非母語で書かれた電子書籍やPDFを母語で書かれたPDFに翻訳するツールです。
一冊50万字あるKindleの洋書を1分で日本語PDFに変換できます。
キーボードの矢印キーでページ送りができるならKindleに限らずあらゆる電子書籍リーダおよびPDFビューワで使え、DeepLが対応している言語であれば英語以外の言語でも翻訳できます(仏→日とか)。
↓
(引用 **The Ethics of Cybersecurity (The International Library of Ethics, Law and Technology Book 21) by by Markus Christen, Bert Gordijn, et al. Feb 10, 2020) (CC: BYです)
pyautogui
img2pdf
Pillow
opencv-python
pyocr
fpdf2
python-dotenv
requests
本ツールはpythonで書かれています。必要なライブラリをrequirements.txtおよびvenv.yamlに出力してあるので、pipを使う場合はrequirements.txtを、condaを使う場合はvenv.yamlをそれぞれ使用して仮想環境を整えてください。
pip install -r requirements.txtconda <env name> create -f venv.yml以下からAPI版DeepLに登録してください。(無料版であってもクレジットカードの登録が必要です)
https://www.deepl.com/ja/pro#developer
無料版で構いませんが、その場合はtranslator.pyの48行目のURLをapi.deepl.comからapi-free.deepl.comに変更しておく必要があります。
登録が済んだら、local.envのDEEPL_API_KEYを入力してください。
以下から自分の環境に合ったインストーラをダウンロードしてください。
https://github.com/UB-Mannheim/tesseract/wiki
インストールが終わったら、local.envのTESSERACT_PATHを自分の環境に適したパスへと変更してください。
画像保存用フォルダとテキストファイル(とできたPDFファイル)を保存するフォルダを準備し、local.envのOUTPUT_IMG_FOLDERとOUTPUT_TXT_FOLDERを適宜変更してください。
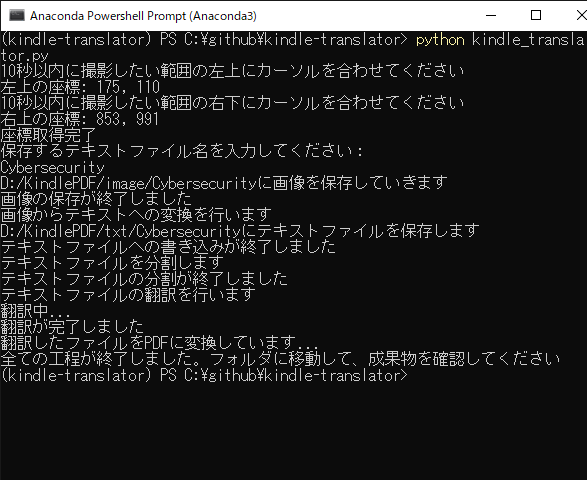
このリポジトリをcloneし、
python kindle_translator.py
を実行するだけでOKです。画像の通り、ほとんどの作業がコンソール上で進みます。
その後は電子書籍リーダをクリックしてアクティブにした上で左上にカーソルをあてて10秒待ち、また右下にカーソルをあてて10秒待ちます。
すると座標が取得でき、保存するファイル名・フォルダ名を聞かれるので入力しましょう。拡張子はいりません。
あとは自動でフォルダが作られ、翻訳され、できたPDFがフォルダに格納されます。
- デフォルトでは、ページ送り方向が【右】になっています。必要に応じて変更してください。(capture.py 104-105行目、118-119行目)
- 現在のバージョンでは、スクリーンショットの撮影を行うため大量のpngファイルが生成されます。容量に余裕をもって実行してください。
- 現在のバージョンでは、生成されたpngファイルやtxtファイルは自動で削除されません。必要に応じて手動で消去してください。
- 相良スヒト
- Twitter: @1plus1is__