DataComp-LM (DCLM) is a comprehensive framework designed for building and training large language models (LLMs) with diverse datasets. It offers a standardized corpus of over 300T unfiltered tokens from CommonCrawl, effective pretraining recipes based on the open_lm framework, and an extensive suite of over 50 evaluations. This repository provides tools and guidelines for processing raw data, tokenizing, shuffling, training models, and evaluating their performance.
DCLM enables researchers to experiment with various dataset construction strategies across different compute scales, from 411M to 7B parameter models. Our baseline experiments show significant improvements in model performance through optimized dataset design.
Already, DCLM has enabled the creation of several high quality datasets that perform well across scales and outperform all open datasets.

Developing datasets for better models that are cheaper to train. Using DataComp-LM, we develop a high-quality dataset, DCLM-BASELINE, which we use to train models with strong compute performance tradeoffs. We compare on both a Core set of tasks (left) and on MMLU 5-shot (right). DCLM-BASELINE (orange) shows favorable performance relative to both close-source models (crosses) and other open-source datasets and models (circles).
Submission workflow:
-
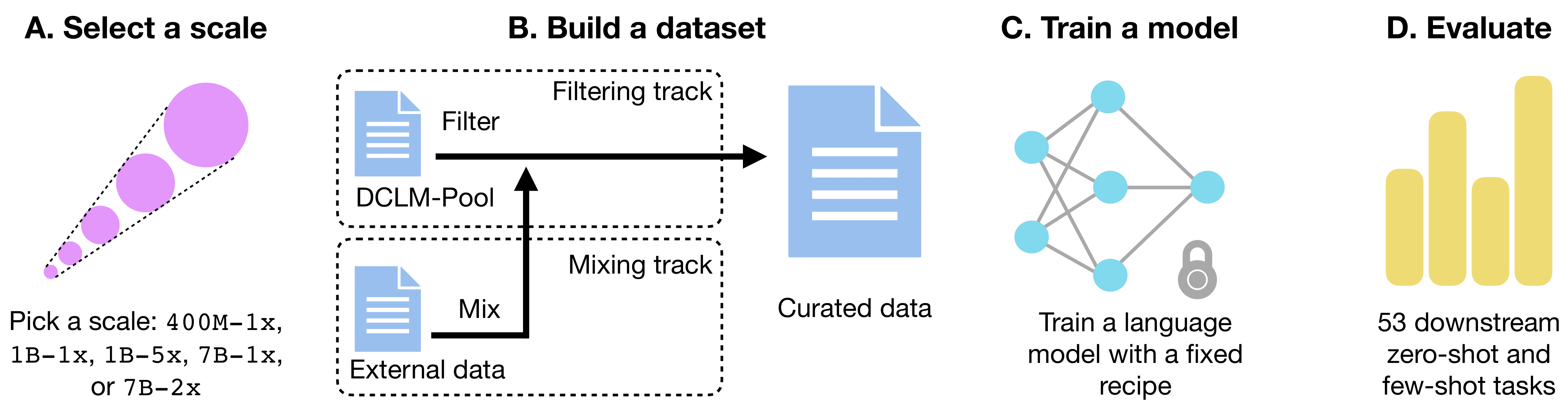
(A) A participant chooses a scale, where larger scales reflect more target training tokens and/or model parameters. The smallest scale is 400m-1x, a 400m parameter model trained compute optimally (1x), and the largest scale is 7B-2x, a 7B parameter model trained with twice the tokens required for compute optimallity.
-
(B) A participant filters a pool of data (filtering track) or mixes data of their own (bring your own data track) to create a dataset.
-
(C) Using the curated dataset, a participant trains a language model, with standardized training code and scale-specific hyperparameters, which is then
-
(D) evaluated on 53 downstream tasks to judge dataset quality.

For more details, please refer to our paper.
The DCLM leaderboard showcases the performance of models trained on various scales and datasets. The leaderboard is updated regularly with the latest submissions from the community.
Below are comparisions of our model with others in the 7B regime.
| Model | Params | Tokens | Open dataset? | CORE | MMLU | EXTENDED |
|---|---|---|---|---|---|---|
| Open weights, closed datasets | ||||||
| Llama2 | 7B | 2T | ✗ | 49.2 | 45.8 | 34.1 |
| DeepSeek | 7B | 2T | ✗ | 50.7 | 48.5 | 35.3 |
| Mistral-0.3 | 7B | ? | ✗ | 57.0 | 62.7 | 45.1 |
| QWEN-2 | 7B | ? | ✗ | 57.5 | 71.9 | 50.5 |
| Llama3 | 8B | 15T | ✗ | 57.6 | 66.2 | 46.3 |
| Gemma | 8B | 6T | ✗ | 57.8 | 64.3 | 44.6 |
| Phi-3 | 7B | ? | ✗ | 61.0 | 69.9 | 57.9 |
| Open weights, open datasets | ||||||
| Falcon | 7B | 1T | ✓ | 44.1 | 27.4 | 25.1 |
| OLMo-1.7 | 7B | 2.1T | ✓ | 47.0 | 54.0 | 34.2 |
| MAP-Neo | 7B | 4.5T | ✓ | 50.2 | 57.1 | 40.4 |
| Models we trained | ||||||
| FineWeb edu | 7B | 0.14T | ✓ | 38.7 | 26.3 | 22.1 |
| FineWeb edu | 7B | 0.28T | ✓ | 41.9 | 37.3 | 24.5 |
| DCLM-BASELINE | 7B | 0.14T | ✓ | 44.1 | 38.3 | 25.0 |
| DCLM-BASELINE | 7B | 0.28T | ✓ | 48.9 | 50.8 | 31.8 |
| DCLM-BASELINE | 7B | 2.6T | ✓ | 57.1 | 63.7 | 45.4 |
To get started with DCLM, follow these steps:
-
Clone the repository:
git clone https://github.com/mlfoundations/DCLM.git cd DCLM -
Install dependencies:
pip install -r requirements.txt
Before installing the dependencies, make sure cmake, build-essential, and g++ are installed, e.g., by installing:
apt install cmake build-essential apt install g++-9 update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-9 90 ``` -
Set up your environment: DCLM uses AWS for storage and possible as a compute backend, and ray for distributed processing. Ensure you have the necessary environment variables and configurations for AWS and Ray clusters.
We recommend the use of Python 3.10 with DCLM.
If you are creating a new source:
- Ensure your data is stored in JSONL format (ideally compressed with zstandard).
- Key names should be consistent with those in here.
- Create a reference JSON in exp_data/datasets/raw_sources.
If you are selecting a raw source for downstream processing:
- Identify the raw source you intend to use, which corresponds to a dataset reference (i.e., a JSON in raw_sources.
- The reference JSON contains the URL to the actual data and other metadata used as input for downstream processing.
To process raw data, follow these steps:
-
Define a set of processing steps: Create a pipeline config YAML file specifying the operations. See our reproduction of C4 for example. Further details on defining a pipeline can be found here.
-
Set up a Ray cluster: The data processing script relies on Ray for distributed processing of data. This cluster can be either launched on a single node (for small scale data processing) or using AWS EC2 instances.
To launch a local cluster, use the following command:
ray start --head --port 6379
To launch a cluster using AWS EC2 instances, use the following:
ray up <your_cluster_config>
where
<your_cluster_config>is a cluster configuration script that depends on your specific use case. We invite the reader to go over the Ray documentation for instructions on how to create this config file.Important: When using EC2 instances, make sure to tear down your cluster after your job finishes, so as to not incur unnecessary costs!
-
Run the processing script: To run the processing script, in the case of a local cluster, simply run the following command:
python3 ray_processing/process.py --source_ref_paths <source_json> --readable_name <name> --output_dir <s3_output_dir> --config_path <config_yaml> --source_name <source_name>
When using EC2 instances, you need to connect to the cluster and then launch the command
# In your local terminal ray attach <your_cluster_config> # Inside the cluster EC2 instance cd dcnlp export PYTHONPATH=$(pwd) python3 ray_processing/process.py --source_ref_paths <source_json> --readable_name <name> --output_dir <s3_output_dir> --config_path <config_yaml> --source_name <source_name>
-
Monitor and tear down: You can track the progress of data processing via the
global_stats.jsonlfile in the output directory. After the job finishes, you can tear down your cluster viaray stop(in the local cluster case) orray down <your_cluster_config>(in the AWS EC2 case). THIS IS VERY IMPORTANT TO NOT INCUR ADDITIONAL COSTS WHEN USING EC2!
After processing the raw text, you should convert it into tokenized datasets and perform shuffling for training:
-
Set up a Ray cluster: Set up a Ray cluster in the same way as the processing step.
-
Run the tokenize and shuffle script:
python ray_processing/tokenize_shuffle.py --source_ref_paths <source_jsons> --readable_name <name> --output <s3_output_dir> --content_key text --do_sample --default_dataset_yaml <mixing_yaml>
-
Tear down: Tear down the Ray cluster as in the processing step.
The tokenize_shuffle.py script creates a dataset in webdataset format, along with a manifest.jsonl file. This file is required by the training script, and it contains information on the number of sequences inside each shard of the dataset. If needed, this manifest file can also be created manually, via the following command:
python -m open_lm.utils.make_wds_manifest --data-dir <tokenized_data_dir>To train a model using the tokenized dataset:
- Run the training script:
torchrun --nproc-per-node 8 -m training.train --scale <scale> <tokenized_json> --logs <log_dir> [--remote-sync <s3_bucket>] [--chinchilla-multiplier <multiplier>] [--clean-exp] [--report-to-wandb]
You can expect the following training times per track:
| Scale | Model parameters | Train tokens | Train FLOPs | Train H100 hours | Pool size |
|---|---|---|---|---|---|
| 400M-1x | 412M | 8.2B | 2.0e19 | 26 | 137B |
| 1B-1x | 1.4B | 28B | 2.4e20 | 240 | 1.64T |
| 1B-5x | 1.4B | 138B | 1.2e21 | 1200 | 8.20T |
| 7B-1x | 6.9B | 138B | 5.7e21 | 3700 | 7.85T |
| 7B-2x | 6.9B | 276B | 1.1e22 | 7300 | 15.7T |
- Monitor and manage your training jobs: Use slurm sbatch scripts or Sagemaker for running experiments on various compute infrastructures.
Evaluate trained models using the following methods:
-
Preferred Method:
python tools/eval_expdb.py --start_idx 0 --end_idx 3 --filters name=<filter> --prefix_replacement <prefix_replacement> --num_gpus 8 --output_dir <s3_output_dir> --eval_yaml <eval_yaml>
-
Direct Evaluation:
torchrun --nproc_per_node <num_gpus> eval/eval_openlm_ckpt.py --checkpoint <checkpoint> --eval-yaml <eval_yaml> --config <model_params_file> --model <open_lm_config> --output-file <output_file_path>
When you finished training and evaluating your model, a model eval json file has been generated and is at exp_data/evals. You can now open a pull request to the main repository to share your results with the team and submit it to the leaderboard.
We welcome contributions to improve the DCLM framework. Please follow our contributing guide for submitting pull requests and reporting issues.
If you use our dataset or models in your research, please cite us as follows:
@article{li2024datacomplm,
title={DataComp-LM: In search of the next generation of training sets for language models},
author={Jeffrey Li and Alex Fang and Georgios Smyrnis and Maor Ivgi and Matt Jordan and Samir Gadre and Hritik Bansal and Etash Guha and Sedrick Keh and Kushal Arora and Saurabh Garg and Rui Xin and Niklas Muennighoff and Reinhard Heckel and Jean Mercat and Mayee Chen and Suchin Gururangan and Mitchell Wortsman and Alon Albalak and Yonatan Bitton and Marianna Nezhurina and Amro Abbas and Cheng-Yu Hsieh and Dhruba Ghosh and Josh Gardner and Maciej Kilian and Hanlin Zhang and Rulin Shao and Sarah Pratt and Sunny Sanyal and Gabriel Ilharco and Giannis Daras and Kalyani Marathe and Aaron Gokaslan and Jieyu Zhang and Khyathi Chandu and Thao Nguyen and Igor Vasiljevic and Sham Kakade and Shuran Song and Sujay Sanghavi and Fartash Faghri and Sewoong Oh and Luke Zettlemoyer and Kyle Lo and Alaaeldin El-Nouby and Hadi Pouransari and Alexander Toshev and Stephanie Wang and Dirk Groeneveld and Luca Soldaini and Pang Wei Koh and Jenia Jitsev and Thomas Kollar and Alexandros G. Dimakis and Yair Carmon and Achal Dave and Ludwig Schmidt and Vaishaal Shankar},
year={2024},
journal={arXiv preprint arXiv:2406.11794}
}This project is licensed under the MIT License. See the license file for details.