当您打开这个仓库时,请自觉遵守学术诚信协议:https://integrity.mit.edu/
北京邮电大学《数据科学导论》2020级大作业
Report
问题分析
根据贷款app提供的数据,预测用户是否存在贷款违约的可能。所给数据集的指标包括:收入、年龄、专业、房车、位置等。
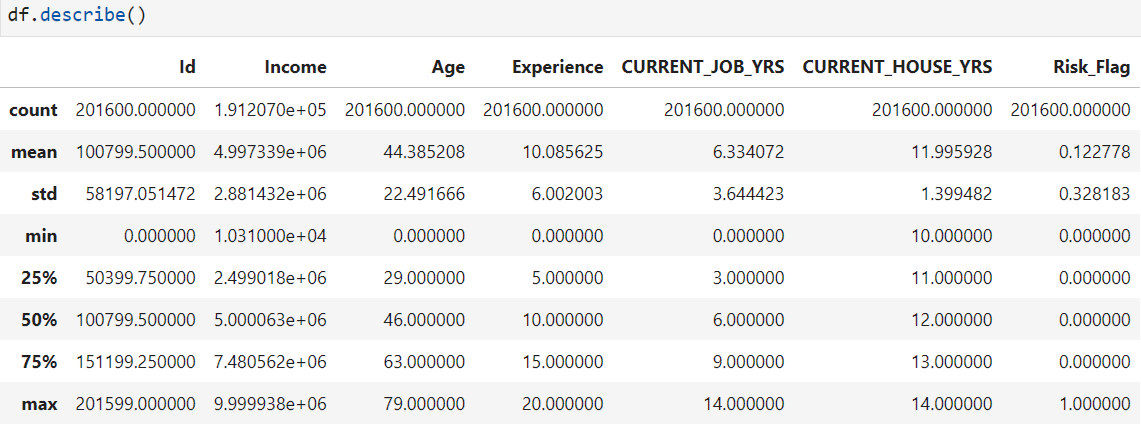
数据示意图:

数据处理流程
通过Null的判断知道,Income居然有空的情况,可能是不好意思写上去吧,这个时候有两种选择:
- 用统计特征值代替
- 直接丢弃对应的列:info:Income的异常值占了约1/20的总量,还是有必要进行处理的,不能浪费
同样地,图示明显,还有异常值Age为0。Age异常值量20000+,不能浪费,观察异常值的具体分布,结果与上图相似度较高(图略)
因此我们采用了回归分析的方式填充异常值。
为什么不选取平均值的方式?
因为我们认为接下来的操作设计到分类聚合,将缺失值统一到同一值可能会导致分箱偏差。
并且,对于存在字符串的列,我们使用了【独热编码】的方式进行离散化,方便我们进行后续的处理。
模型
我们小组尝试过多种模型进行拟合。比如:
- 考虑到二分性,使用了
logistic回归,结果AUC仅在0.63附近,效果不理想。可能是因为独热编码后,维度过高; - 考虑到需要概率,我们尝试了多元线性回归模型,AUC依旧没有改善。我们意识到,难以通过函数的方式获得良好的效果了。
- 我们也考虑了SVM方式,但是运行时间过久,难以继续探索。
- 于是我们转而走向集成学习的道路。首先我们了解到了XgBoost,这一模型运作良好,让我们的AUC值突破了0.9
- 我们不满足于此,了解到XgBoost的优化版本LightGBM,我们欣喜地获得了预期的效果
成员分工与心得
数据科学家定义为具有计算机科学技术,数学和统计学知识基础和实质性专业理论知识的人。
对于每一个可视化的图表、分析的指标,挖掘蕴含的信息需要独到的眼光,才能看到别人忽略的细节。
实验中结合实际,提供贷款的预测,我们代入自己的情况数据进行模型预测,对未来也有了清晰的认识。
参考资料: http://www.shichuan.org/Introduction-to-Data-Science.html