多种 OCR 引擎结果评估后处理
wanghaisheng opened this issue · 2 comments
Process, enhance and evaluate multiple ocr-ouput.
https://github.com/UB-Mannheim/ocromore
-
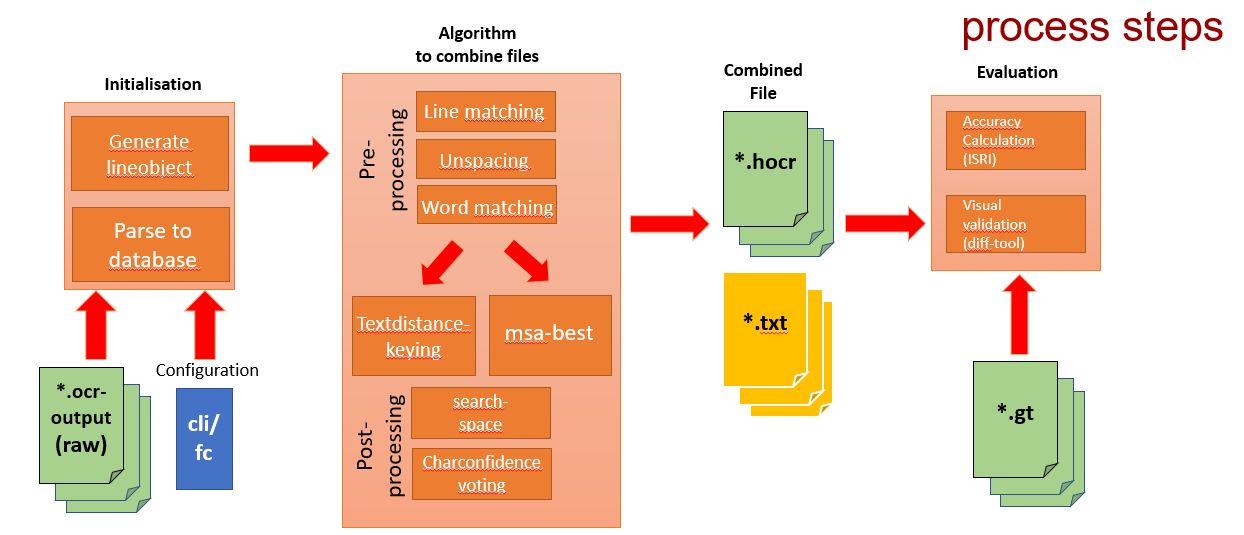
Parsing all ocr-outputfiles to an database
(This step only has to be done once) -
Pre-process the gathered information
The results from the following processes can also
be stored directly to the database- Line-matching all files
- Unspacing words in each file
Unspacing means to delete whitespaces in spaced text
(E.g. H e l l o => Hello) - Word-matching all files per line
-
Combine file information
- Different compare methods
- Textdistance-Keying
- Levenshtein
- Damerau-Levenshtein
- ...
- Multi-Sequence-Alignment (MSA)
- pivot-based
- linewise/wordwise
- Adjustable search-space-processor correction
- Matching similar character
- Whitespace/Wildcard improvements
- Adjustable decision parameter
- Char confidence
- Best-of-n
- Textdistance-Keying
- Different compare methods
-
The output can be stored in the database and/or
as *.txt or *.hocr. -
Evaluate the output against groundtruth files or each other and generate a accuracy report.
Or compare the files visual via diff-tools.
https://github.com/KBNLresearch/ochre
Ochre
Ochre is a toolbox for OCR post-correction.
Overview of OCR post-correction data sets
Preprocess data sets
Train character-based language models/LSTMs for OCR post-correction
Do the post-correction
Assess the performance of OCR post-correction
Analyze OCR errors
Ochre contains ready-to-use data processing workflows (based on CWL). The software also allows you to create your own (OCR post-correction related) workflows. Examples of how to create these can be found in the notebooks directory (to be able to use those, make sure you have Jupyter Notebooks installed). This directory also contains notebooks that show how results can be analyzed and visualized.