
-
- Опис
-
- Список використаних бібліотек
-
- Навіщо воно потрібно.
-
- Що воно робить.
-
- Як воно робить.
-
- Як покращити.
-
- Як все це запустити.
-
Це Веб застосування, яке демонструє можливість пошуку на клієнті та на сервері з кешуванням данних.
-
Використовувалися такі біблиотеки
react -... redux - state management redux-saga - side-effects model redux-search - client-search lib reselect - lib for data memoization immutalbe - lib for immutable data structures react-router - client rouning auth0 - authentication json-server - mock-server faker - fake data -
Offline-first. Кешування запитів на клієнті робить программу більш офлайн спрямованою.
-
Це веб застосування, яке просто кешує пошукові запити і надає можливість пошуку в кешованих запитах
-
Програма викроистовує нормалізований вид данних
{
[id]:{
id:id,
title: '',
author: '',
description: '',
}
}А також іммутабільні структури данних для оптимізації і швидкої перевірки на рівнисть. Для пошуку на клієнті використовується redux-search. Він індексує колекцію и може робити пошук по заданим полям.. Його можна розширити, додавши власний метод для індексування.
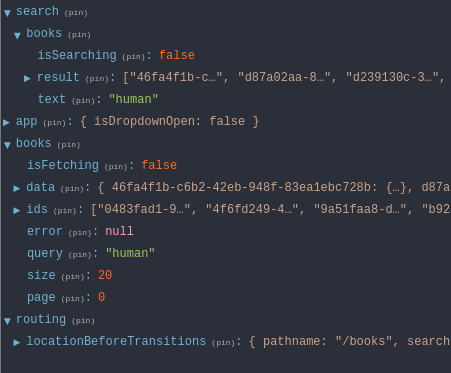
Data flow виглядає наступним чином:
-
на сервер йде пошуковий запит.
-
клієнт отримує його, нормалізує і зберігає під ключем
data. -
результат запиту на сервер зберігається в ключі
ids. Посилання на елементи зdata. -
потім наступні запити, які йдуть на пошук по кешованним даннми перезаписують данні в в ключі
data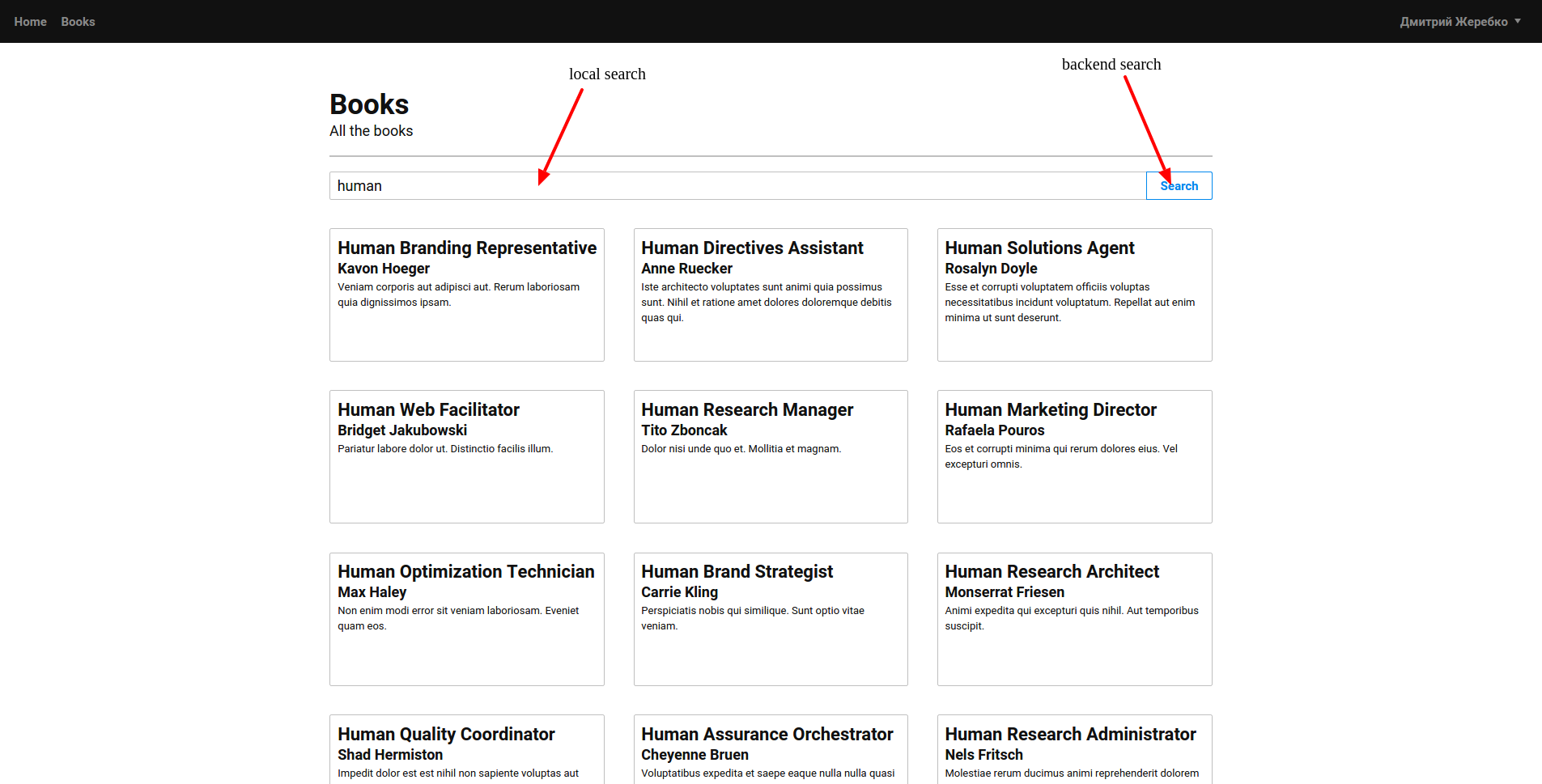
-
Що можна покращити ?
- Кешувати данні не в пам'яті, а в кліентському сторейджі. тут допоможе redux-persist або redux-offline
- Придумати кращий спосіб для серверних запитів.
- Як 3апустити ?
export AUTH0_DOMAIN='auth domain'
export AUTH0_CLIENT_ID='auth id'
// fake.js file for generaing fake data node fake.js
npm run server
npm run dev