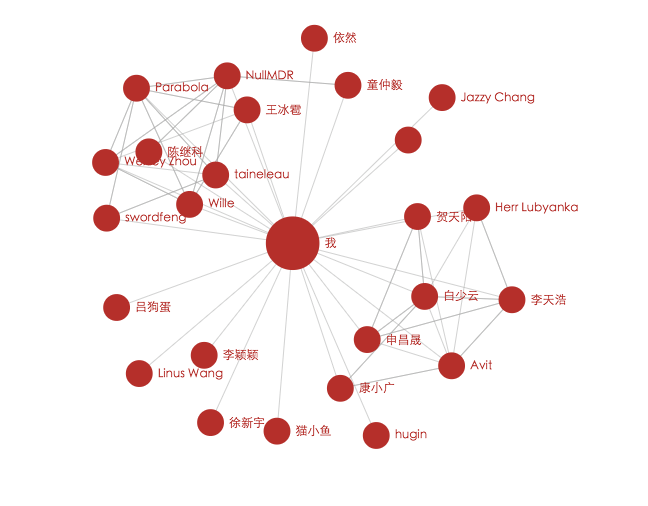
#知乎关系网爬虫
#使用方法 1、初始化
git clone https://github.com/starkwang/Spider.git && cd Spider
npm run init
2、配置
参考server.config.example.js与spider.config.example.js,配置你自己的server.config.js与spider.config.js
3、构建并开始
npm run build
npm run start // Server runs at localhost:3000
#配置
1、spider.config.js
cookie[string](必填项) : 自己在知乎上的cookie_xsrf[string](必填项): 自己在知乎上的_xsrfconcurrency[number](可选项): 请求的并发数,默认为3
由于知乎的API较不稳定,concurrency并发数太大可能会造成卡死,在网络环境不好时建议设置为2或者1
2、server.config.js
socketPort[number](必填项) : 用于websocket的端口号httpPort[number](必填项): 用于http的端口号
###附:cookie与_xsrf配置方法
打开知乎任意用户的关注者页,例如https://www.zhihu.com/people/starkwei/followers
打开浏览器控制台,选择Network:
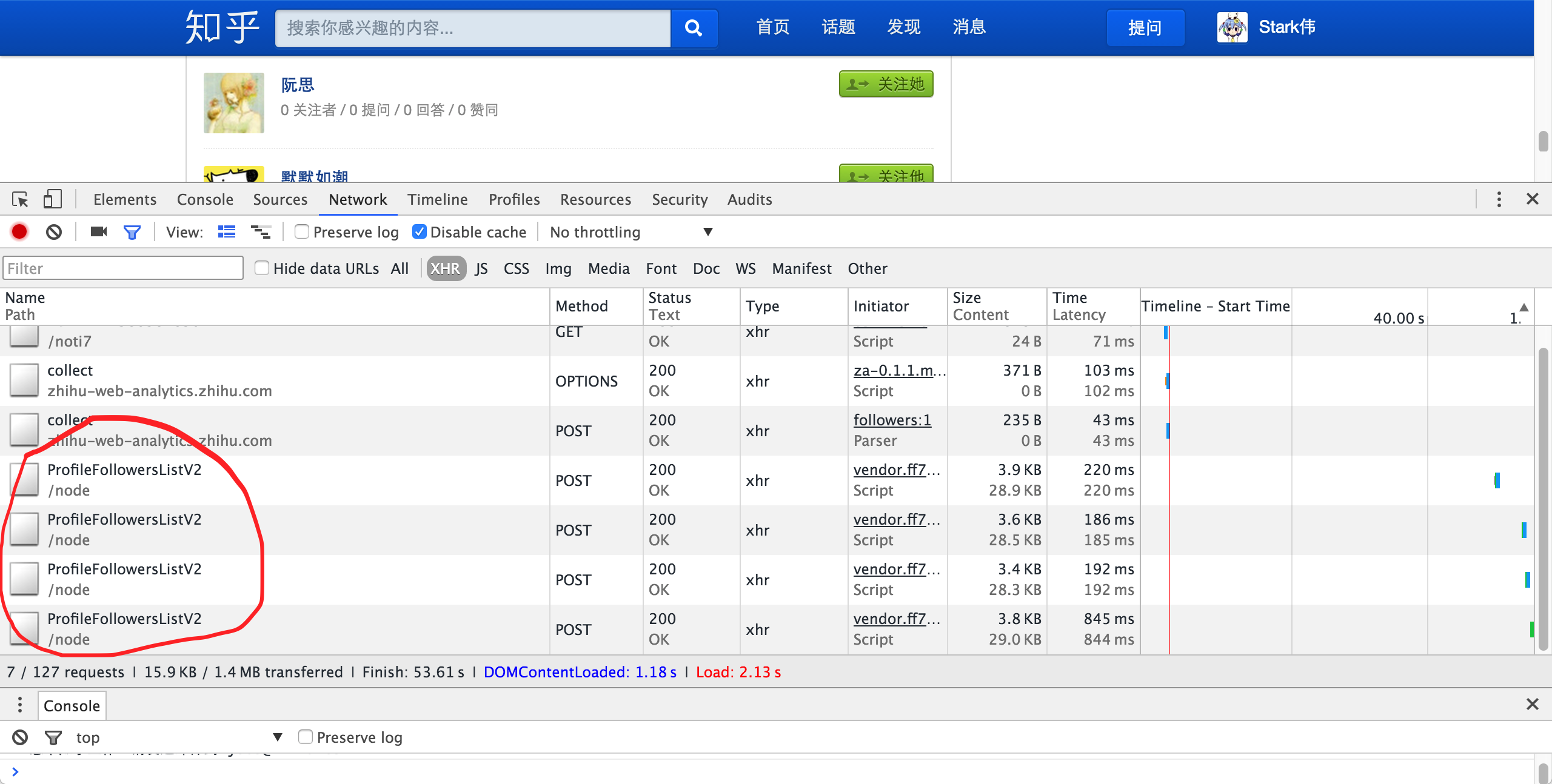
下拉页面,会自动加载更多关注者,可以看到对/node/ProfileFollowersListV2这个接口发起了多次请求:
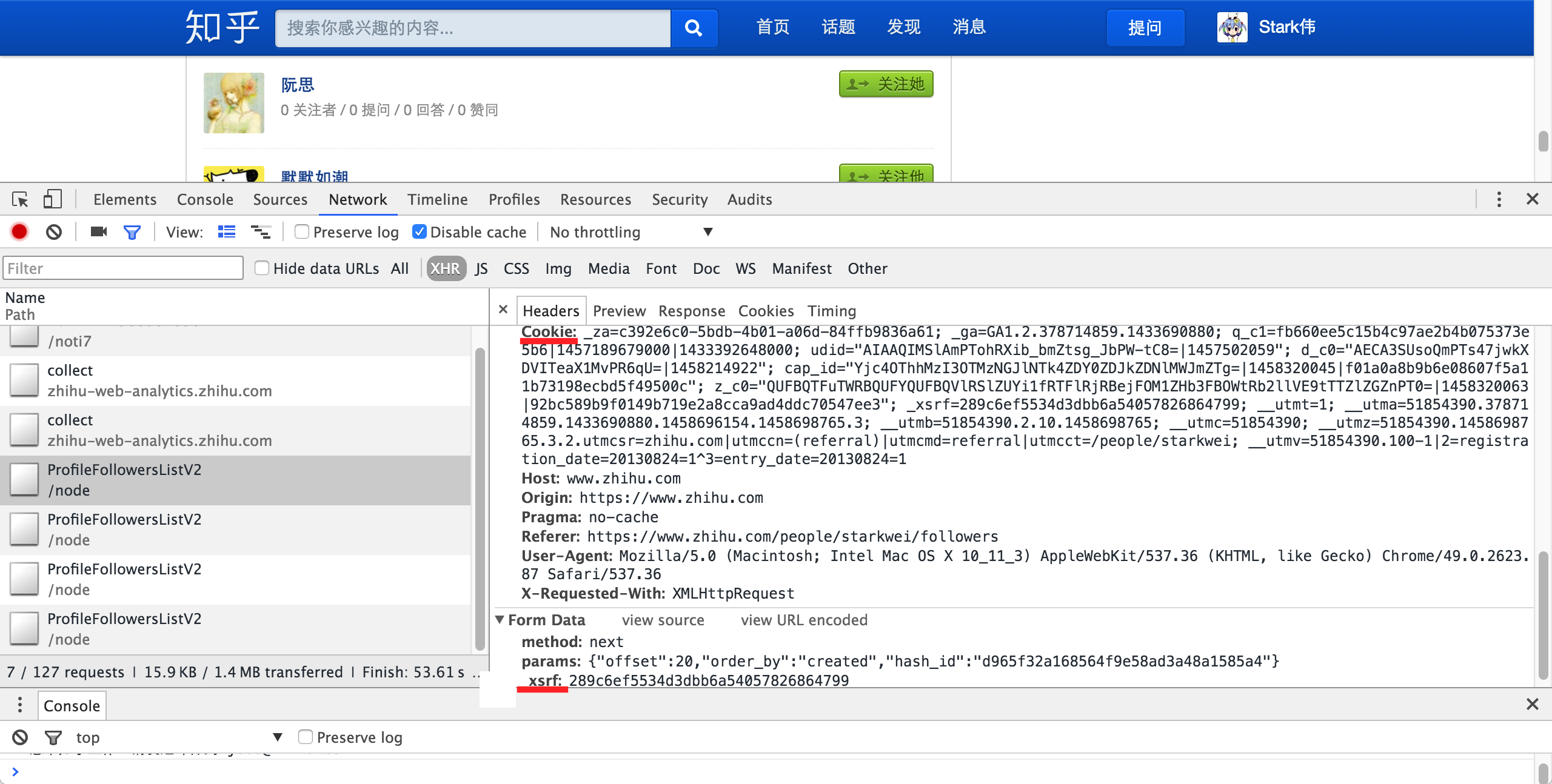
 打开请求详情,Cookie和_xsrf就在里面:
打开请求详情,Cookie和_xsrf就在里面:
#已知的BUG或者缺陷
- 对于粉丝数过多的大V,爬取速度过慢
- 当相互关注的人中有自己时,不能爬取和自己有关的关系链
- 请求失败或者timeout时,没有重发请求,可能会导致部分数据缺失