A recurrent neural network trained to draw dicks.
Demo: https://dickrnn.github.io/
GitHub: https://github.com/dickrnn/dickrnn.github.io/
This project is based on the original sketch-rnn demo, and is a fork of sketch-rnn-js, but customized for dicks.
The methodology is described in this paper: https://arxiv.org/abs/1704.03477
Dataset used for training is based on Quickdraw-appendix.
“Mean Time To Dick is a key measure of any given human or machine intelligence system.” — Elon Musk, on dick-rnn.
Reddit: dick-rnn discussions on /r/MachineLearning and r/javascript.
Articles about dick-rnn around the world, in The Next Web, Boing Boing, PC Gamer, Mashable, Dlisted, 9GAG, Código Espagueti and HD Tecnologia (Spanish), Feber (Swedish), dobreprogramy (Polish), futuretech (Austrian German), 4Gamers (Traditional Chinese), Gigazine and Karapaia (Japanese).
From Studio Moniker's Quickdraw-appendix project:
In 2018 Google open-sourced the Quickdraw data set. “The world's largest doodling data set”. The set consists of 345 categories and over 50 million drawings. For obvious reasons the data set was missing a few specific categories that people seem to enjoy drawing. This made us at Moniker think about the moral reality big tech companies are imposing on our global community and that most people willingly accept this. Therefore we decided to publish an appendix to the Google Quickdraw data set.
I also believe that “Doodling a penis is a light-hearted symbol for a rebellious act” and also “think our moral compasses should not be in the hands of big tech”.
The dicks are embedded in the query string after share.html.
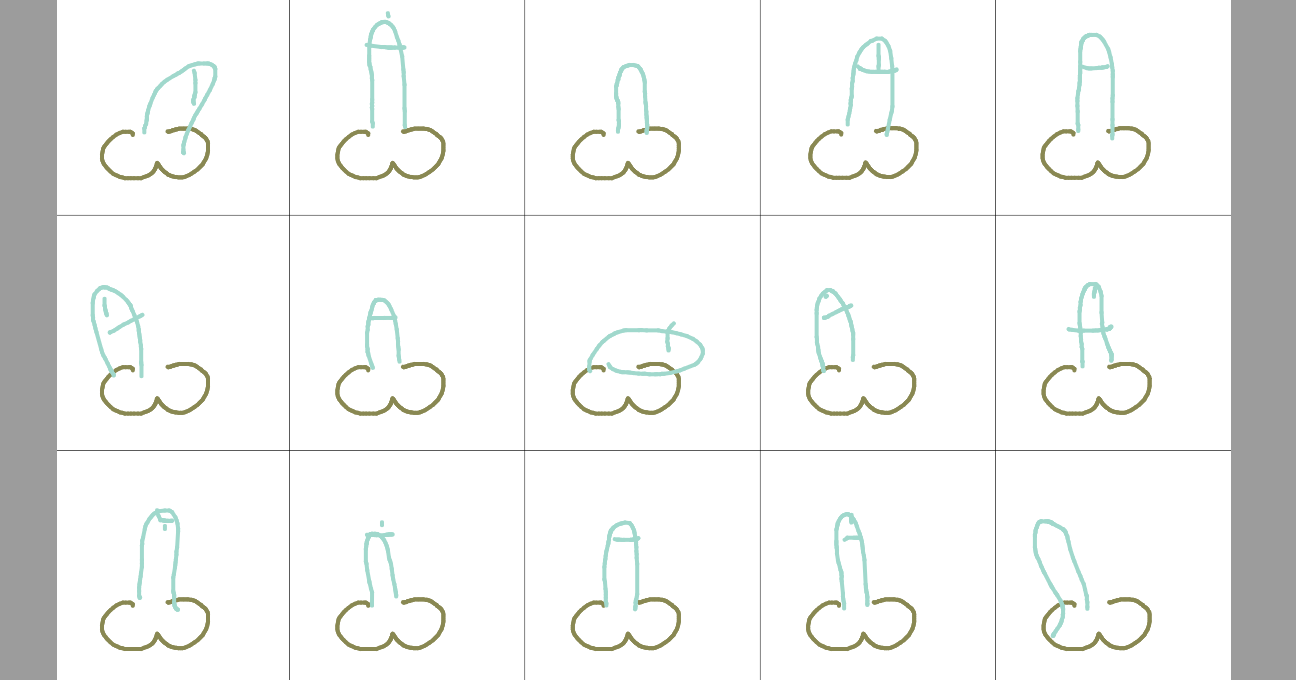
Examples of sharable generated dick doodles:
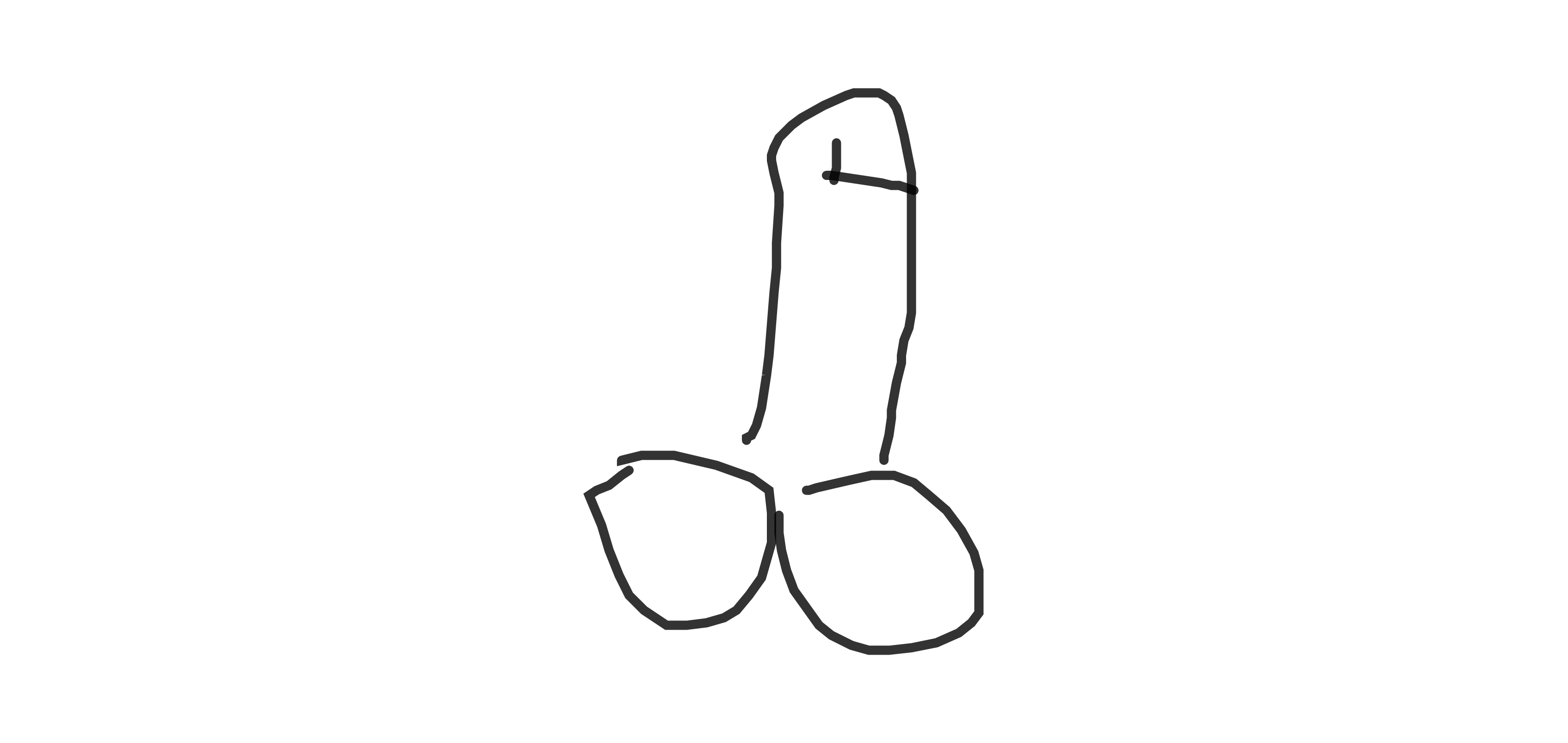
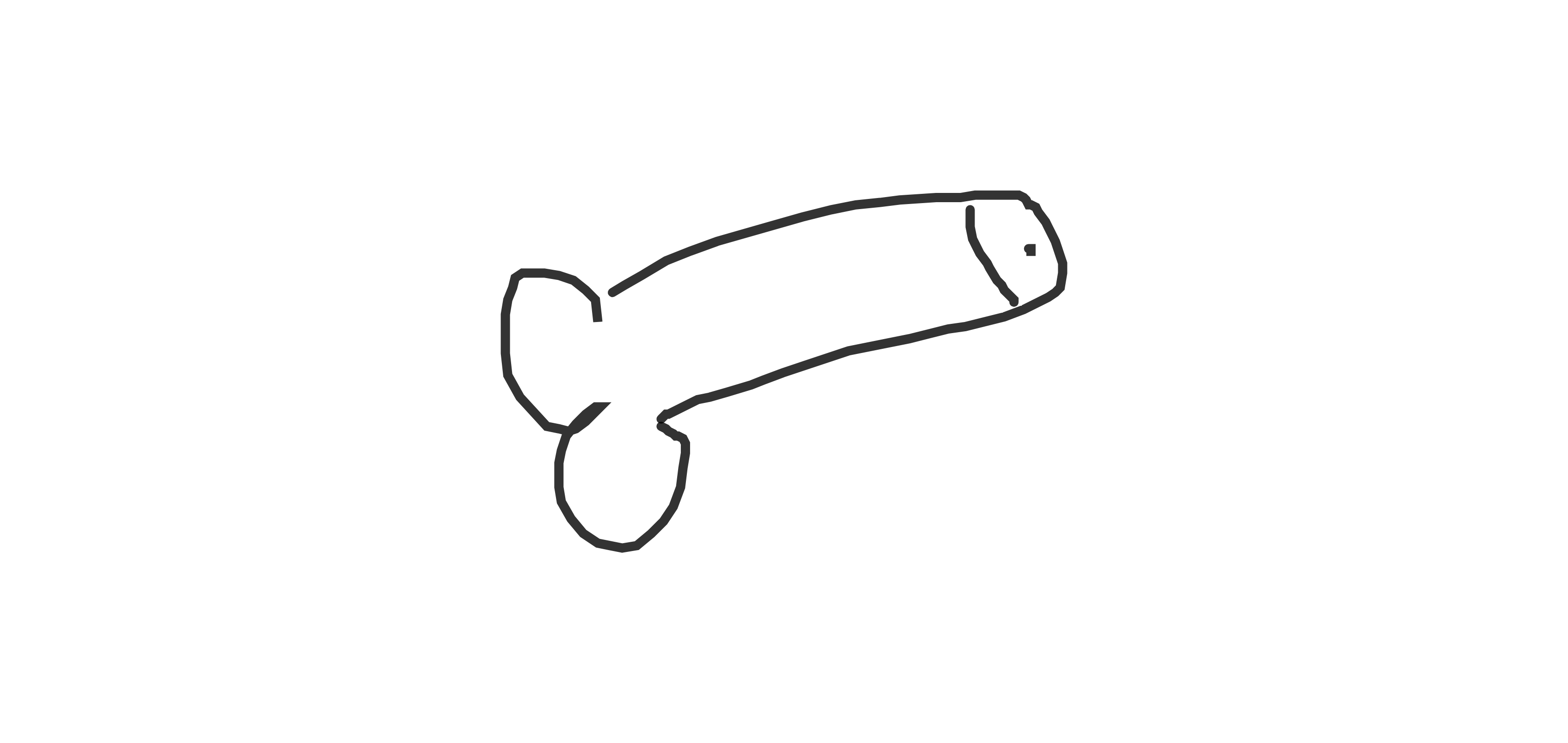
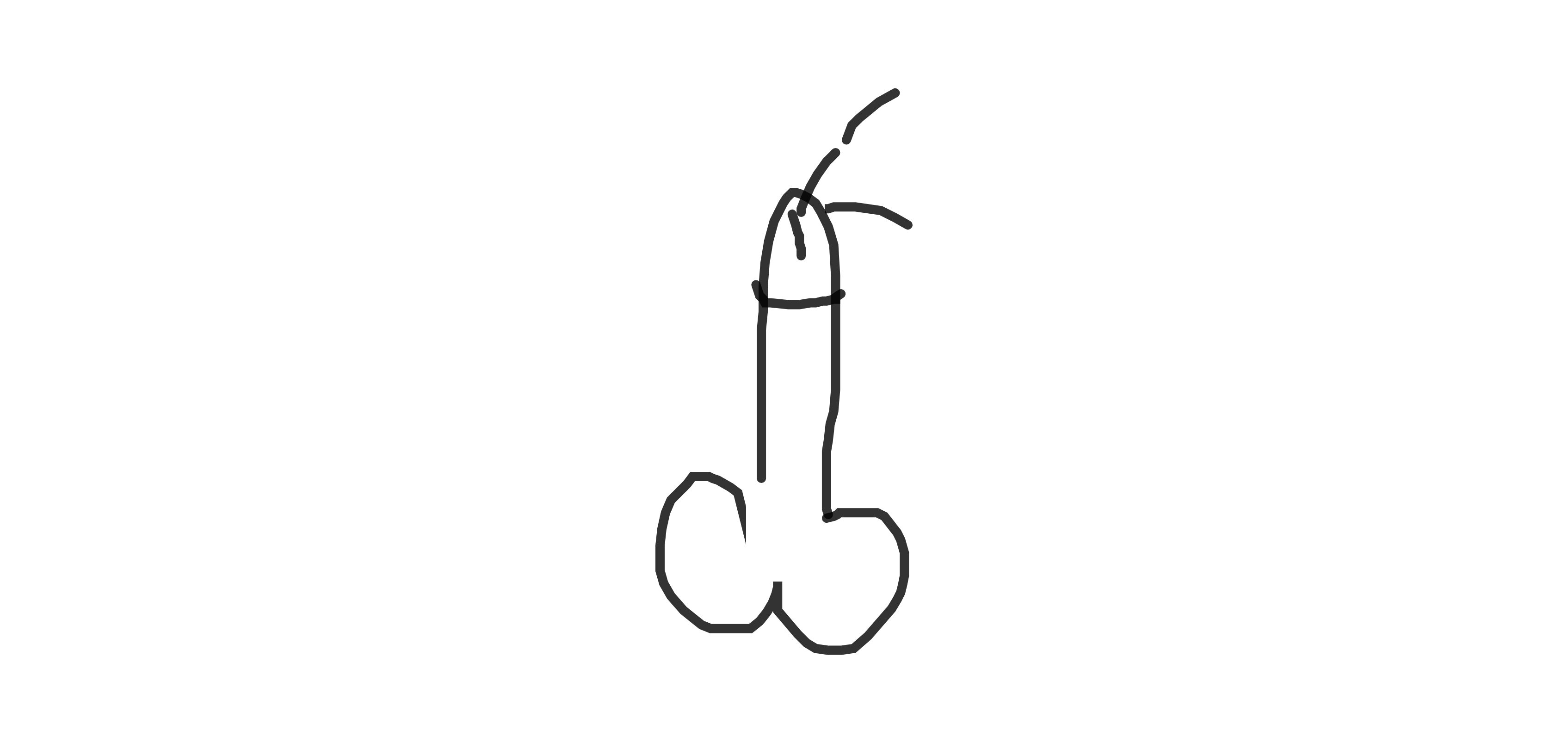

This recurrent neural network was trained on a dataset of roughly 10,000 dick doodles.
The Quickdraw-appendix dataset was processed via incremental RDP epsilons to fit most dicks within 200 steps. Note that I used the raw version, not their simplified version, since the dicks were more detailed. The processed dataset that is compatable with sketch-rnn's strokes (no pun) is in this repo as dataset/dicks.npz and can be loaded this way:
filename = "dataset/dicks.npz"
load_data = np.load(filename)
train_set = load_data['train']
valid_set = load_data['valid']
test_set = load_data['test']
print(len(train_set))
> Output: 9500
print(len(valid_set))
> Output: 496
print(len(test_set))
> Output: 496
# draw a random example (see draw_strokes.py)
draw_strokes(random.choice(train_set), factor=0.5)Training samples from the dataset:

For best results, train with default sketch-rnn settings, but use a dropout keep probability of 80%. Early stopping was performed on the validation set. To maximize samples used for training/validation, no test set is used, and the test set is just set to the same 496 validation samples to be compatable with the data format expected by the existing code.
Command used to train the TensorFlow sketch-rnn model:
python sketch_rnn_train.py --data_dir=dataset --gpu=0 --log_root=log --hparams=data_set=['dicks.npz'],num_steps=1000000,conditional=0,dec_rnn_size=512,recurrent_dropout_prob=0.8
I found a Jupyter notebook in the sketch-rnn repo that easily converted the TensorFlow checkpoint into the .gen.full.json format that sketch-rnn-js can use, with the command:
node compress_model.js custom.gen.full.json dick.gen.js
Update (4/27/2020) The Quickdraw-appendix dataset was updated, and there are now 25K examples, up from the earlier 10K. I processed the newer dataset as dicksv2.npz with a proper train/valid/test split of 23000/1500/693 samples. The Main Demo has been updated to use a larger, but slightly slower model trained on the revised dataset containing more training examples.
Original license for each file is indicated in the header comment for each source file, or referenced in the URL stated in the source file. Creative Commons License for datasets also indicated accordingly.
MIT License for my specific additional work.