The Quora dataset consists of over 400,000 lines of potential question duplicate pairs. Each line contains IDs for each question in the pair, the full text for each question, and a binary value that indicates whether the line truly contains a duplicate pair. Here are a few sample lines of the dataset:

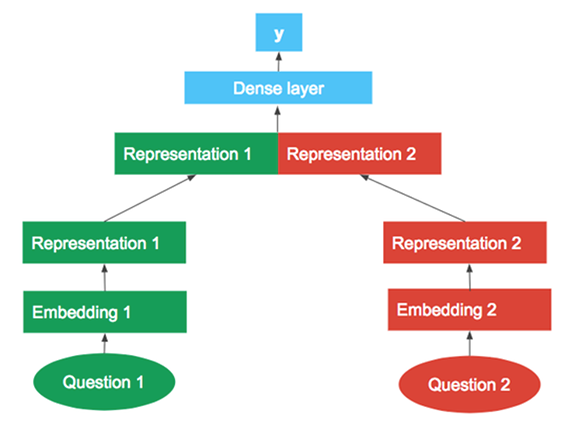
A deep-learning (LSTM) approach is being used here. First of all, a pre-trained GoogleNews word embeddings is used to generate question embeddings for the two questions, and then fed those question embeddings into a representation layer. Then concatenate the two vector representation outputs from the representation layers and fed the concatenated vector into a dense layer to produce the final classification outcome. Here's a graphical representation of this approach: