从 Turborepo 看 Monorepo 工具的任务编排能力
worldzhao opened this issue · 5 comments
本文大部分图片来自互联网
前言
2021 年 12 月 9 号,Vercel 的官方博客上发布了一篇名为 Vercel acquires Turborepo to accelerate build speed and improve developer experience 的博文,正如其标题所说,Vercel 收购了 Turborepo,以加速构建速度以及提高开发体验。

Turborepo 是一个用于 JavaScript 和 TypeScript 代码库的高性能构建系统。通过增量构建、智能远程缓存和优化的任务调度,Turborepo 可以将构建速度提高 85% 或更多,使各种规模的团队都能够维护一个快速有效的构建系统,该系统可以随着代码库和团队的成长而扩展。
博文中已经简明扼要的突出了 Turborepo 的优势,本文则会从现有的实际场景出发,谈谈大型代码仓库(Monorepo)可能会遇到的一些问题,再结合业界现有的解决方案,看看 Turborepo 在任务编排方面做出了哪些创新与突破。
一个合格 Monorepo 的自我修养
随着业务的发展和团队的变化,业务型 Monorepo 中的项目会逐渐增加,极端一点的例子就是 Google 将整个公司的代码都放到一个仓库中,仓库的大小达到了 80TB。
业务型 Monorepo:不同于 lib 型 Monorepo(React、Vue3、Next.js 以及 Babel 等广义上的 packages),业务型 Monorepo 将多个业务应用 App 及其依赖的公用组件库或工具库组织到了一个仓库中。 ——《Eden Monorepo 系列:浅析 Eden Monorepo 工程化建设》
项目数量的增加意味着在享受 Monorepo 优势的同时,也带来了巨大的挑战,优秀的 Monorepo 工具可以让开发者毫无负担的享受 Monorepo 的优势,而不好用的 Monorepo 工具可以让开发者痛不欲生,甚至让人怀疑 Monorepo 存在的意义。
列举笔者遇到的一些实际场景:
- 依赖版本冲突
- 新建一个项目,该项目由于依赖问题无法启动
- 新建一个项目,其他项目由于依赖问题无法启动
- 依赖安装速度慢
- 初始化安装依赖 20min+
- 新增一个依赖 3min+
- build/test/lint 等任务执行慢
笔者先前有过 Rush 的落地经验,在实践过程中,发现除了最基本的代码共享能力外,还应当至少具备三种能力,即:
- 依赖管理能力。随着依赖数量的增加,依旧能够保持依赖结构的正确性、稳定性以及安装效率。
- 任务编排能力。能够以最大的效率以及正确的顺序执行 Monorepo 内项目的任务(可以狭义理解为 npm scripts,如 build、test 以及 lint 等),且复杂度不会随着 Monorepo 内项目增多而增加。
- 版本发布能力。能够基于改动的项目,结合项目依赖关系,正确地进行版本号变更、CHANGELOG 生成以及项目发布。
一些流行工具的支持能力如下表所示:
| - | 依赖管理 | 任务编排 | 版本管理 |
|---|---|---|---|
| Pnpm Workspace | |||
| Rush | |||
| Lage | |||
| Turborepo | |||
| Lerna |
- Pnpm:Pnpm 具备一定的任务编排能力 (
--filter参数),故此处也将其列入,同时作为 Package Manager,其自身更是大型 Monorepo 不可或缺的一部分。 - Rush:由微软开源的可扩展 Monorepo 管理方案,内置 PNPM 以及类 Changesets 发包方案,其插件机制是一大亮点,使得利用 Rush 内置能力实现自定义功能变得极为方便,迈出了 Rush 插件生态圈的第一步。
- Lage :同样由微软开源,个人认为是 Turborepo 的前身,Turborepo 是 Lage 的 Go 语言版本。Lage 自称为 "Monorepo Task Runner",相较于 Turborepo 的 "High-Performance Build System" 内敛许多,Star 数也相差了一个数量级(Lage 300+,而 Turborepo 5k+),更多可查看该 PR。在后文中 Lage 等同于 Turborepo。
- Lerna:已经基本停止维护,故后续讨论不会将其纳入。
依赖管理过于底层,版本控制较为简单且已成熟,将这两项能力再做突破是比较困难的,实践中基本都是结合 Pnpm 以及 Changesets 补全整体能力,甚至就干脆专精于一点,即任务编排,也就是 Lage 以及 Turborepo 的发力点。

如何选择合适自己的 Monorepo 工具链?
- Pnpm Workspace + Changesets:成本低,满足大多数场景
- Pnpm Workspace + Changesets + Turborepo/Lage:在 1 的基础上增强任务编排能力
- Rush:考虑全面,扩展性强
任务编排可以划分为三个步骤,各工具支持如下:
| 范围界定 | 并行执行 | 云端缓存 | |
|---|---|---|---|
| Pnpm | |||
| Rush | |||
| Turborepo/Lage |
范围界定:按需执行子集任务
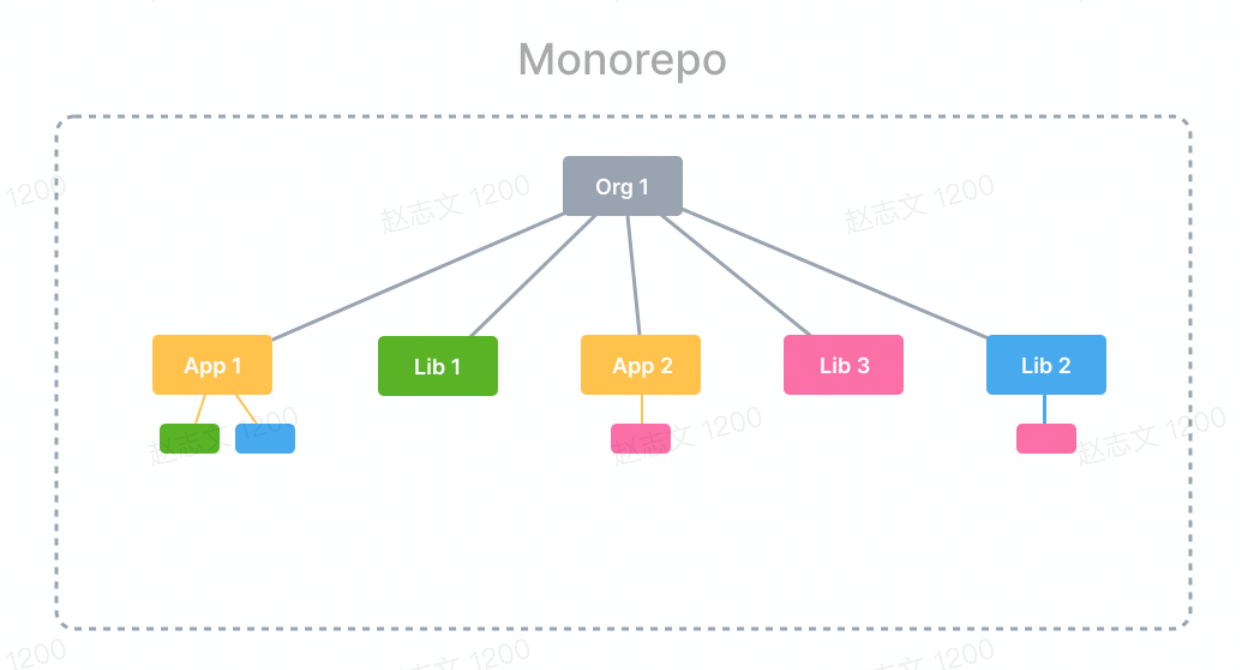
该能力在日常开发中具有丰富的使用场景。
例如第一次拉取仓库,启动项目 app1 需要构建 Monorepo 内 app1 的前置依赖 package1 以及 package2。
打包项目 app1 时,需要构建 app1 自身以及 Monorepo 内 app1 的前置依赖 package1 以及 package2。
此时则应该根据需要筛选出需要构建的项目,而不应该引入与当前意图无关的项目构建。
在不同的 Monorepo 工具中,这一行为有着不同的称呼:
- Rush 中称之为 Selecting subsets of projects,选择项目子集,在本示例中应当使用如下命令:
// 本地启动 app1 开发模式,app1 为依赖图的顶端,但不需要构建 app1 自身
$ rush build --to-except @monorepo/app1
// SCM 打包 app1,app1 为依赖图的顶端,且需要构建 @monorepo/app1 自身
$ rush build --to @monorepo/app1- Pnpm 中称之为 Filtering,即过滤,将命令限制于包的特定子集,在本示例中应当使用如下命令:
// 本地启动 app1 开发模式,app1 为依赖图的顶端,但不需要构建 app1 自身
$ pnpm build --filter @monorepo/app1^...
// SCM 打包 app1,app1 为依赖图的顶端,且需要构建 @monorepo/app1 自身
$ pnpm build --filter @monorepo/app1...- Turborepo/Lage 中称之为Scoped Tasks,但目前(2022/02/13)这一能力过于局限,Vercel 团队正在设计一套与 Pnpm 基本一致的 filter 语法,详情参见 RFC: New Task Filtering Syntax
范围界定保证了执行任务的数量不会随着 Monorepo 内无关项目的增加而增加,丰富的参数能够帮助我们在各种场景(package 发包、app 构建以及 CI 任务)去进行 selecting/filtering/scoping。
比如修改了 package5,在 Merge Request 的 CI 环境需要保证 package5 以及依赖 package5 的项目不会因为本次修改而构建失败,则可以使用以下命令:
// 使用 Rush
$ rush build --to @monorepo/package5 --from @monorepo/package5
// 使用 Pnpm
$ pnpm build --filter ...@monorepo/package5...
在本示例中最终会挑选出 package5 以及 app3 进行构建,从而在 CI 上达到了合入代码的最低要求——不影响其他项目构建。
基于工作区所有项目的 package.json 文件,可以方便地得到项目之间的具体依赖关系,每一个 Project 都知晓其 Dependents 以及 Dependencies,配合开发者传入的参数,从而方便地进行子集项目选择。
并行执行:充分释放机器性能
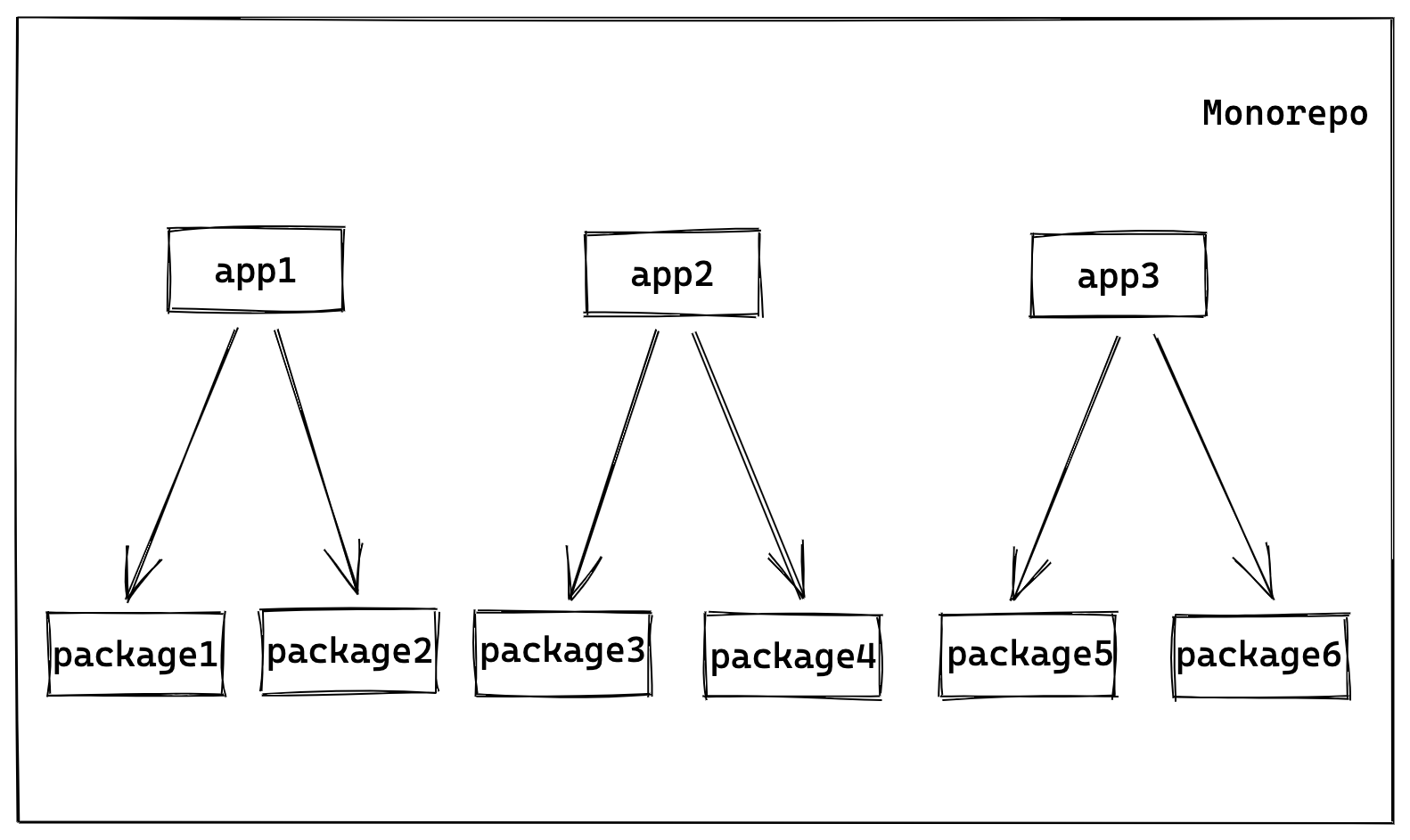
假设挑选出了 20 个子集任务,应该如何执行这 20 个任务来保证正确性以及效率呢?即:
- 正确的对任务进行拓扑排序
- 任务的粒度不是以项目维度,而是对项目下运行的 script 来做更细粒度的编排
Project 之间存在依赖关系,那么任务之间也存在依赖关系,以 build 任务为例,只有前置依赖构建完毕,才可构建当前项目。
网上有一道比较流行的控制最大并发数面试题,大致题意是:给定 m 个 url,每次最大并行请求数为 n,请实现代码保证最大请求数。

这道题的思路其实与任务编排中的任务并行执行大同小异,只不过面试题中的 url 不存在依赖关系,而任务之间存在拓扑序,差别仅此而已。
那么任务的执行思路也就呼之欲出了:
- 初始可执行的任务一定是不存在任何前置任务的任务
- 其 Dependencies 数量为 0
- 一个任务执行完成后,从任务队列中查找下一个可执行的任务,并立刻执行
- 一个任务执行完成后,需要更新其 Dependents 的 Dependencies 数量,从其内移除当前任务(Dependencies 数量 -1)
- 一个任务是否可执行,取决于其 Dependencies 是否全部执行完毕(Dependencies 数量为 0)
本文不作代码层面讲解,具体实现可见 Monorepo 中的任务调度机制 一文,在代码层面上实现了任务的拓扑序并行执行。
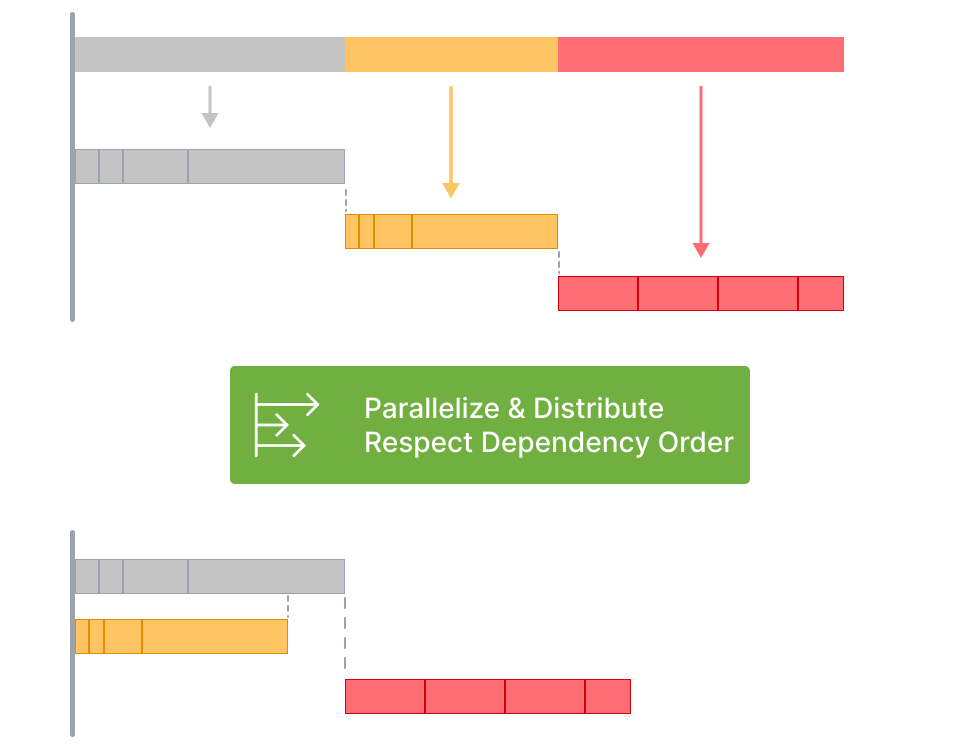
打破任务边界
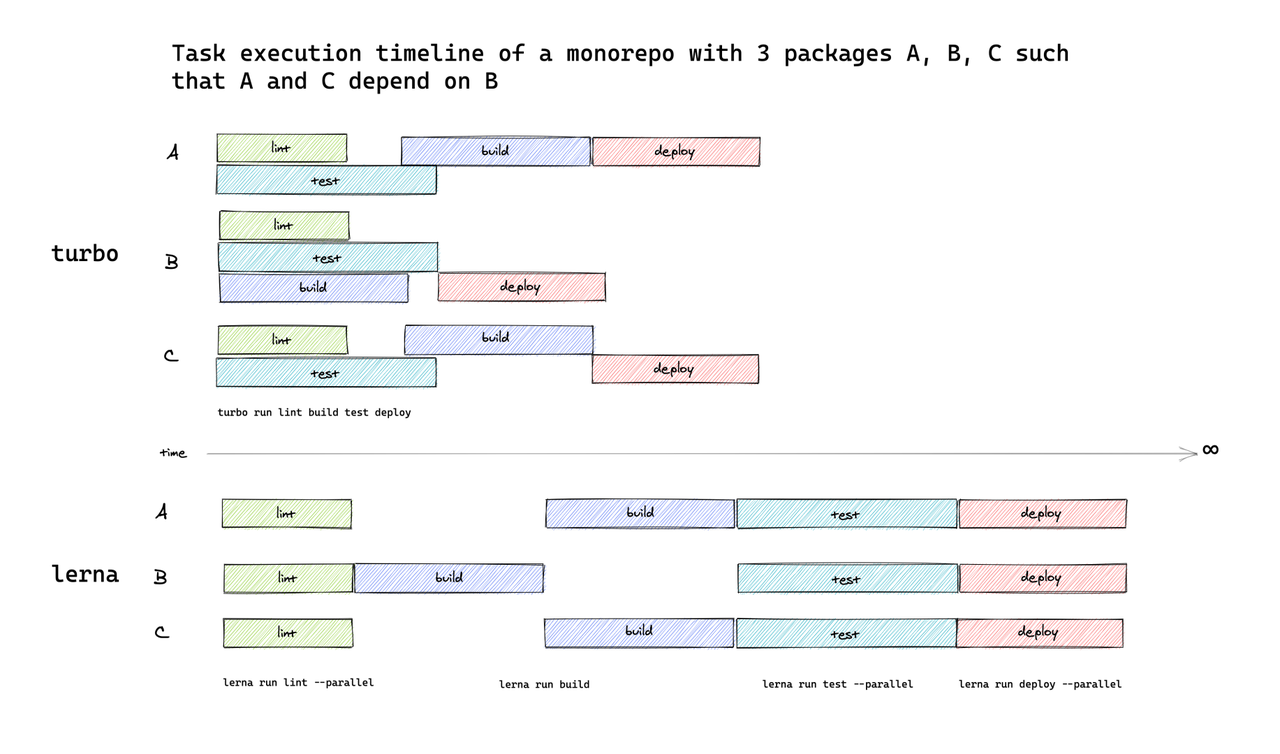
之前谈到任务执行时,都是在同一种任务下,比如 build、lint 或是 test,在并行执行 build 任务时,不会去考虑 lint 或是 test 任务。如上图 Lerna 区域所示,依次执行四种任务,每一种任务都被前一种任务阻塞住了,即使内部是并行执行的,但不同任务之间依旧存在了资源浪费。
Lage/Turborepo 为开发者提供了一套明确任务关系的方法(见 turbo.json),基于该关系,Lage/Turborepo 可以去进行不同种类任务间的调度和优化。
相较于一次只能执行一种任务,重叠瀑布式的任务执行效率当然要高得多。
turbo.json
{
"$schema": "https://turborepo.org/schema.json",
"pipeline": {
"build": {
// 其依赖项构建命令完成后,进行构建
"dependsOn": ["^build"]
},
"test": {
// 自身的构建命令完成后,进行测试(故上图存在错误)
"dependsOn": ["build"]
},
"deploy": {
// 自身 lint 构建测试命令完成后,进行部署
"dependsOn": ["build", "test", "lint"]
},
// 随时可以开始 lint
"lint": {}
}
}正确编排顺序
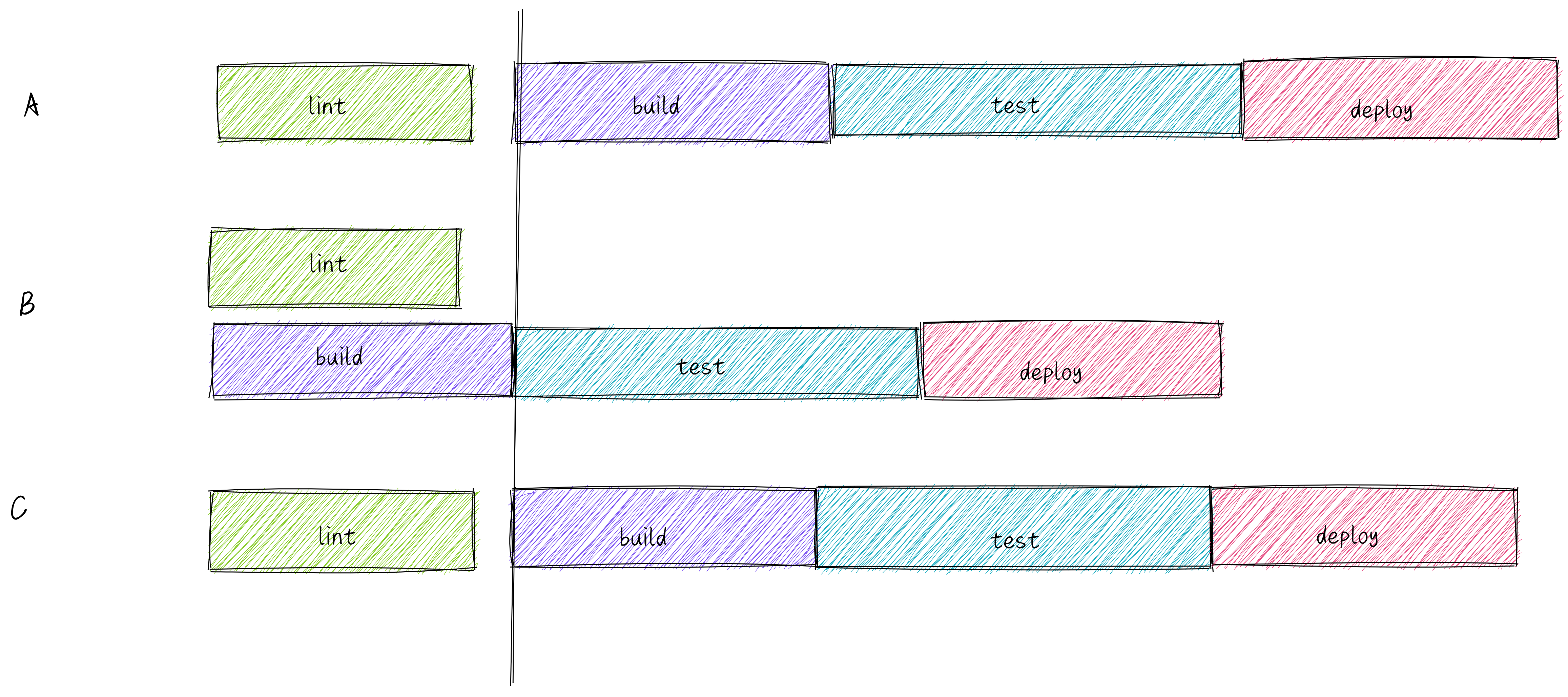
Rush 在 20 年 3 月以及 10 月也进行过相关设计的讨论,并于 21 年年底支持了类似的功能特性,具体 PR 可查阅 [rush] Add support for phased commands. #3113
- Turborepo: Pipelining Package Tasks
- How does lage work?
- [rush] Design proposal: "phased" custom commands #2300
云端缓存:跨多环境复用缓存
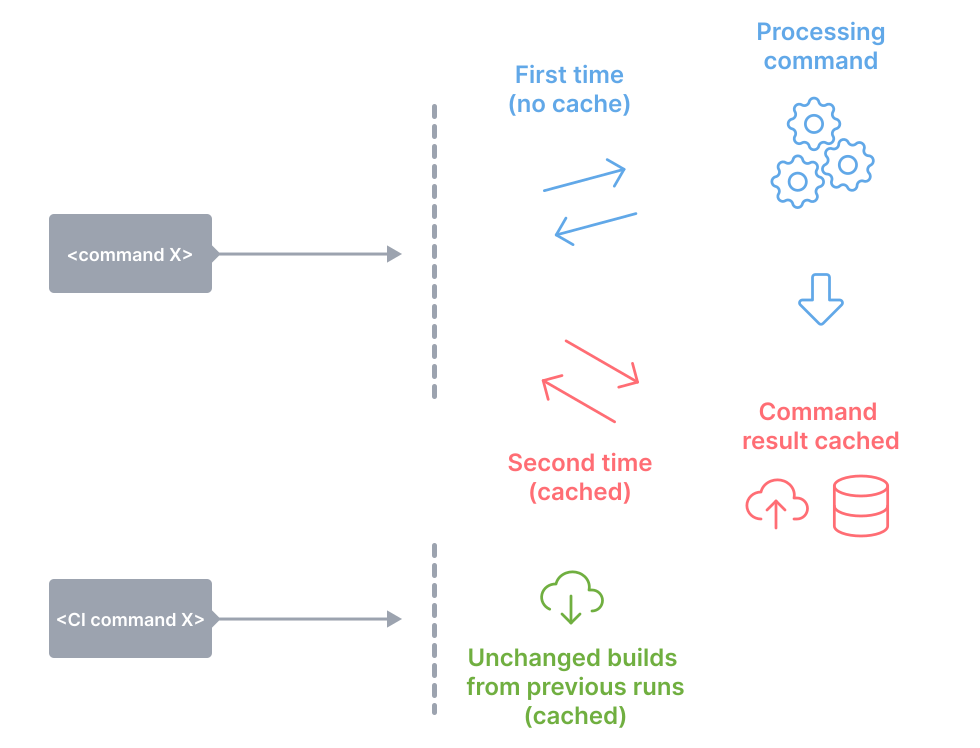
Rush 具备增量构建的特性,使 rush build 能够跳过自上次构建以来输入文件(input files)没有变化的项目,配合第三方存储服务,可以达到跨多环境复用缓存的效果。
Rush 在 5.57.0 版本引入了插件机制 ,进而支持了第三方远端缓存能力(在此之前仅支持 azure 与 amazon)。基于插件机制,可以轻松地将公司内部的存储服务作为云端缓存的存储方案。
落地到日常开发场景中,本地开发、CI 以及 SCM 各开发环节都能从中受益。
上文有提到,在 CI 环节构建改动项目及其上下游项目可以一定程度上保证 Merge Request 的质量。
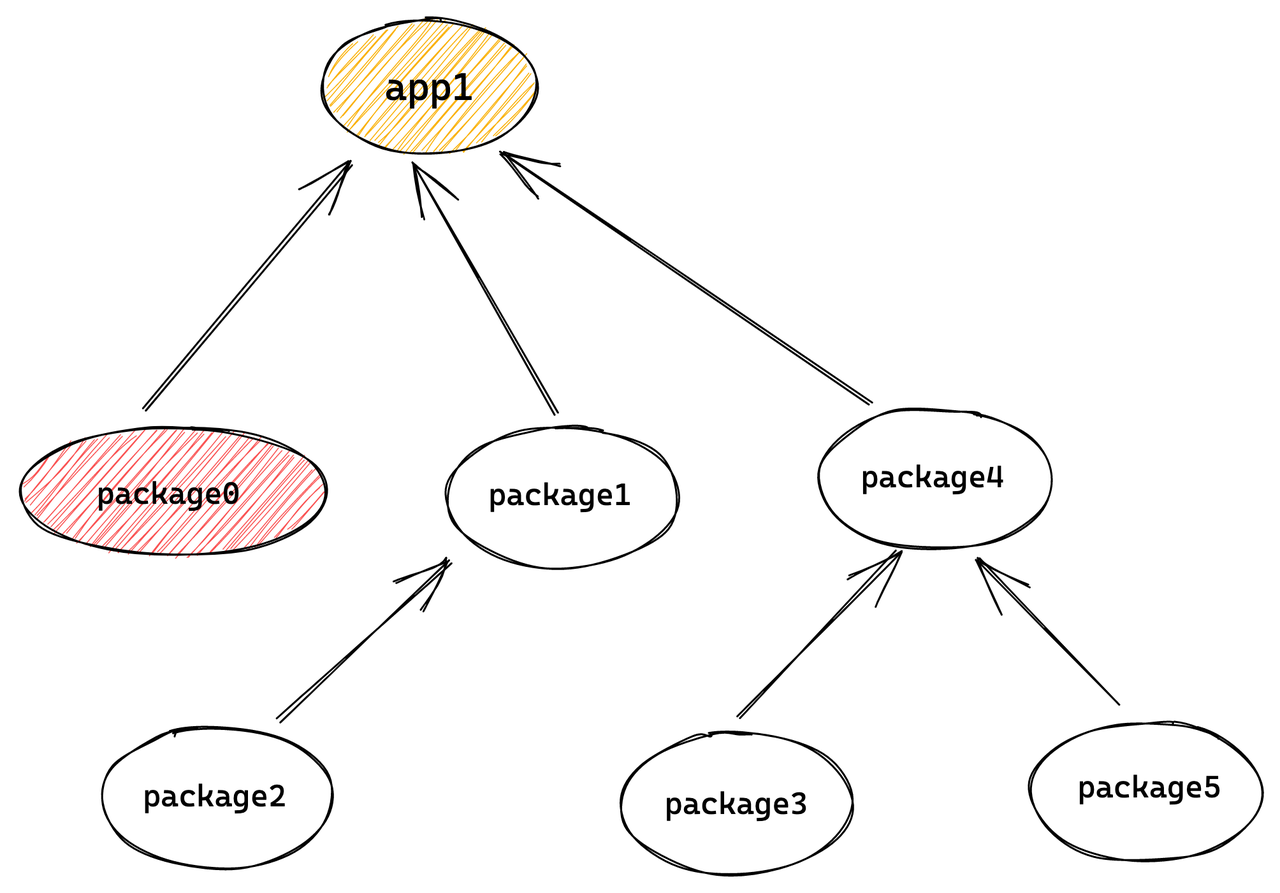
如上图所示,存在场景修改了 package0 的代码,为了保证其上下游构建不被影响,则在 CI Build Changed Projects 阶段,会执行以下命令:
$ rush build --to package0 --from package0基于 git diff 挑选出源文件改动的 projects,此处为 package0
经过范围界定,package0 及其上游 app1 会被纳入构建流程,由于 app1 需要构建,作为其前置依赖,package1 至 package5 也需要被构建,但这 5 个 package 实际上与 package0 并不存在依赖关系,也不存在变更,仅为了完成 app1 的构建准备工作。
若依赖关系复杂起来,比如某个基础包被多个应用引用,那么类似于 package1-package5 的准备构建工作就会大大增多,导致这一阶段 CI 十分缓慢。
实际构建的项目 = 改动项目 + 改动项目的 Dependencies + Dependencies 的依赖 + 改动项目的 Dependents + Dependents 的依赖
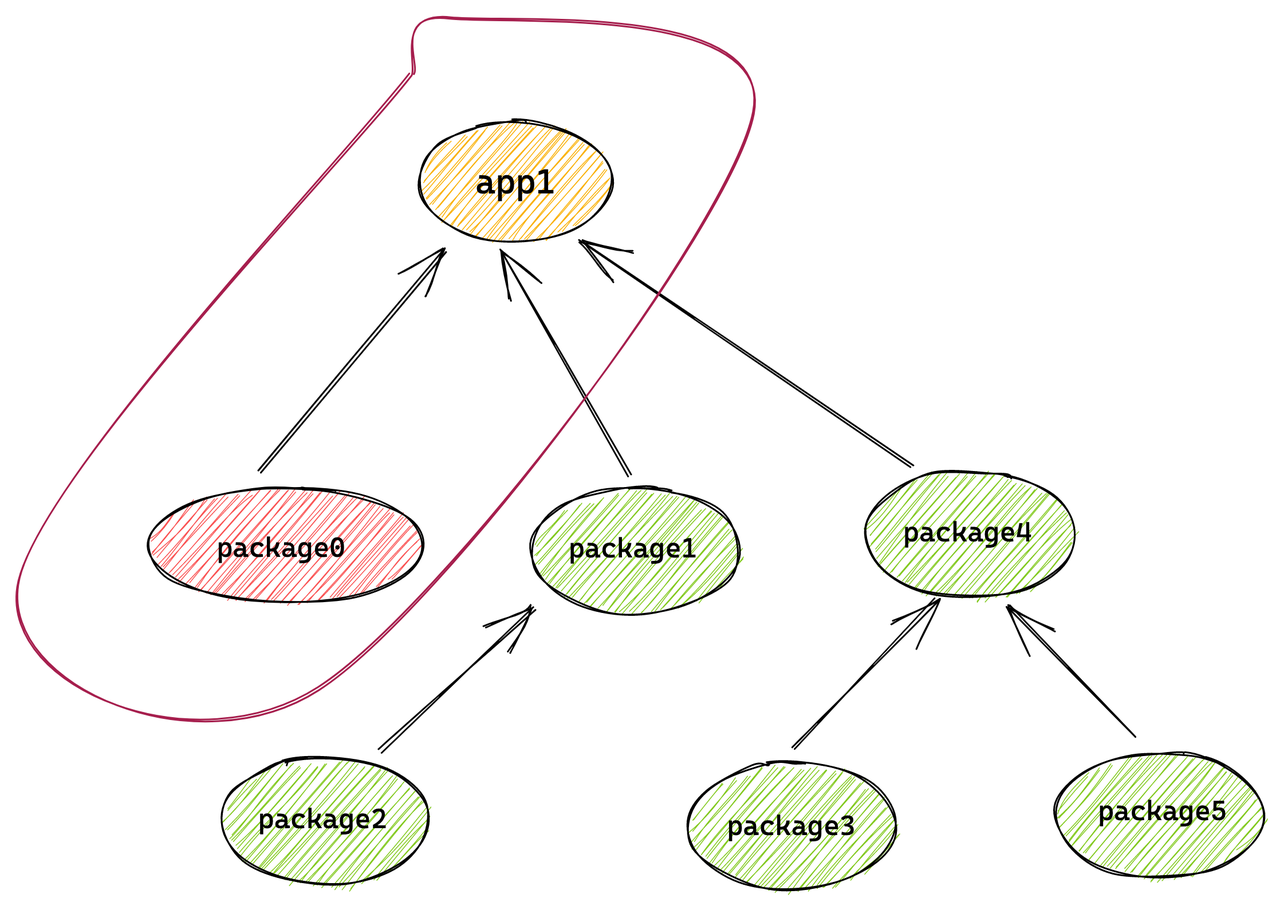
由于 package1-package5 等 5 个项目与 package0 不存在直接或间接的依赖关系,且输入文件没有改变,故能够命中缓存(如有),跳过构建行为。
如此便将构建范围由 7 个 project 降至 2 个 project。
实际构建的项目 = 改动项目 + 改动项目的 Dependents
如何判断是否命中缓存?
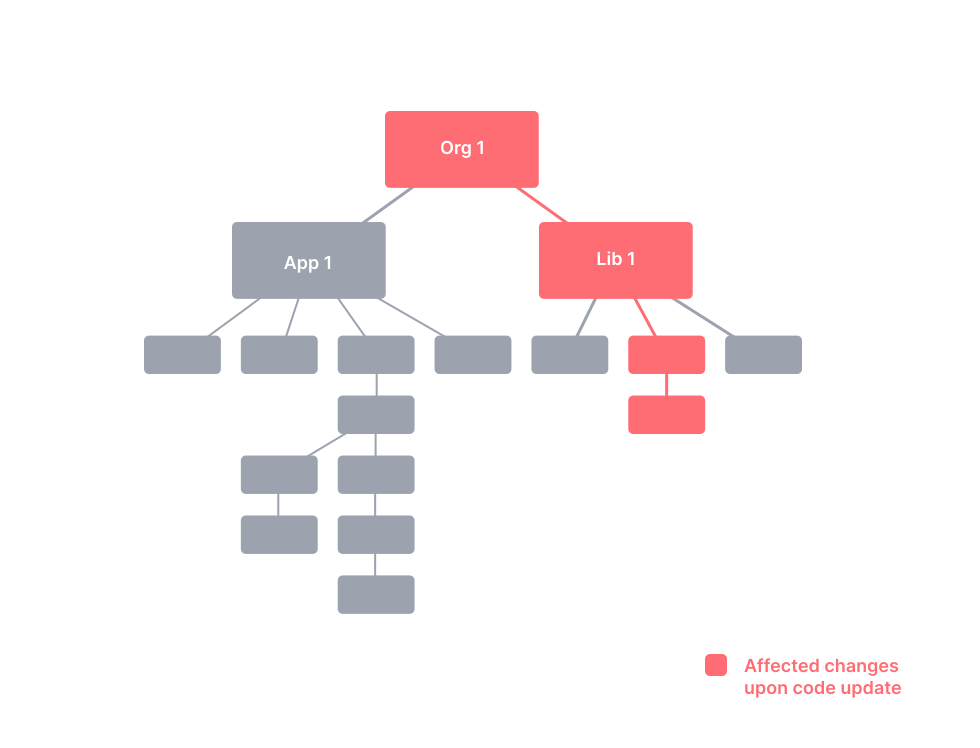
在云端,每一个项目构建结果的缓存压缩包与其输入文件 input files 计算出来的 cacheId 形成映射,输入文件未发生变化,则计算出来的 cacheId 值就不会变化(内容哈希),就能命中对应的云端缓存。
输入文件包含以下内容:
- 项目代码源文件
- 项目 NPM 依赖
- 项目依赖的其他 Monorepo 内部项目的 cacheId
缓存hash 的生成比较复杂,除了上述的内容,还可能包括一些其他情况,比如编译使用的环境变量,用来区分测试环境以及线上环境等。
若对实现感兴趣,可以查看 @rushstack/package-deps-hash。
结语
在编写本文过程中笔者也想起了 @sorrycc 在 GMTC 上分享的 《前端构建提速的体系化思路》中提到的构建提速三大法宝:
- 延迟处理。基于请求的按需编译、延迟编译 sourcemap
- 缓存。Vite Optmize、Webpack5 物理缓存、Babel 缓存
- Native Code。SWC、ESBuild
作为任务编排工具来讲,Native Code 的优势并不明显(虽然 Turborepo 使用 Go 语言编写,但 Lage 作者认为在现有规模下,任务编排的效率瓶颈并不在编排工具本身),但延迟处理与缓存是有异曲同工之妙的。
最后使用精简且务实的 Lage 官网副标题作为本文主题「任务编排」的结尾:
Run all your npm scripts in topological order incrementally with cloud cache - @microsoft/lage
配合云端缓存,依照拓扑排序增量运行你所有的 npm scripts。
参考
请教一个看起来有点傻的问题:你在「一个合格 Monorepo 的自我修养」一节引用的 《Eden Monorepo 系列:浅析 Eden Monorepo 工程化建设》,是一篇文章吗?我google了一下,没有找到它。
请教一个看起来有点傻的问题:你在「一个合格 Monorepo 的自我修养」一节引用的 《Eden Monorepo 系列:浅析 Eden Monorepo 工程化建设》,是一篇文章吗?我google了一下,没有找到它。
不好意思,这个是公司内网的文章,有兴趣来字节吗...
分析的很到位,感谢分享!
对于看到这还在纠结到底选择啥的同学,我觉得还是要从自身需求出发,比如先试试最基本的pnpm到底能不能满足,然后是搭配一下其他的工具,比如turbo,最后再试试rush之类的大而全的工具,个人认为没有最完美的解决方案,只有最适合的