





A fork of so-vits-svc with realtime support and greatly improved interface. Based on branch 4.0 (v1) and the models are compatible.
Install this via pip (or your favourite package manager):
pip install -U torch torchaudio --index-url https://download.pytorch.org/whl/cu117
pip install so-vits-svc-fork- Realtime voice conversion
- GUI available
- Unified command-line interface (no need to run Python scripts)
- Ready to use just by installing with
pip. - Automatically download pretrained base model and HuBERT model
- Code completely formatted with black, isort, autoflake etc.
- Other minor differences
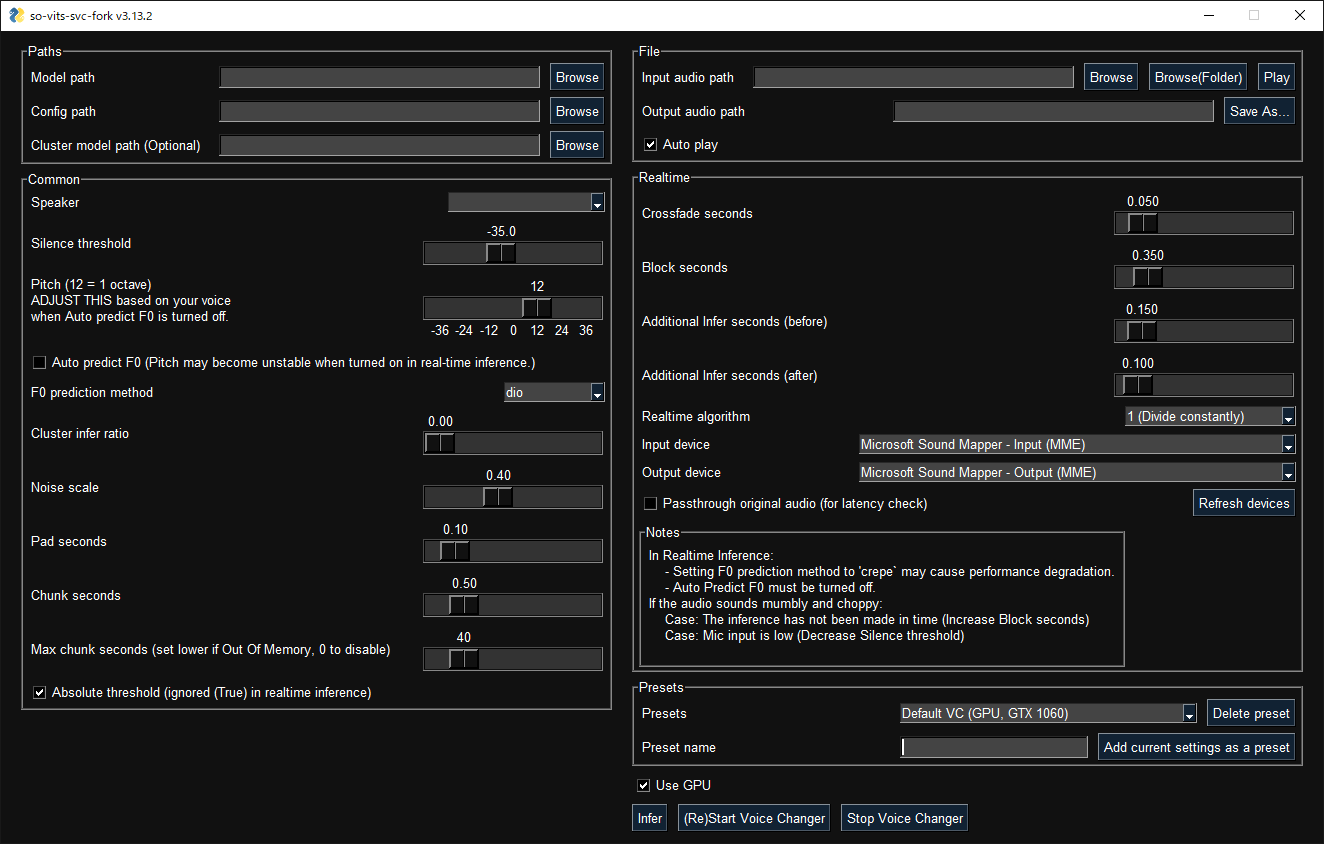
GUI launches with the following command:
svcg- Realtime (from microphone)
svc vc --model-path <model-path>- File
svc --model-path <model-path> source.wavUse of Google Colab is recommended. (To train locally, you need at least 12GB of VRAM.)
Place your dataset like dataset_raw/{speaker_id}/{wav_file}.wav and run:
svc pre-resample
svc pre-config
svc pre-hubert
svc trainFor more details, run svc -h or svc <subcommand> -h.
> svc -h
Usage: svc [OPTIONS] COMMAND [ARGS]...
so-vits-svc allows any folder structure for training data.
However, the following folder structure is recommended.
When training: dataset_raw/{speaker_name}/{wav_name}.wav
When inference: configs/44k/config.json, logs/44k/G_XXXX.pth
If the folder structure is followed, you DO NOT NEED TO SPECIFY model path, config path, etc.
(The latest model will be automatically loaded.)
To train a model, run pre-resample, pre-config, pre-hubert, train.
To infer a model, run infer.
Options:
-h, --help Show this message and exit.
Commands:
clean Clean up files, only useful if you are using the default file structure
infer Inference
onnx Export model to onnx
pre-config Preprocessing part 2: config
pre-hubert Preprocessing part 3: hubert If the HuBERT model is not found, it will be...
pre-resample Preprocessing part 1: resample
train Train model If D_0.pth or G_0.pth not found, automatically download from hub.
train-cluster Train k-means clustering
vc Realtime inference from microphoneThanks goes to these wonderful people (emoji key):
 34j 💻 🤔 📖 |
This project follows the all-contributors specification. Contributions of any kind welcome!