web开发中,必须要了解的HTTP相关知识
sunzhaoye opened this issue · 0 comments
本文主要记录与HTTP相关的具体概念和知识,关于HTTP协议的诞生和历史发展,不多做介绍,自己但是既然是写HTTP,顺带说两句,上下文也能衔接的上。
CERN(欧洲核子研究组织)的蒂姆 • 伯纳斯 - 李(Tim BernersLee)博士提出了一种能让远隔两地的研究者们共享知识的设想,于是HTTP慢慢的诞生了。
另外,HTTP协议是无状态可以,于是为了保存用户的状态,cookie诞生了。
HTTP协议是建立在TCP连接之上的,当浏览器输入URL进行访问,浏览器冲URL中解析出主机名和端口,浏览器建立一条与web服务器的连接,然后才进行http请求。
TCP连接的建立与终止
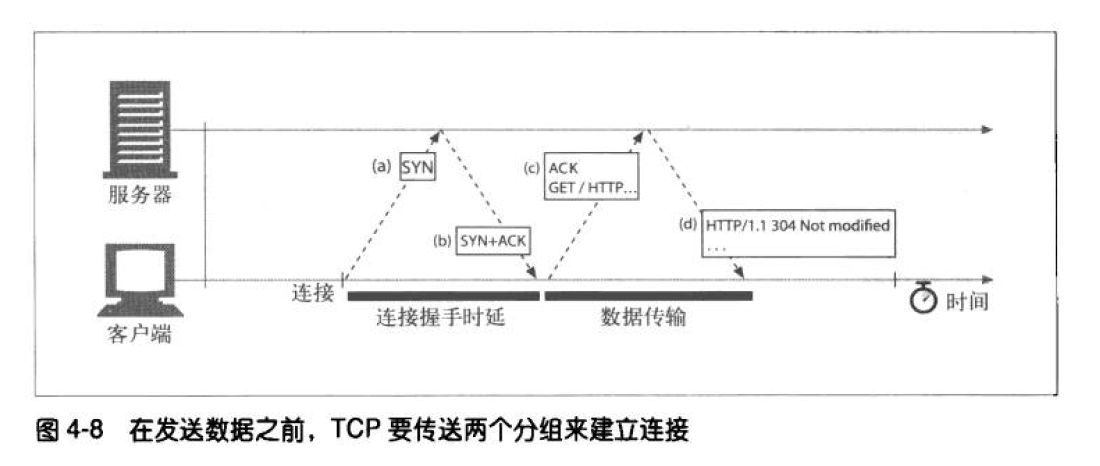
建立TCP连接(三次握手)
在客户端与服务端进行http通信之前,需要建立TCP连接,这时需要三次握手
(1) 请求新的TCP连接,客户端发送一个小的TCP分组,这个分组设置一个特殊的SYN标记,表明是一个客户端请求。
(2) 如果服务器接受这个连接,就会对一些连接参数进行计算,并向客户端回送一个TCP分组,发送SY和ACK标记,表明连接请求已经被接受
(3) 最后,客户端向服务器回送一条确认消息,通知服务器连接已经建立。
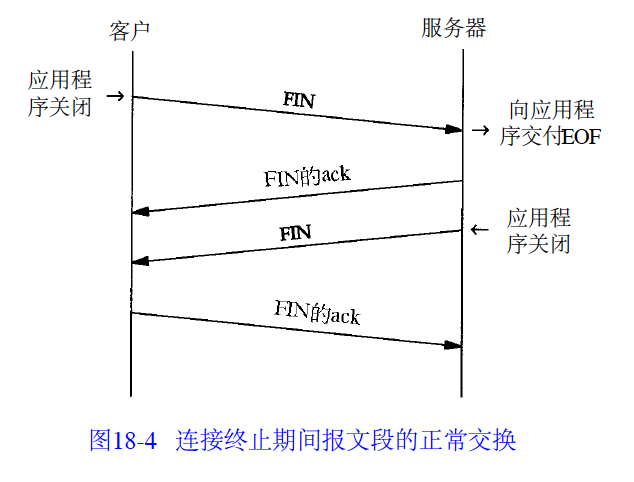
断开TCP连接(四次断开)
建立一个连接需要三次握手,而终止一个连接要经过4次握手。这由TCP的半关闭(half-close)造成的。既然一个TCP连接是全双工(即数据在两个方向上能同时传递),因此每个方
向必须单独地进行关闭。这原则就是当一方完成它的数据发送任务后就能发送一个FIN来终止
这个方向连接。当一端收到一个FIN,它必须通知应用层另一端几经终止了那个方向的数据传
送。发送FIN通常是应用层进行关闭的结果。
(1) 客户端发送FIN标记到服务器,表明客户端发起关闭连接
(2) 服务器接收客户端的FIN标记并,向客户端发送FIN的ACK确认标记
(3) 服务器发送FIN到客户端,服务器关闭连接
(4) 服务器端发送一个FIN的ACK确认标记,确认连接关闭
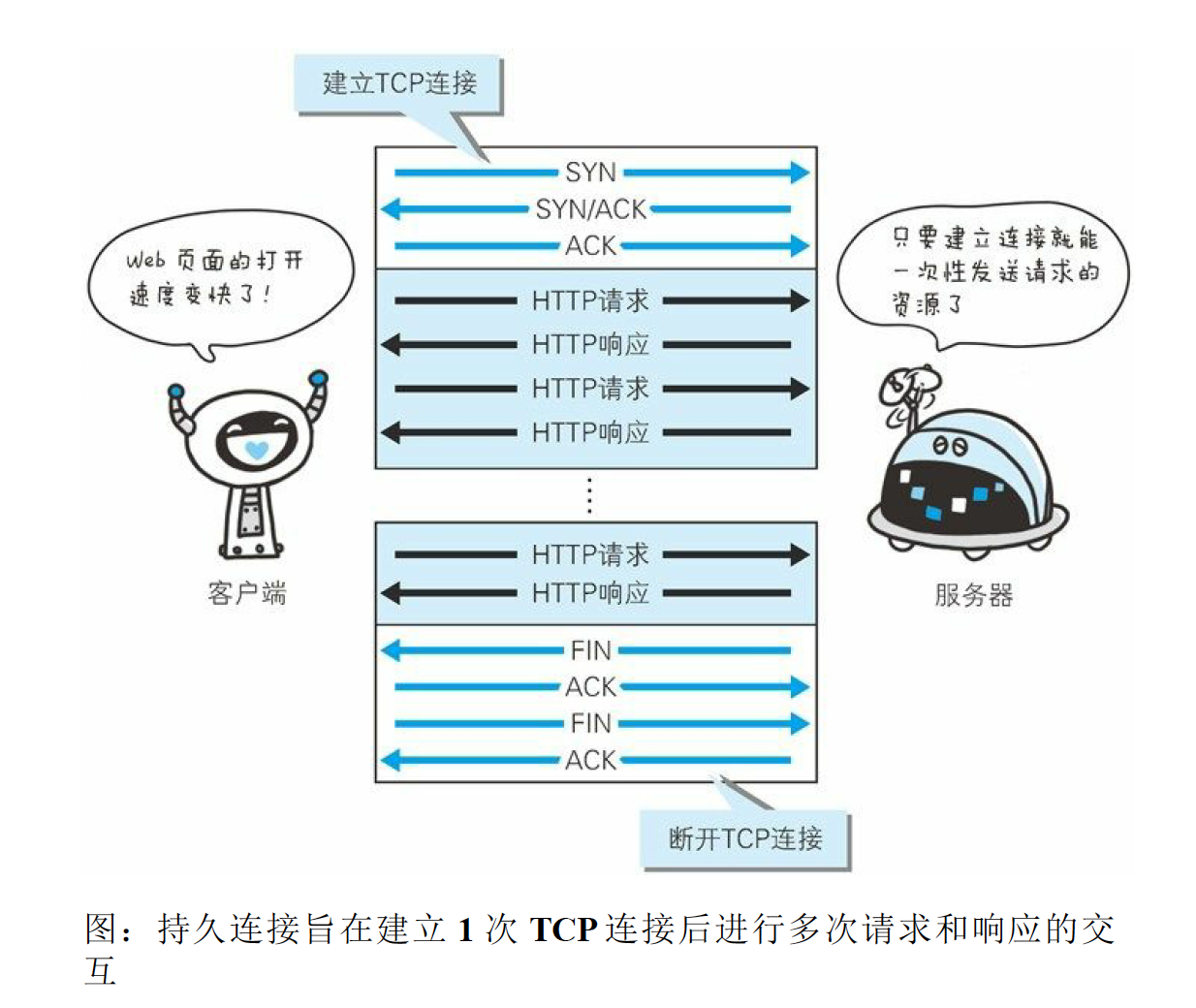
建立持久连接的请求和响应交互:
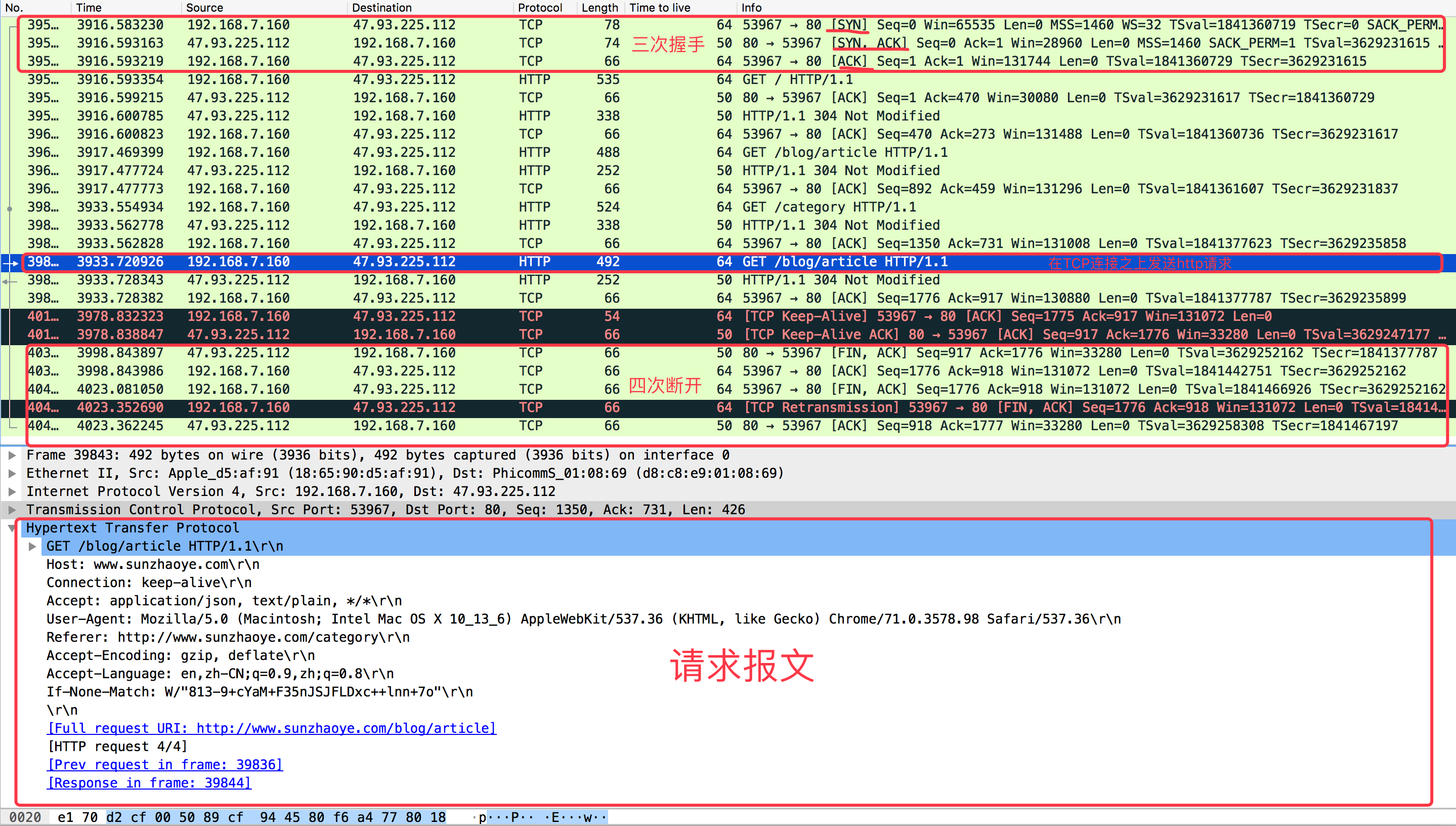
使用wireshark进行数据抓包:
这里向大家推荐一款抓包软件Wireshark,可以用来分析TCP连接的建立和断开过程,以及抓取HTTP请求和相应的信息等,下面是我进行一次客户端和服务端通信的抓包数据截图:
HTTP报文
HTTP协议报文是应用程序之间发送的数据块,也就是客户端和服务端用于交互的信息。客户端的报文叫做请求报文,服务器端的报文叫做响应报文。
HTTP报文组成
HTTP报文由起始行、首部和实体的主体(也称报文主体或主体)组成。起始行和首部以一个回车符和换行符作为结束,主体部分可以是二进制数据,也可以为空。
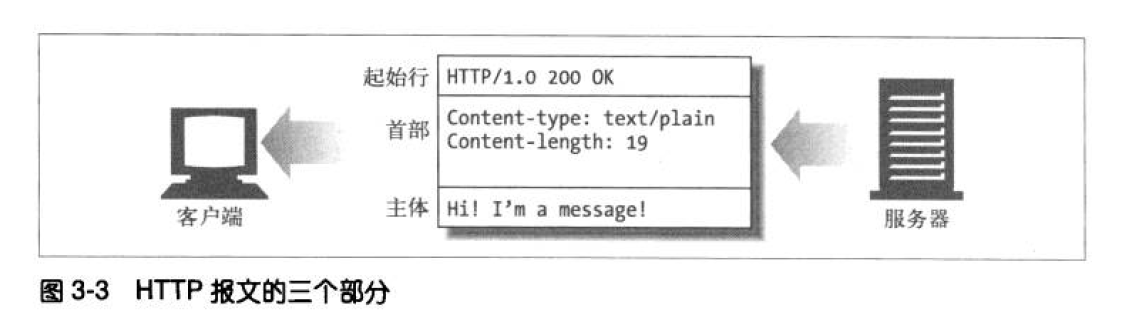
1. 起始行
请求报文起始行:
请求报文起始行说明了要做什么,由请求方法 、请求URI和协议版本构成。
GET /index.html HTTP/1.1
响应报文起始行:
响应报文的起始行,由协议版本、状态码和原因短语构成。
HTTP/1.1 200 OK // OK就是原因短语

2. 首部
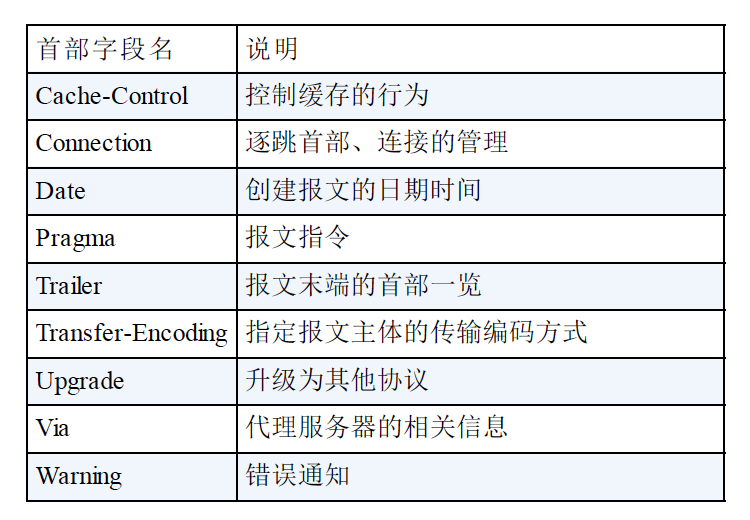
首部字段分类
- 1.通用首部
客户端和服务端都可以使用的首部
通用首部字段表:
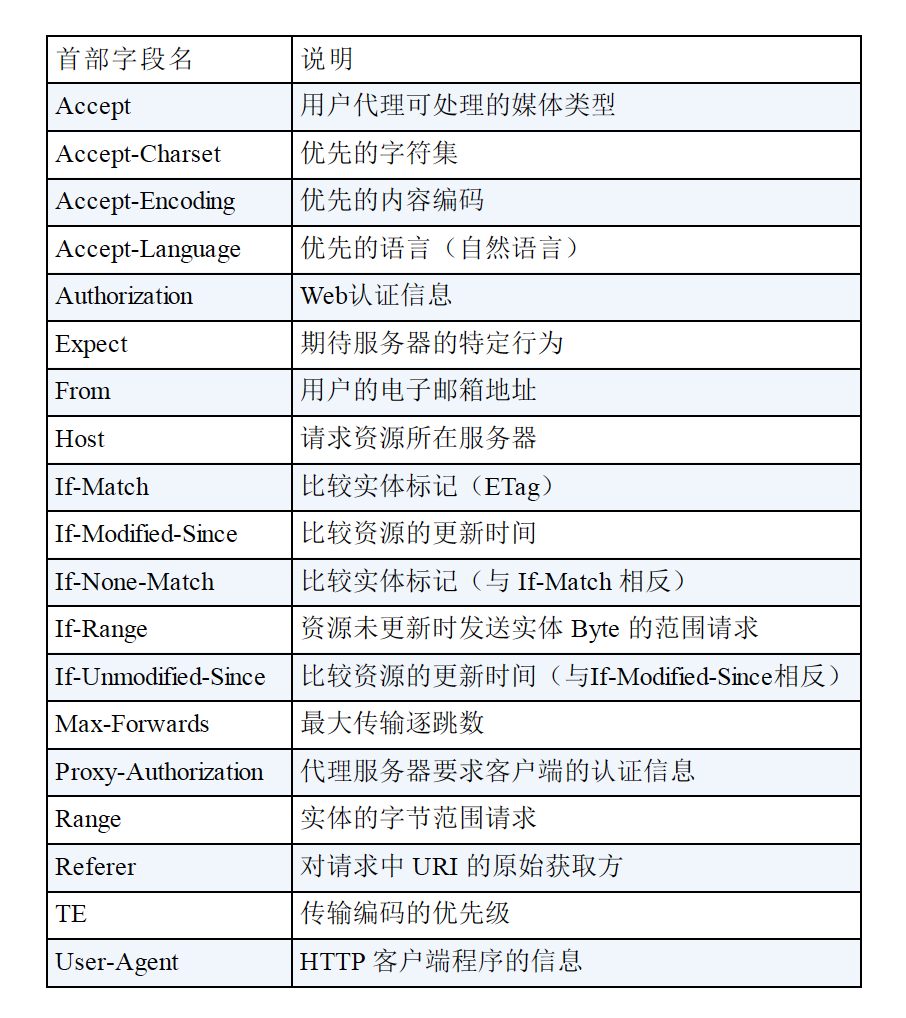
- 2.请求首部
请求报文特有的首部,为服务器提供了一些额外的信息,补充了请求的附加内容、客户端信息、响应内容相关的优先级等信息。
请求首部字段
- 3.响应首部
响应报文特有的字段
响应首部字段表:
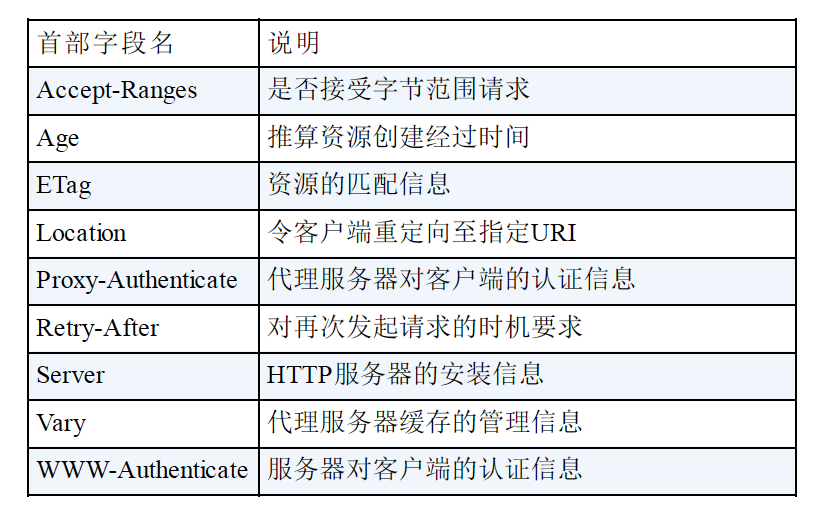
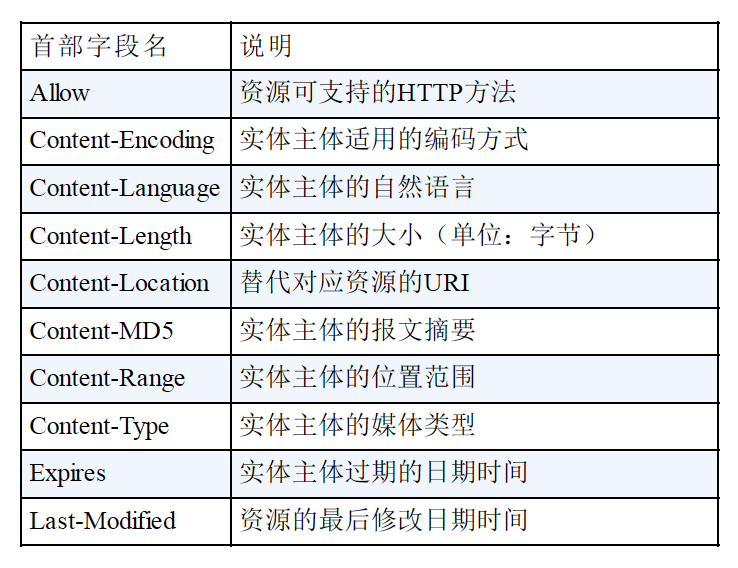
- 4.实体首部
用于针对请求报文和响应报文主体部分使用的首部
- 5.扩展首部
扩展首部是非标准的首部,由应用程序开发者创建,但还未添加到已批准的HTTP标准中去。
http状态码
状态码的职责是当客户端向服务器端发送请求时,描述返回的请求结果。借助状态码,用户可以知道服务器端是正常处理了请求,还是出现了错误。
状态码分类:
| 状态码区间 | 类别 |
|---|---|
| 100~199 | 信息性状态码 |
| 200~299 | 成功状态码 |
| 300~399 | 重定向状态码 |
| 400~499 | 客户端错误状态码 |
| 500~599 | 服务器错误状态码 |
常用状态码列表:
| 状态码 | 原因短语 | 含义 |
|---|---|---|
| 200 | OK | 表示从客户端发来的请求在服务器端被正常处理了 |
| 204 | No Content | 该状态码代表服务器接收的请求已成功处理,但在返回的响应报文中不含实体的主体部分。另外,也不允许返回任何实体的主体。 |
| 301 | Moved Permanently | 永久重定向,该状态码表示请求的资源已被分配了新的 URI,以后应使用资源现在所指的 URI |
| 302 | Found | 临时性重定向,该状态码表示请求的资源已被分配了新的 URI,希望用户(本次)能使用新的 URI 访问 |
| 303 | See Other | 303 状态码和 302 Found 状态码有着相同的功能,但 303 状态码明确表示客户端应当采用 GET 方法获取资源,这点与 302 状态码有区别 |
| 304 | Not Modified | 缓存 |
| 307 | Temporary Redirect | 临时重定向,和302一样 |
| 400 | Bad Request | 该状态码表示请求报文中存在语法错误。当错误发生时,需修改请求的内容后再次发送请求。另外,浏览器会像 200 OK 一样对待该状态码 |
| 401 | Unauthorized | 该状态码表示发送的请求需要有通过 HTTP 认证(BASIC 认证、DIGEST 认证)的认证信息 |
| 403 | Forbidden | 该状态码表明对请求资源的访问被服务器拒绝了 |
| 404 | Not Found | 该状态码表明服务器上无法找到请求的资源 |
| 500 | Internal Server Error | 该状态码表明服务器端在执行请求时发生了错误。也有可能是 Web应用存在的 bug 或某些临时的故障 |
| 502 | Bad Gateway | 网关错误 |
| 503 | Service Unavailable | 该状态码表明服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。如果事先得知解除以上状况需要的时间,最好写入RetryAfter 首部字段再返回给客户端 |
HTTP中不同场景下,首部字段的作用
1. CORS 跨域资源共享
跨域资源共享(CORS) 是一种机制,它使用额外的 HTTP 头来告诉浏览器 让运行在一个 origin (domain) 上的Web应用被准许访问来自不同源服务器上的指定的资源。当一个资源从与该资源本身所在的服务器不同的域、协议或端口请求一个资源时,资源会发起一个跨域 HTTP 请求。 --MDN
下面使用nodejs来搭建一个简单的服务器,来介绍一个跨域问题的解决方法
// index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>CORS</title>
</head>
<body>
Hello World
<script>
fetch('http://127.0.0.1:8081')
</script>
</body>
</html>
// server.js
const http = require('http')
http.createServer(function(req, res) {
res.writeHead('200', {
'Access-Control-Allow-Origin': 'http://localhost:8082'
})
}).listen(8081)
在源地址为 http://localhost:8082 下,请求http://localhost:8081,是跨域请求,浏览器会自动在request Header中发送Origin首部字段,并把值设置为来自哪个源,本例为http://localhost:8081。服务器需要在响应头中设置Access-Control-Allow-Origin,来告知浏览器可以处理返回的数据。如果响应头中不设置Access-Control-Allow-Origin则会报错,但是返回状态码为200,跨域实际上是浏览器本身的一个安全机制。


// server2.js
// 启动8082端口服务,在浏览器中访问http://127.0.0.1:8082,会返回index.html内容
const http = require('http')
const fs = require('fs')
http.createServer(function(req, res) {
var page = fs.readFileSync('index.html', 'utf-8')
res.writeHead(200, {
'Content-Type': 'text/html'
})
res.end(page)
}).listen(8082)
关于CORS跨域请求的分类:
1.简单请求:
需要同时满足以下的条件就是简单请求
(1)请求方法:
GET、POST、HEAD
(2)请求头不能为以下其他字段之外
Accept
Accept-Language
Content-Language
Content-Type的值必须为application/x-www-form-urlencoded、multipart/form-data、text/plain之一
2.非简单请求:
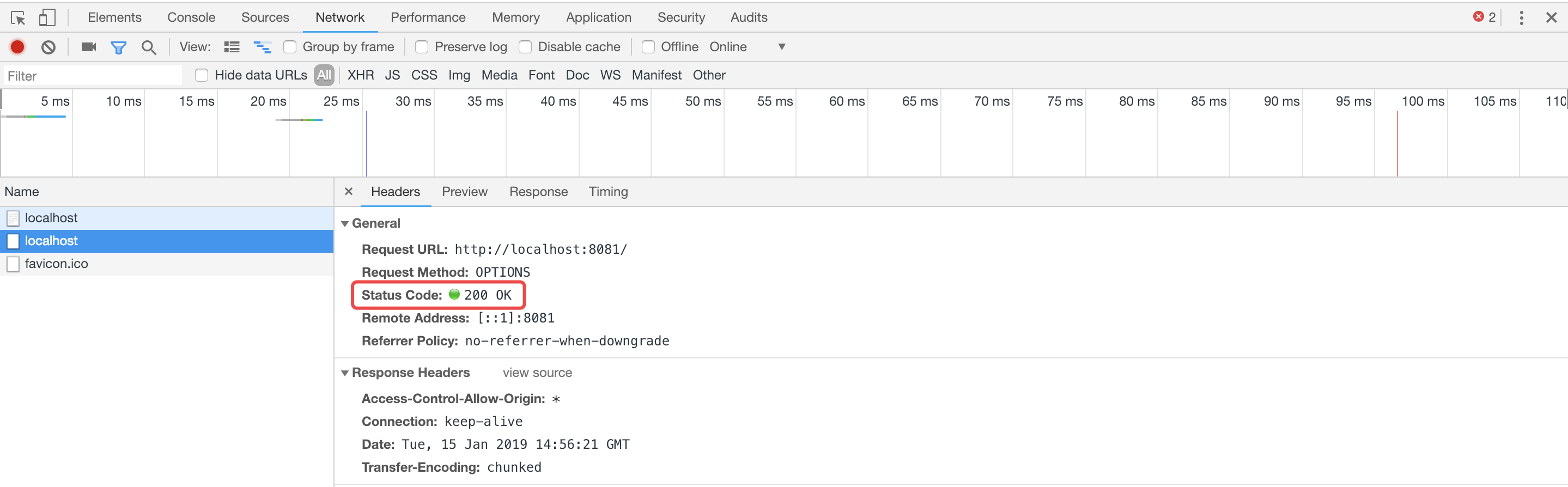
非简单请求是当请求信息不满足简单请求的条件,浏览器就发送方法为OPTIONS的预请求,包含自己请求的方法及需要使用的请求头字段,在得到服务器响应允许之后,浏览器会按照想要使用的请求方法及头信息再发一次请求。
现在修改以下上面的例子:
// index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>CORS</title>
</head>
<body>
Hello World
<script>
fetch('http://127.0.0.1:8081', {
method: 'PUT',
headers: {
X-Coustom-Head: 'abc'
}
})
</script>
</body>
</html>
// server.js
const http = require('http')
http.createServer(function(req, res) {
res.writeHead('200', {
'Access-Control-Allow-Origin': 'http://localhost:8082'
})
}).listen(8081)
如果服务端不进行相应的设置告诉浏览器允许跨域访问则会报错

但是预请求返回状态码为200
// server2.js
// 启动8082端口服务,在浏览器中访问http://127.0.0.1:8082,会返回index.html内容
const http = require('http')
const fs = require('fs')
http.createServer(function(req, res) {
var page = fs.readFileSync('index.html', 'utf-8')
res.writeHead(200, {
'Content-Type': 'text/html'
})
res.end(page)
}).listen(8082)
现在我们修改以下 server.js
// server.js
const http = require('http')
http.createServer(function(req, res) {
res.writeHead('200', {
'Access-Control-Allow-Origin': 'http://localhost:8082',
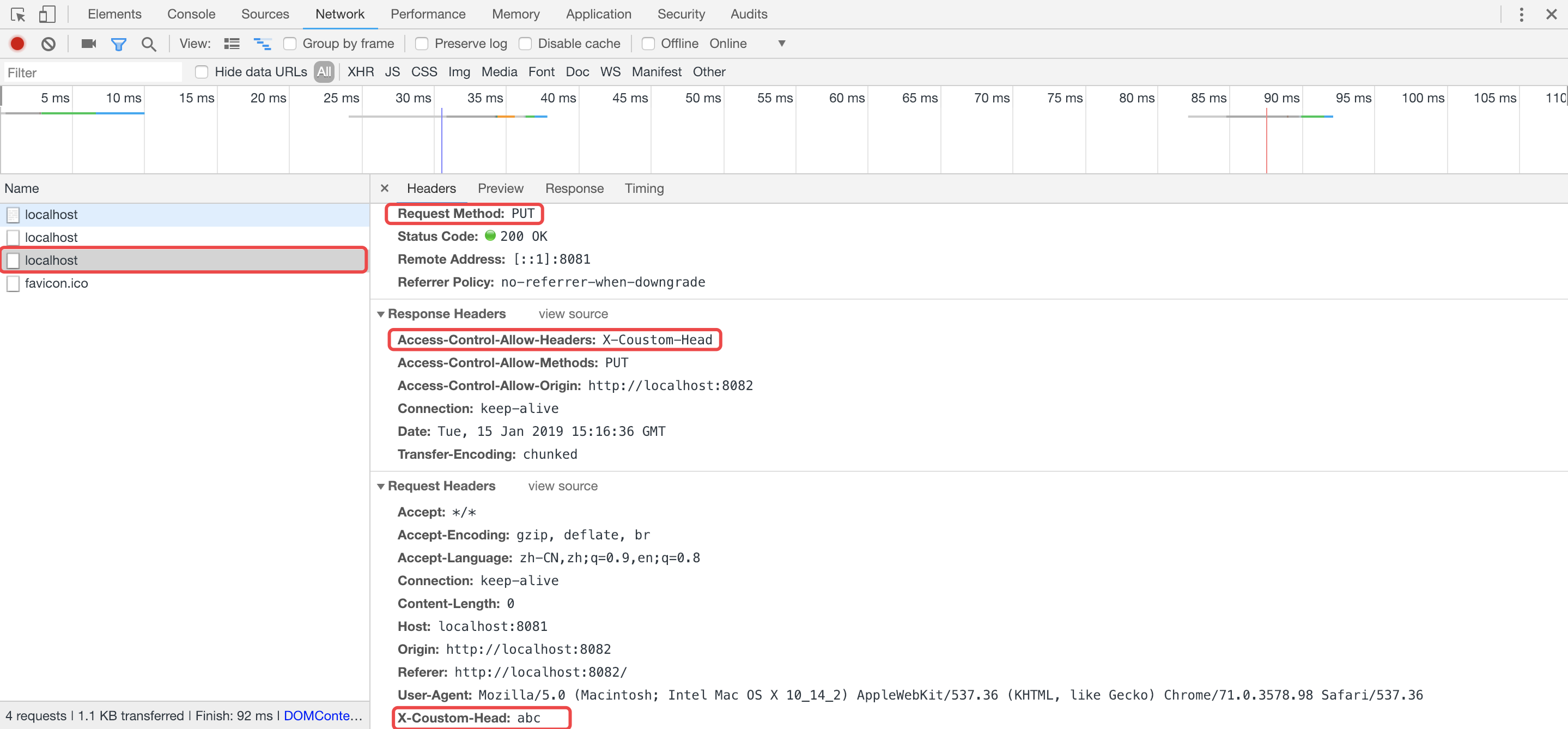
'Access-Control-Allow-Headers': 'X-Coustom-Head',
'Access-Control-Allow-Methods': 'PUT'
})
}).listen(8081)
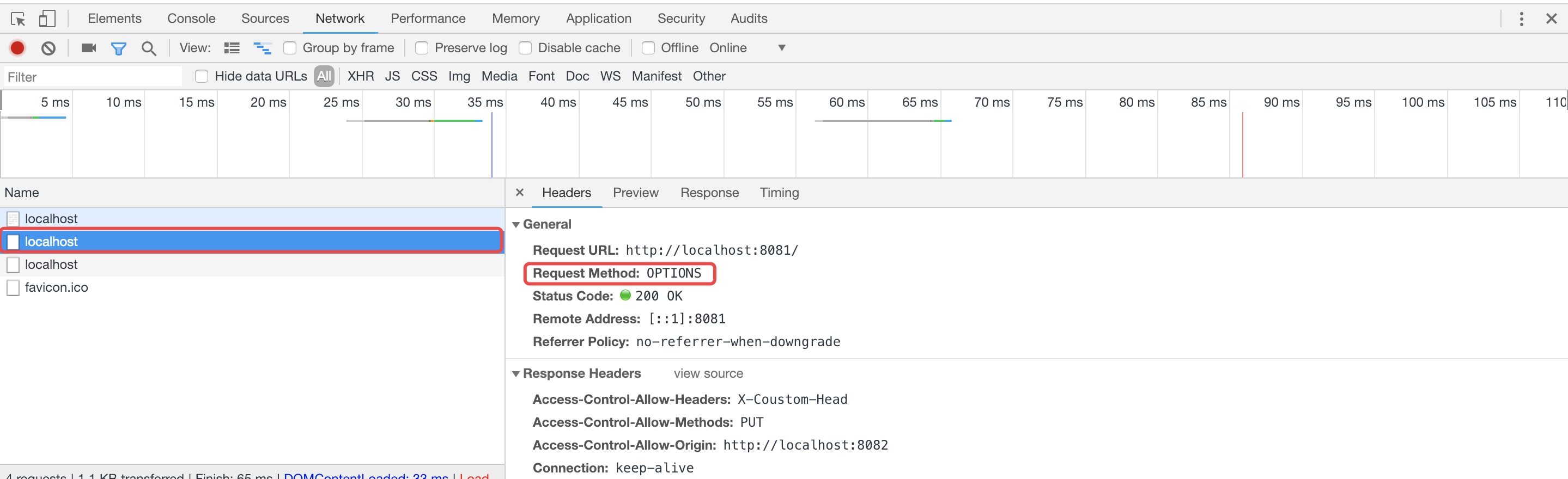
重新启动node服务,访问http://locaohost:8082,可以看到在发送预请求后,浏览器会继续发送PUT请求
关于CORS的其他设置这里就不多做介绍了,这里主要是用一个例子来说明以下http不同字段在跨域场景下的作用。
2. 缓存 (Cache-Control的作用)
本例依旧用node服务来讲解一下Cache-Control的作用,新建三个文件
// index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<title>Cache-Control</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body>
<script src="/script.js"></script>
</body>
</html>
// script.js
console.log('script.js')
// server.js
const http = require('http')
const fs = require('fs')
http.createServer(function(req, res) {
if (req.url === '/') {
let page = fs.readFileSync('index2.html', 'utf-8')
res.writeHead(200, {
'Content-Type': 'text/html'
})
res.end(page)
}
if (req.url === '/script.js') {
let page = fs.readFileSync('script.js', 'utf-8')
res.writeHead(200, {
'Content-Type': 'text/javascript',
'Cache-Control': 'max-age=10'
})
res.end(page)
}
}).listen(8082)
在第一次请求script.js资源时,向服务器发送请求


由于服务器返回响应时,设置Cache-Control: 'max-age=10'时,修改script.js后,在10秒内继续请求script.js资源,则从缓存中读取,而打印信息依旧是'script.js'
// script.js
console.log('script-modify.js')

更多关于缓存的知识在这里也不多介绍了,贴两张cache-control字段在请求和响应时可以设置的值和其表示含义:
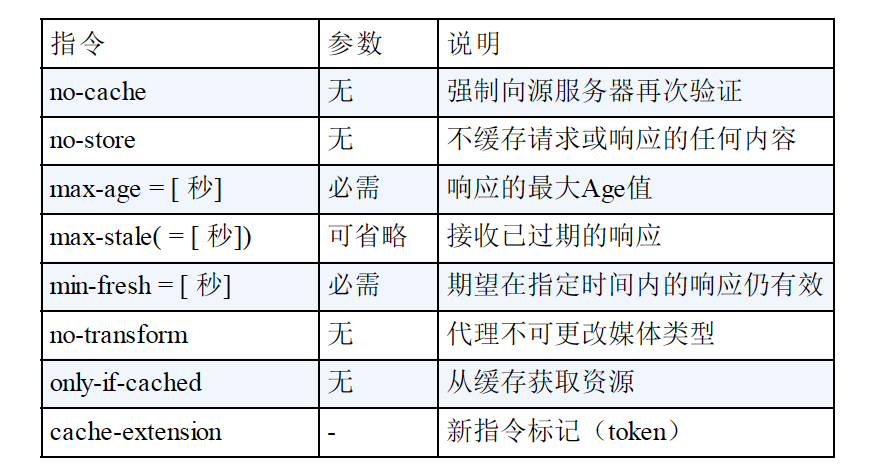
1. Cache-Control 缓存请求指令:
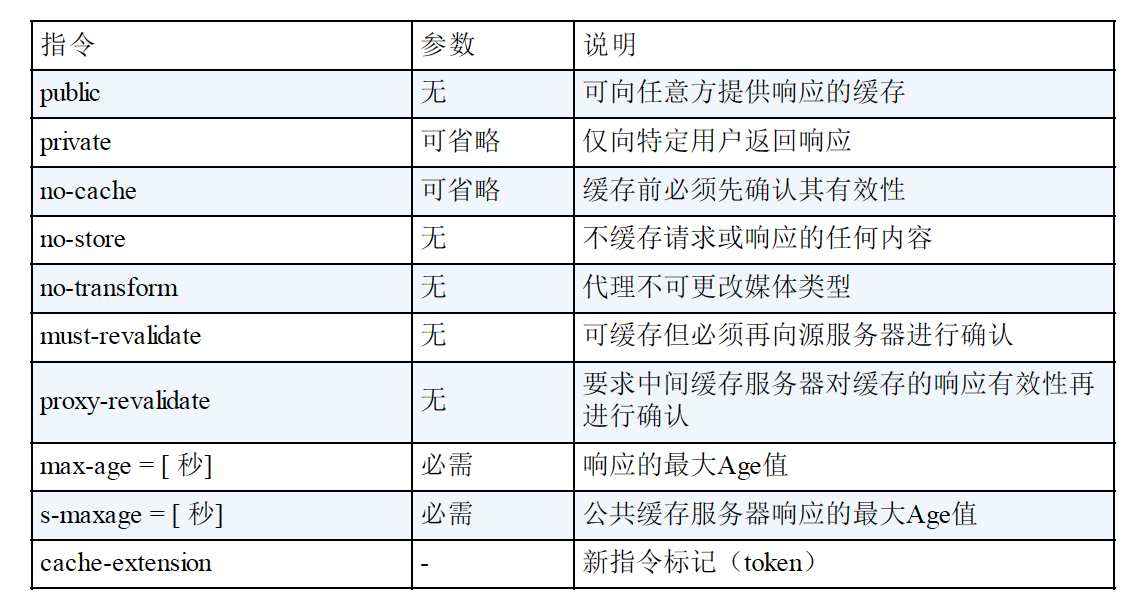
2. Cache-Control 缓存响应指令:
3. cookie
指某些网站为了辨别用户身份、进行 session 跟踪而储存在用户本地终端上的数据(通常经过加密),当下次再访问时浏览器会将该网站的cookie发回给服务器端。
cookie如果不设置过期时间,随浏览器关闭而失效,如果有需要可以设置过期时间,继续上代码例子🌰,新建两个文件如下
// index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>Cookie</title>
</head>
<body>
Cookie
<script>
console.log(document.cookie)
</script>
</body>
</html>
// server.js
const http = require('http')
const fs = require('fs')
http.createServer(function(req, res) {
if (req.url === '/') {
let page = fs.readFileSync('index.html', 'utf-8')
res.writeHead(200, {
'Content-Type': 'text/html',
'Set-Cookie': ['a=1;max-age:5', 'b=2;HTTPOnly']
})
res.end(page)
}
}).listen(8082)
启动node服务,访问localhost:8082,可以看到成功设置了cookie
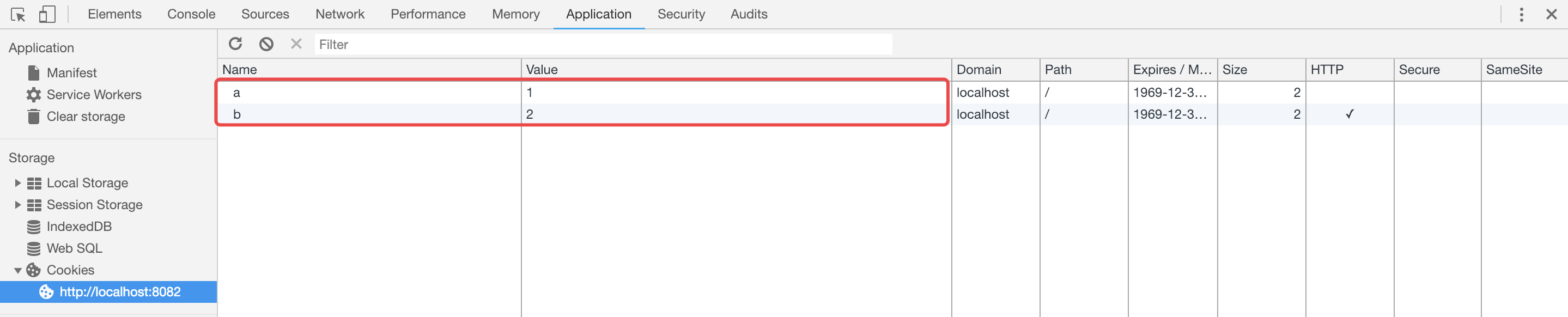
并在响应头信息中设置了Set-Cookie字段
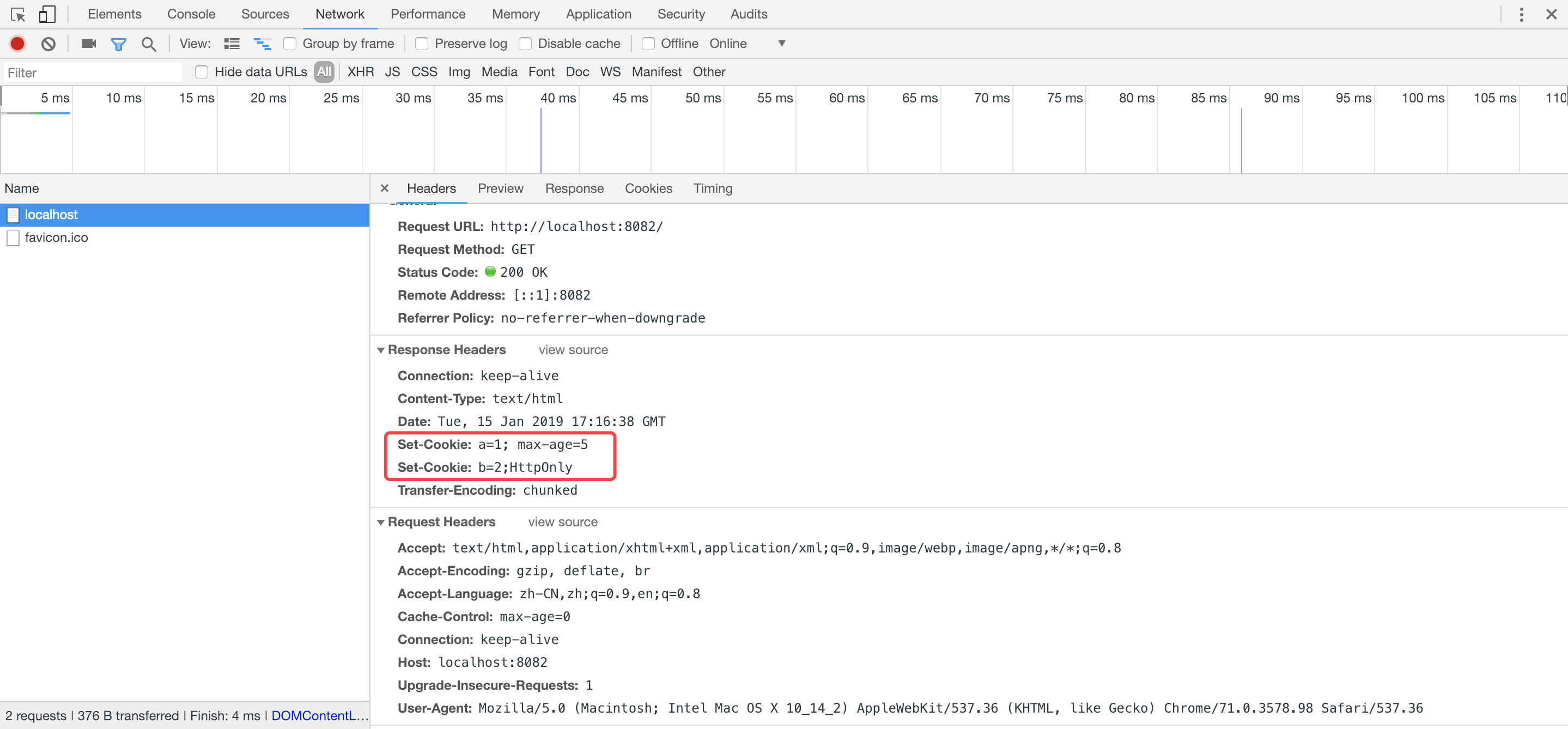
另外关注以下打印信息,发现只有a=1,因为给b=2设置了HttpOnly属性,不允许JavaScript通过脚本来获取到cookie信息

由于当再次请求时,cookie会在请求头中发送到服务器,由于cookie a=1设置了5秒后过期,在5秒后刷新页面,请求头中的cookie只有a=1
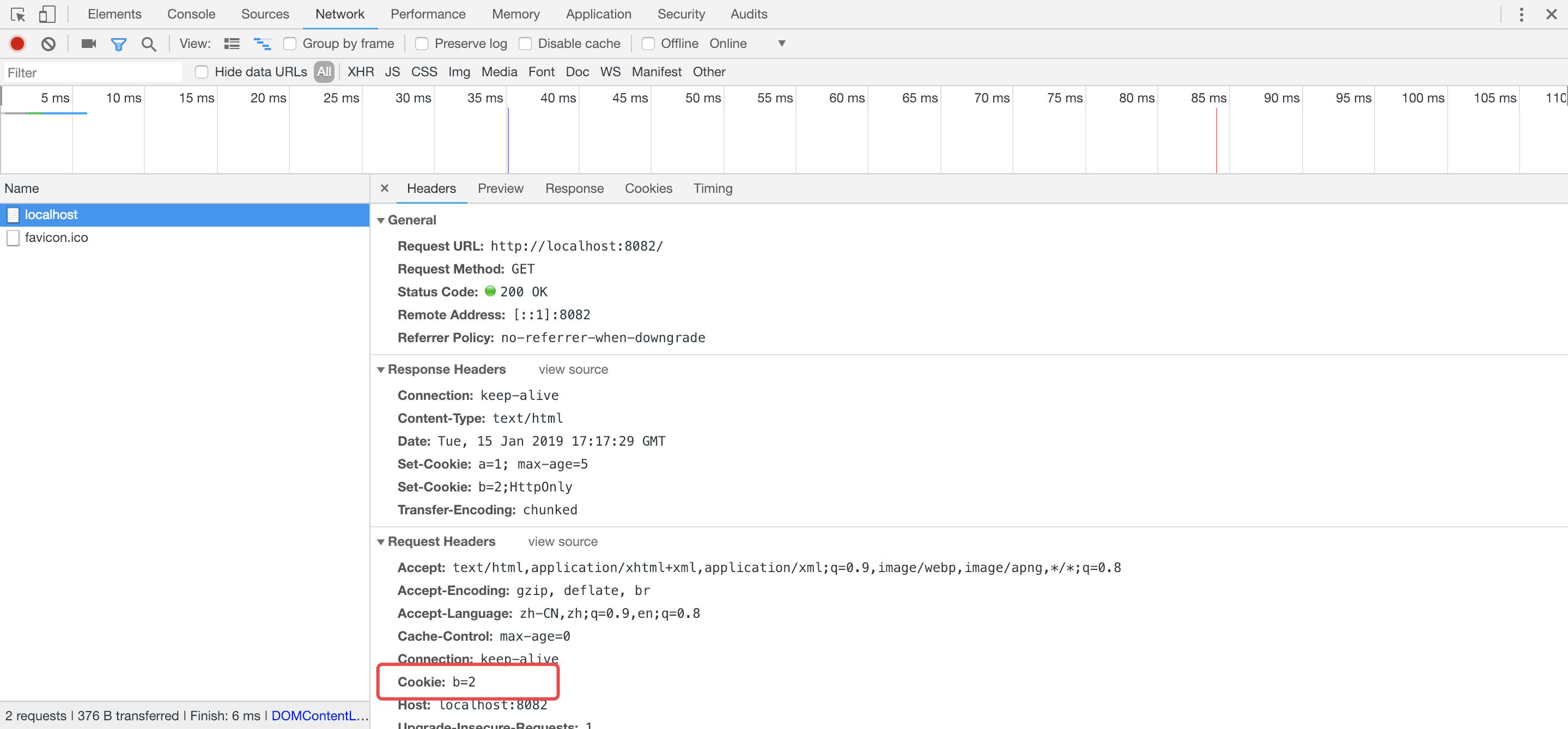
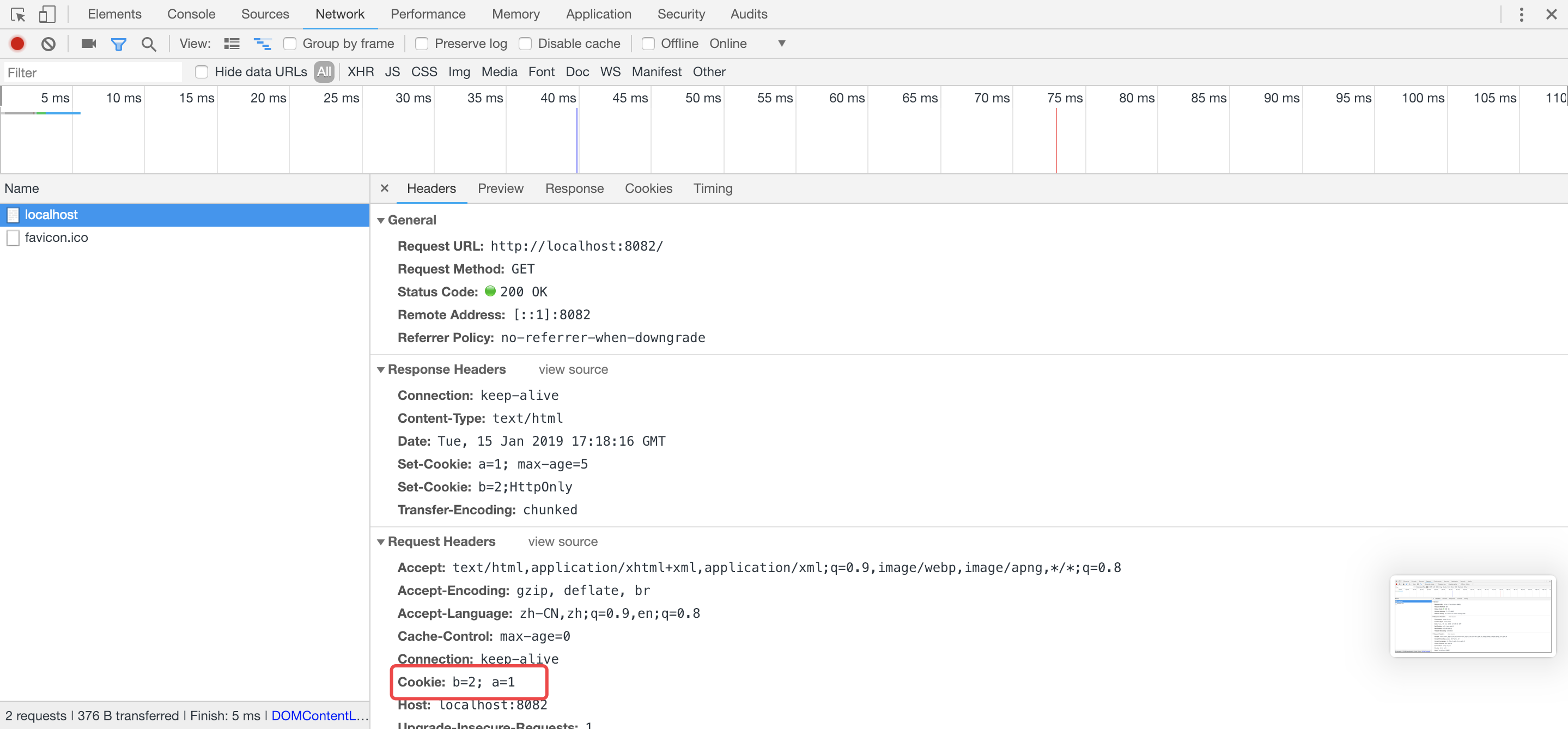
在5秒内发送二次请求,cookie a=1没有失效,在请求头中cookie a=1;b=2都会发送到服务器
另外对于cookie的其他设置如expires、domain等在这里也不多做介绍了
4. 重定向
当服务端返回301、302、307等状态码都代表资源已经被重定向到其他位置,301表示永久改变URI,302和307表示临时重定向到某个URI
本例举一个服务器返回302状态码的例子,直接上代码:
// server.js
const http = require('http');
const fs = require('fs')
http.createServer((req, res) => {
if (req.url === '/') {
res.writeHead(302, {
'Location': '/redirect'
})
res.end()
}
if (req.url === '/redirect') {
res.end('redirect')
}
}).listen(8082);
访问localhost:8082, 服务器返回302状态码时,在相应头中设置Location首部字段,浏览器会继续发送请求到重定向的地址
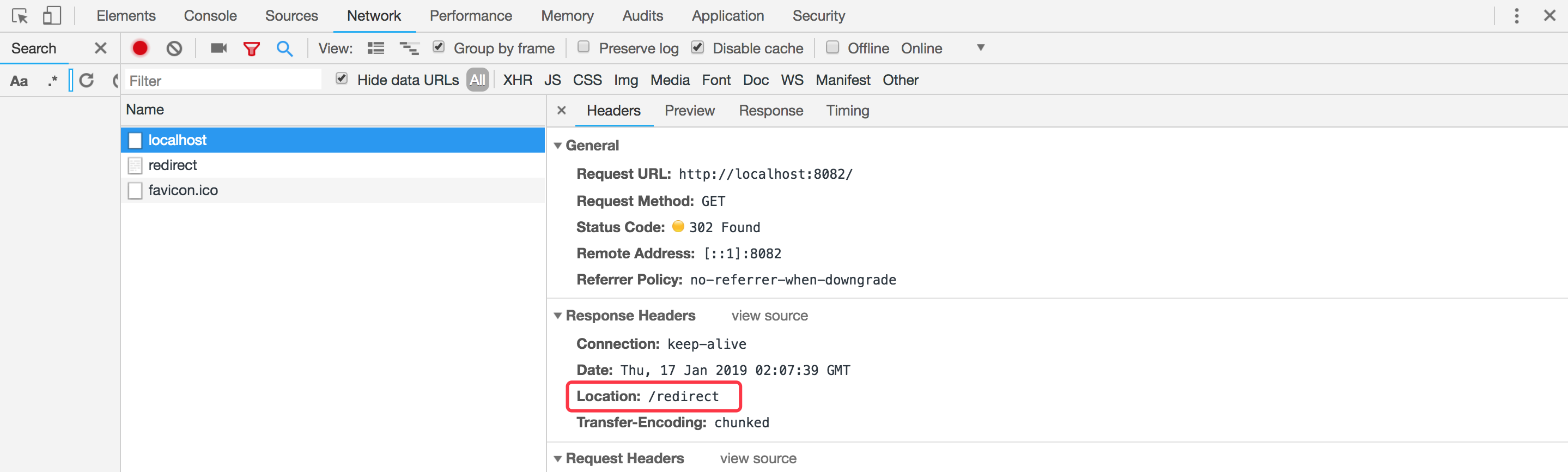

HTTP与HTTPS的区别
首先说一下什么是HTTPS
HTTPS(全称:Hyper Text Transfer Protocol over Secure Socket Layer 或 Hypertext Transfer Protocol Secure,超文本传输安全协议),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。 --百度百科
HTTPS = HTTP+ 加密 + 认证 + 完整性保护
最主要是在应用层和传输层中间加了一个SSL(安全套阶层),通常,HTTP 直接和 TCP 通信。当使用 SSL 时,则演变成先和 SSL 通信,再由 SSL 和 TCP 通信。
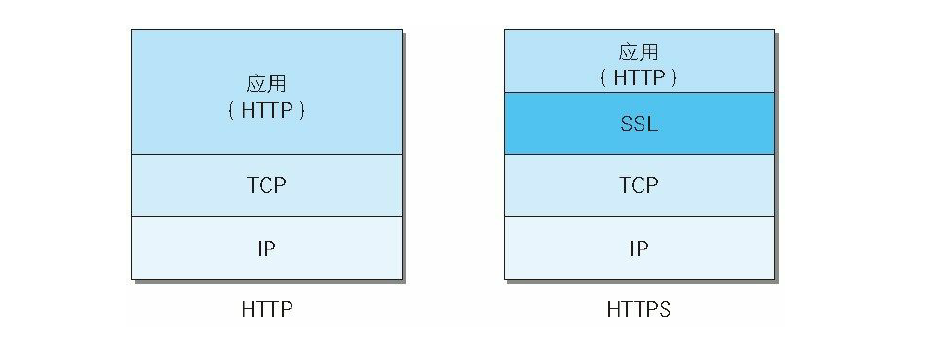
HTTP与HTTPS的区别:
-
(1) HTTP是明文传输,HTTPS是经过SSL加密后进行传输,只有客户端和服务端根据公钥和私钥进行加密和解密能看到,中间任何传输环节无法获取传输信息,所以HTTPS比HTTP安全
-
(2) HTTPS需要到数字证书认证机构进行购买
-
(3) HTTP服务器默认端口是80,HTTPS服务器默认端口是443
本文主要介绍HTTP,关于HTTPS主要就介绍这么多吧。
HTTP2
本想说点HTTP2的知识,奈何自己是小白,放个百度百科的链接吧 HTTP2。
等后续随着不断的学习,再回来更新本文。
另外放一个HTTP1.1与HTTP2请求与相应对比的demo的链接HTTP/2 is the future of the Web, and it is here!
最后,本文主要介绍了一些HTTP在web开发中的基础知识,关于概念和图解流程的截图基本上都是来自《TCP/IP详解 卷1:协议》、《图解HTTP》、《HTTP权威指南》,可放心参考。笔者功力实在有限,如有问题,请大家多多指出,相互学习和进步,也希望通过我的学习与实践过程,整理出的笔记能对大家有所帮助,谢谢。
本文参考链接: