JavaScript异步编程之事件循环
Opened this issue · 0 comments
我的github博客 https://github.com/zhuanyongxigua/blog
最基本的事件循环模型
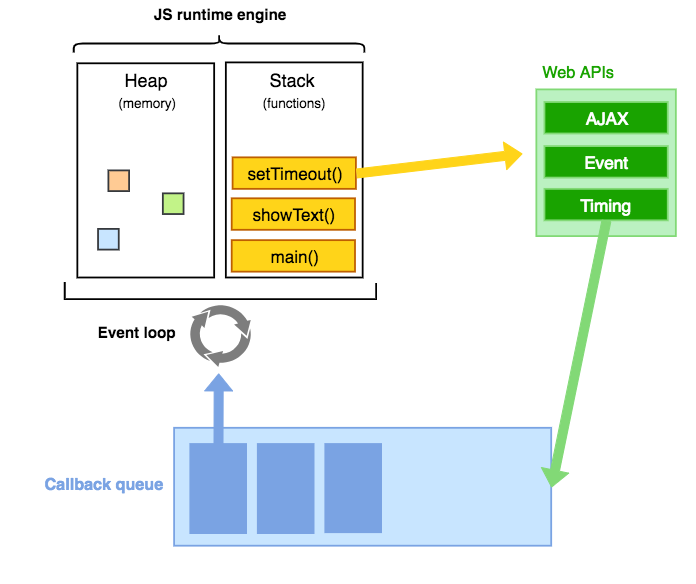
相信想搞清楚node与浏览器事件循环区别的人,对于JavaScript运行机制的简单认知应该是没有问题的。简单总结一下:程序开始运行,同步代码进入调用栈(即图中stack)运行,异步代码交给浏览器处理,处理完毕的(如timeout规定时间到达,ajax请求服务端响应返回等)进入任务队列(即图中的callback queue),当调用栈中的代码执行完毕之后,任务队列中的任务以先进先出的原则进入调用栈依次执行,如果执行过程中再次产生异步操作,则同样交给浏览器处理,待处理完毕后进入任务队列,等到调用栈中的任务再次执行完毕之后,任务队列中的任务同样以先进先出的原则进入调用栈,这样不断地循环下去。
这个网页中对这个过程的演示非常的清楚。
进一步的理解
实际上事件循环中的队列并不是只有一个,而是两个,一个是task(macrotask) queue,另一个是microtask queue。
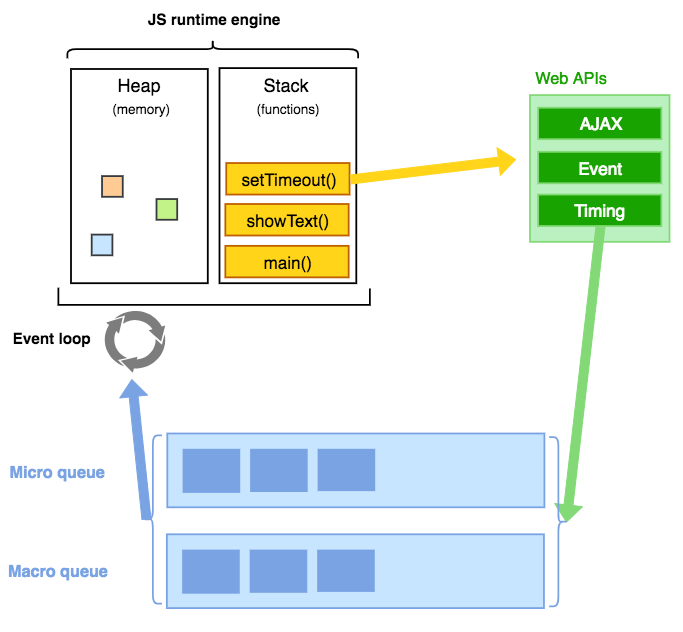
简单的说,microtask queue的处理会先于task queue。这样分开了之后会产生两个明显的差别:队列有了明显的先后顺序,并且理论上当microtask queue中不断的产生新的microtask时,macrotask queue将永远不会进入调用栈。例如:
setTimeout(() => {
console.log('timeout');
});
function a(cb) {
Promise.resolve().then(data => {
console.log("Promise");
a();
})
}
a();不信可以拿到你的浏览器里面试试,当然更有可能出现的结果是页面崩溃。
node中的事件循环
上一个部分中的提到的宏任务与微任务,实际上是HTML的标准,也就是在浏览器环境中的运行情况,而node是与浏览器差异很大的运行环境,在node中并没有这样的概念。
网络上一个流传很广的分类方式:
macrotask:setTimeout setInterval setImmediate I/O;
microtask:Promise process.nextTick Object.observe MutationObserver。
这种分类方式是很值得怀疑的。如果放在浏览器中,浏览器环境并没有process.nextTick。如果放在node中,这种方式不但过于粗糙,而且不完全正确。不正确是因为MutationObserver,这个API是用来监听DOM的。粗糙是因为nodejs的事件循环队列有很多个,比如process.nextTick,它有一个单独的队列,它比microtask(先这样理解)还要提前被处理,例如:
var counter = 0;
setTimeout(() => {
console.log('timeout');
});
Promise.resolve().then(data => {
console.log("Promise");
})
function a() {
process.nextTick(data => {
console.log("nextTick");
if (counter >= 20) return;
counter++;
a();
})
}
a();运行结果为:
nextTick
nextTick
...
nextTick
nextTick
Promise
timeout正如上一部分内容说的microtask会卡住macrotask一样,process.nextTick不但会卡住macrotask,还会卡住microtask。
所以,如果你想先用microtask和macrotask这种方式理解,也是可以的,只不过需要对前面所说的分类方式做一点修改:
macrotask:setTimeout setInterval setImmediate I/O;
process.nextTick:process.nextTick;
microtask:Promise Object.observe。
继续完善
虽然做了改进,可是这种分类方式依然过于粗糙。对于事件循环,nodejs实际上有自己的运行机制,也就是libuv。还是拿上面的分类做修改:
macrotaskOne:setTimeout setInterval;
macrotaskTwo:I/O操作;
macrotaskThree:setImmediate;
macrotaskFour:close操作;
process.nextTick:process.nextTick;
microtask:Promise Object.observe。
队列又变多了,但并没有变得特别的复杂。回想一下第二部分内容中增加了microtask queue之后的变化,在这里也是非常相似的,每个队列都要在清空了之后才会进入下一个队列。另外需要注意的是,microtask和process.nextTick整体优先于macrotask,在每个macrotask queue完成之前都会执行一次。如图:

需要注意的是,虽然setTimeout在setImmediate的前面,可是实际执行的时候,结果可能是不确定的。例如:
// timeout_vs_immediate.js
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});两种结果都有可能出现:
$ node timeout_vs_immediate.js
timeout
immediate
$ node timeout_vs_immediate.js
immediate
timeout原因是在实际运行的时候,node内部的运算也需要时间,所以当运行到macrotaskOne的时候,如果node花费的时间稍长,可能就会错过这一次执行。
可如果代码这样写,结果就是确定的:
// timeout_vs_immediate.js
const fs = require('fs');
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});结果为:
$ node timeout_vs_immediate.js
immediate
timeout
$ node timeout_vs_immediate.js
immediate
timeout原因是fs.readFile的回调是在macrotaskTwo阶段,这个时候添加的异步操作被立即(当处理完毕后,比如setTimeout到达了设定的时间)放到各自所属的队列中,而macrotaskTwo之后就是macrotaskThree队列,及setImmediate的操作,所以,此时setImmdiate一定会提前与setTimeout。
macrotaskOne这种名字是为了帮助理解才加上去的,最后把各个阶段的名称改成node正真正的名称:
timers:setTimeout setInterval;
poll:I/O操作;
check:setImmediate;
close callbacks:close操作;
process.nextTick:process.nextTick;
microtask:Promise Object.observe。
参考资料: