使用Librosa音频处理库和openSMILE工具包,进行简单的声学特征提取,包括韵律学特征(持续时间、短时能量、过零率、基频等)、基于谱的相关特征(MFCC特征)和声音质量特征(共振峰、频率微扰、振幅微扰)。
如果您觉得有一点点用,请隔空比个心(或者,点一下 "Star" 也可以~)
ReadMe Language | 中文版 | English |
- 写在前面
在这之前,本人对于声学一窍不通,奈何实验室项目需求,看了一些文献和博客,这才算是刚刚入了门,尽管坎坷,但发现细品声学,还是挺有意思的。
本程序基于python3.6开发,Windows10上运行,其他版本暂时没有测试过,但我感觉python3.x,ubuntu平台应该都可以正常运行,不行的话,按照报错稍微修改适配下,程序里每行我尽量都做了注释。
注意:由于本人也是边学边搞的这个程序,很多专业的声学名词我也是一知半解,没有深入研究,根据所能理解的,再加上自己的一些理解,写成的这个程序(也许叫demo更好),难免会出现提取到的特征不准确的现象,尤其是在基频追踪、共振峰估计上,方法不同,准确度千差万别,可以尝试更改参数、使用最新的算法,或者直接使用本程序中利用openSMILE特征集提取的特征,避免重复造轮子,又有大厂保证~
- 关于本程序
本程序利用两种方法对声学特征进行了提取,一种是直接调用openSMILE中的特征配置文件,包括2016-eGeMAPS特征集,共88个特征;2016-ComParE特征集,共6373个特征;2009-InterSpeech Emotion Challenge特征集(IS09_emotion),共384个特征。这些特征集主要用于基于语音的情绪识别,也可用于语音识别。关于它们详细介绍的相关文献:
一个关于它们的简单整体介绍的博客:论文笔记:语音情感识别(五)语音特征集之eGeMAPS,ComParE,09IS,BoAW。关于openSMILE工具包及其配置文件的介绍,请参考官方说明文档openSMILE book。本程序里已经包含该工具包的编译版本及其所需的配置文件,位于./openSMILE文件夹下,因此无需再次下载编译。
第二种是利用Librosa音频处理库,提取了一些常用的声学特征,包括韵律学特征(浊音持续时间、轻音持续时间、有效语音持续时间、短时能量、过零率、基频、对数能量和声压级这些基于帧的LLD特征,以及基于这些LLDs对整段语音的全局统计值的HSF特征,包括最小值、最大值、极差、均值、标准差、偏度和峰度,同时对其一阶和二阶差分也作同样操作)、基于谱的相关特征(39维MFCC特征)和声音质量特征(第1/2/3共振峰中心频率及其带宽、频率微扰、振幅微扰)。
此外,程序也包括一些语音的预处理部分:预加重、分帧、加窗、FFT;基于双门限法的语音端点检测;声谱图提取。
最后,几乎对每一种特征都给出了图形绘制方法,毕竟可视化真香~
- 步骤及一些细节展示
首先通过Git将本程序克隆到您的计算机上。
git clone https://github.com/Zhangtingyuxuan/AcousticFeatureExtraction.git或者直接download压缩包,或者也可以通过**"Fork"** 按钮,Copy一份副本,然后通过您自己的SSH密钥克隆到本地。
运行本程序之前,请安装必要的Python3版依赖库。
cd到当前程序路径后直接运行本程序:
python3 acoustic_feature.py本程序./audios路径下有两个语音文件:“audio_raw.wav”(汉语:蓝天 白云)和“ae.wav”(英语单元音:[æ]),分别基于这两个语音文件运行程序,会得到以下文件和图形输出,待我一一介绍:
-
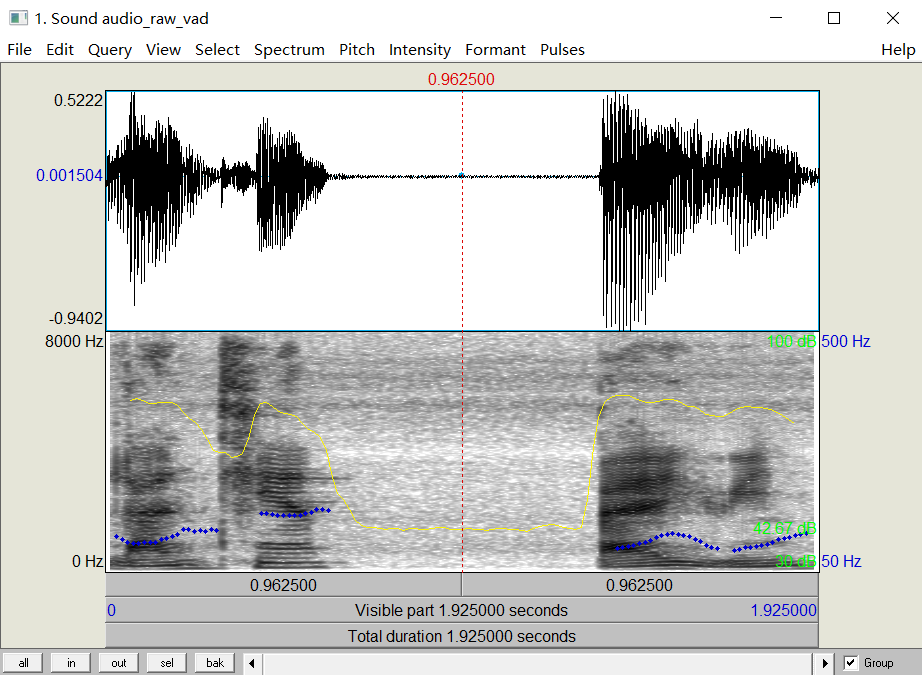
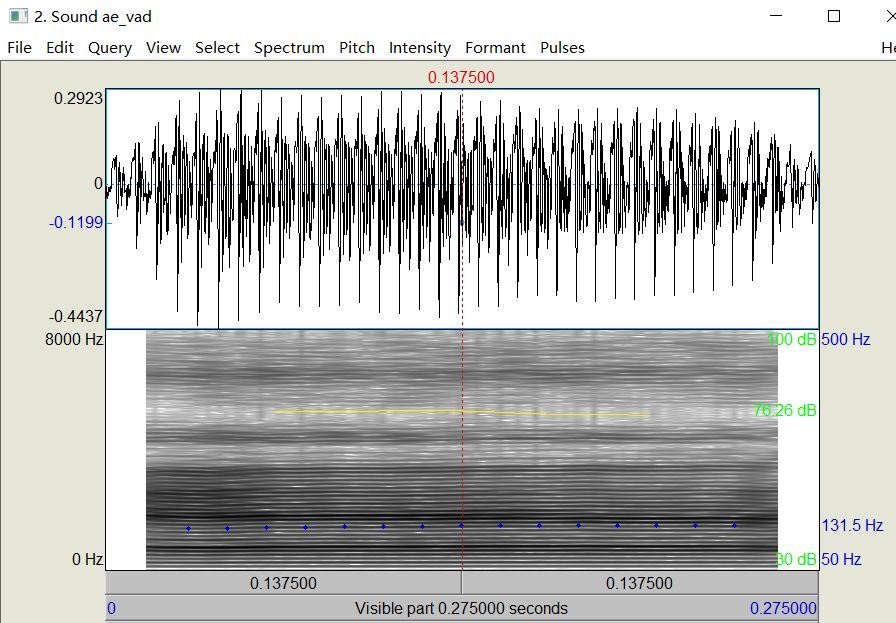
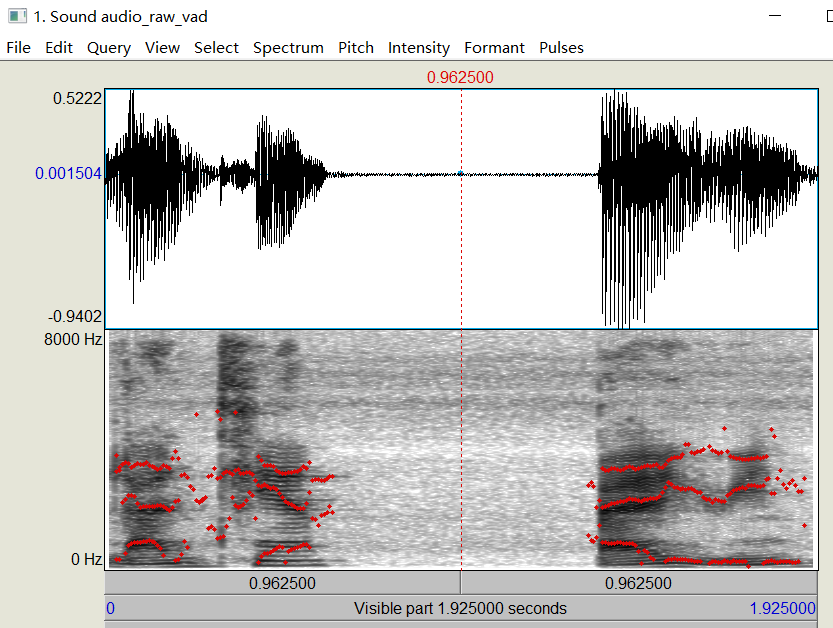
首先是语音的端点检测:输出的图形见下图1/2。这可以检测一段语音的所有有效语音部分,主要用于语音预处理,也可以通过它实现基于端点检测的语音分割,有关该方法的更细节程序在我的另一个仓库里:voice_activity_detection。
图1 汉语:“蓝天 白云”的语音端点检测
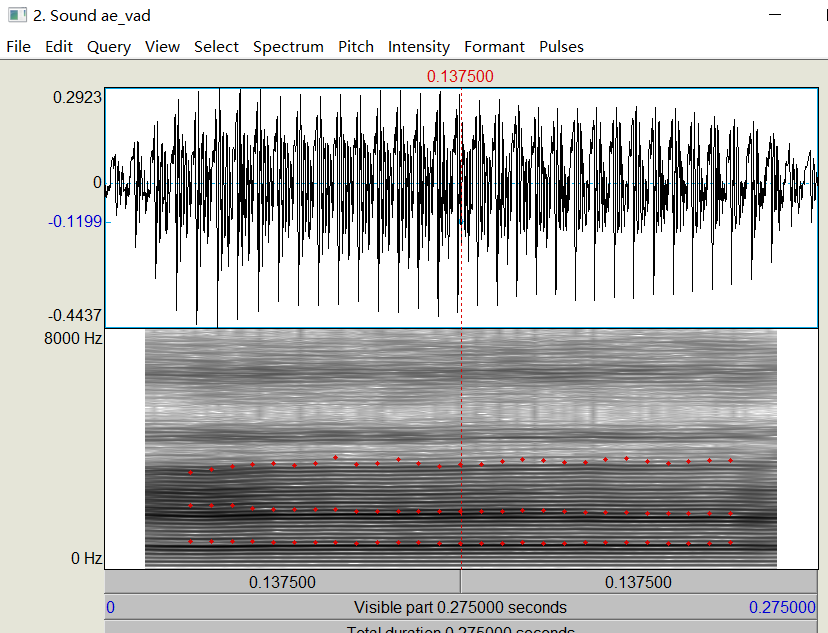
图2 英语单元音:[æ]的语音端点检测
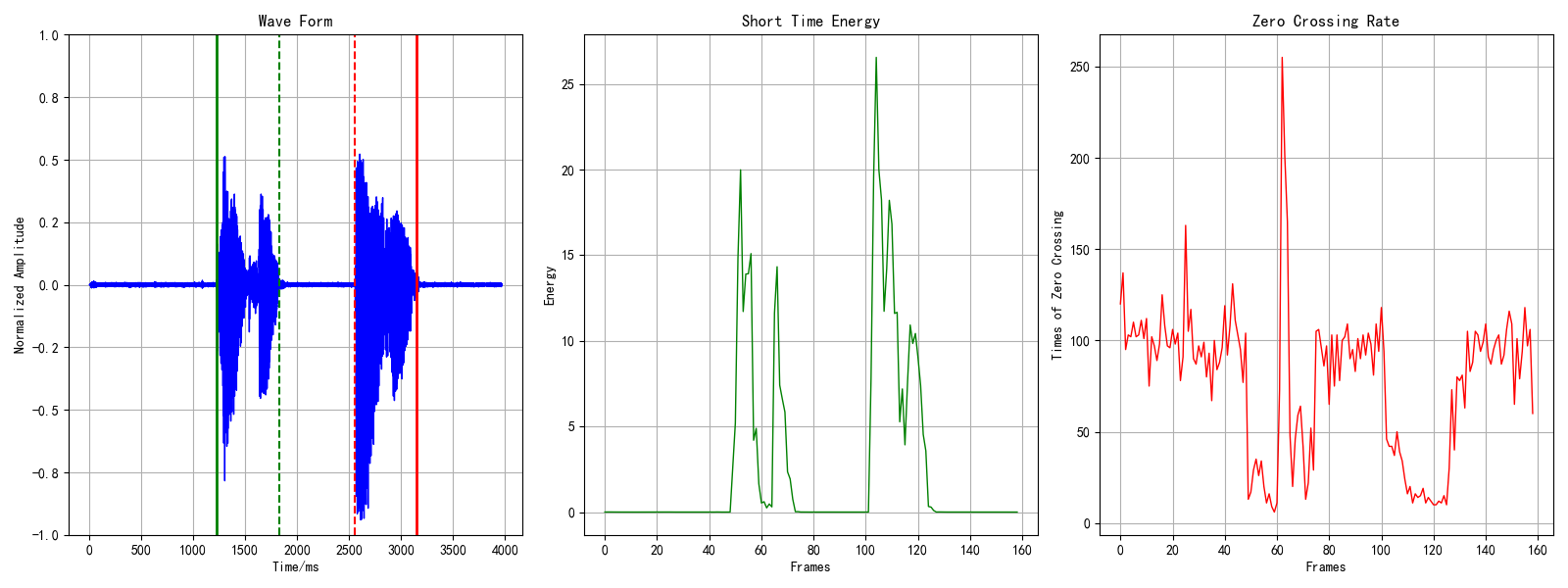
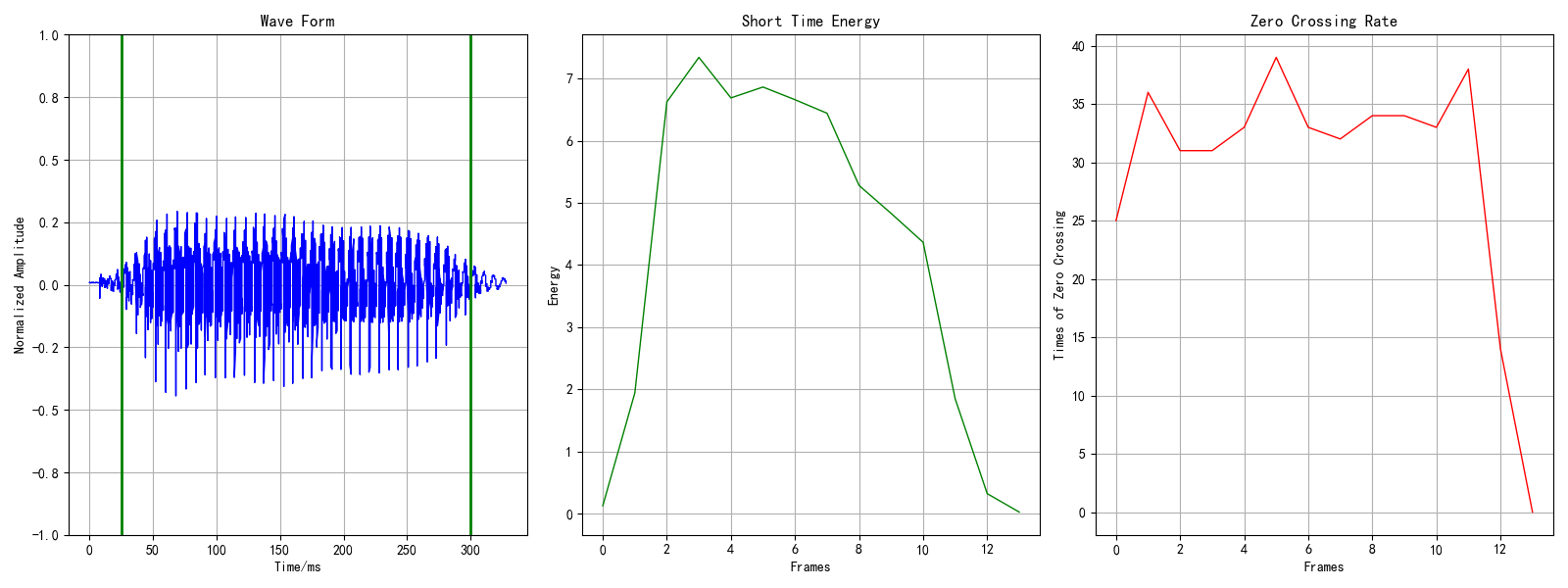
同时在./audios路径下会生成对应语音文件的首尾端点检测后的_vad.wav文件,接下来的特征提取均是通过该文件进行的。在./features文件夹下,会生成利用openSMILE工具包对应的特征集的ARFF格式的features.csv特征文件,文件部分内容见下图3所示:
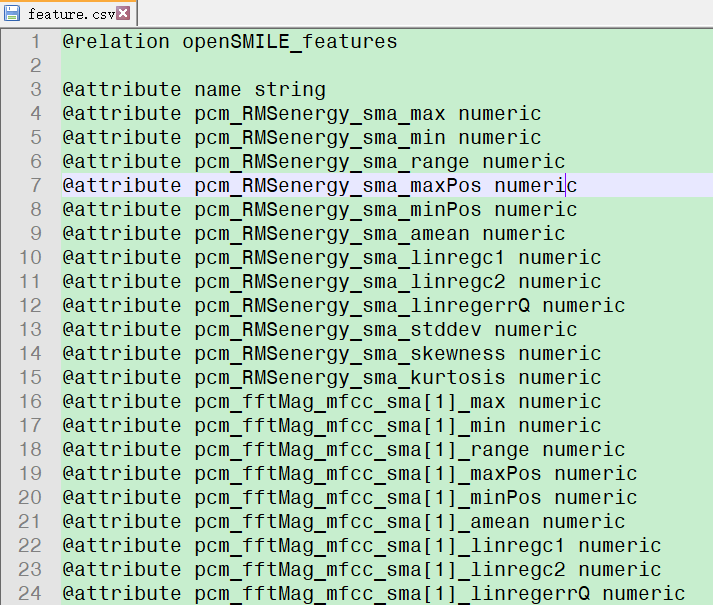
图3 利用openSMILE工具包中IS09_emotion特征集提取到的特征
-
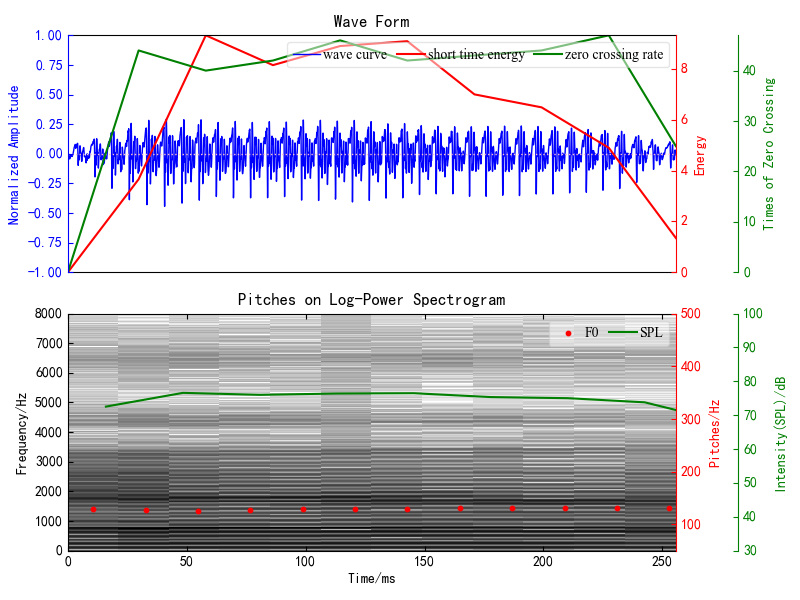
韵律学特征提取,比较了本程序和利用Praat软件在基频F0、声压级和谱特征的差异,由于是一句话语音,难免会出现较大的误差,而对于单元音的比较,误差小了些(图4/5):
图4 汉语:“蓝天 白云”的韵律学特征可视化(左)与利用Praat软件获取的特征可视化(右)比较
图5 英语单元音:[æ]的韵律学特征可视化(左)与利用Praat软件获取的特征可视化(右)比较
-
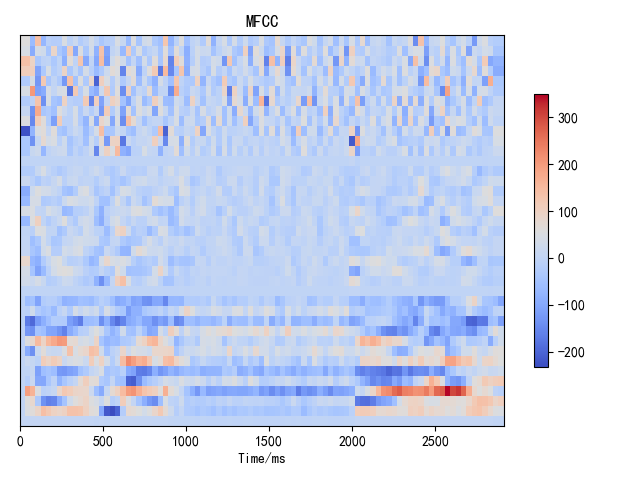
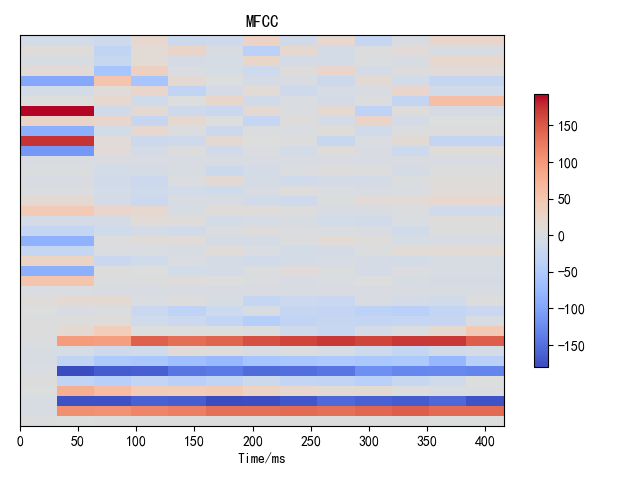
基于谱的相关特征:39维MFCC特征,包括MFCC1-13,其中MFCC1替换为对数能量,再依次计算一阶和二阶差分(图6)。
图6 汉语:“蓝天 白云”(左)和英语单元音[æ](右)的39维MFCC特征可视化
-
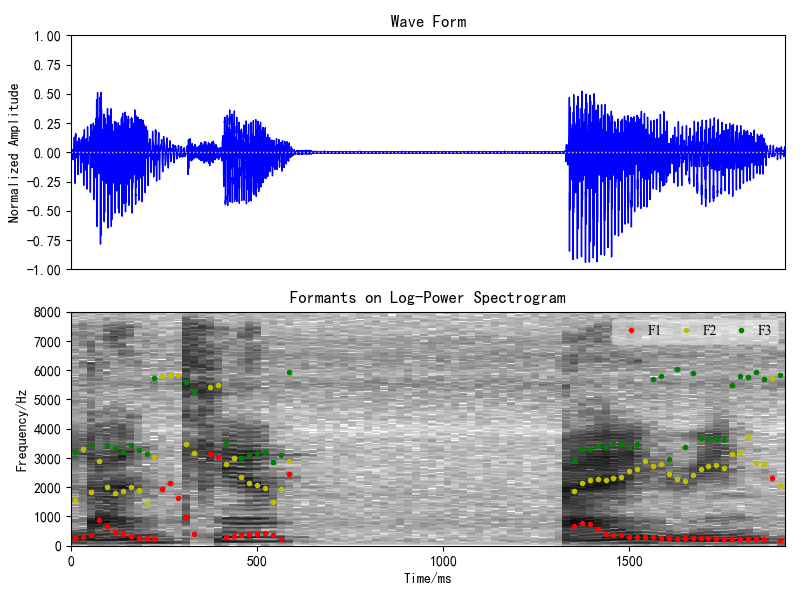
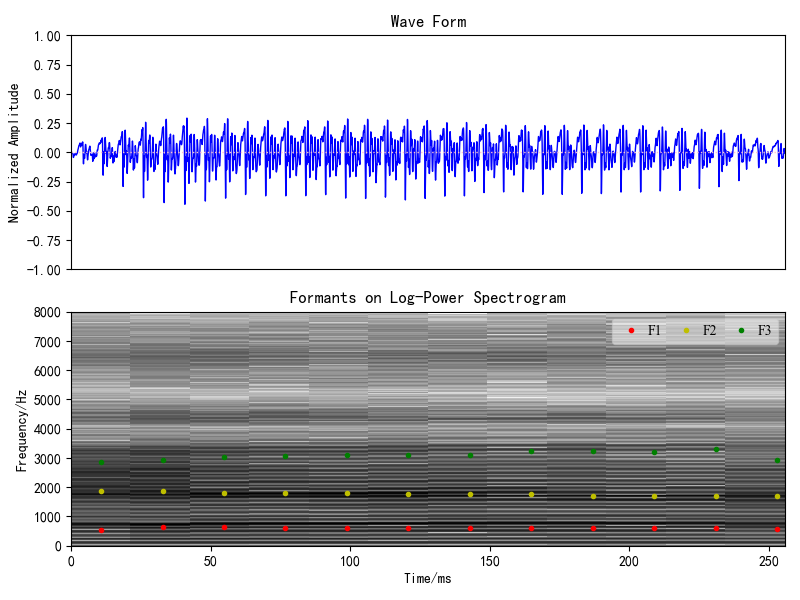
声音质量特征:比较了本程序和利用Praat软件在共振峰中心频率F1/F2/F3差异(图7/8):
图7 汉语:“蓝天 白云”的F1-3可视化(左)与利用Praat软件获取的特征可视化(右)比较
图8 英语单元音:[æ]的F1-3可视化(左)与利用Praat软件获取的特征可视化(右)比较
-
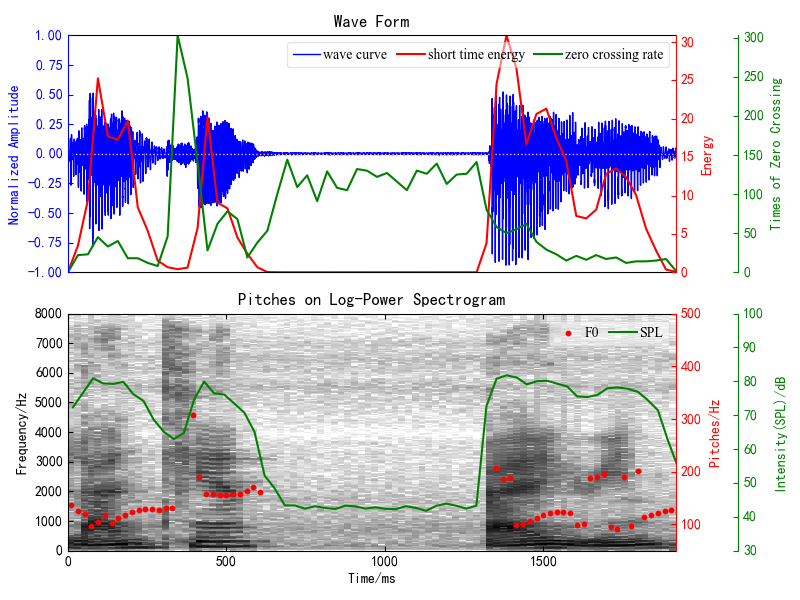
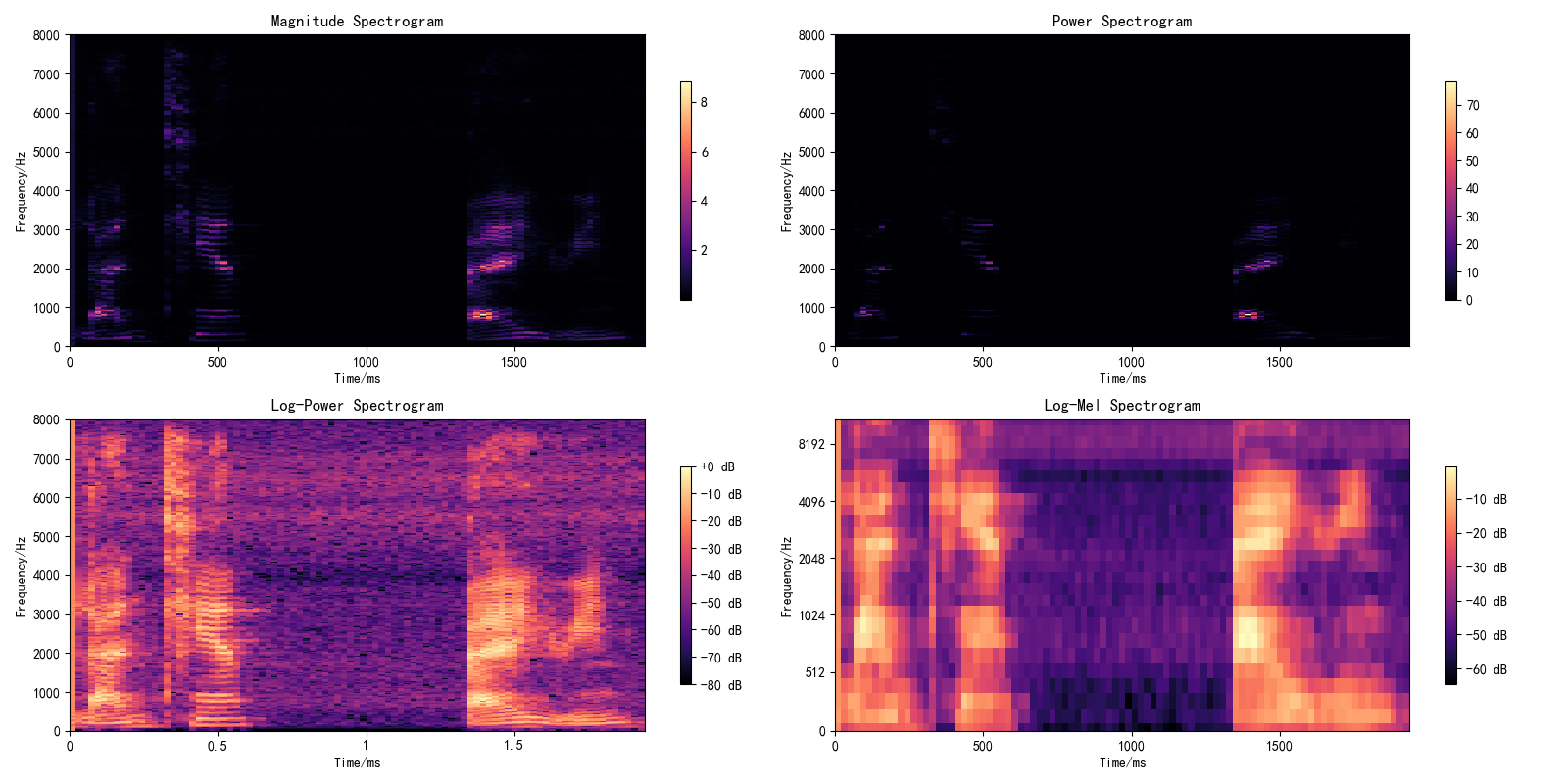
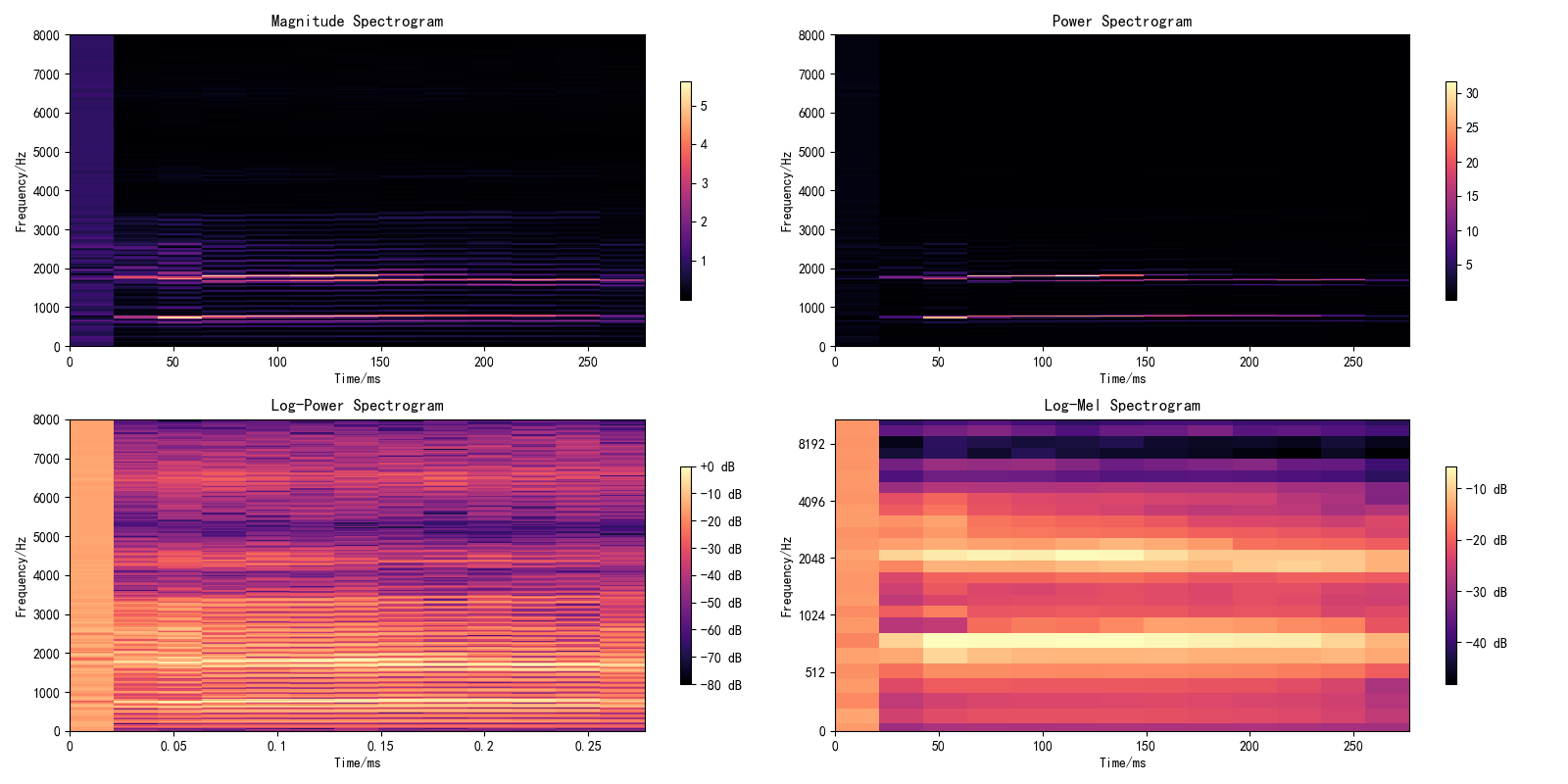
声谱图:包括幅值谱、功率谱、log功率谱和log-Mel谱,图9。
图9 汉语:“蓝天 白云”(左)和英语单元音[æ](右)的各种声谱图可视化
关于本程序的依赖库(其中Librosa最好和我使用的版本一致,其他版本都没测试过):
- Librosa-0.7.2
- Numpy-1.18.1
- matplotlib-3.1.3
- Scipy-1.4.1
- Soundfile-0.9.0
特别鸣谢:openSMILE和Librosa的开发维护人员、声学等相关学科的科研人员,以及各大博客论坛的大佬们的无私奉献与辛勤劳作!感谢前辈们让我学到了很多相关知识!
如果你喜欢本程序,并且它对你有些许帮助,欢迎给我打赏一杯奶茶哈~
微信:

支付宝:
