CenterNet works ok on Pytorch 1.1 + Cuda10.1 + Win10
ausk opened this issue · 82 comments
First thanks for authors' great work.
This is not an issue. But I just want to say that CenterNet works ok on Pytorch 1.1 + Cuda10.1 + Win10:.
Just clone CenterNet, compile the nms and DCNv2, download the models, and run the demo.
1. build nms
cd CenterNet\src\lib\external
#python setup.py install
python setup.py build_ext --inplace
just comment the parameter in setup.py when building 'nms' extension to solve invalid numeric argument '/Wno-cpp' :
#extra_compile_args=["-Wno-cpp", "-Wno-unused-function"]
2. clone and build original DCN2
You may fail to compile DCNv2 when using Pytorch 1.x, because torch.utils.ffi is deprecated. Then replace DCNv2 using the original repo and [Solved] dcn_v2_cuda.obj : error LNK2001: unresolved external symbol state caused by extern THCState *state; by modifing the line DCNv2/blob/master/src/cuda/dcn_v2_cuda.cu#L11:
//extern THCState *state;
THCState *state = at::globalContext().lazyInitCUDA(); // Modified
cd CenterNet\src\lib\models\networks
rm -rf DCNv2
git clone https://github.com/CharlesShang/DCNv2
cd DCNv2
vim cuda/dcn_va_cuda.cu
"""
# extern THCState *state;
THCState *state = at::globalContext().lazyInitCUDA();
"""
python setup.py build develop
3. test
cd CenterNet/src
python demo.py ctdet --demo ../images/17790319373_bd19b24cfc_k.jpg --load_model ../models/ctdet_coco_dla_2x.pth --debug 2
python demo.py multi_pose --demo ../images/17790319373_bd19b24cfc_k.jpg --load_model ../models/multi_pose_dla_3x.pth --debug 2


非常感谢!
Thanks!
Why I got the message when I ran nms :
ModuleNotFoundError: No module named '_ext'
Have you compiled nms? cd src/lib/external, make
how to compile in windows and run sh
git bash?
Can you elaborate on GIT and GCC versions?
I have Git for Windows, make.exe、VS2017、 Cuda10.1、torch 1.0.1 on my PC. And I also set paths for cl.exe bash.exe make.exe and cuda.
external is failed
(CenterNet) D:\research\CenterNet-master\src\lib\external>python setup.py install
running install
running build
running build_ext
building 'nms' extension
D:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\BIN\x86_amd64\cl.exe /c /nologo /Ox /W3 /GL /DNDEBUG /MD -ID:\Anaconda3\envs\CenterNet\lib\site-packages\numpy\core\include -ID:\Anaconda3\envs\CenterNet\include -ID:\Anaconda3\envs\CenterNet\include "-ID:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\INCLUDE" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.10240.0\ucrt" "-IC:\Program Files (x86)\Windows Kits\NETFXSDK\4.6.1\include\um" "-IC:\Program Files (x86)\Windows Kits\8.1\include\shared" "-IC:\Program Files (x86)\Windows Kits\8.1\include\um" "-IC:\Program Files (x86)\Windows Kits\8.1\include\winrt" /Tcnms.c /Fobuild\temp.win-amd64-3.6\Release\nms.obj -Wno-cpp -Wno-unused-function
cl : Command line error D8021 : invalid numeric argument '/Wno-cpp'
error: command 'D:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\BIN\x86_amd64\cl.exe' failed with exit status 2
Pytorch 1.0.1 + Cuda9.0 + Win10
Another problem
(CenterNet) D:\research\CenterNet-master\src>python demo.py ctdet --demo D:\research\CenterNet-master\images\17790319373_bd19b24cfc_k.jpg --load_model D:\research\CenterNet-master\models\ctdet_coco_dla_1x.pth
Fix size testing.
training chunk_sizes: [32]
The output will be saved to D:\research\CenterNet-master\src\lib....\exp\ctdet\default
heads {'hm': 80, 'wh': 2, 'reg': 2}
Creating model...
Traceback (most recent call last):
File "demo.py", line 56, in
demo(opt)
File "demo.py", line 21, in demo
detector = Detector(opt)
File "D:\research\CenterNet-master\src\lib\detectors\ctdet.py", line 22, in init
super(CtdetDetector, self).init(opt)
File "D:\research\CenterNet-master\src\lib\detectors\base_detector.py", line 24, in init
self.model = create_model(opt.arch, opt.heads, opt.head_conv)
File "D:\research\CenterNet-master\src\lib\models\model.py", line 28, in create_model
model = get_model(num_layers, head, head_conv)
File "D:\research\CenterNet-master\src\lib\models\networks\pose_dla_dcn.py", line 491, in get_pose_net
head_conv=head_conv)
File "D:\research\CenterNet-master\src\lib\models\networks\pose_dla_dcn.py", line 434, in init
self.base = globals()base_name
File "D:\research\CenterNet-master\src\lib\models\networks\pose_dla_dcn.py", line 314, in dla34
model.load_pretrained_model(data='imagenet', name='dla34', hash='ba72cf86')
File "D:\research\CenterNet-master\src\lib\models\networks\pose_dla_dcn.py", line 305, in load_pretrained_model
self.load_state_dict(model_weights)
File "D:\Anaconda3\envs\CenterNet\lib\site-packages\torch\nn\modules\module.py", line 769, in load_state_dict
self.class.name, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for DLA:
Missing key(s) in state_dict: "base_layer.0.weight", "base_layer.1.weight", "base_layer.1.bias", "base_layer.1.running_mean", "base_layer.1.running_var", "level0.0.weight", "level0.1.weight", "level0.1.bias", "level0.1.running_mean", "level0.1.running_var", "level1.0.weight", "level1.1.weight", "level1.1.bias", "level1.1.running_mean", "level1.1.running_var", "level2.tree1.conv1.weight", "level2.tree1.bn1.weight", "level2.tree1.bn1.bias", "level2.tree1.bn1.running_mean", "level2.tree1.bn1.running_var", "level2.tree1.conv2.weight", "level2.tree1.bn2.weight", "level2.tree1.bn2.bias", "level2.tree1.bn2.running_mean", "level2.tree1.bn2.running_var", "level2.tree2.conv1.weight", "level2.tree2.bn1.weight", "level2.tree2.bn1.bias", "level2.tree2.bn1.running_mean", "level2.tree2.bn1.running_var", "level2.tree2.conv2.weight", "level2.tree2.bn2.weight", "level2.tree2.bn2.bias", "level2.tree2.bn2.running_mean", "level2.tree2.bn2.running_var", "level2.root.conv.weight", "level2.root.bn.weight", "level2.root.bn.bias", "level2.root.bn.running_mean", "level2.root.bn.running_var", "level2.project.0.weight", "level2.project.1.weight", "level2.project.1.bias", "level2.project.1.running_mean", "level2.project.1.running_var", "level3.tree1.tree1.conv1.weight", "level3.tree1.tree1.bn1.weight", "level3.tree1.tree1.bn1.bias", "level3.tree1.tree1.bn1.running_mean", "level3.tree1.tree1.bn1.running_var", "level3.tree1.tree1.conv2.weight", "level3.tree1.tree1.bn2.weight", "level3.tree1.tree1.bn2.bias", "level3.tree1.tree1.bn2.running_mean", "level3.tree1.tree1.bn2.running_var", "level3.tree1.tree2.conv1.weight", "level3.tree1.tree2.bn1.weight", "level3.tree1.tree2.bn1.bias", "level3.tree1.tree2.bn1.running_mean", "level3.tree1.tree2.bn1.running_var", "level3.tree1.tree2.conv2.weight", "level3.tree1.tree2.bn2.weight", "level3.tree1.tree2.bn2.bias", "level3.tree1.tree2.bn2.running_mean", "level3.tree1.tree2.bn2.running_var", "level3.tree1.root.conv.weight", "level3.tree1.root.bn.weight", "level3.tree1.root.bn.bias", "level3.tree1.root.bn.running_mean", "level3.tree1.root.bn.running_var", "level3.tree1.project.0.weight", "level3.tree1.project.1.weight", "level3.tree1.project.1.bias", "level3.tree1.project.1.running_mean", "level3.tree1.project.1.running_var", "level3.tree2.tree1.conv1.weight", "level3.tree2.tree1.bn1.weight", "level3.tree2.tree1.bn1.bias", "level3.tree2.tree1.bn1.running_mean", "level3.tree2.tree1.bn1.running_var", "level3.tree2.tree1.conv2.weight", "level3.tree2.tree1.bn2.weight", "level3.tree2.tree1.bn2.bias", "level3.tree2.tree1.bn2.running_mean", "level3.tree2.tree1.bn2.running_var", "level3.tree2.tree2.conv1.weight", "level3.tree2.tree2.bn1.weight", "level3.tree2.tree2.bn1.bias", "level3.tree2.tree2.bn1.running_mean", "level3.tree2.tree2.bn1.running_var", "level3.tree2.tree2.conv2.weight", "level3.tree2.tree2.bn2.weight", "level3.tree2.tree2.bn2.bias", "level3.tree2.tree2.bn2.running_mean", "level3.tree2.tree2.bn2.running_var", "level3.tree2.root.conv.weight", "level3.tree2.root.bn.weight", "level3.tree2.root.bn.bias", "level3.tree2.root.bn.running_mean", "level3.tree2.root.bn.running_var", "level3.project.0.weight", "level3.project.1.weight", "level3.project.1.bias", "level3.project.1.running_mean", "level3.project.1.running_var", "level4.tree1.tree1.conv1.weight", "level4.tree1.tree1.bn1.weight", "level4.tree1.tree1.bn1.bias", "level4.tree1.tree1.bn1.running_mean", "level4.tree1.tree1.bn1.running_var", "level4.tree1.tree1.conv2.weight", "level4.tree1.tree1.bn2.weight", "level4.tree1.tree1.bn2.bias", "level4.tree1.tree1.bn2.running_mean", "level4.tree1.tree1.bn2.running_var", "level4.tree1.tree2.conv1.weight", "level4.tree1.tree2.bn1.weight", "level4.tree1.tree2.bn1.bias", "level4.tree1.tree2.bn1.running_mean", "level4.tree1.tree2.bn1.running_var", "level4.tree1.tree2.conv2.weight", "level4.tree1.tree2.bn2.weight", "level4.tree1.tree2.bn2.bias", "level4.tree1.tree2.bn2.running_mean", "level4.tree1.tree2.bn2.running_var", "level4.tree1.root.conv.weight", "level4.tree1.root.bn.weight", "level4.tree1.root.bn.bias", "level4.tree1.root.bn.running_mean", "level4.tree1.root.bn.running_var", "level4.tree1.project.0.weight", "level4.tree1.project.1.weight", "level4.tree1.project.1.bias", "level4.tree1.project.1.running_mean", "level4.tree1.project.1.running_var", "level4.tree2.tree1.conv1.weight", "level4.tree2.tree1.bn1.weight", "level4.tree2.tree1.bn1.bias", "level4.tree2.tree1.bn1.running_mean", "level4.tree2.tree1.bn1.running_var", "level4.tree2.tree1.conv2.weight", "level4.tree2.tree1.bn2.weight", "level4.tree2.tree1.bn2.bias", "level4.tree2.tree1.bn2.running_mean", "level4.tree2.tree1.bn2.running_var", "level4.tree2.tree2.conv1.weight", "level4.tree2.tree2.bn1.weight", "level4.tree2.tree2.bn1.bias", "level4.tree2.tree2.bn1.running_mean", "level4.tree2.tree2.bn1.running_var", "level4.tree2.tree2.conv2.weight", "level4.tree2.tree2.bn2.weight", "level4.tree2.tree2.bn2.bias", "level4.tree2.tree2.bn2.running_mean", "level4.tree2.tree2.bn2.running_var", "level4.tree2.root.conv.weight", "level4.tree2.root.bn.weight", "level4.tree2.root.bn.bias", "level4.tree2.root.bn.running_mean", "level4.tree2.root.bn.running_var", "level4.project.0.weight", "level4.project.1.weight", "level4.project.1.bias", "level4.project.1.running_mean", "level4.project.1.running_var", "level5.tree1.conv1.weight", "level5.tree1.bn1.weight", "level5.tree1.bn1.bias", "level5.tree1.bn1.running_mean", "level5.tree1.bn1.running_var", "level5.tree1.conv2.weight", "level5.tree1.bn2.weight", "level5.tree1.bn2.bias", "level5.tree1.bn2.running_mean", "level5.tree1.bn2.running_var", "level5.tree2.conv1.weight", "level5.tree2.bn1.weight", "level5.tree2.bn1.bias", "level5.tree2.bn1.running_mean", "level5.tree2.bn1.running_var", "level5.tree2.conv2.weight", "level5.tree2.bn2.weight", "level5.tree2.bn2.bias", "level5.tree2.bn2.running_mean", "level5.tree2.bn2.running_var", "level5.root.conv.weight", "level5.root.bn.weight", "level5.root.bn.bias", "level5.root.bn.running_mean", "level5.root.bn.running_var", "level5.project.0.weight", "level5.project.1.weight", "level5.project.1.bias", "level5.project.1.running_mean", "level5.project.1.running_var", "fc.weight", "fc.bias".
Unexpected key(s) in state_dict: "epoch", "state_dict".
@mk123qwe I think you should load model in this way:
checkpoint = torch.load(model_weights) state_dict = checkpoint['state_dict'] self.load_state_dict(state_dict)
@mk123qwe I think you should load model in this way:
checkpoint = torch.load(model_weights) state_dict = checkpoint['state_dict'] self.load_state_dict(state_dict)
The demo provided by the author is correct and I can't modify it.
@ausk Hi, you mentioned replace DCNv2 using the original repo. Could you tell me detail? Just can't get DCNV2 compile done correctly...
Why I got the message when I ran nms :
ModuleNotFoundError: No module named '_ext'
maybe you install using python2, but run using python3
3q
@ausk Hi, Gentle, I just follow by your suggestion , but I get a import error in dcn_v2.py 'import _ext as _backend' , 'No module named _ext' ,what's this _ext package really about?
Why I got the message when I ran nms :
ModuleNotFoundError: No module named '_ext'
I think I have met the same problem ,but the _ext import error is in dcnv2.py , and the '_ext' is a CUDAExtension name , but how to solve it ? LOL
@ausk 非常感谢 我跑成功了
兄弟 你Pytorch哪个版本的
@heartInsert 我的环境:win10+cuda10+torch1.1.0+python36
关于:
Why I got the message when I ran nms :
ModuleNotFoundError: No module named '_ext'
我这边是这样解决的:
设置环境变量:PYTHONHOME = 你自己的python.exe所在路径 (重启下)
@heartInsert 我的环境:win10+cuda10+torch1.1.0+python36
关于:
Why I got the message when I ran nms :
ModuleNotFoundError: No module named '_ext'我这边是这样解决的:
设置环境变量:PYTHONHOME = 你自己的python.exe所在路径 (重启下)
Okay,我跑起来啦
external is failed
(CenterNet) D:\research\CenterNet-master\src\lib\external>python setup.py install
running install
running build
running build_ext
building 'nms' extension
D:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\BIN\x86_amd64\cl.exe /c /nologo /Ox /W3 /GL /DNDEBUG /MD -ID:\Anaconda3\envs\CenterNet\lib\site-packages\numpy\core\include -ID:\Anaconda3\envs\CenterNet\include -ID:\Anaconda3\envs\CenterNet\include "-ID:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\INCLUDE" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.10240.0\ucrt" "-IC:\Program Files (x86)\Windows Kits\NETFXSDK\4.6.1\include\um" "-IC:\Program Files (x86)\Windows Kits\8.1\include\shared" "-IC:\Program Files (x86)\Windows Kits\8.1\include\um" "-IC:\Program Files (x86)\Windows Kits\8.1\include\winrt" /Tcnms.c /Fobuild\temp.win-amd64-3.6\Release\nms.obj -Wno-cpp -Wno-unused-function
cl : Command line error D8021 : invalid numeric argument '/Wno-cpp'
error: command 'D:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\BIN\x86_amd64\cl.exe' failed with exit status 2
How do you solve this propblem ,I have the same question with you
CenterNet-master\src\lib\external>python setup.py install
just comment the parameter in setup.py when building 'nms' extension to solve invalid numeric argument '/Wno-cpp' :
#extra_compile_args=["-Wno-cpp", "-Wno-unused-function"]
CenterNet-master\src\lib\external>python setup.py install
just comment the parameter in
setup.pywhen building 'nms' extension to solveinvalid numeric argument '/Wno-cpp':#extra_compile_args=["-Wno-cpp", "-Wno-unused-function"]
If you are a girl , I think I will say 'I love you '
@ausk I compiled the NMS, but it didn't work ,a warning Extension name 'nms' does not match fully qualified name 'external.nms' of 'nms.pyx',What should I do ,Thanks
@ausk cuda 9 doesn't your method work? i compiled DCNv2 error: command 'C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\BIN\x86_amd64\cl.exe' failed with exit status 2?
error: command 'E:\vs\VC\Tools\MSVC\14.21.27702\bin\HostX86\x64\link.exe' failed with exit status 1120
Has anybody solved this problem?
@ausk 非常感谢 我跑成功了
error: command 'E:\vs\VC\Tools\MSVC\14.21.27702\bin\HostX86\x64\link.exe' failed with exit status 1120
请问在运行DCNv2的make.sh中你有遇到这个问题吗?或者你有什么特殊的配置吗?
When I run build.sh in DAIN on Windows,
Error: command 'D:\Microsoft VisualStudio\2019\Community\VC\Tools\MSVC\14.21.27702\bin\HostX86\x64\cl.exe' failed with exit status 2 ,
But I have configured path for cl.exe, can someone guide me?
Traceback (most recent call last):
File "./src/demo.py", line 11, in
from detectors.detector_factory import detector_factory
File "/opt/data/private/centernet_objects_as_points_pytorch/src/lib/detectors/detector_factory.py", line 5, in
from .exdet import ExdetDetector
File "/opt/data/private/centernet_objects_as_points_pytorch/src/lib/detectors/exdet.py", line 22, in
from .base_detector import BaseDetector
File "/opt/data/private/centernet_objects_as_points_pytorch/src/lib/detectors/base_detector.py", line 11, in
from models.model import create_model, load_model
File "/opt/data/private/centernet_objects_as_points_pytorch/src/lib/models/model.py", line 12, in
from .networks.pose_dla_dcn import get_pose_net as get_dla_dcn
File "/opt/data/private/centernet_objects_as_points_pytorch/src/lib/models/networks/pose_dla_dcn.py", line 16, in
from .DCNv2.dcn_v2 import DCN
File "/opt/data/private/centernet_objects_as_points_pytorch/src/lib/models/networks/DCNv2/dcn_v2.py", line 13, in
import _ext as _backend
ImportError: /opt/data/private/centernet_objects_as_points_pytorch/src/lib/models/networks/DCNv2/_ext.cpython-35m-x86_64-linux-gnu.so: undefined symbol: _ZNSt13runtime_errorC1EPKc
LOOKING FOR HELP!!!!!!!!!!!!!!!!!!!
(measure) C:\Users\IFL\Desktop\Liu\Detector\CenterNet\src>python demo.py ctdet --demo ../images/17790319373_bd19b24cfc_k.jpg --load_model ../models/ctdet_coco_dla_2x.pth --debug 2
Fix size testing.
training chunk_sizes: [1]
The output will be saved to C:\Users\IFL\Desktop\Liu\Detector\CenterNet\src\lib....\exp\ctdet\default
heads {'hm': 80, 'wh': 2, 'reg': 2}
Creating model...
loaded ../models/ctdet_coco_dla_2x.pth, epoch 230
Traceback (most recent call last):
File "demo.py", line 57, in
demo(opt)
File "demo.py", line 50, in demo
ret = detector.run(image_name)
File "C:\Users\IFL\Desktop\Liu\Detector\CenterNet\src\lib\detectors\base_detector.py", line 116, in run
output, dets, forward_time = self.process(images, return_time=True)
File "C:\Users\IFL\Desktop\Liu\Detector\CenterNet\src\lib\detectors\ctdet.py", line 27, in process
output = self.model(images)[-1]
File "C:\Users\IFL\Anaconda3\envs\measure\lib\site-packages\torch\nn\modules\module.py", line 493, in call
result = self.forward(*input, **kwargs)
File "C:\Users\IFL\Desktop\Liu\Detector\CenterNet\src\lib\models\networks\pose_dla_dcn.py", line 471, in forward
x = self.base(x)
File "C:\Users\IFL\Anaconda3\envs\measure\lib\site-packages\torch\nn\modules\module.py", line 493, in call
result = self.forward(*input, **kwargs)
File "C:\Users\IFL\Desktop\Liu\Detector\CenterNet\src\lib\models\networks\pose_dla_dcn.py", line 288, in forward
x = self.base_layer(x)
File "C:\Users\IFL\Anaconda3\envs\measure\lib\site-packages\torch\nn\modules\module.py", line 493, in call
result = self.forward(*input, **kwargs)
File "C:\Users\IFL\Anaconda3\envs\measure\lib\site-packages\torch\nn\modules\container.py", line 92, in forward
input = module(input)
File "C:\Users\IFL\Anaconda3\envs\measure\lib\site-packages\torch\nn\modules\module.py", line 493, in call
result = self.forward(*input, **kwargs)
File "C:\Users\IFL\Anaconda3\envs\measure\lib\site-packages\torch\nn\modules\conv.py", line 338, in forward
self.padding, self.dilation, self.groups)
RuntimeError: cuDNN error: CUDNN_STATUS_EXECUTION_FAILED
what's this problem?
按楼主的方法出现如下错误,哪位大佬知道怎么解决吗?
ubuntu18+pytorch1.1+cuda10
(cxy) car@car:~/Documents/CenterNet/CenterNet_pytorch/src$ python demo.py ctdet --demo ../images/17790319373_bd19b24cfc_k.jpg --load_model ../models/ctdet_coco_dla_2x.pth --debug 1 Fix size testing. training chunk_sizes: [1] The output will be saved to /home/car/Documents/CenterNet/CenterNet_pytorch/src/lib/../../exp/ctdet/default heads {'hm': 80, 'wh': 2, 'reg': 2} Creating model... loaded ../models/ctdet_coco_dla_2x.pth, epoch 230 error in modulated_deformable_im2col_cuda: invalid device function error in modulated_deformable_im2col_cuda: invalid device function error in modulated_deformable_im2col_cuda: invalid device function error in modulated_deformable_im2col_cuda: invalid device function error in modulated_deformable_im2col_cuda: invalid device function error in modulated_deformable_im2col_cuda: invalid device function error in modulated_deformable_im2col_cuda: invalid device function error in modulated_deformable_im2col_cuda: invalid device function THCudaCheck FAIL file=/pytorch/aten/src/THC/THCCachingHostAllocator.cpp line=265 error=77 : an illegal memory access was encountered Traceback (most recent call last): File "demo.py", line 56, in <module> demo(opt) File "demo.py", line 49, in demo ret = detector.run(image_name) File "/home/car/Documents/CenterNet/CenterNet_pytorch/src/lib/detectors/base_detector.py", line 116, in run output, dets, forward_time = self.process(images, return_time=True) File "/home/car/Documents/CenterNet/CenterNet_pytorch/src/lib/detectors/ctdet.py", line 26, in process output = self.model(images)[-1] File "/home/car/anaconda3/envs/cxy/lib/python3.6/site-packages/torch/nn/modules/module.py", line 493, in __call__ result = self.forward(*input, **kwargs) File "/home/car/Documents/CenterNet/CenterNet_pytorch/src/lib/models/networks/pose_dla_dcn.py", line 472, in forward x = self.dla_up(x) File "/home/car/anaconda3/envs/cxy/lib/python3.6/site-packages/torch/nn/modules/module.py", line 493, in __call__ result = self.forward(*input, **kwargs) File "/home/car/Documents/CenterNet/CenterNet_pytorch/src/lib/models/networks/pose_dla_dcn.py", line 411, in forward ida(layers, len(layers) -i - 2, len(layers)) File "/home/car/anaconda3/envs/cxy/lib/python3.6/site-packages/torch/nn/modules/module.py", line 493, in __call__ result = self.forward(*input, **kwargs) File "/home/car/Documents/CenterNet/CenterNet_pytorch/src/lib/models/networks/pose_dla_dcn.py", line 384, in forward layers[i] = upsample(project(layers[i])) File "/home/car/anaconda3/envs/cxy/lib/python3.6/site-packages/torch/nn/modules/module.py", line 493, in __call__ result = self.forward(*input, **kwargs) File "/home/car/Documents/CenterNet/CenterNet_pytorch/src/lib/models/networks/pose_dla_dcn.py", line 355, in forward x = self.conv(x) File "/home/car/anaconda3/envs/cxy/lib/python3.6/site-packages/torch/nn/modules/module.py", line 493, in __call__ result = self.forward(*input, **kwargs) File "/home/car/Documents/CenterNet/CenterNet_pytorch/src/lib/models/networks/DCNv2/dcn_v2.py", line 121, in forward offset = torch.cat((o1, o2), dim=1) RuntimeError: cuda runtime error (77) : an illegal memory access was encountered at /pytorch/aten/src/THC/THCCachingHostAllocator.cpp:265 Segmentation fault (core dumped)
(dl_cai) yzc@tjd-PowerEdge-T640:~/CenterNet/src$ python demo.py ctdet --demo ../images/17790319373_bd19b24cfc_k.jpg --load_model ../models/ctdet_coco_dla_2x.pth --debug 2
Fix size testing.
training chunk_sizes: [1]
The output will be saved to /home/yzc/CenterNet/src/lib/../../exp/ctdet/default
heads {'hm': 80, 'wh': 2, 'reg': 2}
Creating model...
loaded ../models/ctdet_coco_dla_2x.pth, epoch 230
Segmentation fault (core dumped)
@TonyAlpha12
I am facing the same problem right now. I found segmentation fault actually happened when code ran into forward function. Do you have any idea about it? I am actually using Python 3.7, torch 1.1 and cuda 9.0. How about your setup?
@ruinianxu 我在win下能跑起来了,但是服务器下Ubuntu18.0+pytorch1.1+cuda10还是报这个错,暂时不知道怎么出的问题。
@TonyAlpha12
I have solved this error. The error comes from DCNv2. C/C++ extension from pytorch 1.0 requires version of gcc larger than 4.9. If your gcc is under 4.9, you are still able to compile it but will get segmentation fault during running.
@ruinianxu I have solved this too, and the version of gcc can't larger than 6!
follow the step and got this question:
python3.6 error: Unable to find vcvarsall.bat
how to solve it?
thanks
note that you need VS2017, when I use pytorch 1.2
<To who may mix-installation with vs2015/vs2017 , conda python virtual envs 3.55/3.65/3.7>
[My original installation is 64bit Win10 +cuda 10.0.130 /cudnn 7.6.0 installed by Anaconda3 ,NVIDIA driver is 10.1.120 maintained by NVDIA auto-update, I like py37 most and it's based on vs2015 and pytorch 1.0]
I failed may times to build DCNv2 in my very complex environment but fillally get it's passed compile just now so I put it here and hope it's usefully to someone who need it.
I download and installed cudatoolkit 10.1.120 and installed somewhere (not the default directory )
I use the bat file below to let my py37 environment can use vs2017 instead of vs2015.
set DevEnvDir=D:\VS2017\Common7\IDE
set INCLUDE=D:\VS2017\VC\Tools\MSVC\14.16.27023\include;C:\Windows Kits\10\include\10.0.17763.0\ucrt;C:\Program Files (x86)\Windows Kits\NETFXSDK\4.6.1\include\um;C:\Windows Kits\10\include\10.0.17763.0\shared;C:\Windows Kits\10\include\10.0.17763.0\um;C:\Windows Kits\10\include\10.0.17763.0\winrt;
set LIB=D:\VS2017\VC\Tools\MSVC\14.16.27023\lib\x64;;C:\Windows Kits\10\lib\10.0.17763.0\ucrt\x64;C:\Program Files (x86)\Windows Kits\NETFXSDK\4.6.1\lib\um\x64;C:\Windows Kits\10\lib\10.0.17763.0\um\x64;
set LIBPATH=D:\VS2017\VC\Tools\MSVC\14.16.27023\lib\x64;D:\VS2017\VC\Tools\MSVC\14.16.27023\lib\x86\store\references;C:\WINDOWS\Microsoft.NET\Framework64\v4.0.30319;C:\Windows Kits\10\UnionMetadata;C:\Windows Kits\10\References;C:\Program Files (x86)\Microsoft SDKs\Windows Kits\10\ExtensionSDKs\Microsoft.VCLibs\14.0\References\CommonConfiguration\neutral;
set Path=D:\VS2017\VC\Tools\MSVC\14.16.27023\bin\HostX64\x64;D:\VS2017\VC\Tools\MSVC\14.16.27023\bin\HostX64\x64;D:\VS2017\Common7\IDE\VC\VCPackages;D:\VS2017\Common7\IDE\CommonExtensions\Microsoft\TestWindow;D:\VS2017\Common7\IDE\CommonExtensions\Microsoft\TeamFoundation\Team Explorer;D:\VS2017\MSBuild\15.0\bin\Roslyn;C:\Program Files (x86)\Microsoft SDKs\Windows\v10.0A\bin\NETFX 4.6.1 Tools\x64;C:\Windows Kits\10\bin\10.0.17763.0\x64;C:\Windows Kits\10\bin\x64;D:\VS2017\MSBuild\15.0\bin;C:\WINDOWS\Microsoft.NET\Framework64\v4.0.30319;D:\VS2017\Common7\IDE;D:\VS2017\Common7\Tools;F:\CUDA10013\Dev\bin;F:\CUDA10013\Dev\libnvvp;C:\Windows Kits\10\bin\x64;C:\Windows Kits\10\bin\x86;C:\Program Files (x86)\Microsoft SDKs\Windows\v10.0A\bin\NETFX 4.6.1 Tools\x64;D:\ANCD3\envs\py37;D:\ANCD3\envs\py37\Library\mingw-w64\bin;D:\ANCD3\envs\py37\Library\usr\bin;D:\ANCD3\envs\py37\Library\bin;D:\ANCD3\envs\py37\Scripts;D:\ANCD3\envs\py37\bin;D:\ANCD3\condabin;F:\CUDA10013\Dev\bin;F:\CUDA10013\Dev\libnvvp;C:\WINDOWS\system32;C:\WINDOWS;C:\WINDOWS\System32\Wbem;C:\WINDOWS\System32\WindowsPowerShell\v1.0;C:\WINDOWS\System32\OpenSSH;C:\Program Files (x86)\NVIDIA Corporation\PhysX\Common;C:\Program Files\PuTTY;C:\Users\onesh.dnx\bin;C:\Program Files\Microsoft DNX\Dnvm;C:\Program Files\Microsoft SQL Server\130\Tools\Binn;C:\Program Files\NVIDIA Corporation\NVIDIA NvDLISR;C:\Program Files\OpenVPN\bin;C:\Program Files (x86)\QuickTime\QTSystem;C:\WINDOWS\system32;C:\WINDOWS;C:\WINDOWS\System32\Wbem;C:\WINDOWS\System32\WindowsPowerShell\v1.0;C:\WINDOWS\System32\OpenSSH;C:\Program Files\Git\cmd;C:\Users\onesh\AppData\Local\Microsoft\WindowsApps;;D:\PyCharm\bin;;C:\Program Files (x86)\Windows Kits\8.1\bin\x86
set VCIDEInstallDir=D:\VS2017\Common7\IDE\VC
set VCINSTALLDIR=D:\VS2017\VC
set VCToolsInstallDir=D:\VS2017\VC\Tools\MSVC\14.16.27023
set VCToolsRedistDir=D:\VS2017\VC\Redist\MSVC\14.16.27012
set VCToolsVersion=14.16.27023
set VisualStudioVersion=15.0
set VS150COMNTOOLS=D:\VS2017\Common7\Tools
set VSCMD_ARG_app_plat=Desktop
set VSCMD_ARG_HOST_ARCH=x64
set VSCMD_ARG_TGT_ARCH=x64
set VSCMD_VER=15.9.13
set VSINSTALLDIR=D:\VS2017\
set MSSdk=1
set MSYS2_ARG_CONV_EXCL=/AI;/AL;/OUT;/out
set MSYS2_ENV_CONV_EXCL=CL
set VS_MAJOR=
set VS_VERSION=
set VS_YEAR=
set VSREGKEY=
set VS140COMNTOOLS=
set VCINSTALLDIR=
set PY_VCRUNTIME_REDIST=\vcruntime140.dll
set CMAKE_GENERATOR=Visual Studio 15 2017 Win64
set __VSCMD_PREINIT_PATH=F:\CUDA10013\Dev\bin;F:\CUDA10013\Dev\libnvvp;C:\WINDOWS\system32;C:\WINDOWS;C:\WINDOWS\System32\Wbem;C:\WINDOWS\System32\WindowsPowerShell\v1.0;C:\WINDOWS\System32\OpenSSH;C:\Program Files (x86)\NVIDIA Corporation\PhysX\Common;C:\Program Files\PuTTY;C:\Users\onesh.dnx\bin;C:\Program Files\Microsoft DNX\Dnvm;C:\Program Files\Microsoft SQL Server\130\Tools\Binn;C:\Program Files\NVIDIA Corporation\NVIDIA NvDLISR;C:\Program Files\OpenVPN\bin;C:\Program Files (x86)\QuickTime\QTSystem;C:\WINDOWS\system32;C:\WINDOWS;C:\WINDOWS\System32\Wbem;C:\WINDOWS\System32\WindowsPowerShell\v1.0;C:\WINDOWS\System32\OpenSSH;C:\Program Files\Git\cmd;C:\Users\onesh\AppData\Local\Microsoft\WindowsApps;;D:\PyCharm\bin;
after that I recompiled the nms and DVNv2 and followed some suggestions from internet and finally compile DCNv2 successfully .
Cheers!
from .DCNv2.dcn_v2 import DCN
File "/home/rencong/CenterNet/src/lib/models/networks/DCNv2/dcn_v2.py", line 13, in
import _ext as _backend
ImportError: /home/rencong/CenterNet/src/lib/models/networks/DCNv2/_ext.cpython-36m-x86_64-linux-gnu.so: undefined symbol: _ZN3c105ErrorC1ENS_14SourceLocationERKSs
@heartInsert 我的环境:win10 + cuda10 + torch1.1.0 + python36
关于:
为什么我在运行nms时收到消息:
ModuleNotFoundError:没有名为'_ext'的模块我这边是这样解决的:
设置环境变量:PYTHONHOME =你自己的python.exe所在路径(重启下)
@heartInsert 我的环境:win10+cuda10+torch1.1.0+python36
关于:
Why I got the message when I ran nms :
ModuleNotFoundError: No module named '_ext'我这边是这样解决的:
设置环境变量:PYTHONHOME = 你自己的python.exe所在路径 (重启下)
请问linux里面遇到同样的问题怎么解决呢,我添加了环境变量好像不起作用
@heartInsert 我的环境:win10 + cuda10 + torch1.1.0 + python36
关于:
为什么我在运行nms时收到消息:
ModuleNotFoundError:没有名为'_ext'的模块
我这边是这样解决的:
设置环境变量:PYTHONHOME =你自己的python.exe所在路径(重启下)@heartInsert 我的环境:win10+cuda10+torch1.1.0+python36
关于:
Why I got the message when I ran nms :
ModuleNotFoundError: No module named '_ext'
我这边是这样解决的:
设置环境变量:PYTHONHOME = 你自己的python.exe所在路径 (重启下)请问linux里面遇到同样的问题怎么解决呢,我添加了环境变量好像不起作用
I use python setup.py install to fix this issue in linux.
AttributeError: 'sys.flags' object has no attribute 'utf8_mode'
这个问题还如何解决呢
@heartInsert 我的环境:win10+cuda10+torch1.1.0+python36
关于:
Why I got the message when I ran nms :
ModuleNotFoundError: No module named '_ext'
我这边是这样解决的:
设置环境变量:PYTHONHOME = 你自己的python.exe所在路径 (重启下)Okay,我跑起来啦
能否问一下你的环境变量在哪个文件设置的吗?
~/.bashrc 是这个?
@heartInsert 您好 Why I got the message when I ran nms :
ModuleNotFoundError: No module named '_ext'
我这边是这样解决的:
设置环境变量:PYTHONHOME = 你自己的python.exe所在路径 (重启下)
@heartInsert 我的环境:win10+cuda10+torch1.1.0+python36
关于:
Why I got the message when I ran nms :
ModuleNotFoundError: No module named '_ext'
我这边是这样解决的:
设置环境变量:PYTHONHOME = 你自己的python.exe所在路径 (重启下)Okay,我跑起来啦
您好,我想请教下PYTHONHOME怎么设置 我设置了anaconda下的python路径和anaconda虚拟环境下的python路径(E:\ProgramData\Anaconda3\envs\centernet),重启后打不开虚拟环境了,您能把你的发我看下吗
@heartInsert 我的环境:win10+cuda10+torch1.1.0+python36
关于:
Why I got the message when I ran nms :
ModuleNotFoundError: No module named '_ext'
我这边是这样解决的:
设置环境变量:PYTHONHOME = 你自己的python.exe所在路径 (重启下)Okay,我跑起来啦
能否问一下你的环境变量在哪个文件设置的吗?
~/.bashrc 是这个?
sorry,已忘
@heartInsert 您好 Why I got the message when I ran nms :
ModuleNotFoundError: No module named '_ext'
我这边是这样解决的:
设置环境变量:PYTHONHOME = 你自己的python.exe所在路径 (重启下)@heartInsert 我的环境:win10+cuda10+torch1.1.0+python36
关于:
Why I got the message when I ran nms :
ModuleNotFoundError: No module named '_ext'
我这边是这样解决的:
设置环境变量:PYTHONHOME = 你自己的python.exe所在路径 (重启下)Okay,我跑起来啦
您好,我想请教下PYTHONHOME怎么设置 我设置了anaconda下的python路径和anaconda虚拟环境下的python路径(E:\ProgramData\Anaconda3\envs\centernet),重启后打不开虚拟环境了,您能把你的发我看下吗
项目实在太久了,导致我忘记怎么设置的了,当时好像是 _ext没有什么影响,我最后没有使用形变卷积,用的好像是hourglass和posenet的backbone ,效果还不错。centernet思路也很清晰,一看就懂了
@ausk 非常感谢 我跑成功了
error: command 'E:\vs\VC\Tools\MSVC\14.21.27702\bin\HostX86\x64\link.exe' failed with exit status 1120
请问在运行DCNv2的make.sh中你有遇到这个问题吗?或者你有什么特殊的配置吗?
I also have met this issue, what's your solution, thank you!
python3.6+pytorch1.2+win10 ok
py3.7+pytorch1.3 +win10 fail
Thanks, works like a charm!!!
@GreenTeaHua I believe you are right.
@heartInsert 我的环境:win10+cuda10+torch1.1.0+python36
关于: Why I got the message when I ran nms : ModuleNotFoundError: No module named '_ext'
我这边是这样解决的: 设置环境变量:PYTHONHOME = 你自己的python.exe所在路径 (重启下)Okay,我跑起来啦
我这样设置会出现,python停止工作
@heartInsert 我的环境:win10 + cuda10 + torch1.1.0 + python36
关于:
为什么我在运行nms时收到消息:
ModuleNotFoundError:没有名为'_ext'的模块
我这边是这样解决的:
设置环境变量:PYTHONHOME =你自己的python.exe所在路径(重启下)@heartInsert 我的环境:win10+cuda10+torch1.1.0+python36
关于:
Why I got the message when I ran nms :
ModuleNotFoundError: No module named '_ext'
我这边是这样解决的:
设置环境变量:PYTHONHOME = 你自己的python.exe所在路径 (重启下)请问linux里面遇到同样的问题怎么解决呢,我添加了环境变量好像不起作用
I use
python setup.py installto fix this issue in linux.
Thank you so much for solving my problem!
@ausk 非常感谢 我跑成功了
error: command 'E:\vs\VC\Tools\MSVC\14.21.27702\bin\HostX86\x64\link.exe' failed with exit status 1120
请问在运行DCNv2的make.sh中你有遇到这个问题吗?或者你有什么特殊的配置吗?
i follow the step and met this error:
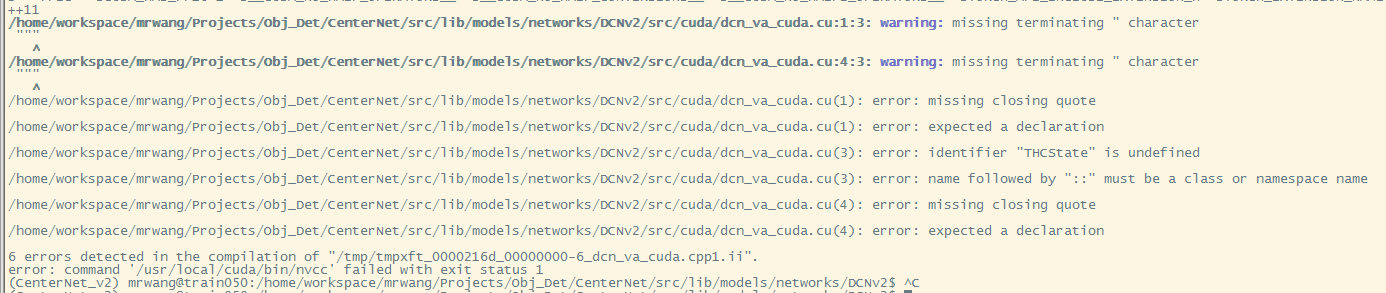
what should i do. thanks
thanks,that's a great news.
thanks a lot
When I run the demo according to the above, I got a following error message.
C:\Users\username\PycharmProjects\CenterNet\src>python demo.py ctdet --demo ../images/17790319373_bd19b24cfc_k.jpg --load_model ../models/ctdet_coco_dla_2x.pth --debug 2
Fix size testing.
training chunk_sizes: [1]
The output will be saved to C:\Users\username\PycharmProjects\CenterNet\src\lib....\exp\ctdet\default
heads {'hm': 80, 'wh': 2, 'reg': 2}
Creating model...
Traceback (most recent call last):
File "demo.py", line 56, in
demo(opt)
File "demo.py", line 21, in demo
detector = Detector(opt)
File "C:\Users\username\PycharmProjects\CenterNet\src\lib\detectors\ctdet.py", line 26, in init
super(CtdetDetector, self).init(opt)
File "C:\Users\username\PycharmProjects\CenterNet\src\lib\detectors\base_detector.py", line 25, in init
self.model = load_model(self.model, opt.load_model)
File "C:\Users\username\PycharmProjects\CenterNet\src\lib\models\model.py", line 34, in load_model
checkpoint = torch.load(model_path, map_location=lambda storage, loc: storage)
File "C:\Users\username\AppData\Local\Continuum\anaconda3\envs\CenterNet\lib\site-packages\torch\serialization.py", line 387, in load
return _load(f, map_location, pickle_module, **pickle_load_args)
File "C:\Users\username\AppData\Local\Continuum\anaconda3\envs\CenterNet\lib\site-packages\torch\serialization.py", line 564, in _load
magic_number = pickle_module.load(f, **pickle_load_args)
ValueError: could not convert string to float: rom:
how it solved it? thanks
I ran into this problem following your steps. What should I do to fix it?If possible, can you share the DCNv2 that you had compiled?Thank you!
D:/Python_project/DCNv2-master/src/cuda/dcn_v2_cuda.cu(11): fatal error C1021: 无效的预处理器命令“extern” error: command 'C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v10.1\\bin\\nvcc.exe' failed with exit status 2
我在跑demo.py时,遇到了错误cuda runtime error(46): all cuda-capable devices are busy or unavailable at [/opt/cuda/conda-bld/pytorch_1544199946412/work/aten/src/thc/generatic/thc/tensormath.cu:14,大家知道如何解决吗?谢谢

First thanks for authors' great work.
This is not an issue. But I just want to say that
CenterNetworks ok onPytorch 1.1 + Cuda10.1 + Win10:.Just
clone CenterNet, compile the nms and DCNv2, download the models, and run the demo.1. build nms
cd CenterNet\src\lib\external #python setup.py install python setup.py build_ext --inplacejust comment the parameter in
setup.pywhen building 'nms' extension to solveinvalid numeric argument '/Wno-cpp':#extra_compile_args=["-Wno-cpp", "-Wno-unused-function"]2. clone and build original DCN2
You may fail to compile DCNv2 when using
Pytorch 1.x, because torch.utils.ffi is deprecated. Then replace DCNv2 using the original repo and [Solved] dcn_v2_cuda.obj : error LNK2001: unresolved external symbol state caused by extern THCState *state; by modifing the line DCNv2/blob/master/src/cuda/dcn_v2_cuda.cu#L11://extern THCState *state; THCState *state = at::globalContext().lazyInitCUDA(); // Modifiedcd CenterNet\src\lib\models\networks rm -rf DCNv2 git clone https://github.com/CharlesShang/DCNv2 cd DCNv2 vim cuda/dcn_va_cuda.cu """ # extern THCState *state; THCState *state = at::globalContext().lazyInitCUDA(); """ python setup.py build develop3. test
cd CenterNet/src python demo.py ctdet --demo ../images/17790319373_bd19b24cfc_k.jpg --load_model ../models/ctdet_coco_dla_2x.pth --debug 2 python demo.py multi_pose --demo ../images/17790319373_bd19b24cfc_k.jpg --load_model ../models/multi_pose_dla_3x.pth --debug 2
I get this Error. how to solve it? thx
error: command 'C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\bin\nvcc.exe' failed with exit status 2
I ran into this problem following your steps. What should I do to fix it?If possible, can you share the DCNv2 that you had compiled?Thank you!
D:/Python_project/DCNv2-master/src/cuda/dcn_v2_cuda.cu(11): fatal error C1021: 无效的预处理器命令“extern” error: command 'C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v10.1\\bin\\nvcc.exe' failed with exit status 2
have you solve it? I get the same error
follwing the instruction when running 'python setup.py build develp' ran into error
" error: identifier "THCState_getCurrentStream" is undefined"
@shivareddy37 (Sorry for the confusing format)
I get the same error with you.
My env is Ubuntu16.04+python3.5+CUDA10.2+cuDNN8.0.3+pytorch1.5.1.
The error is following:
/media/*/Data/PythonProject/CenterNet_My/CenterNet/src/lib/models/networks/DCNv2/src/cuda/dcn_v2_cuda.cu(107): error: identifier "THCState_getCurrentStream" is undefined
/media/*/Data/PythonProject/CenterNet_My/CenterNet/src/lib/models/networks/DCNv2/src/cuda/dcn_v2_cuda.cu(279): error: identifier "THCState_getCurrentStream" is undefined
2 errors detected in the compilation of "/tmp/tmpxft_00005d61_00000000-6_dcn_v2_cuda.cpp1.ii".
error: command '/usr/local/cuda/bin/nvcc' failed with exit status 1
I sloved by change the DCNv2 from DCNv2_latest.
(BTY, changingTHCState_getCurrentStreamtoc10::cuda::getCurrentCUDAStream` may be useful, maybe not, you can try).
Thanks.
@shivareddy37 (Sorry for the confusing format)
I get the same error with you.
My env is Ubuntu16.04+python3.5+CUDA10.2+cuDNN8.0.3+pytorch1.5.1.
The error is following:/media/*/Data/PythonProject/CenterNet_My/CenterNet/src/lib/models/networks/DCNv2/src/cuda/dcn_v2_cuda.cu(107): error: identifier "THCState_getCurrentStream" is undefined /media/*/Data/PythonProject/CenterNet_My/CenterNet/src/lib/models/networks/DCNv2/src/cuda/dcn_v2_cuda.cu(279): error: identifier "THCState_getCurrentStream" is undefined 2 errors detected in the compilation of "/tmp/tmpxft_00005d61_00000000-6_dcn_v2_cuda.cpp1.ii". error: command '/usr/local/cuda/bin/nvcc' failed with exit status 1I sloved by change the DCNv2 from DCNv2_latest.
(BTY, changingTHCState_getCurrentStreamtoc10::cuda::getCurrentCUDAStream` may be useful, maybe not, you can try).
Thanks.
(BTY, changing THCState_getCurrentStream to c10::cuda::getCurrentCUDAStream in DCNv2/src/cuda/dcn_v2_cuda.cu may be useful, maybe not, you can try)
Thanks.
@xingyizhou please update INSTALL.md according to this
@ausk Excuse me. I try to run CenterNet code on env( Pytorch 1.6 + Cuda10.1 + Win10). I can't run the demo.py directly. So I find your issue. I follow your steps,
cd CenterNet\src\lib\external #python setup.py install python setup.py build_ext --inplace
but in first step I have some problems. such as :
running build_ext building 'nms' extension cl.exe /c /nologo /Ox /W3 /GL /DNDEBUG /MD -IC:\ProgramData\Anaconda3\lib\site-packages\numpy\core\include -IC:\ProgramData\Anaconda3\include -IC:\ProgramData\Anaconda3\include /Tcnms.c /Fobuild\temp.win-amd64-3.7\Release\nms.obj error: command 'cl.exe' failed: No such file or directory
I try to address the problem by installing the visual studio 2017, and set the path of cl. Meanwhile I open the Visual C++ 2015 x64 Native Build Tools Command Prompt. In this tool, input cl can find the cl.exe, I do the step 1 also, but it's the same problem:
error:command 'cl.exe' failed: No such file or directory
so I mess up. Could you explain it? Would you like to help me,please. Thanks so much.
@ausk Thank you for sharing the installation recipe, I am trying to run CenterNet on pytorch 1.6, I followed your steps and I'm failing on the second stage, building the DCNv2 from the original repo.
python setup.py build develop
outputs:
Traceback (most recent call last):
File "setup.py", line 70, in
cmdclass={"build_ext": torch.utils.cpp_extension.BuildExtension},
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/site-packages/setuptools/init.py", line 145, in setup
return distutils.core.setup(**attrs)
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/distutils/core.py", line 148, in setup
dist.run_commands()
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/distutils/dist.py", line 966, in run_commands
self.run_command(cmd)
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/distutils/command/build.py", line 135, in run
self.run_command(cmd_name)
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/distutils/cmd.py", line 313, in run_command
self.distribution.run_command(command)
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/site-packages/setuptools/command/build_ext.py", line 84, in run
_build_ext.run(self)
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/site-packages/Cython/Distutils/old_build_ext.py", line 186, in run
_build_ext.build_ext.run(self)
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/distutils/command/build_ext.py", line 340, in run
self.build_extensions()
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/site-packages/torch/utils/cpp_extension.py", line 649, in build_extensions
build_ext.build_extensions(self)
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/site-packages/Cython/Distutils/old_build_ext.py", line 195, in build_extensions
_build_ext.build_ext.build_extensions(self)
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/distutils/command/build_ext.py", line 449, in build_extensions
self._build_extensions_serial()
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/distutils/command/build_ext.py", line 474, in _build_extensions_serial
self.build_extension(ext)
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/site-packages/setuptools/command/build_ext.py", line 205, in build_extension
_build_ext.build_extension(self, ext)
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/distutils/command/build_ext.py", line 534, in build_extension
depends=ext.depends)
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/site-packages/torch/utils/cpp_extension.py", line 478, in unix_wrap_ninja_compile
with_cuda=with_cuda)
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/site-packages/torch/utils/cpp_extension.py", line 1233, in _write_ninja_file_and_compile_objects
error_prefix='Error compiling objects for extension')
File "/apps/conda/anaconda/envs/deci-development/lib/python3.7/site-packages/torch/utils/cpp_extension.py", line 1529, in _run_ninja_build
raise RuntimeError(message)
RuntimeError: Error compiling objects for extension
Any idea how to overcome and build for pytorch 1.6?
other envs:
torchvision 0.7.0
CUDA 10.2
Thanks in advance
After 3 days of trying, I work it out.
No matter which of the following errors occur:
'C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin\nvcc.exe' failed with exit status 2
error: command 'D:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\BIN\x86_amd64\cl.exe' failed with exit status 2
VS2015 and VS2019 don't work!
solution:
Just uninstall VS2019 and install VS2017!
Only VS2017 works!
After 3 days of trying, I work it out.
No matter which of the following errors occur:
'C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin\nvcc.exe' failed with exit status 2
error: command 'D:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\BIN\x86_amd64\cl.exe' failed with exit status 2VS2015 and VS2019 don't work!
solution:
Just uninstall VS2019 and install VS2017!
Only VS2017 works!
OK, I will try VS2017 later
Have you compiled nms?
cd src/lib/external,make
I got this error when I ran it:
C:\Users\sopul\CenterNet\src\lib\external>make
python setup.py build_ext --inplace
running build_ext
rm -rf build
process_begin: CreateProcess(NULL, rm -rf build, ...) failed.
make (e=2): The system cannot find the file specified.
make: *** [Makefile:3: all] Error 2
hello,I would like to run this modify in my Pytorch 1.9 + Cuda10.2 + Win10 , so I try this mode this suggestion .but when I build nms, I follow the guide run
cd CenterNet\src\lib\external
#python setup.py install
python setup.py build_ext --inplace
but I meet a bug ValueError: 'nms.pyx' doesn't match any files
this is the delatied error
(pytorchtest) D:\CenterNet-master>python src/lib/external/setup.py build_ext --inplace
Traceback (most recent call last):
File "src/lib/external/setup.py", line 16, in <module>
ext_modules=cythonize(extensions),
File "C:\Users\11427\anaconda3\envs\pytorchtest\lib\site-packages\Cython\Build\Dependencies.py", line 972, in cython
ize
aliases=aliases)
File "C:\Users\11427\anaconda3\envs\pytorchtest\lib\site-packages\Cython\Build\Dependencies.py", line 815, in create
_extension_list
for file in nonempty(sorted(extended_iglob(filepattern)), "'%s' doesn't match any files" % filepattern):
File "C:\Users\11427\anaconda3\envs\pytorchtest\lib\site-packages\Cython\Build\Dependencies.py", line 114, in nonemp
ty
raise ValueError(error_msg)
ValueError: 'nms.pyx' doesn't match any files

I google this bug,but I can't resolve it .so could you help me settle this bug
I got this error when I am running this code
python setup.py build develop
Error:
/content/CenterNet/src/lib/models/networks/DCNv2/src/cpu/dcn_v2_cpu.cpp:227:51: warning: ‘T* at::Tensor::data() const [with T = float]’ is deprecated: Tensor.data<T>() is deprecated. Please use Tensor.data_ptr<T>() instead. [-Wdeprecated-declarations] grad_bias.data<scalar_t>(), 1); ^ In file included from /usr/local/lib/python3.7/dist-packages/torch/include/ATen/Tensor.h:3:0, from /usr/local/lib/python3.7/dist-packages/torch/include/ATen/Context.h:4, from /usr/local/lib/python3.7/dist-packages/torch/include/ATen/ATen.h:9, from /content/CenterNet/src/lib/models/networks/DCNv2/src/cpu/dcn_v2_cpu.cpp:4: /usr/local/lib/python3.7/dist-packages/torch/include/ATen/core/TensorBody.h:216:7: note: declared here T * data() const { ^~~~ /content/CenterNet/src/lib/models/networks/DCNv2/src/cpu/dcn_v2_cpu.cpp:224:9: error: ‘THFloatBlas_gemv’ was not declared in this scope THFloatBlas_gemv('t', k_, m_, 1.0f, ^~~~~~~~~~~~~~~~ /content/CenterNet/src/lib/models/networks/DCNv2/src/cpu/dcn_v2_cpu.cpp:224:9: note: suggested alternative: ‘THFloatStorage’ THFloatBlas_gemv('t', k_, m_, 1.0f, ^~~~~~~~~~~~~~~~ THFloatStorage error: command 'g++' failed with exit status 1
Anyone knows how to solve this?
external is failed (CenterNet) D:\research\CenterNet-master\src\lib\external>python setup.py install running install running build running build_ext building 'nms' extension D:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\BIN\x86_amd64\cl.exe /c /nologo /Ox /W3 /GL /DNDEBUG /MD -ID:\Anaconda3\envs\CenterNet\lib\site-packages\numpy\core\include -ID:\Anaconda3\envs\CenterNet\include -ID:\Anaconda3\envs\CenterNet\include "-ID:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\INCLUDE" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.10240.0\ucrt" "-IC:\Program Files (x86)\Windows Kits\NETFXSDK\4.6.1\include\um" "-IC:\Program Files (x86)\Windows Kits\8.1\include\shared" "-IC:\Program Files (x86)\Windows Kits\8.1\include\um" "-IC:\Program Files (x86)\Windows Kits\8.1\include\winrt" /Tcnms.c /Fobuild\temp.win-amd64-3.6\Release\nms.obj -Wno-cpp -Wno-unused-function cl : Command line error D8021 : invalid numeric argument '/Wno-cpp' error: command 'D:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\BIN\x86_amd64\cl.exe' failed with exit status 2
I'm also get this problem,so have you resolved the problems?
After 3 days of trying, I work it out. No matter which of the following errors occur: 'C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin\nvcc.exe' failed with exit status 2 error: command 'D:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\BIN\x86_amd64\cl.exe' failed with exit status 2
VS2015 and VS2019 don't work! solution: Just uninstall VS2019 and install VS2017! Only VS2017 works!
I have installed vs2017 but still report this error, how to solve it
Thanks a Lot. After effort of one week i successfully ran demo with windows 10, pytorch 1.1.0. I wish i had read this issue
before
Can you make tutorial to do this, please!
Has anyone managed with torch 2.0.1?
I replaced DCNv2 using the original repo and then got this while compiling using ./make.sh:
RuntimeError:
The detected CUDA version (9.1) mismatches the version that was used to compile
PyTorch (11.7). Please make sure to use the same CUDA versions.