Deep-Atrous-CNN-Text-Network: End-to-end word level model for sentiment analysis and other text classifications
A Deep Atrous CNN architecture suitable for text (sentiment) classification with variable length.
The architecture substitutes the typical CONV->POOL->CONV->POOL->...->CONV->POOL->SOFTMAX architectures, instead to speed up computations it uses atrous convolutions which are resolution perserving. Another great property of these type of networks is the short travel distance between the first and last words, where the path between them is bounded by C*log(d) steps, where C is a constant and d is the length of the input sequence.
The architecture is inspired by the Neural Machine Translation in Linear Time and Convolutional Neural Networks for Sentence Classification.
Where the Atrous CNN layers are similar to the ones in the bytenet encoder in Neural Machine Translation in Linear Time and the max-over-time pooling idea was inspired from the Convolutional Neural Networks for Sentence Classification paper.
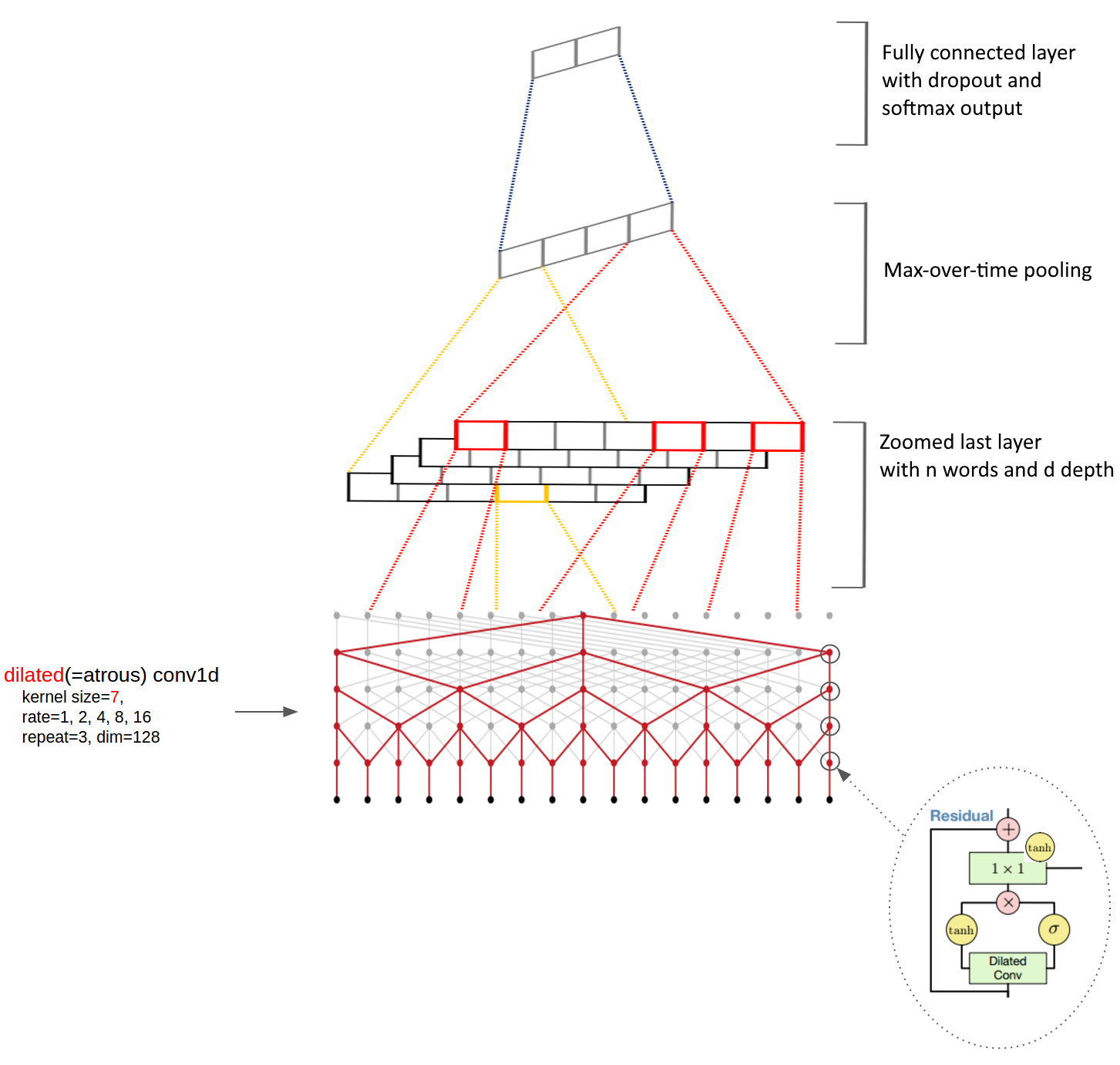
The network support embedding initialization with pre-trained GloVe vectors (GloVe: Gloval Vectors for Word Representations) which handle even rare words quite well compared to word2vec.
To speed up training the model pre-processes any input into "clean" file, which then utilizes for training. The data is read by line from the "clean" files for better memory management. All input data is split into the appropriate buckets and dynamic padding is applied, which provides better accuracy and speed up during training. The input pipeline can read from multiple data sources which makes addition of more data sources easy as long as they are preprocessed in the right format. The model can be trained on multiple GPUs if the hardware provides this capability.
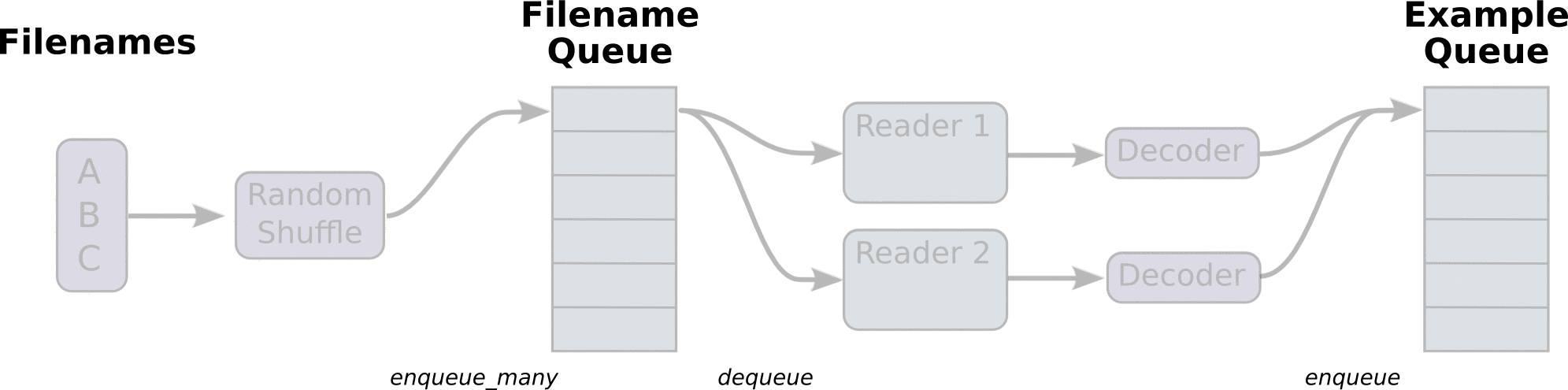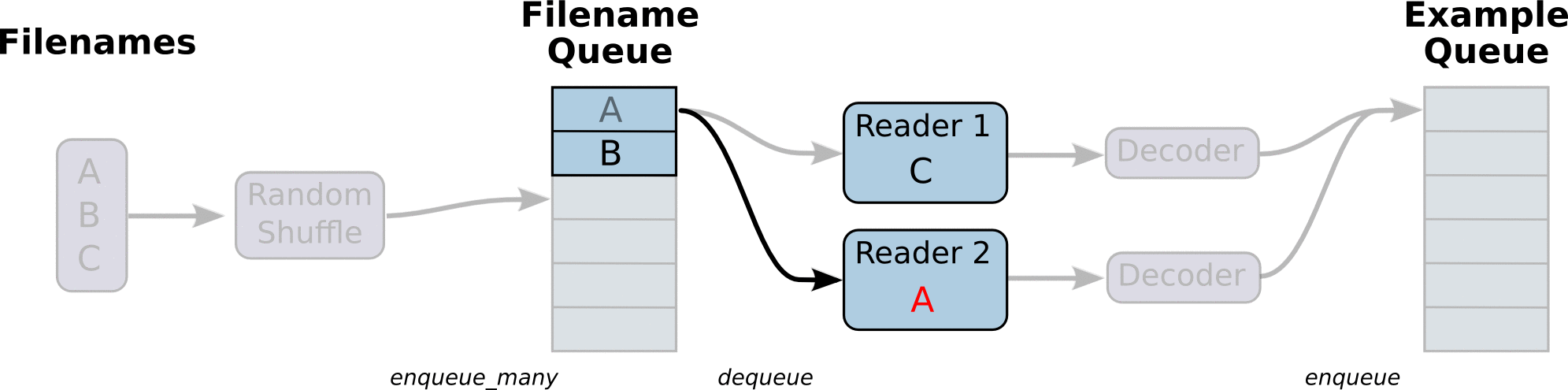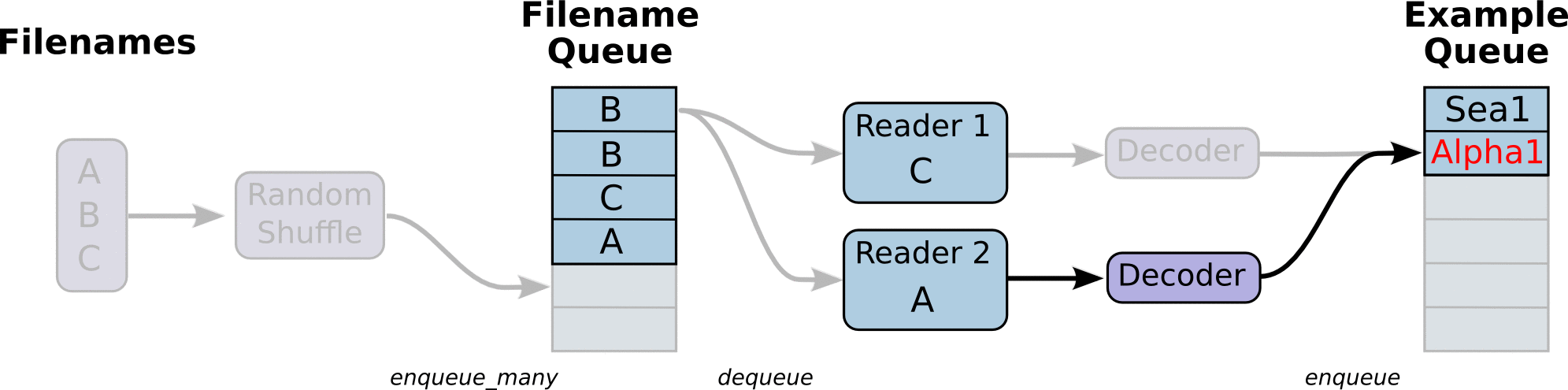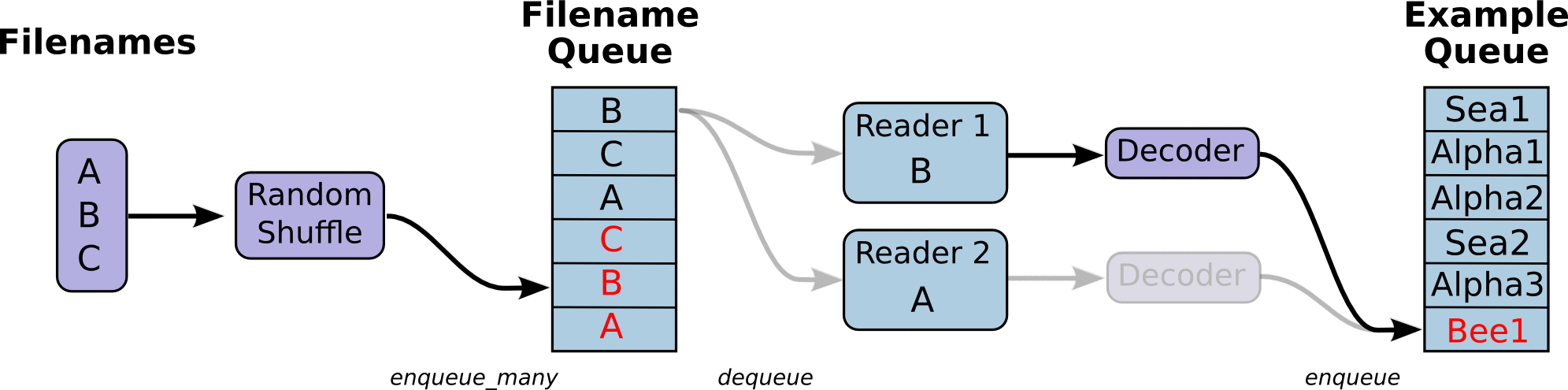
(Some images are cropped from WaveNet: A Generative Model for Raw Audio, Neural Machine Translation in Linear Time and Tensorflow's Reading Data Tutorial)
Current version : 0.0.0.1
- python3.5
- arrow==0.10.0
- numpy==1.13.0
- pandas==0.20.2
- protobuf==3.3.0
- python-dateutil==2.6.0
- pytz==2017.2
- six==1.10.0
- sugartensor==1.0.0.2
- tensorflow==1.2.0
- tqdm==4.14.0
- python3.5 -m pip install -r requirements.txt
- install tensorflow or tensorflow-gpu, depending on whether your machine supports GPU configurations
Currently the only supported dataset is the one provided by the Bag of Words Meets Bags of Popcorn challenge, instructions how to obtain and preprocess it can be found here
The Kaggle dataset contains 25,000 labeled examples of movie reviews. Positive movie reviews are labeled with 1, while negative movie reviews are labeled with 0. The dataset is split into 20,000 training and 5,000 validation examples.
The model can be trained across multiple GPUs to speed up the computations. In order to start the training:
Execute
python train.py ( <== Use all available GPUs )
or
CUDA_VISIBLE_DEVICES=0,1 python train.py ( <== Use only GPU 0, 1 )
Currently the model achieves up to 97% accuracy on the validation set.
In order to monitor the training, validation losses and accuracy and other interesting metrics like gradients, activations, distributions, etc. across layers do the following:
# when in the project's root directory
bash launch_tensorboard.sh
then open your browser http://localhost:6008/
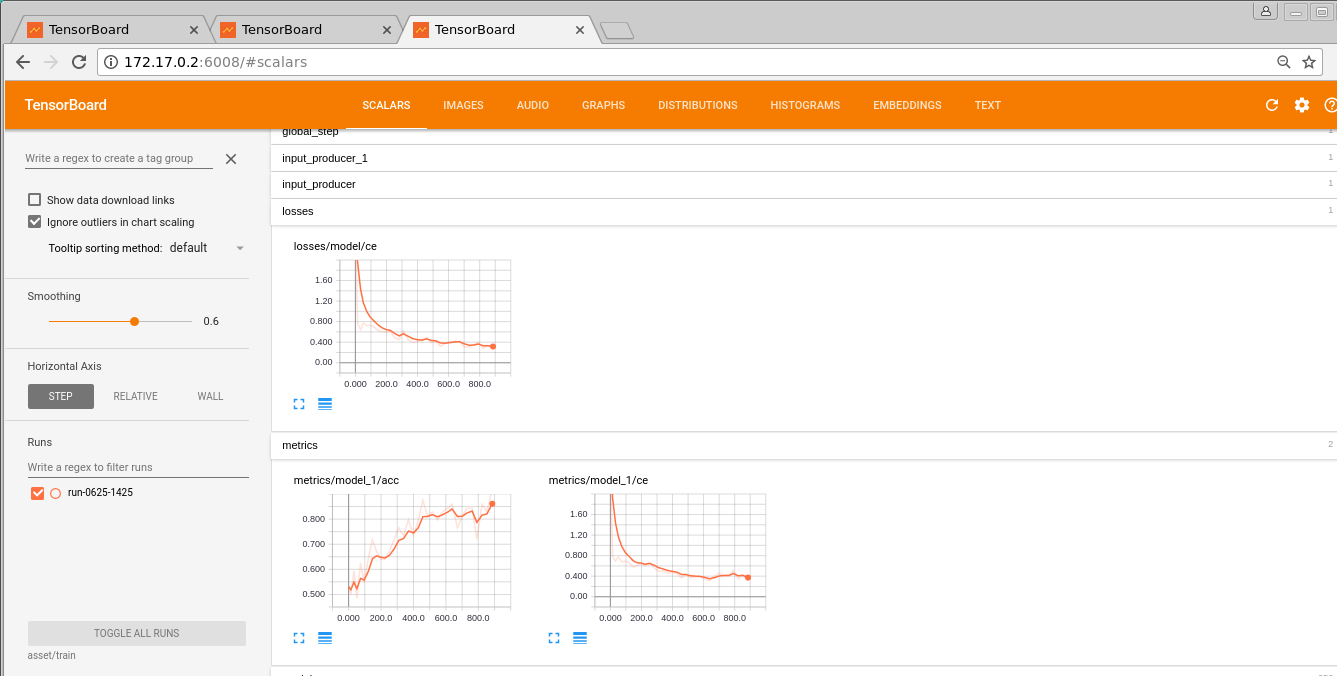
(kudos to sugartensor for the great tf wrapper which handles all the monitoring out of the box)
This version of the model provides interactive testing, in order to start it, execute:
python test.py ( <== Use all available GPUs )
or
CUDA_VISIBLE_DEVICES=0,1 python test.py ( <== Use only GPU 0, 1 )
The console will ask for input, some sample manual test over examples of the dataset:
>this is an intimate movie of a sincere girl in the real world out of hollywoods cheap fantasy is a very good piece of its class , and ashley judd fills the role impeccably . it may appear slo
w for thrill seekers though . cool movie for a calm night . br br
> Sentiment score: 0.538484
>the silent one - panel cartoon henry comes to fleischer studios , billed as the worlds funniest human in this dull little cartoon . betty , long past her prime , thanks to the production code
, is running a pet shop and leaves henry in charge for far too long - - five minutes . a bore .
> Sentiment score: 0.0769837
>in her first nonaquatic role , esther williams plays a school teacher whos the victim of sexual assault . she gives a fine performance , proving she could be highly effective out of the swimm
ing pool . as the detective out to solve the case , george nader gives perhaps his finest performance . and he is so handsome it hurts ! john saxon is the student under suspicion , and althoug
h he gets impressive billing in the credits , its edward andrews as his overly - protective father who is the standout . br br bathed in glorious technicolor , the unguarded moment is irresist
ible hokum and at times compelling drama .
> Sentiment score: 0.832277
- Increase the number of supported datasets
- Put everything into Docker
- Create a REST API for an easy deploy as a service
If you find this code useful please cite me in your work:
George Stoyanov. Deep-Atrous-CNN-Text-Network. 2017. GitHub repository. https://github.com/randomrandom.
George Stoyanov (george@ai.hacker.works) at AiWorks.