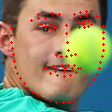
1.Download and unzip the WFLW data set to get two folders, WFLW_annotations and WFLW_images, place these two folders under the data/WFLW folder, and place the Mirror98.txt folder under WFLW_annotations
2.Run the data/data_sep.py file, and test_data and train_data folders will be generated in the data directory. Each folder will have an imgs folder and a list.txt file. The imgs folder stores the processed pictures ( Cut the person's avatar from the original image), each line in the list.txt file represents the information of a picture in imgs, and the information from one line from left to right is as follows: image path + key point coordinate ( 98 * 2) + image type (expression, big gesture, etc. 6) + Euler angle (3)
3.Set the train section in the configuration file config.json,“lr_shrink_epoch” indicates how many epochs perform a decay of the learning rate,
“lr_shrink_rate” indicates the strength of each decay of the learning rate,“save_model_epoch ”means to store the epoch_model every "save_model_epoch" epoch。(It should be noted here that two models are stored under model_save_path, one is epoch_model.pth, the other is best_model.pth, epoch_model.pth is the model stored for every "save_model_epoch" epoch, and best_model.pth is the best performing model on test dataset during the training process)
4.Run train.py
1.Set the predict part in the configuration file config.json,"use_best_model" indicates whether to use best_model, set to 1 to use, 0 to use epoch_model.
“use_camera” indicates whether to use the camera, set to 1 to use, 0 to not use.When using a camera, “is_video” indicates whether to load a video, 1 means load video to predict video, 0 means not use video but use camera directly.
If a video is loaded, "video_path" indicates the video path.“test_img_dir” indicates that the storage path of the predicted images needs to be specified without using a camera.“predict_result_save_dir” indicates the storage path of the prediction result without using the camera.
2.Run predict.py