"find_under_expand" (ctrl+d) command has no effect with words containing certain unicode chars
yg-h opened this issue · 10 comments
gif explanation

explanation in words
normally when no text is selected and caret is inside a word, pressing [ ctrl + d ] will select that word, pressing it again will select next instance, etc.
on my machine this works for (i) words containing only ascii word chars, and (i'm pleasantly surprised to find) also (ii) words made up partly of ascii word chars and partly of east asian word chars.
however, with some more recent unicode chars and emojis (many of which are actually very suitable for naming e.g. throwaway variables), find_under_expand only partially works. pressing [ ctrl + d ] once will expand selection to the word under caret, but pressing it again will not select the next instance.
Environment
- Operating system and version:
- Windows 10 Pro 64 bit
- Sublime Text:
- Build 3126
Please include the text used in the recording for easier reproduction.
Expanding the selection to words usually works by going in both directions until a non-word character is found. Neither whitespace nor your unicode character are proper word characters, so it presumes there is no word next to the selection. (This is just speculation.)
If ST was able to distinguish any unicode character between a word and non-word character, how would you expect it to behave? Use unicode properties?
oops, sorry, should have included the code sample. here it is:
pop = ScbStackData.peek()
scb_debug_write("peek " + pop)
window = sublime.active_window()
window_id = window.id()
window_id = window.id()
window_id = window.id()
window_id = window.id()
window_id = window.id()
window_id = window.id()
window🆔 = window.id()
window🆔 = window.id()
window🆔 = window.id()
window🆔 = window.id()
window🆔 = window.id()
window🆔 = window.id()
window🆔 = window.id()
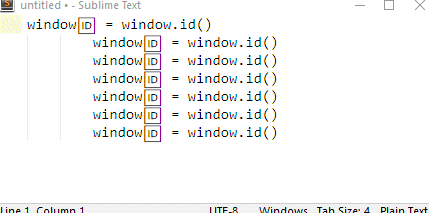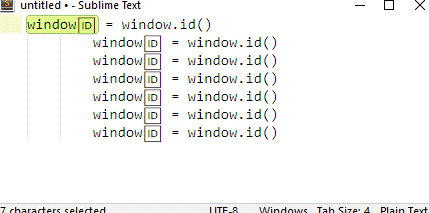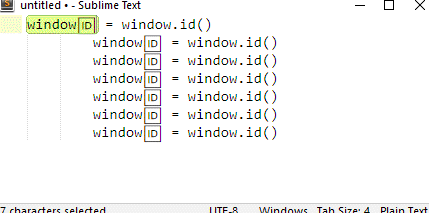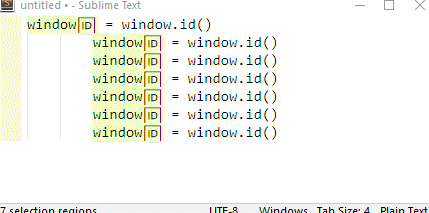
in response to your point, i would argue that my version of sublime does regard the text "window🆔" as a single word (i.e. it treats 🆔 as a word char, rather than a non-word char (which is desirable from my point of view). i say this because:
-
the initial pressing of [ ctrl + d ] does expand the selection to include the unicode char (this can be seen in the video above)
-
if i simply run the "expand_selection" command, setting the "to" argument to "word", again the desired behavior is produced: the selection is expanded to include the unicode char. here's a video to illustrate this.

-
finally, doubling clicking on "window🆔" selects the whole thing, rather than simply "window".

Ah right, now I understand the issue. I presume it's an issue with the regex engine ST uses, because you can replicate by searching for window🆔 with "Whole word" search active, which yields "Unable to find \bwindow🆔\b" in the status bar. You can also manually search for window🆔\b (with regexp search active) to observe the same.
According to Unicode, the emoji you are using is in the category Other Symbol, so I don't think it qualifies as a word char. https://codepoints.net/U+1F194?lang=en
The issue is probably technically more that it is selected when pressing ctrl+d in the first place.
That makes sense in a language standpoint, but most languages that support unicode glyphs in identifiers usually do not care what category a glyph is in. Usually some categories or classifiers are excluded, too. That said, languages differ, so I can see this going either way.
According to Unicode, the emoji you are using is in the category Other Symbol
true. on the other hand, from a semantic point of view '🆔' seems even further from whitespaces and punctuation symbols as it is the kind of symbol that stands for some concept/idea (like the english word 'id') and so might reasonable appear in names and identifiers.
seems to me there'd be little harm in allowing emojis to be part of the word, given that
- programmers who don't use emojis won't be negatively affected by it
- those who do will benefit from it (their ctrl+d will work as desired)
- it's possible to configure preferences (the word_separators setting) to make even commas and colons part of words. so from a consistency point of view, it seems it'd be desirable for there at least to be the possibility to do the same for emojis like 🆔 which have a better claim than commas and colons to be part of words.
I would have to run such a change by Jon to get his opinion.
My main concern with this is coming up with a set of rules that can be documented, tests written for and implemented in a consistent way. The current implementation uses the concept of a word boundary, \b when finding the next match. By allowing emoji, we need to effectively recreate word boundary regex in such a way that (all?) emojis are allowed, but that we are not breaking existing matching behavior.
great. thanks for at least considering it, whichever way you and Jon decide to go in the end.
if i may i would just add one more point to advocate on behalf of emojis. i feel that one advantage of programming languages over math formuals is that you can have meaningful/descriptive identifiers (unlike e.g. the intrinsically meaningless greek letters used in math), which allows you to recall what a symbol is supposed to stand for just from the symbol's appearance. however, this comes at a cost, in that one advantange math formuals have over programming languages is that the structure is easier to parse visually —— e.g. you eyes can very quickly pick out all the instances of Σ in your visual field when you look at a chunk of math formulas, whereas they can't as easily do this with words like 'sum' (not to mention even longer identifiers), which is why "highlight all instances" functionality is needed and useful in code editors. although descriptive identifiers are helpful when you want to remember what was supposed to be stored in a variable, they are a hindrance when you want to e.g. quickly see all the places in a function where a particular var is manipulated.
in a way, emojis combine the best of both worlds, because like greek letters they stand out from the text, and unlike greek letter most of them are pictograms and so do encode some conventional meaning (so you can e.g. see 🆔 in your code and instantly know what you used it for). i think this makes them more useful for coding than a lot of people tend to give them credit for. ..
crtl+f (Whole word button should be disabled) and esc, then ctrl+d will select duplicates.
Also, speaking of rules and all that, there is Default Word Boundary Specification, it includes only those related to Emoji Sequences (i.e. the case when one modifies the appearance of another), many emojis do not have a sequence modifier, thus are not word breakers
1F194 ; emoji ; L1 ; none ; j # V6.0 (🆔) SQUARED ID
none means no modifier