En primer lugar creamos una librería y cargamos el conjunto de datos
*conexion de libreria;
libname lib_prac '/home/u38080140/ivanrubiomoreno/Practica';
* Cargamos el dataset ;
* Tenemos 50000 observations and 10 variables.
data bweight;
set lib_prac.bweight;
run;Vemos que el conjunto de datos secompone de 50.000 obsevaciones y 10 variables.
La variable objetivo de denomina weight. Vamos a analizar el contenido de esta variable mediante una tabla de frecuencias.
proc freq data=bweight;
tables weight;
run;Vemos que los datos están muy repartidos. Hay que analizar si tenemos outlayers. Por suerte vemos que todas las filas tienen valor en la variable objetivo.
Vamos a mostrar un gráfico de barras para ver como se reparten los datos.
proc gchart data=bweight;
vbar weight / type = freq;
run;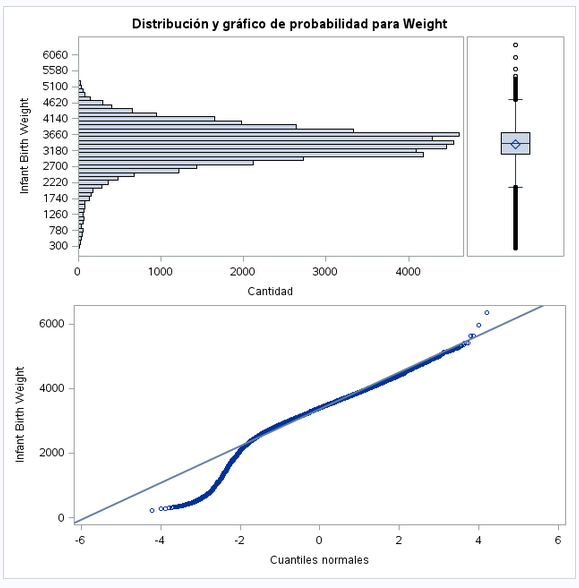
Podemos observar que los datossiguen una distribución normal. Parece lógico que la mayoría de bebes al nacer tengan un peso que similar. En los extremos estarán, por ejemplo, nacimientos de bebes prematuros.
Vamos a hacer un poco de limpieza eliminando las observaciones duplicadas:
proc sort nodupkey data= bweight;
by _all_;
run;Después de hacer limpieza nos quedamos con 48734 y 10 variables.
Ya tenemos analizada nuestra variable objetivo. Hemos visto que es de tipo numérico, por lo que no tenemos que hacerla numérica y que tiene una distribución normal.
Vamos analizar la variables independientes. En primer lugar vamos a sacar una tabla con las medias de las variables numéricas:
proc means data=bweight;
var _numeric_;
run;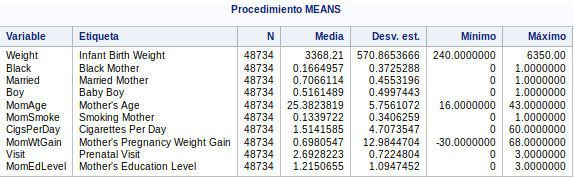
Vemos que ninguna variable tiene valores "missing". Todas tienen 48734 valores. Vemos que la desviación estandar no tiene valores muy altos (menos en la variableobjetivo).
Lo siguiente que hacemos es un TTest con la opción de gráficos activada:
ods graphics on;
proc ttest data=bweight;
var _numeric_;
run;
ods graphics off; Vamos a analizar la información que nos proporciona SAS:
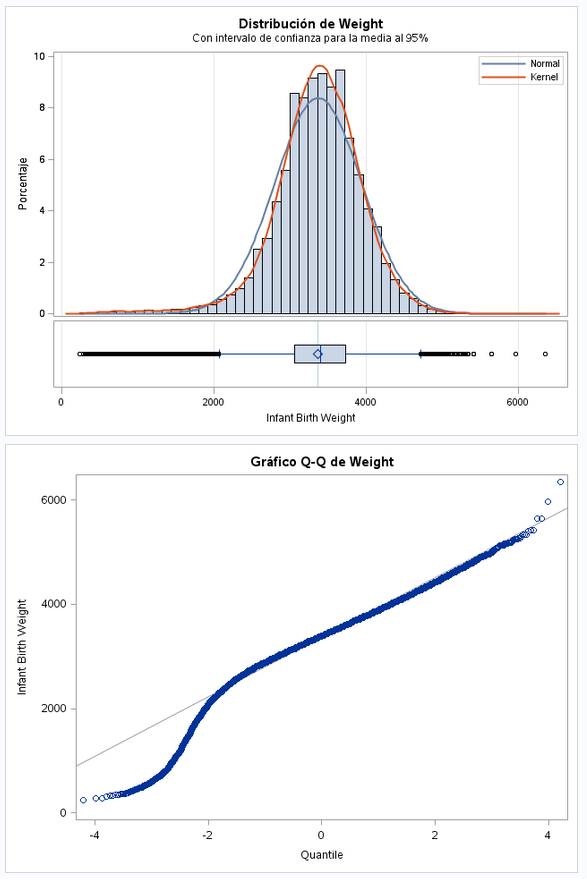
- Como ya hemos visto antes, el peso sigue una distribución normal.
- La distribución estandar está muy alejada de la media.
- Hay outliers por arriba y por abajo.
- La mayoría de los datos siguen la recta Q-Q. Los valores más bajos son los que salen más desviados. Habŕia que averiguar si además de nacimientos también se han incluido abortos. En esos casos es posible que los fetos al no estar desarrollados arrojen estos datos que se devían del resto.
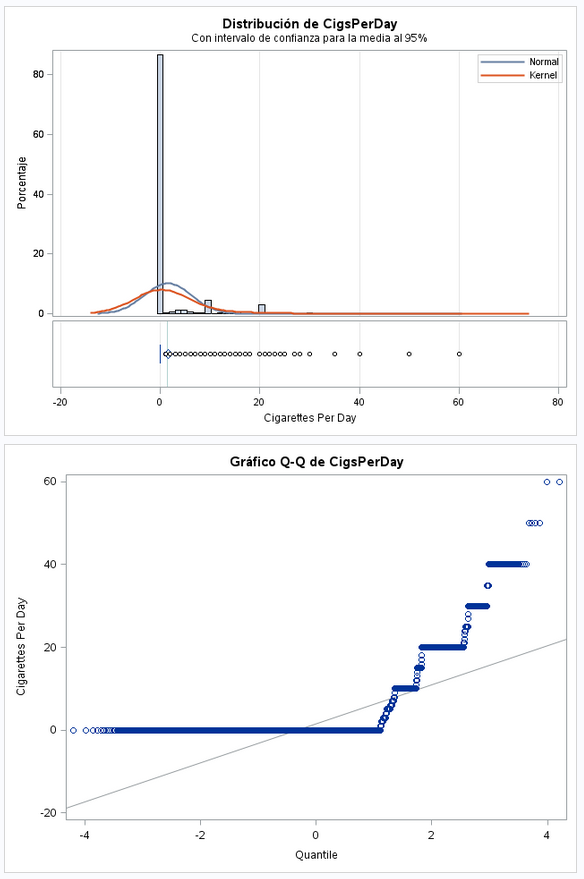
Este es un campo dicotómico. Vemos que hay muchos mas que no son de raza que negra que los que si.
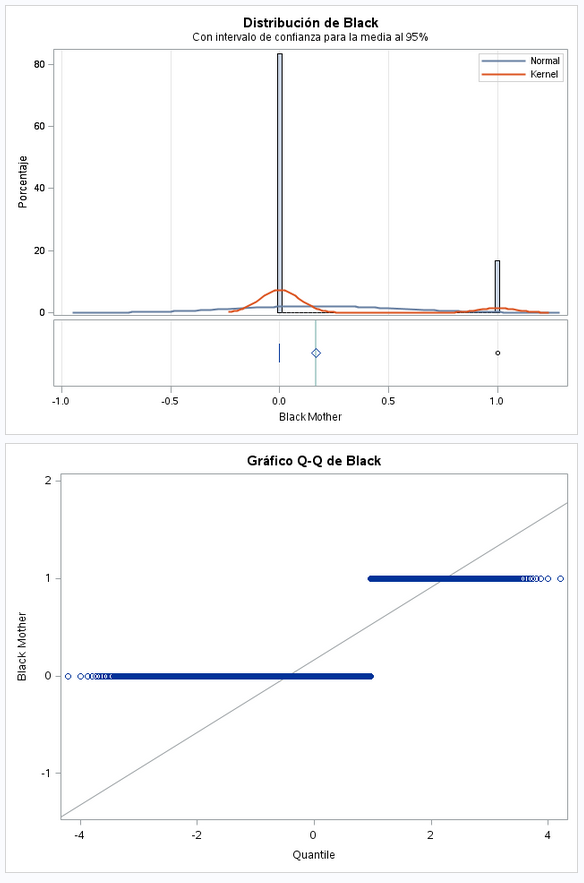
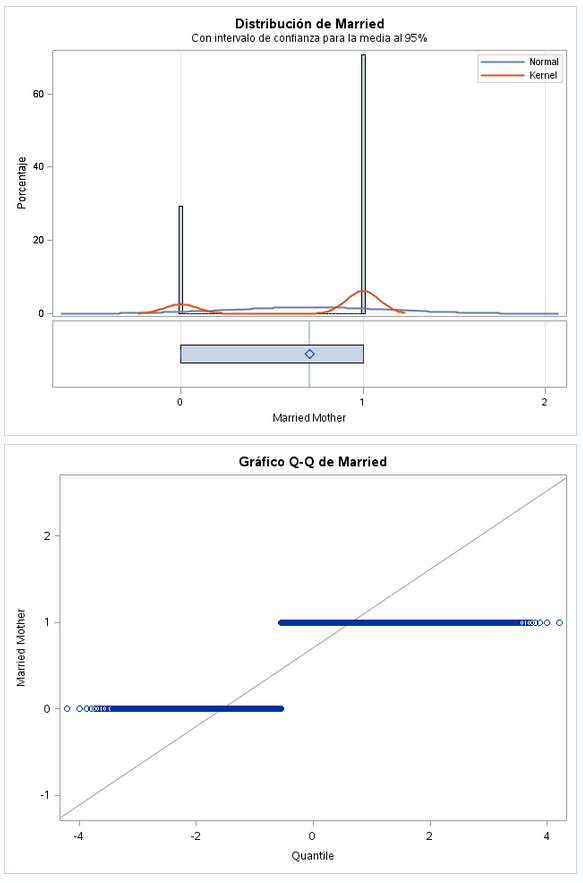
También es una variable dicotómica. En este caso vemos que hay más nacimientos de madres casadas que solteras.
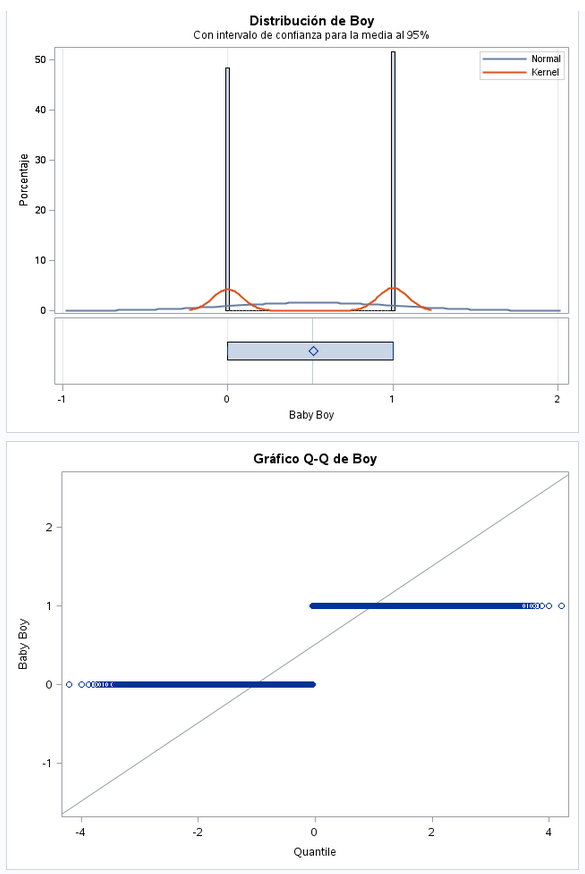
Variable dicotómica. Como se ve en la gráfica, en la media y la desviación estandar los valores está muy repartidos.
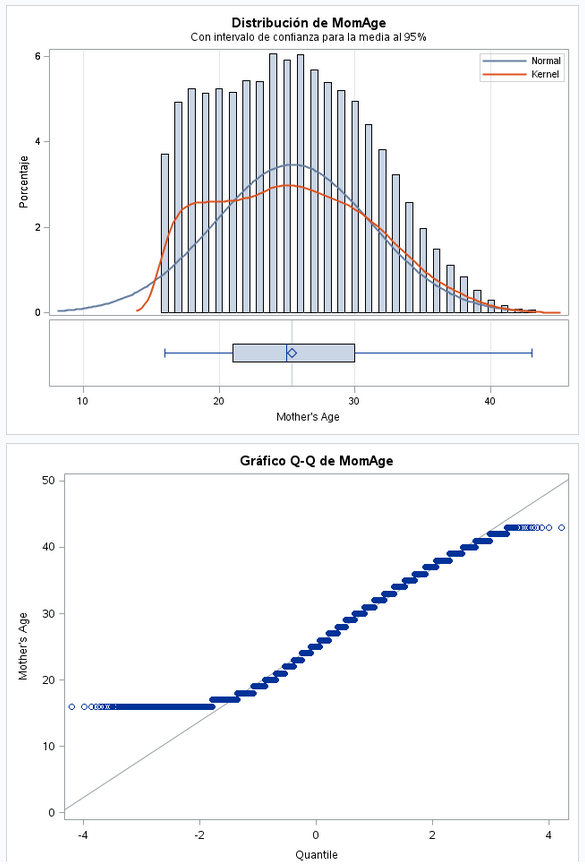
El campo MomAge tiene la edad de la madre, pero los valores no son la edad real. Los valores van a escala. 0 indica que tiene 25 años. Si tiene menos de 25 tiene valores negativos y si tiene mas de 25 años tiene valores positivos. Vamos a sumar 25 al campo MomAge para tener los valores reales de edad y con ese campo cambiado volvemos a ejecutar el TTest:
data bweight;
set bweight;
MomAge = MomAge + 25;
run;Los datos se desvian un poco de una distribución normal. El valor mínimo es 16 años y el máximo 43 años. Es lógico que no haya datos de edades muy bajos y muy altos.
Variable dicotómica. Vemos que hay muchas menos madres fumadoras que no fumadoras.
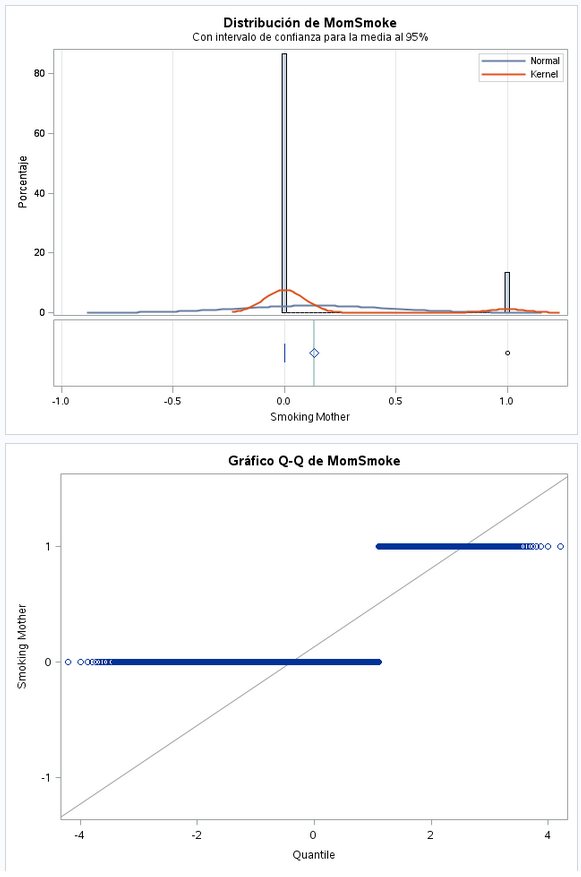
Lógicamente, al haber muchas menos madres no fumadoras es normal que el valor que más se repita sea el 0.