opencv+mtcnn+facenet+python+tensorflow 实现实时人脸识别
Abstract:本文记录了在学习深度学习过程中,使用opencv+mtcnn+facenet+python+tensorflow,开发环境为ubuntu18.04,实现局域网连接手机摄像头,对目标人员进行实时人脸识别,效果并非特别好,会继续改进
这里是
如果各位老爷看完觉得对你有帮助的话,请给个小星星,3q
- 20170512-110547文件夹是facent的模型,官方存放在google网盘上了(而且现在出来2018的预训练模型了),不方便下载的我一会儿会把用到的大文件打包放在坚果云上
- align文件中包含三个mtcnn要用到的模型,以及搭建mtcnn网络的文件
detect_face.py,这里面的东西在facenet的项目中的都可以找到 - models中存放的是训练好的knn模型,用于测试使用的简单模型,一会儿展示的效果也是由其完成
train_dir顾名思义,就不解释了facenet.py就是一直在谈的东西,其中包含了如何搭建facenet网络,以及计算的内容test.pytrain_knn.pytemp_test.pyimageconvert.py这几个文件分别人脸识别测试、训练knn模型、遇到问题是精简代码调试使用、图像批量转化 用于准备数据集其他的没有谈及的文件都没有使用到,应该是以前测试时候忘记删除的
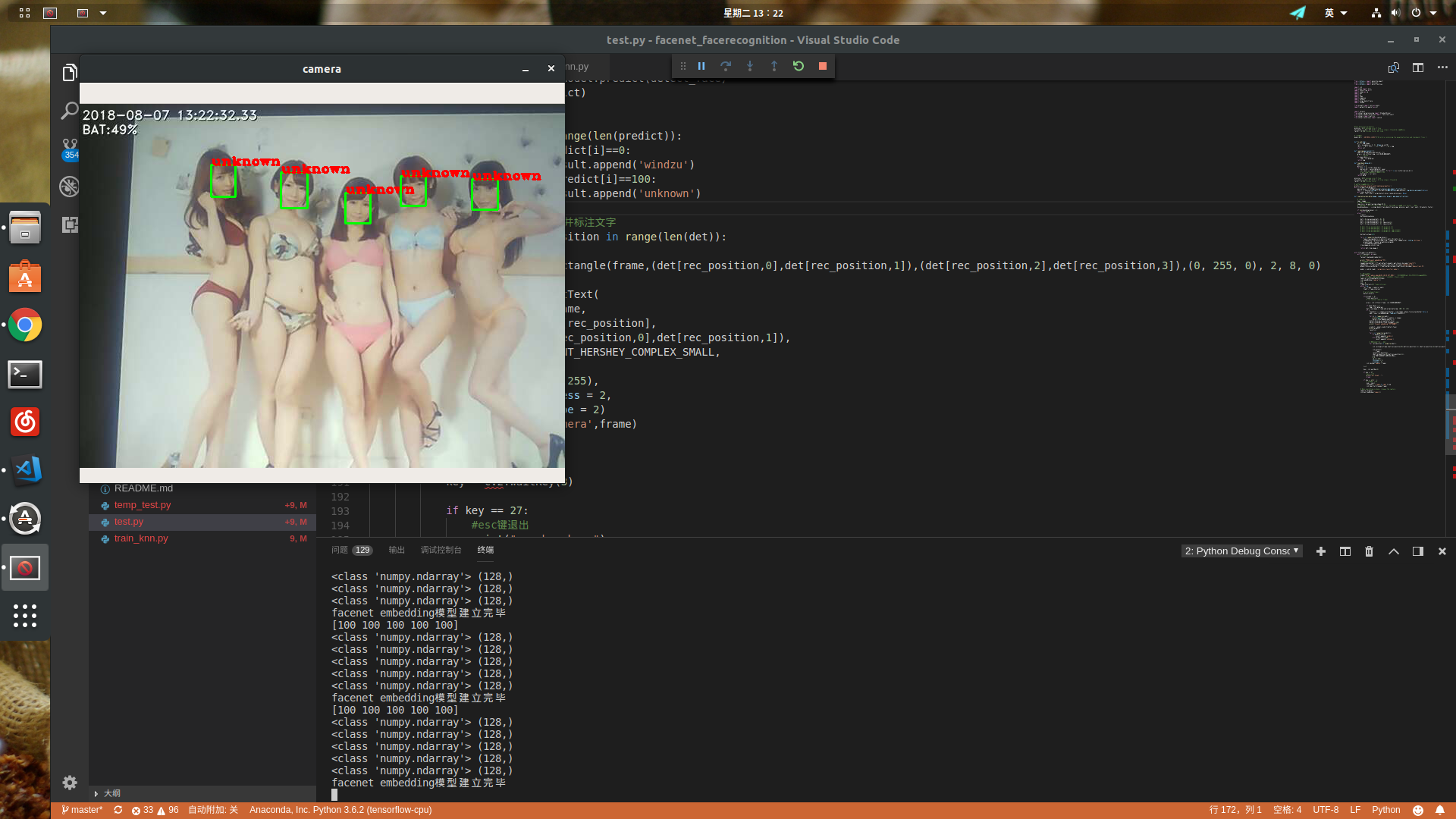
这是使用手机摄像头拍摄ipad从网上随便搜来的合照进行测试(也许也不是随便搜的...),能够准确将人脸框出,并进行识别,因为我使用的是knn训练的,而这几个人是未经过特殊训练的,所以将其归结为未知人群,再接下来一段时间会对其进行改进,最终效果应该是可以实现单张图片数据库比对,这样就不用对需要识别的目标每一个都训练一遍了,这也是人脸识别要达到的效果,上面所说的triplet loss就是一种很好的方法
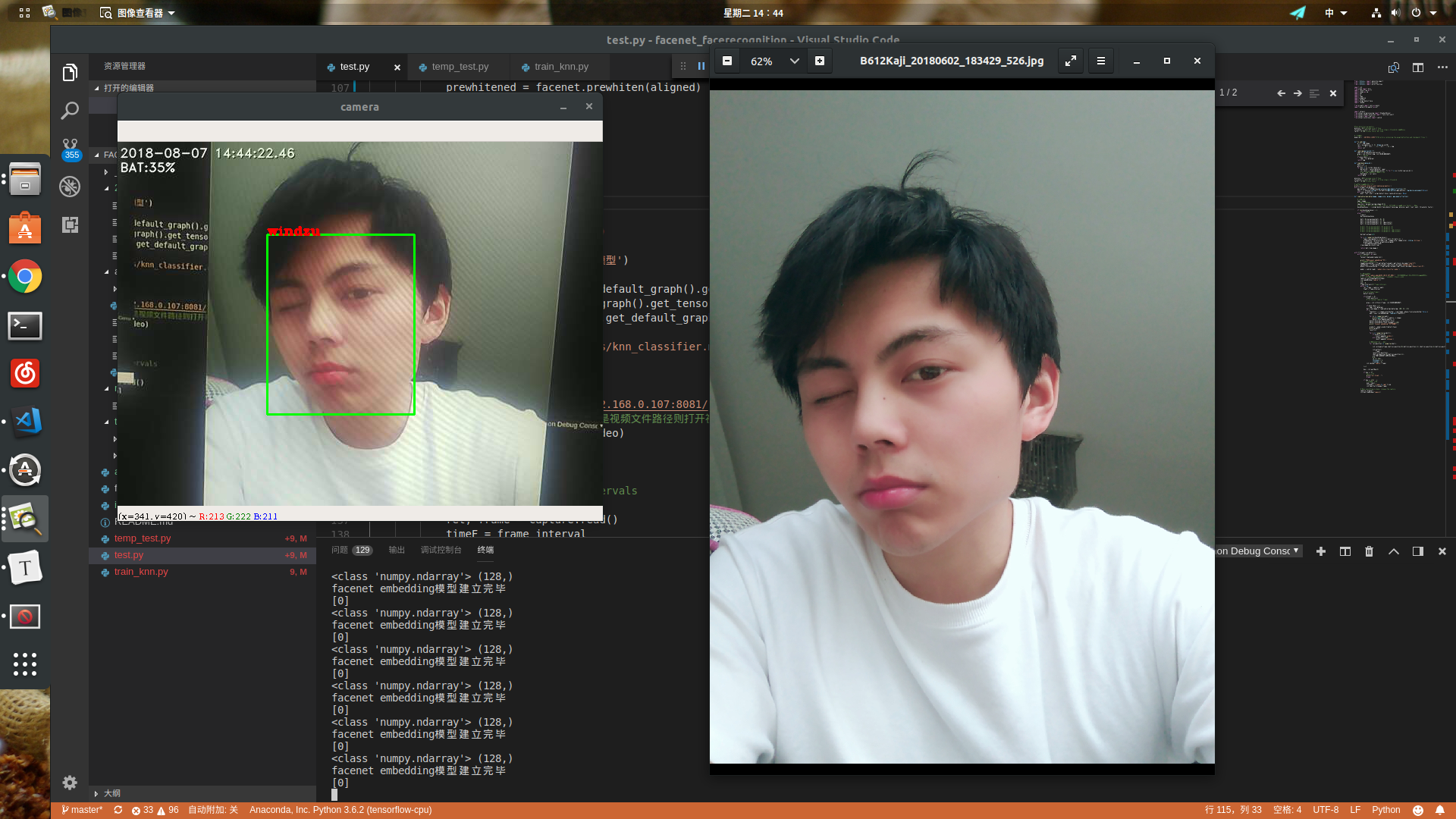
因为房间光线比较暗,用手机摄像头拍摄以前的自拍,识别成功
-
推荐使用Anaconda配置tensorflow环境(因为本项目就是基于tensorflow框架的),是cpu版本(等新卡,其实就是穷...)网上教程很多,也很简单,本环境的python版本是3.6的,如果你的是2.7的话,那就要改很多东西了(跟着报错改就ok),但何不如再安装个3.6的呢,在anaconda下真的是超级方便
-
编辑器用的是vscode,从windows转来,习惯使用vscode,真的很好用,在安装anaconda的时候会提示你是否装个vscode的,当然使用其他的也很好
-
一些依赖库当然是必备的,提示少啥装啥吧,我也忘了,反正那些基本的是要装的,比如numpy maplotlib jupyter scikit-image librosa kersa 这些,安装也很简单,在anaconda里安装 使用conda命令 或者如果你的linux的默认python就是anaconda里的,直接使用pip安装就好了
-
本项目里的几个运行的代码,我都写好了参数,直接运行即可(当然制定文件要在指定位置) 运行顺序是
-
准备好自己的训练集 几十张自己照片即可(尺寸要小一点的,最好500*500以下,不然速度慢,精度低),放到train_dir/pic_me 文件夹下面,把我打包文件里的pic_others文件夹中的放到指定train_dir/pic_others下面(这部分数据也可以自己准备,我的数据是来自lfw中的前几百张图片)
-
运行
train_knn.py得到自己的knn模型 -
运行
test.py(记得要把手机上的ip摄像头app打开,点击下面打开IP摄像头服务器,并检查下显示的局域网ip和test.py中的是否相同,如不相同,改一下) -
启动的时候会比较慢,30s到一分钟左右,取决于电脑性能
-
至此你应该已经成功跑起来这个项目了,在此感谢开源的伟大,让我们能感受到这些神奇的算法
好学的各位爷肯定是要将代码好好看一通的,因为我也是菜鸡,看到拙劣之处,请会心一笑...
代码思路
- 使用mtcnn截取视频帧中人像的人脸,并拉伸为固定大小(这里为160*160,由使用的facenet网络所受限)
- 将上一步骤得到的人脸输入facenet,得到embedding层的输出,一个人像对应一个1*128数据,然后将其输入knn网络,得到预测结果
学习思路
- 一定一定要搞清楚其中的数据流是以什么样的格式和形式在传递,其中大多数使用的都是numpy.ndarray数据类型,此外便要掌握一些基本的此类数据类型的格式转换函数,并熟记,很常用的,还有就是和list 的转换
- 掌握一点点opcv的读写函数
- 掌握一些对文件操作的函数
新增测试方法“直接使用emb特征进行计算对比”
上一个版本是使用knn对准备好的若干张照片进行“训练”,首先准确率不是很高(还没细究问题,猜测原因是自己准备的图片问题,以及实时采集实时的环境影响),但最主要的原因还是对每个目标对象都必须准备若干张照片进行训练,再看当前市面上的人脸识别都是直接采集一张图片放入数据库,并不需要再训练,直接便可以识别,而facenet的最初**便是如此,是一开始的自己走远了。
所以本次的更新便是,直接将想要测试的对象的一张照片以其英文名命名(中文会乱码),放入一个名为test_img文件夹中,接下来对其进行人脸检测并切割,切割后的人脸图片尺寸为160*160,存入emb_img文件夹中,这一步的主要目的是为了不要每次测试的时候都还要重新开始人脸检测,当人脸识别程序启动时,先读取emb_img文件夹图片并输入网络得到其emb(128维特征),用于后续与摄像头捕捉的照片进行比较
总体来说,基本上没什么**,可以说是很简单,甚至可以说是一个简单版的knn,因为我的想法是以后能够将每张照片的emb存入数据库,并使用kd树优化(本次更新没有做),可是这样的话不就和knn一样了么,哎,做完自己才发现自己在做一件傻事,可是还是觉得knn不太好....先不管了,就酱
新增两个文件夹、两个.py文件
-
文件夹(涉及个人和同学照片,未上传,测试时自己直接新建即可)
test_img : 此文件夹中直接存放需要识别对象的一张照片
emb_img: 此文件夹可以自己新建,或者不管(脚本中对这个文件夹检测了,没有则新建),用于存放剪切后的160*160尺寸的人脸图片
-
.py文件(一个用来批处理图片,一个用来运行检测)
calculate_dection_face.py : 代码中已经注明了有些路径自己要更改一下,先执行此脚本,进行人脸定位切割(有点残忍的感觉)
new_face_recognition.py : 直接执行即可,此次默认使用的是电脑自带的摄像头(如果要使用手机的,自己改一下,还是以前方法),路径也要注意
此次代码中的路径我使用的都是绝对路径,所以要根据自己的路径更改一下
github地址:https://github.com/WindZu/facenet_facerecognition 如果觉得有用,给个小星星啦,我会很开心的:)