
⬇️ Download AI Workbench • 📖 Read the Docs • 📂 Explore Example Projects • 🚨 Facing Issues? Let Us Know!
Note: NVIDIA AI Workbench is the easiest way to get this RAG app running.
- NVIDIA AI Workbench is a free client application that you can install on your own machines.
- It provides portable and reproducible dev environments by handling Git repos and containers for you.
- Installing on a local system? Check out our guides here for Windows, Local Ubuntu 22.04 and for macOS 12 or higher
- Installing on a remote system? Check out our guide for Remote Ubuntu 22.04
This is an NVIDIA AI Workbench project for developing a Retrieval Augmented Generation application with a customizable Gradio Chat app. It lets you:
- Embed your documents into a locally running vector database.
- Run inference locally on a Hugging Face TGI server, in the cloud using NVIDIA inference endpoints, or using microservices via NVIDIA Inference Microservices (NIMs):
- 4-bit, 8-bit, and no quantization options are supported for locally running models served by TGI.
- Other models may be specified to run locally using their Hugging Face tag.
- Locally-running microservice option is supported for Docker users only.
Expand this section for a full table on all supported models by inference mode.
| Model | Local (TGI) | Cloud (NVIDIA API Catalog) | Microservices (NVIDIA NIMs) |
|---|---|---|---|
| Llama3-ChatQA-1.5-8B | Y | Y | * |
| Llama3-ChatQA-1.5-70B | Y | * | |
| Nemotron-Mini-4B | Y | * | |
| Nemotron-4-340B-Instruct | Y | * | |
| Mistral-NeMo 12B Instruct | Y | * | |
| Mistral-7B-Instruct-v0.1 | Y (gated) | * | |
| Mistral-7B-Instruct-v0.2 | Y (gated) | Y | * |
| Mistral-7B-Instruct-v0.3 | Y | Y | |
| Mistral-Large | Y | * | |
| Mixtral-8x7B-Instruct-v0.1 | Y | Y | |
| Mixtral-8x22B-Instruct-v0.1 | Y | Y | |
| Mamba Codestral 7B v0.1 | Y | * | |
| Codestral-22B-Instruct-v0.1 | Y | * | |
| Llama-2-7B-Chat | Y (gated) | * | |
| Llama-2-13B-Chat | * | ||
| Llama-2-70B-Chat | Y | * | |
| Llama-3-8B-Instruct | Y (gated) | Y | Y (default) * |
| Llama-3-70B-Instruct | Y | Y | |
| Llama-3.1-8B-Instruct | Y | * | |
| Llama-3.1-70B-Instruct | Y | * | |
| Llama-3.1-405B-Instruct | Y | * | |
| Gemma-2B | Y | * | |
| Gemma-7B | Y | * | |
| CodeGemma-7B | Y | * | |
| Phi-3-Mini-4k-Instruct | Y | * | |
| Phi-3-Mini-128k-Instruct | Y | Y | * |
| Phi-3-Small-8k-Instruct | Y | * | |
| Phi-3-Small-128k-Instruct | Y | * | |
| Phi-3-Medium-4k-Instruct | Y | * | |
| Phi-3-Medium-128k-Instruct | Y | * | |
| Phi-3.5-Mini-Instruct | Y | * | |
| Phi-3.5-MoE-Instruct | Y | * | |
| Arctic | Y | * | |
| Granite-8B-Code-Instruct | Y | * | |
| Granite-34B-Code-Instruct | Y | * | |
| Solar-10.7B-Instruct | Y | * | |
| Jamba-1.5-Mini-Instruct | Y | * | |
| Jamba-1.5-Large-Instruct | Y | * |
*NIM containers for LLMs are starting to roll out under General Availability (GA). If you set up any accessible language model NIM running on another system, it is supported under Remote NIM inference inside this project. For Local NIM inference, this project provides a flow for setting up the default meta/llama3-8b-instruct NIM locally as an example. Advanced users may choose to swap this NIM Container Image out with other NIMs as they are released.
This section demonstrates how to use this project to run RAG via NVIDIA Inference Endpoints hosted on the NVIDIA API Catalog. For other inference options, including local inference, see the Advanced Tutorials section for set up and instructions.
- An NGC account is required to generate an NVCF run key.
- A valid NVCF key is required to access NVIDIA API endpoints. Generate a key on any NVIDIA API catalog model card, eg. here by clicking "Get API Key".

- Install and configure AI Workbench locally and open up AI Workbench. Select a location of your choice.
- Fork this repo into your own GitHub account.
- Inside AI Workbench:
- Click Clone Project and enter the repo URL of your newly-forked repo.
- AI Workbench will automatically clone the repo and build out the project environment, which can take several minutes to complete.
- Upon
Build Complete, navigate to Environment > Secrets > NVCF_RUN_KEY > Configure and paste in your NVCF run key as a project secret. - Select Open Chat on the top right of the AI Workbench window, and the Gradio app will open in a browser.
- In the Gradio Chat app:
- Click Set up RAG Backend. This triggers a one-time backend build which can take a few moments to initialize.
- Select the Cloud option, select a model family and model name, and submit a query.
- To perform RAG, select Upload Documents Here from the right hand panel of the chat UI.
- You may see a warning that the vector database is not ready yet. If so wait a moment and try again.
- When the database starts, select Click to Upload and choose the text files to upload.
- Once the files upload, the Toggle to Use Vector Database next to the text input box will turn on.
- Now query your documents! What are they telling you?
- To change the endpoint, choose a different model from the dropdown on the right-hand settings panel and continue querying.
Next Steps:
- If you get stuck, check out the "Troubleshooting" section.
- For tutorials on other supported inference modes, check out the "Advanced Tutorials" section below. Note: All subsequent tutorials will assume
NVCF_RUN_KEYis already configured with your credentials.
Need help? Submit any questions, bugs, feature requests, and feedback at the Developer Forum for AI Workbench. The dedicated thread for this Hybrid RAG example project is located here.
-
Make sure you installed AI Workbench. There should be a desktop icon on your system. Double click it to start AI Workbench.


-
Make sure you have opened AI Workbench.
-
Click on the Local location (or whatever location you want to clone into).
-
If this is your first project, click the green Clone Existing Project button.
- Otherwise, click Clone Project in the top right
-
Drop in the repo URL, leave the default path, and click Clone.
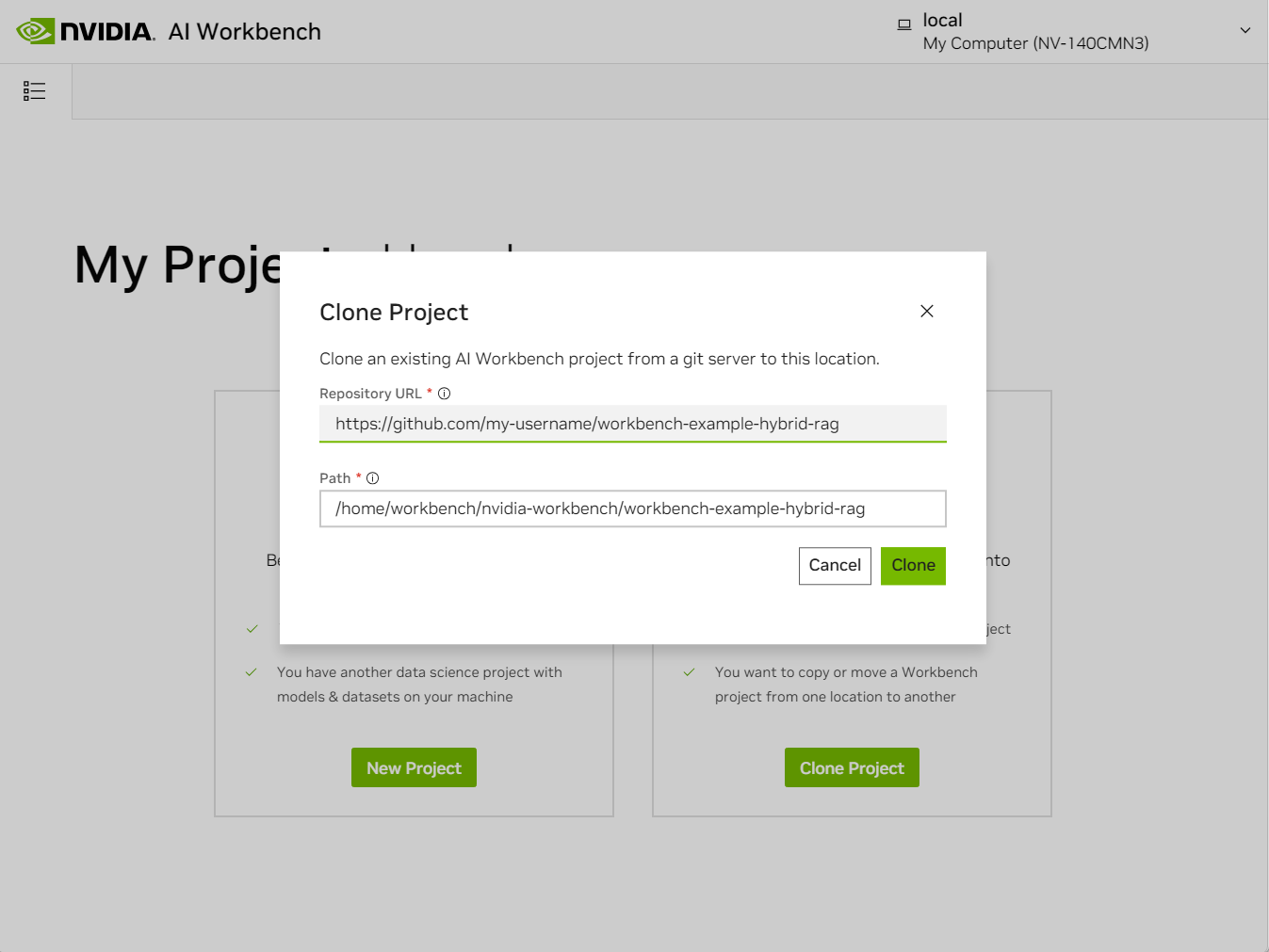

-
The container is likely building and can take several minutes.
-
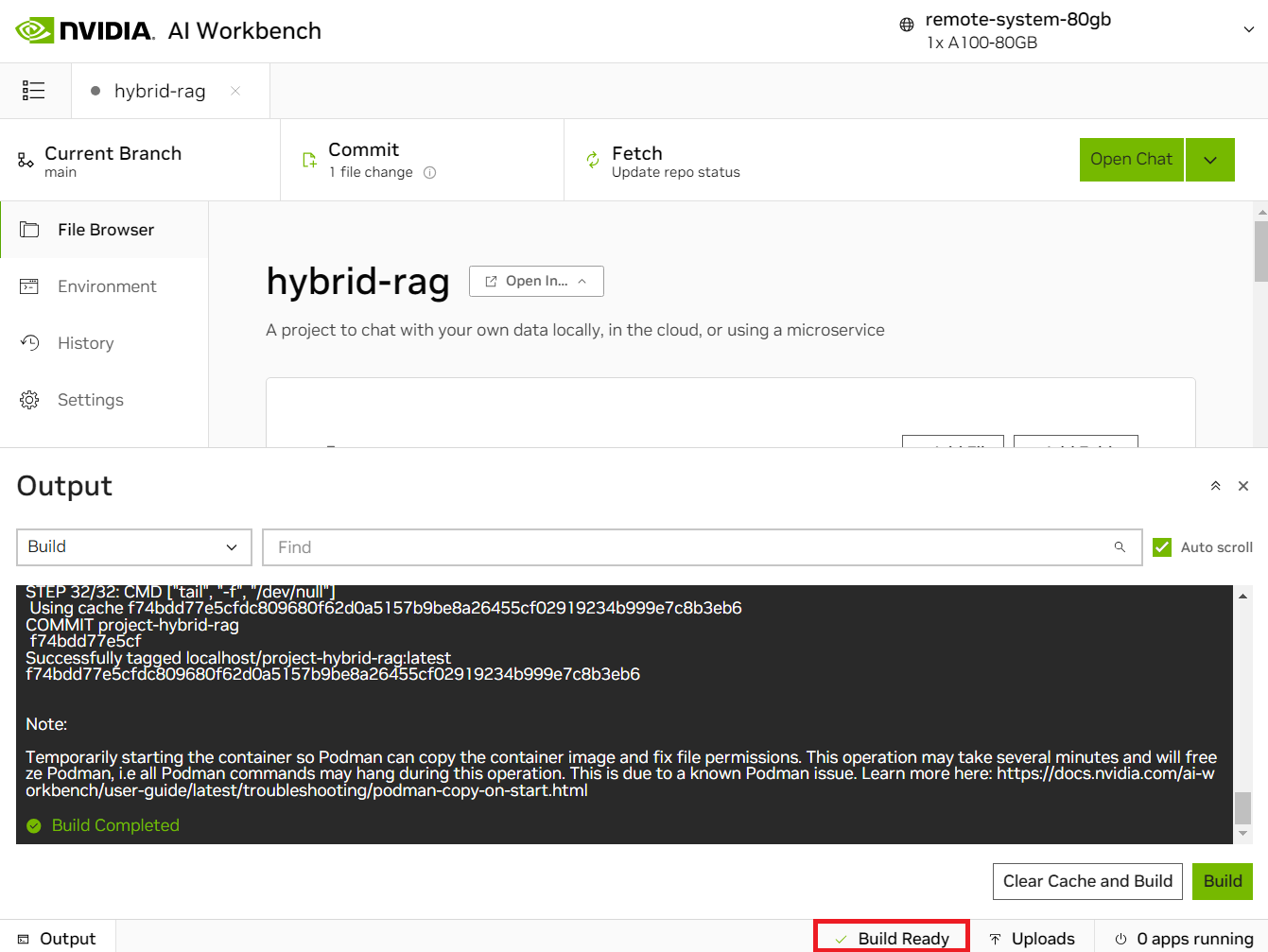
Look at the very bottom of the Workbench window, you will see a Build Status widget.
-
Click it to expand the build output.
-
When the container is built, the widget will say
Build Ready. -
Now you can begin.

-
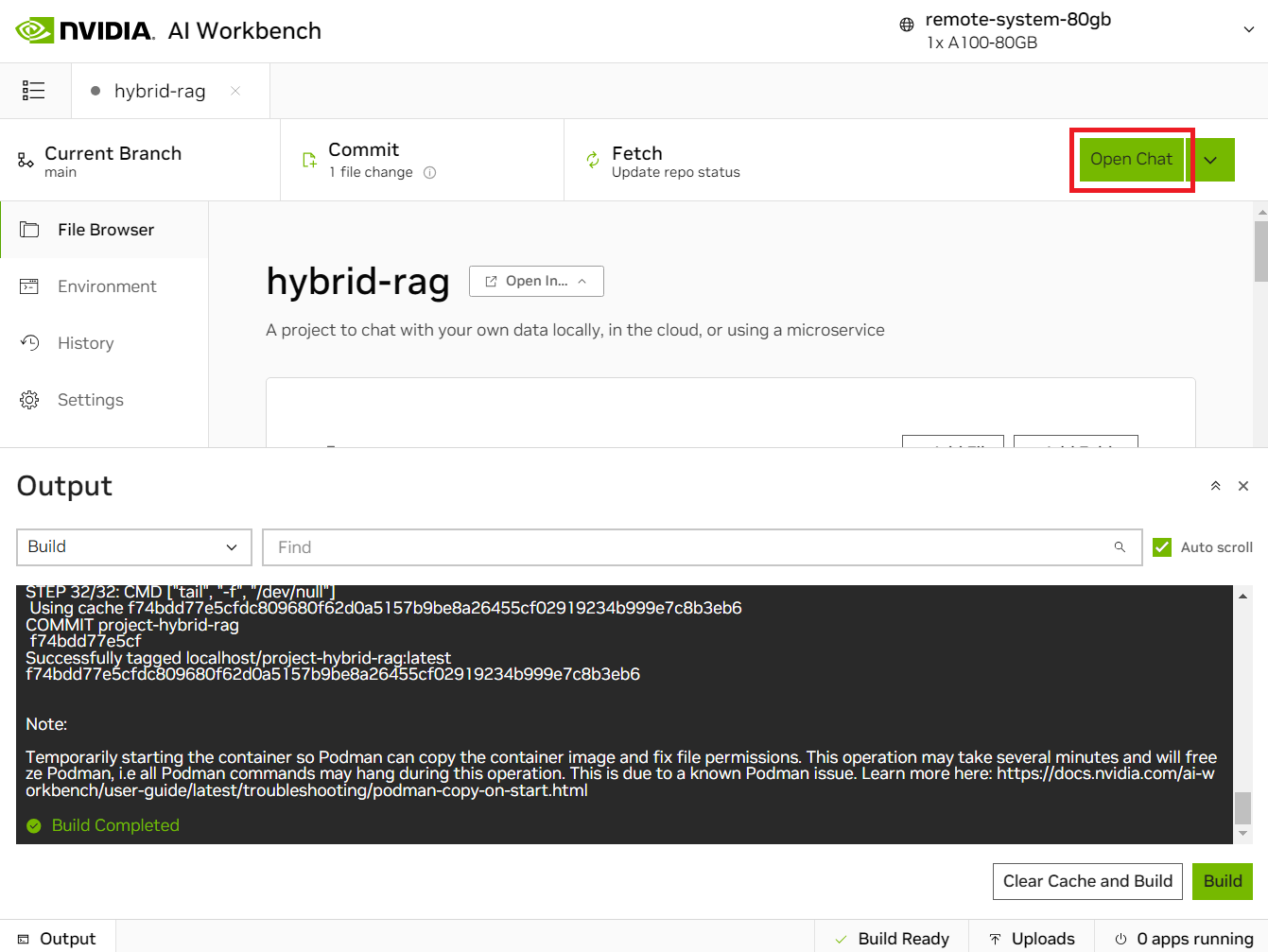
Check that the container finished building.
-
When it finishes, click the green Open Chat button at the top right.

-
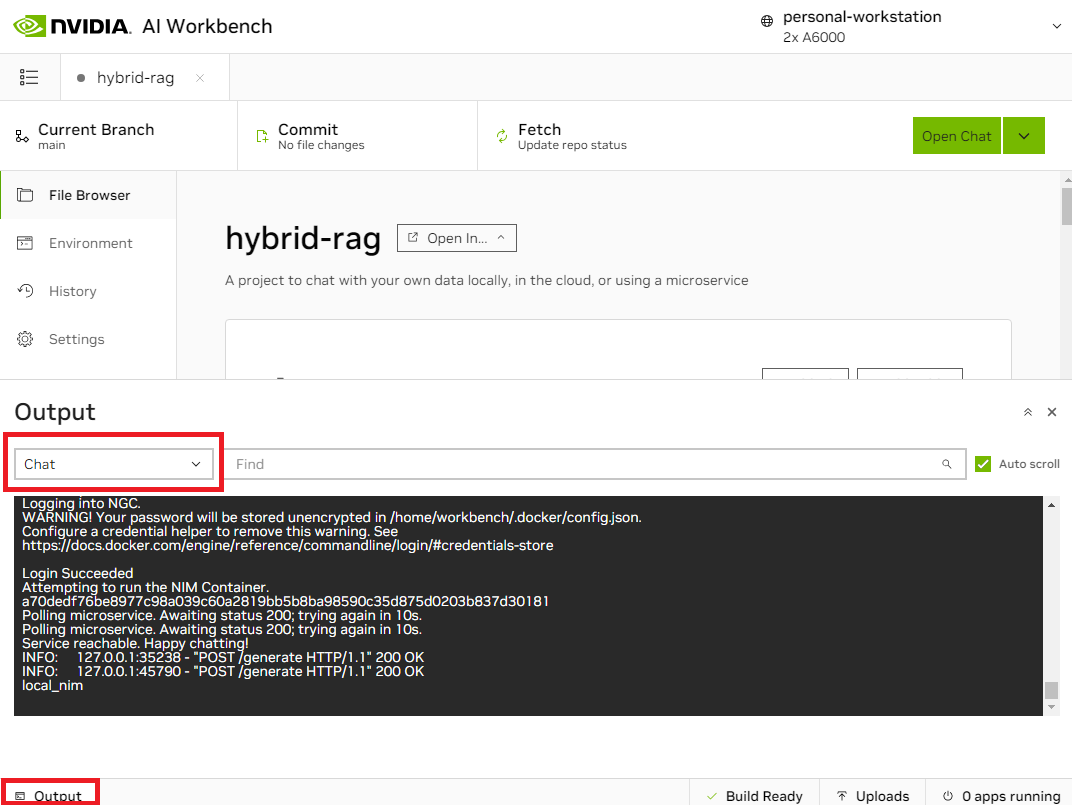
Look at the bottom left of the AI Workbench window, you will see an Output widget.
-
Click it to expand the output.
-
Expand the dropdown, navigate to
Applications>Chat. -
You can now view all debug messages in the Output window in real time.

-
Check that the container is built.
-
Then click the green dropdown next to the
Open Chatbutton at the top right. -
Select JupyterLab to start editing the code. Alternatively, you may configure VSCode support here.

This section shows you how to use different inference modes with this RAG project. For these tutorials, a GPU of at least 12 GB of vRAM is recommended. If you don't have one, go back to the Quickstart Tutorial that shows how to use Cloud Endpoints.
This tutorial assumes you already cloned this Hybrid RAG project to your AI Workbench. If not, please follow the beginning of the Quickstart Tutorial.

The following models are ungated. These can be accessed, downloaded, and run locally inside the project with no additional configurations required:
Some additional configurations in AI Workbench are required to run certain listed models. Unlike the previous tutorials, these configs are not added to the project by default, so please follow the following instructions closely to ensure a proper setup. Namely, a Hugging Face API token is required for running gated models locally. See how to create a token here.
The following models are gated. Verify that You have been granted access to this model appears on the model cards for any models you are interested in running locally:
Then, complete the following steps:
- If the project is already running, shut down the project environment under Environment > Stop Environment. This will ensure restarting the environment will incorporate all the below configurations.
- In AI Workbench, add the following entries under Environment > Secrets.
- Your Hugging Face Token: This is used to clone the model weights locally from Hugging Face.
- Name:
HUGGING_FACE_HUB_TOKEN - Value: (Your HF API Key)
- Description: HF Token for cloning model weights locally
- Name:
- Your Hugging Face Token: This is used to clone the model weights locally from Hugging Face.
- Rebuild the project if needed to incorporate changes.
Note: All subsequent tutorials will assume both NVCF_RUN_KEY and HUGGING_FACE_HUB_TOKEN are already configured with your credentials.
- Select the green Open Chat button on the top right the AI Workbench project window.
- Once the UI opens, click Set up RAG Backend. This triggers a one-time backend build which can take a few moments to initialize.
- Select the Local System inference mode under
Inference Settings>Inference Mode. - Select a model from the dropdown on the right hand settings panel. You can filter by gated vs ungated models for convenience.
- Ensure you have proper access permissions for the model; instructions are here.
- You can also input a custom model from Hugging Face, following the same format. Careful, as not all models and quantization levels may be supported in the current TGI version!
- Select a quantization level. The recommended precision for your system will be pre-selected for you, but full, 8-bit, and 4-bit bitsandbytes precision levels are currently supported.
| vRAM | System RAM | Disk Storage | Model Size & Quantization |
|---|---|---|---|
| >=12 GB | 32 GB | 40 GB | 7B & int4 |
| >=24 GB | 64 GB | 40 GB | 7B & int8 |
| >=40 GB | 64 GB | 40 GB | 7B & none |
- Select Load Model to pre-fetch the model. This will take up to several minutes to perform an initial download of the model to the project cache. Subsequent loads will detect this cached model.
- Select Start Server to start the inference server with your current local GPU. This may take a moment to warm up.
- Now, start chatting! Queries will be made to the model running on your local system whenever this inference mode is selected.
- In the right hand panel of the Chat UI select Upload Documents Here. Click to upload or drag and drop the desired text files to upload.
- You may see a warning that the vector database is not ready yet. If so wait a moment and try again.
- Once the files upload, the Toggle to Use Vector Database next to the text input box will turn on by default.
- Now query your documents! To use a different model, stop the server, make your selections, and restart the inference server.
This tutorial assumes you already cloned this Hybrid RAG project to your AI Workbench. If not, please follow the beginning of the Quickstart Tutorial.

- Set up your NVIDIA Inference Microservice (NIM) to run self-hosted on another system of your choice. The playbook to get started is located here. Remember the model name (if not the
meta/llama3-8b-instructdefault) and the ip address of this running microservice. Ports for NIMs are generally set to 8000 by default. - Alternatively, you may set up any other 3rd party supporting the OpenAI API Specification. One example is Ollama, as they support the OpenAI API Spec. Remember the model name, port, and the ip address when you set this up.
- Select the green Open Chat button on the top right the AI Workbench project window.
- Once the UI opens, click Set up RAG Backend. This triggers a one-time backend build which can take a few moments to initialize.
- Select the Self-hosted Microservice inference mode under
Inference Settings>Inference Mode. - Select the Remote tab in the right hand settings panel. Input the IP address of the accessible system running the microservice, Port if different from the 8000 default for NIMs, as well as the model name to run if different from the
meta/llama3-8b-instructdefault. - Now start chatting! Queries will be made to the microservice running on a remote system whenever this inference mode is selected.
- In the right hand panel of the Chat UI select Upload Documents Here. Click to upload or drag and drop the desired text files to upload.
- You may see a warning that the vector database is not ready yet. If so wait a moment and try again.
- Once uploaded successfully, the Toggle to Use Vector Database should turn on by default next to your text input box.
- Now you may query your documents!
This tutorial assumes you already cloned this Hybrid RAG project to your AI Workbench. If not, please follow the beginning of the Quickstart Tutorial.

Here are some important PREREQUISITES:
- Your AI Workbench must be running with a DOCKER container runtime. Podman is unsupported.
- You must have access to NeMo Inference Microservice (NIMs) General Availability Program.
- Shut down any other processes running locally on the GPU as these may result in memory issues when running the microservice locally.
Some additional configurations in AI Workbench are required to run this tutorial. Unlike the previous tutorials, these configs are not added to the project by default, so please follow the following instructions closely to ensure a proper setup.
- If running, shut down the project environment under Environment > Stop Environment. This will ensure restarting the environment will incorporate all the below configurations.
- In AI Workbench, add the following entries under Environment > Secrets:
- Your NGC API Key: This is used to authenticate when pulling the NIM container from NGC. Remember, you must be in the General Availability Program to access this container.
- Name:
NGC_CLI_API_KEY - Value: (Your NGC API Key)
- Description: NGC API Key for NIM authentication
- Name:
- Your NGC API Key: This is used to authenticate when pulling the NIM container from NGC. Remember, you must be in the General Availability Program to access this container.
- Add and/or modify the following under Environment > Variables:
DOCKER_HOST: location of your docker socket, eg.unix:///var/host-run/docker.sockLOCAL_NIM_HOME: location of where your NIM files will be stored, for example/mnt/c/Users/<my-user>for Windows or/home/<my-user>for Linux
- Add the following under Environment > Mounts:
- A Docker Socket Mount: This is a mount for the docker socket for the container to properly interact with the host Docker Engine.
- Type:
Host Mount - Target:
/var/host-run - Source:
/var/run - Description: Docker socket Host Mount
- Type:
- A Filesystem Mount: This is a mount to properly run and manage your LOCAL_NIM_HOME on the host from inside the project container for generating the model repo.
- Type:
Host Mount - Target:
/mnt/host-home - Source: (Your LOCAL_NIM_HOME location) , for example
/mnt/c/Users/<my-user>for Windows or/home/<my-user>for Linux - Description: Host mount for LOCAL_NIM_HOME
- Type:
- A Docker Socket Mount: This is a mount for the docker socket for the container to properly interact with the host Docker Engine.
- Rebuild the project if needed.
- Select the green Open Chat button on the top right the AI Workbench project window.
- Once the UI opens, click Set up RAG Backend. This triggers a one-time backend build which can take a few moments to initialize.
- Select the Self-hosted Microservice inference mode under
Inference Settings>Inference Mode. - Select the Local sub-tab in the right hand settings panel.
- Bring your NIM Container Image (placeholder can be used as the default flow), and select Prefetch NIM. This one-time process can take a few moments to pull down the NIM container.
- Select Start Microservice. This may take a few moments to complete.
- Now, you can start chatting! Queries will be made to your microservice running on the local system whenever this inference mode is selected.
- In the right hand panel of the Chat UI select Upload Documents Here. Click to upload or drag and drop the desired text files to upload.
- You may see a warning that the vector database is not ready yet. If so wait a moment and try again.
- Once uploaded successfully, the Toggle to Use Vector Database should turn on by default next to your text input box.
- Now you may query your documents!
By default, you may customize Gradio app using the jupyterlab container application. Alternatively, you may configure VSCode support here.
- In AI Workbench, select the green dropdown from the top right and select Open JupyterLab.
- Go into the
code/chatui/folder and start editing the files. - Save the files.
- To see your changes, stop the Chat UI and restart it.
- To version your changes, commit them in the Workbench project window and push to your GitHub repo.
In addition to modifying the Gradio frontend, you can also use the Jupyterlab or another IDE to customize other aspects of the project, eg. custom chains, backend server, scripts, configs, etc.
This NVIDIA AI Workbench example project is under the Apache 2.0 License
This project may download and install additional third-party open source software projects. Review the license terms of these open source projects before use. Third party components used as part of this project are subject to their separate legal notices or terms that accompany the components. You are responsible for confirming compliance with third-party component license terms and requirements.