JavaScript 深入系列之深拷贝的实现
yuanyuanbyte opened this issue · 0 comments
本系列的主题是 JavaScript 深入系列,每期讲解一个技术要点。如果你还不了解各系列内容,文末点击查看全部文章,点我跳转到文末。
如果觉得本系列不错,欢迎 Star,你的支持是我创作分享的最大动力。
一、什么是深拷贝?深拷贝和浅拷贝有什么区别?
浅拷贝是指只复制第一层对象,但是当对象的属性是引用类型时,实质复制的是其引用,当引用指向的值改变时也会跟着变化。
深拷贝复制变量值,对于非基本类型的变量,则递归至基本类型变量后,再复制。深拷贝后的对象与原来的对象是完全隔离的,互不影响,对一个对象的修改并不会影响另一个对象。
二、JS 的变量存储类型
变量存储类型分两类
-
基本类型:直接存储在栈中的数据。(字符串、布尔值、数字、undefined、null)
-
引用类型:将该对象引用地址存储在栈中,然后对象里面的数据存放在堆中。(数组、对象、Date、RegExp、函数、特殊的基本包装类型以及单体内置对象)
特殊的基本包装类型(String、Number、Boolean)以及单体内置对象(Global、Math)
1. 基本类型的变量是存放在栈区的(栈区指内存里的栈内存)
假如有以下几个基本类型的变量:
var name = 'jozo';
var city = 'guangzhou';
var age = 22;那么它的存储结构如下图:

栈区包括了 变量的标识符和变量的值。
2. 引用类型的变量将对象引用地址存储在栈中,对象里面的数据存放在堆中
JavaScript 和其他语言不同,其不允许直接访问内存中的位置,也就是说不能直接操作对象的内存空间,那我们操作啥呢? 实际上,是操作对象的引用,所以引用类型的值是按引用访问的。
准确地说,引用类型的存储需要内存的栈区和堆区(堆区是指内存里的堆内存)共同完成,栈区内存保存变量标识符和指向堆内存中该对象的指针,也可以说是该对象在堆内存的地址。
假如有以下几个对象:
var person1 = {name:'jozo'};
var person2 = {name:'xiaom'};
var person3 = {name:'xiaoq'};则这三个对象的在内存中保存的情况如下图:

3. 简单赋值
在从一个变量向另一个变量赋值基本类型时,会在该变量上创建一个新值,然后再把该值复制到为新变量分配的位置上:
var a = 10;
var b = a;
a ++ ;
console.log(a); // 11
console.log(b); // 10此时,a中保存的值为 10 ,当使用 a 来初始化 b 时,b 中保存的值也为10,但b中的10与a中的是完全独立的,该值只是a中的值的一个副本,此后,这两个变量可以参加任何操作而相互不受影响。

也就是说基本类型在赋值操作后,两个变量是相互不受影响的。
4. 对象引用
当从一个变量向另一个变量赋值引用类型的值时,同样也会将存储在变量中的对象的值复制一份放到为新变量分配的空间中。前面讲引用类型的时候提到,保存在变量中的是对象在堆内存中的地址,所以,与简单赋值不同,这个值的副本实际上是一个指针,而这个指针指向存储在堆内存的一个对象。那么赋值操作后,两个变量都保存了同一个对象地址,则这两个变量指向了同一个对象。因此,改变其中任何一个变量,都会相互影响:
var a = {}; // a保存了一个空对象的实例
var b = a; // a和b都指向了这个空对象
a.name = 'jozo';
console.log(a.name); // 'jozo'
console.log(b.name); // 'jozo'
b.age = 22;
console.log(b.age);// 22
console.log(a.age);// 22
console.log(a == b);// true它们的关系如下图:
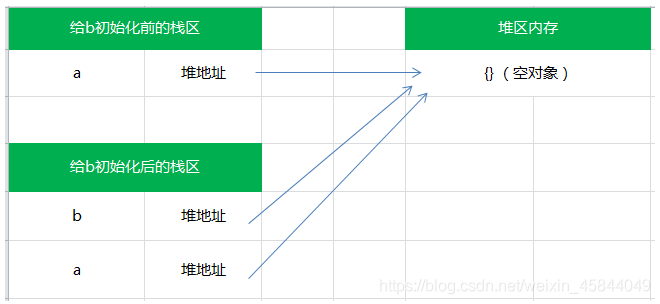
因此,引用类型的赋值其实是对象保存在栈区地址指针的赋值,因此两个变量指向同一个对象,任何的操作都会相互影响。
三、深拷贝和浅拷贝
最后再来看深拷贝和浅拷贝还有赋值的区别,这样就好理解多了
浅拷贝:也就是拷贝A对象里面的数据,但是不拷贝A对象里面的子对象
深拷贝:会克隆出一个对象,数据相同,但是引用地址不同(就是拷贝A对象里面的数据,而且拷贝它里面的子对象)
赋值:简单赋值和对象引用,对象引用获得该对象的引用地址
四、JSON.parse(JSON.stringify())
在不使用第三方库的情况下,想要深拷贝一个对象,一般来讲最简单的用的最多的就是 JSON.parse(JSON.stringify(obj)),其过程说白了就是利用 JSON.stringify 将 JS 对象序列化(JSON字符串),再使用 JSON.parse 来反序列化(还原) JS 对象。
JSON.parse(JSON.stringify(obj));这种写法非常简单,而且可以应对大部分的应用场景,但注意 JSON 只能用来序列化对象、数组、数值、字符串、布尔值和 null,依靠 JSON 深拷贝时存在很大缺陷,原因在于 JSON.stringify() 在序列化时会有以下问题:
1、时间对象序列化后会变成字符串;
const target = {
name: 'Jack',
date: [new Date(1536627600000), new Date(1540047600000)]
};
JSON.parse(JSON.stringify(target));
Date 日期调用了 toJSON() 将其转换为了 string 字符串(同 Date.toISOString()),因此会被当做字符串处理。
JSON.stringify(new Date(1536627600000));
// '"2018-09-11T01:00:00.000Z"'2、RegExp、Error 对象序列化后将只得到空对象;
const target = {
re: new RegExp("\\w+"),
err: new Error('"x" is not defined')
};
JSON.stringify(target);
// '{"re":{},"err":{}}'
3、任意的函数、undefined 以及 symbol 值,在序列化过程中会被忽略;
const target = {
func: function () {
console.log(1)
},
val: undefined,
sym: Symbol('foo')
};
JSON.stringify(target);
// '{}'
4、NaN 和 Infinity 格式的数值都会被当做 null;
1.7976931348623157E+10308是浮点数的最大上限 显示为 Infinity-1.7976931348623157E+10308是浮点数的最小下限 显示为 -Infinity

const target = {
nan: NaN,
infinityMax: 1.7976931348623157E+10308,
infinityMin: -1.7976931348623157E+10308,
};
JSON.stringify(target);
// '{"nan":null,"infinityMax":null,"infinityMin":null}'
5、对包含循环引用的对象(对象之间相互引用,形成无限循环)序列化,会抛出错误。
var circularReference = { otherData: 123 };
circularReference.myself = circularReference;
JSON.stringify(circularReference);
// TypeError: cyclic object value(Firefox) 或 Uncaught TypeError: Converting circular structure to JSON(Chrome and Opera)
在 JSON 中出现循环引用时,JavaScript 会抛出 "cyclic object value" 的异常。
JSON.stringify()并不会尝试解决这个问题,因此导致运行失败。
- 提示信息:
- TypeError: cyclic object value (Firefox)
- TypeError: Converting circular structure to JSON (Chrome and Opera)
- TypeError: Circular reference in value argument not supported (Edge)
五、深拷贝
通过递归实现深拷贝:
function deepClone(obj) { // 递归拷贝
if (typeof obj !== 'object' || obj === null) return obj; // 如果不是复杂数据类型 或者为null,直接返回
if (obj instanceof RegExp) return new RegExp(obj);
if (obj instanceof Date) return new Date(obj);
let cloneObj = Array.isArray(obj) ? [] : {};
for (let key in obj) {
// 判断是否是对象自身的属性,筛掉对象原型链上继承的属性
if (obj.hasOwnProperty(key)) {
// 如果 obj[key] 是复杂数据类型,递归
cloneObj[key] = deepClone(obj[key]);
}
}
return cloneObj;
}我们应该拷贝要拷贝对象自身的属性,对象原型上的属性我们不应该拷贝,这里我们用到 hasOwnProperty() 方法来解决。
hasOwnProperty() 方法会返回一个布尔值,这个方法可以用来检测一个对象是否含有特定的自身属性;该方法会忽略掉那些从原型链上继承到的属性。
1. 循环引用
循环引用会使递归进入死循环导致栈内存溢出。
我们拷贝一下前面循环引用的例子:
var circularReference = { otherData: 123 };
circularReference.myself = circularReference;
deepClone(circularReference);
// Uncaught RangeError: Maximum call stack size exceeded 超出最大调用堆栈大小解决循环引用问题,可以额外开辟一个存储空间,来存储当前对象和拷贝对象的对应关系,当需要拷贝当前对象时,先去存储空间中找,有没有拷贝过这个对象,如果有的话直接返回,如果没有的话继续拷贝,这样就巧妙化解的循环引用的问题。
这个存储空间,需要可以存储 key-value 形式的数据,且 key 可以是一个引用类型,我们可以选择 Map 这种数据结构:
- 检查
map中有无克隆过的对象 - 有 - 直接返回
- 没有 - 将当前对象作为
key,克隆对象作为value进行存储 - 继续克隆
function deepClone(obj, map = new Map()) { // 递归拷贝
if (typeof obj !== 'object' || obj === null) return obj; // 如果不是复杂数据类型 或者为null,直接返回
if (obj instanceof RegExp) return new RegExp(obj);
if (obj instanceof Date) return new Date(obj);
if (map.has(obj)) return map.get(obj);
let cloneObj = Array.isArray(obj) ? [] : {};
map.set(obj, cloneObj);
for (let key in obj) {
// 判断是否是对象自身的属性,筛掉对象原型链上继承的属性
if (obj.hasOwnProperty(key)) {
// 如果 obj[key] 是复杂数据类型,递归
cloneObj[key] = deepClone(obj[key], map);
}
}
return cloneObj;
}再次执行前面的用例可以发现没有报错,循环引用的问题解决了。
2. 使用 WeakMap 优化
下面我们用 WeakMap 替代 Map 来优化深拷贝的实现。
如下:
function deepClone(obj, map = new WeakMap()) {
// ...
};
为什么要这样做呢?先来看看 WeakMap 的作用:
WeakMap 对象是一组键/值对的集合,其中的键是弱引用的。其键必须是对象,而值可以是任意的。
什么是弱引用呢?
在计算机程序设计中,弱引用与强引用相对,是指不能确保其引用的对象不会被垃圾回收器回收的引用。 一个对象若只被弱引用所引用,则被认为是不可访问(或弱可访问)的,并因此可能在任何时刻被回收。
我们默认创建一个对象:const obj = {},就默认创建了一个强引用的对象,我们只有手动将 obj = null,它才会被垃圾回收机制进行回收,如果是弱引用对象,垃圾回收机制会自动帮我们回收。
举个例子:
如果我们使用 Map 的话,那么对象间是存在强引用关系的:
let obj = { name : 'Jack'}
const target = new Map();
target.set(obj,'person');
obj = null;虽然我们手动将 obj,进行释放,然是 target 依然对 obj 存在强引用关系,所以这部分内存依然无法被释放。
再来看 WeakMap:
let obj = { name : 'Jack'}
const target = new WeakMap();
target.set(obj,'person');
obj = null;如果是 WeakMap 的话,target 和 obj 存在的就是弱引用关系,当下一次垃圾回收机制执行时,这块内存就会被释放掉。
设想一下,如果我们要拷贝的对象非常庞大时,使用 Map 会对内存造成非常大的额外消耗,而且我们需要手动清除 Map 的属性才能释放这块内存,而 WeakMap 会帮我们巧妙化解这个问题。
我也经常在某些代码中看到有人使用 WeakMap 来解决循环引用问题,但是解释都是模棱两可的,当你不太了解 WeakMap 的真正作用时。我建议你也不要在面试中写这样的代码,结果只能是给自己挖坑,即使是准备面试,你写的每一行代码也都是需要经过深思熟虑并且非常明白的。
能考虑到循环引用的问题,你已经向面试官展示了你考虑问题的全面性,如果还能用 WeakMap 解决问题,并很明确的向面试官解释这样做的目的,那么你的代码在面试官眼里应该算是合格了。
- 循环引用部分内容出自
ConardLi大佬如何写出一个惊艳面试官的深拷贝?。
参考
- 如何写出一个惊艳面试官的深拷贝?
- JavaScript专题之深浅拷贝
- TypeError: cyclic object value
- 浅拷贝与深拷贝
- 探秘 JavaScript 世界的神秘数字 1.7976931348623157e+308
- 深拷贝的终极探索(99%的人都不知道)
- Map
- JSON
- JSON.parse(JSON.stringify()) 实现对对象的深拷贝
- JSON.parse(JSON.stringify(obj))实现深拷贝的弊端以及解决方法
博文系列目录
- JavaScript 深入系列
- JavaScript 专题系列
- JavaScript 基础系列
- 网络系列
- 浏览器系列
- Webpack 系列
- Vue 系列
- 性能优化与网络安全系列
- HTML 应知应会系列
- CSS 应知应会系列
交流
各系列文章汇总:https://github.com/yuanyuanbyte/Blog
我是圆圆,一名深耕于前端开发的攻城狮。
