PyTorch Implementations of various state of the art architectures.
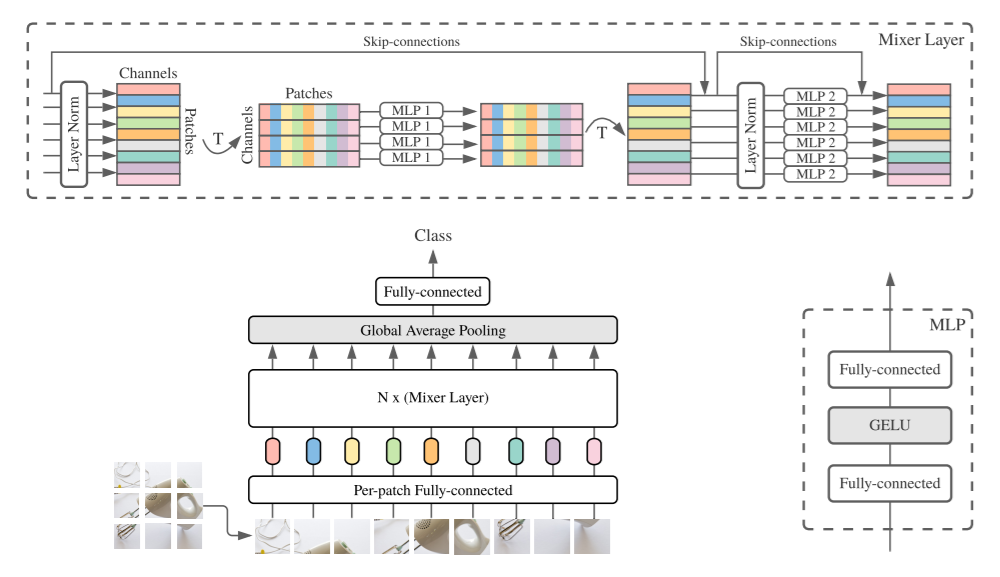
import torch
from MLP_Mixer import MLPMixer
model = MLPMixer(
classes= 10,
blocks= 6,
img_dim= 128,
patch_dim= 128,
in_channels= 3,
dim= 512,
token_dim= 256,
channel_dim= 2048
)
x = torch.randn(1, 3, 128, 128)
model(x) # (1, 10)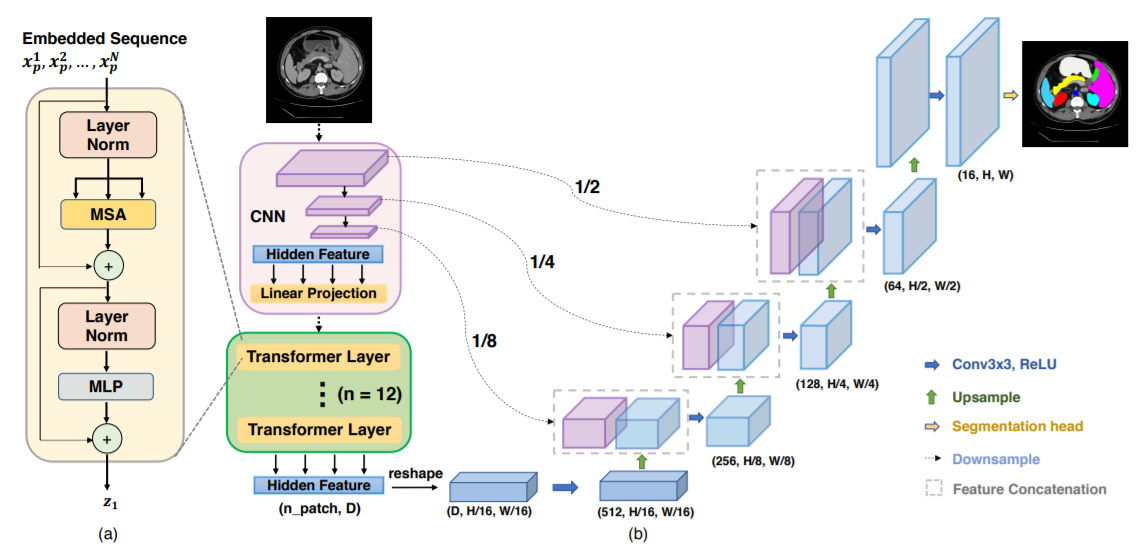
import torch
from TransUNet import TransUNet
model = TransUNet(
img_dim= 128,
patch_dim= 16,
in_channels= 3,
classes= 2,
blocks= 6,
heads= 8,
linear_dim= 1024
)
x = torch.randn(1, 3, 128, 128)
model(x) # (2, 128, 128)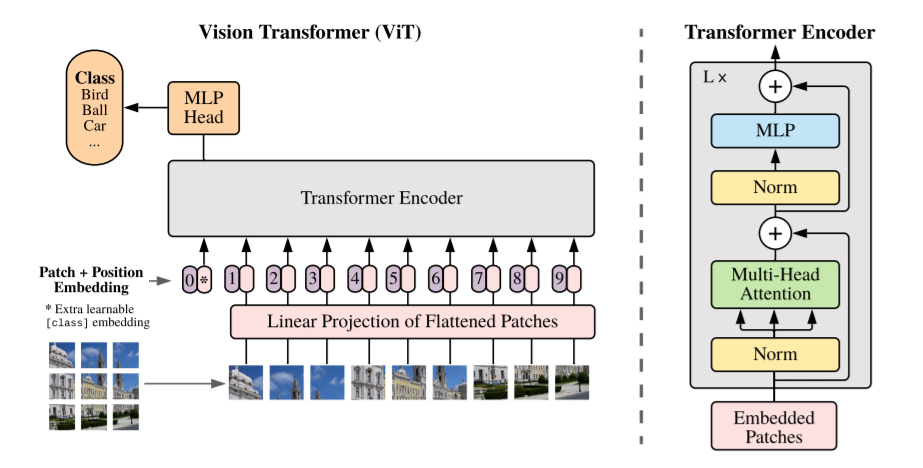
import torch
from ViT import ViT
model = ViT(
img_dim= 128,
in_channels= 3,
patch_dim= 16,
classes= 10,
dim= 512,
blocks= 6,
heads= 4,
linear_dim= 1024,
classification= True
)
x = torch.randn(1, 3, 128, 128)
model(x) # (1, 10)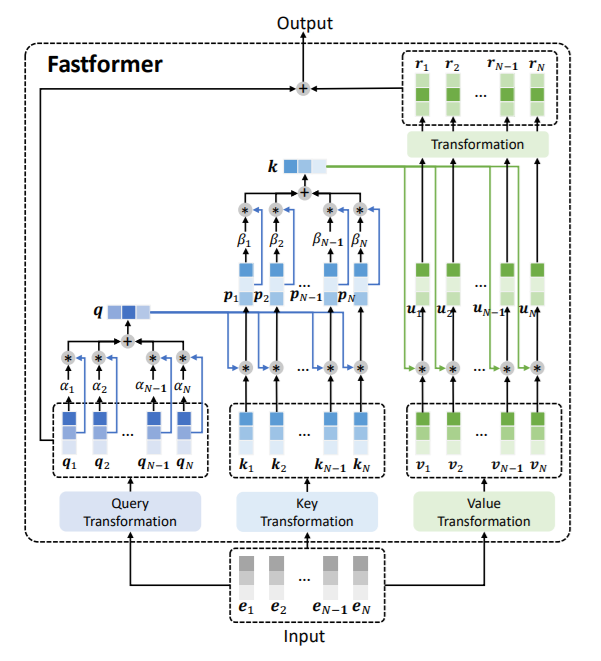
import torch
from fastformer import FastFormer
model = FastFormer(
in_dims= 256,
token_dim= 512,
num_heads= 8
)
x = torch.randn(1, 128, 256)
model(x) # (1, 128, 512)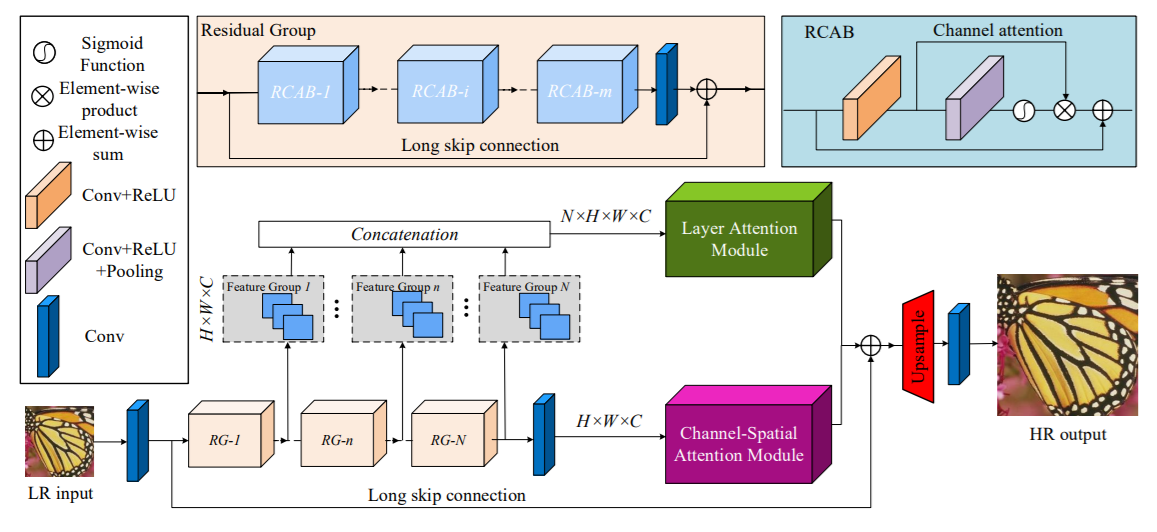
import torch
from han import HAN
model = HAN(in_channels= 3)
x = torch.randn(1, 3, 256, 256)
model(x) # (1, 3, 512, 512)



