by Xudong Wang*, Long Lian* and Stella X. Yu at UC Berkeley / ICSI. (*: equal contribution)
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
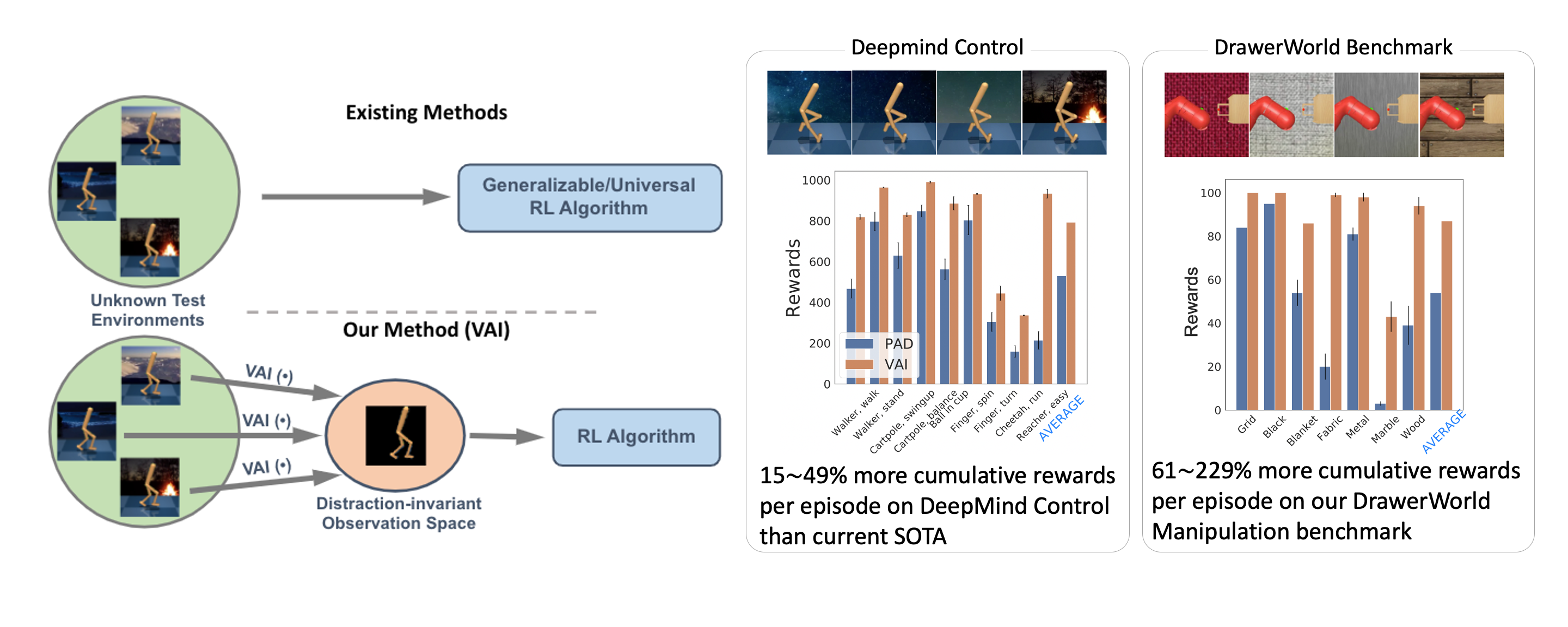
For more information, please check: Project Page | PDF | Preprint | BibTex
The key message of this paper: Adapt not RL, but the vision!
This repo has the official PyTorch VAI implementation.
Before you start, you need to make sure that you have a valid mujoco key and your environment satisfies the requirements of OpenAI gym. Requirements for RL can be installed in a similar way as PAD. If you use conda, you could install with this file:
conda env create -f install.yaml
conda activate vai
If you prefer configuring on your own, make sure to install packages in install.yaml.
Then, install the following python packages:
# If you need DeepMind Control suite:
cd src/env/dm_control
pip install -e .
cd ../dmc2gym
pip install -e .
# If you also need DrawerWorld.
cd ../drawerworld
pip install -e .
The code requires a copy of Places dataset on places365_standard directory (download the dataset on their website).
Note: this project requires a torch >= 1.7.0 and CUDA >= 10.2, and official NVIDIA driver is needed instead of the open-source NVIDIA driver. If you encounter mujoco/gym issues, please contact mujoco or OpenAI gym. If you encounter DM Control or DrawerWorld issues, you can have a look at DM Control repo and MetaWorld repo first and see whether people have similar questions. DM Control and MetaWorld actually use different mujoco python package, so running one does not imply the other is configured right. We suggest Ubuntu 18.04 since packages may not be pre-compiled on other OS (e.g. CentOS). This can save you a lot of time!
After installation, you can start collecting samples from the environment and start training adapters.
CUDA_VISIBLE_DEVICES=0 EGL_DEVICE_ID=0 python3 src/train.py --domain_name cartpole --task_name balance --action_repeat 8 --mode train --num_shared_layers 4 --seed 0 --work_dir logs/your_work_dir --update_rewards --save_model --num_layers 4 --use_inv --export_replay_buffer --init_steps 5000
This command runs the training script and --export_replay_buffer asks it to export the replay buffer and quit before training starts. Since it quits before training starts, all data is collected with a random policy.
Feel free to adjust init_steps if you find the collected data not enough. We use 5000 across all environments.
Train keypoints by running:
CUDA_VISIBLE_DEVICES=0 python src/train_stage1.py
Feel free to adjust the hyperparams in the file. On environments other than cartpole, k needs to be tuned to select as much foreground and little background as possible. However, not much tuning needs to performed when compared to Step 2, since training environments don't have complex textures and keypoints model is not used in test environment.
Please modify the path for keypoints in train_stage2.py to load the keypoints that you just trained. See comments for tuning hyperparams for different environments. This is much harder to tune because it needs to adapt in test environments. I strongly encourage you to export the adapted observation in test environment with train.py (you can use mode to switch to test environment in train.py) to check the adapter before RL training since RL training takes so long and you probably want to verify the adapter before the real training. Train adapter by running:
CUDA_VISIBLE_DEVICES=0 python train_stage2.py
Use the following command to train RL:
CUDA_VISIBLE_DEVICES=0 EGL_DEVICE_ID=0 python3 src/train.py --domain_name cartpole --task_name balance --action_repeat 8 --mode train --num_shared_layers 4 --seed 0 --work_dir logs/your_work_dir --update_rewards --save_model --num_layers 4 --use_inv --adapt_observation --adapter_checkpoint adapter_checkpoint --adapt_aug
Note:
For finger tasks, we set num_shared_layers=8, num_layers=11. For other tasks we set num_shared_layers=4, num_layers=4.
For finger tasks, we set action_repeat=2. For cartpole tasks, we set action_repeat=8. For other tasks, action_repeat=4.
For DrawerWorld close and open, we set action_repeat=2. For DeepMind Control tasks, we follow the settings in PAD.
Please set work_dir to the working directory to save checkpoints, and set adapter_checkpoint to the path of checkpoint. Adapter is required in training time.
The eval.py is for running inference.
To run inference on many seeds, you probably want to use a shell script:
#!/bin/bash
for i in {0..9}
do
echo "Running:" $i
python3 src/eval.py \
--domain_name cartpole \
--task_name balance \
--action_repeat 8 \
--mode color_hard \
# To enable video mode for individual video:
# --mode video$i \
--num_shared_layers 4 \
--num_layers 4 \
--seed $i \
--work_dir logs/cartpole_balance_mask \
--pad_checkpoint 500k \
--adapt_observation \
--adapter_checkpoint runs/May31_02-05-06_dm_control.pth \
--pad_num_episodes 10
done
This file supports PAD too.
See FAQ. Please read the FAQ if you encounter any problems. We also offer some tips, since it can be very difficult to debug.
@InProceedings{Wang_2021_CVPR,
author = {Wang, Xudong and Lian, Long and Yu, Stella X.},
title = {Unsupervised Visual Attention and Invariance for Reinforcement Learning},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {6677-6687}
}
We thank authors for the following projects that we reference:
- PAD which our work is based on.
- A repo with our baseline SAC implementation
- DeepMind Control which we benchmark on.
- Metaworld which Drawerworld is based on.
- Transporter Implementation
- PyTorch Morphology for functions that perform visual modifications.
- SODA for the code which loads Places.