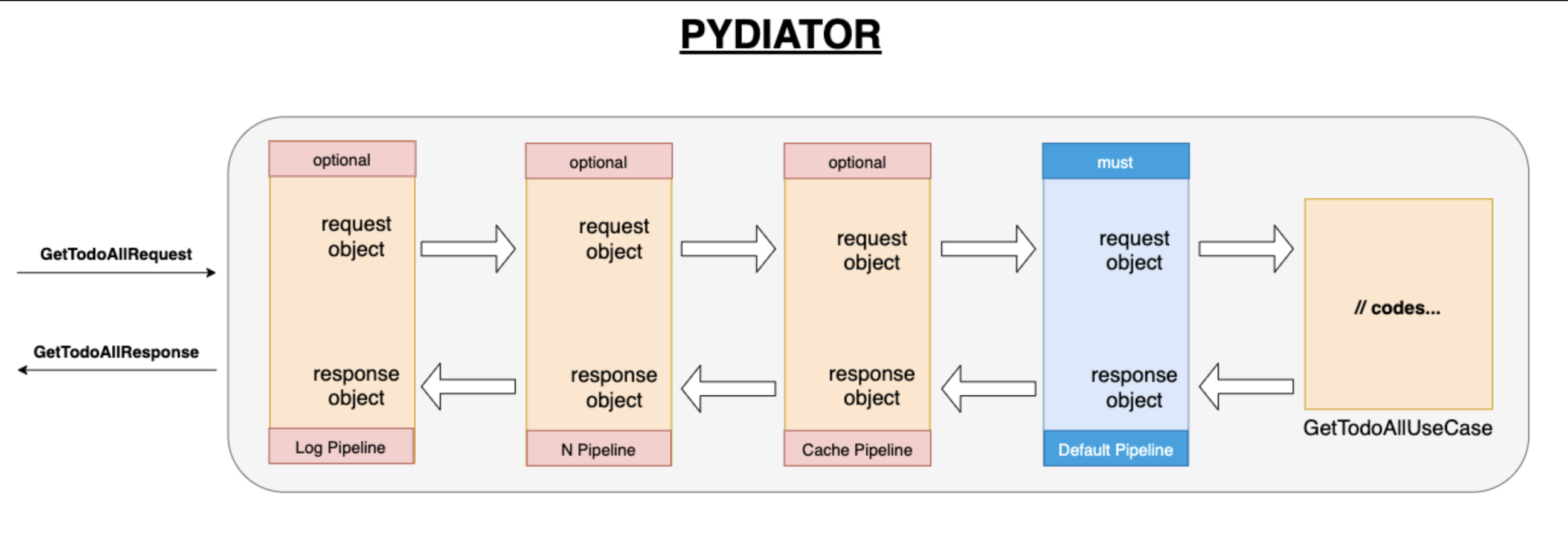
Pydiator knows 4 object types. These are;
1- Request object
- Is used for calling the use case.
- It should be inherited from BaseRequest
class GetSampleByIdRequest(BaseRequest):
def __init__(self, id: int):
self.id = id2- Response object
- Is used for returning from use case
- It should be inherited from BaseResponse
class GetSampleByIdResponse(BaseResponse):
def __init__(self, id: int, title: str):
self.id = id
self.title = title 3- Use Case
- Includes logic codes
- It should be inherited from BaseHandler
- It takes one parameter to handle. The parameter should be inherited BaseRequest
class GetSampleByIdUseCase(BaseHandler):
async def handle(self, req: GetSampleByIdRequest):
# related codes are here such as business
return GetSampleByIdResponse(id=req.id, title="hello pydiator") What is the relation between these 3 object types?
Every use case object only knows a request object
Every request object is only used by one use case object
How is the use case run?
Should be had a particular map between the request object and the use case object.
Mapping example;
def set_up_pydiator():
container = MediatrContainer()
container.register_request(GetSampleByIdRequest, GetSampleByIdUseCase())
#container.register_request(xRequest, xUseCase())
pydiator.ready(container=container)Calling example;
await pydiator.send(GetByIdRequest(id=1))or
loop = asyncio.new_event_loop()
response: GetByIdResponse = loop.run_until_complete(pydiator.send(GetByIdRequest(id=1)))
loop.close()
print(response.to_json())4- Pipeline
The purpose of the pipeline is to manage the code as an aspect. For instance, you want to write a log for the request and the response of every use case. You can do it via a pipeline easily. You can see the sample log pipeline at this link.
You can create a lot of pipelines such as cache pipeline, validation pipeline, tracer pipeline, authorization pipeline etc.
Also, you can create the pipeline much as you want but you should not forget that every use case will be used in this pipeline.
You can add the pipeline to pipelines such as;
def set_up_pydiator():
container = MediatrContainer()
container.register_pipeline(LogPipeline())
#container.register_pipeline(xPipeline())
pydiator.ready(container=container)How can I write custom pipeline?
- Every pipeline should be inherited BasePipeline
- Sample pipeline
class SamplePipeline(BasePipeline):
def __init__(self):
pass
async def handle(self, req: BaseRequest) -> object:
# before executed pipeline and uce case
response = await self.next().handle(req)
# after executed next pipeline and use case
return response