
- Application designed for analysing linguistic properties of various texts
- Builds fingerprints for classified text to associate authorship
- Can do comparitive analysis on text, compare and contrast if two structures align
- Can be scaled for better accuracy in some benchmarks
- Install dependencies
pip install -r requirements.txt
- Requires placing a GGUF formatted model in this directory
./vendor/llama.guard/llama-guard-2-8b.f16.gguf
- Requires compiling llama.cpp in this directory
./vendor/llama.cpp/main
- Requires placing a
prompt.txtfile in
./vendor/llama.guard/prompt.txt
see the examples section for more info
- Fingerprint style of document
python3 ./main.py --input <PATH TO TEXT FILE>
- Fingerprint style of document and output results
python3 ./main.py --input <PATH> --output <PATH>
- Launch collaborative web server
python3 ./server.py
- CLI and Web UI support
- N-gram factorial style pairing
- Spelling mistake tracking
- Word frequency and usage
- Words per line hits tracking
- Characters per word hits tracking
- Comparing fingerprint profiles
- Local LLM classifier to mark content based on categories
- Create OCR features for picking apart non-text data
- SQLite database toggle for persistent data storage
- Changing of categories of interest prompt from web UI and CLI
- Optimize everything more
- Use Llama python bindings instead of llama.cpp directly
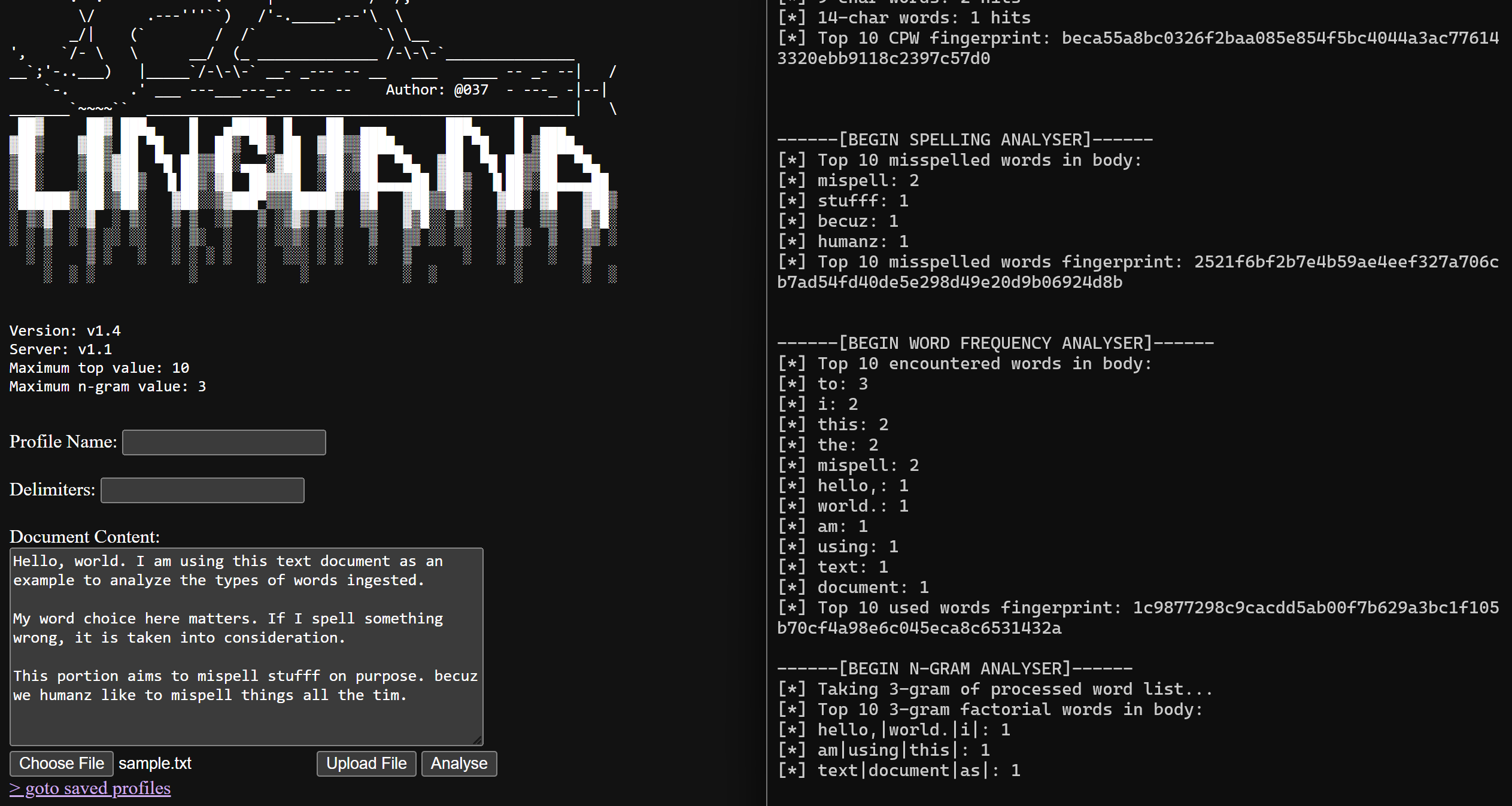 Linguana front web UI dashboard and CLI logs. Shows where documents can be uploaded or pasted, and various techniques in which they are analyzed.
Linguana front web UI dashboard and CLI logs. Shows where documents can be uploaded or pasted, and various techniques in which they are analyzed.
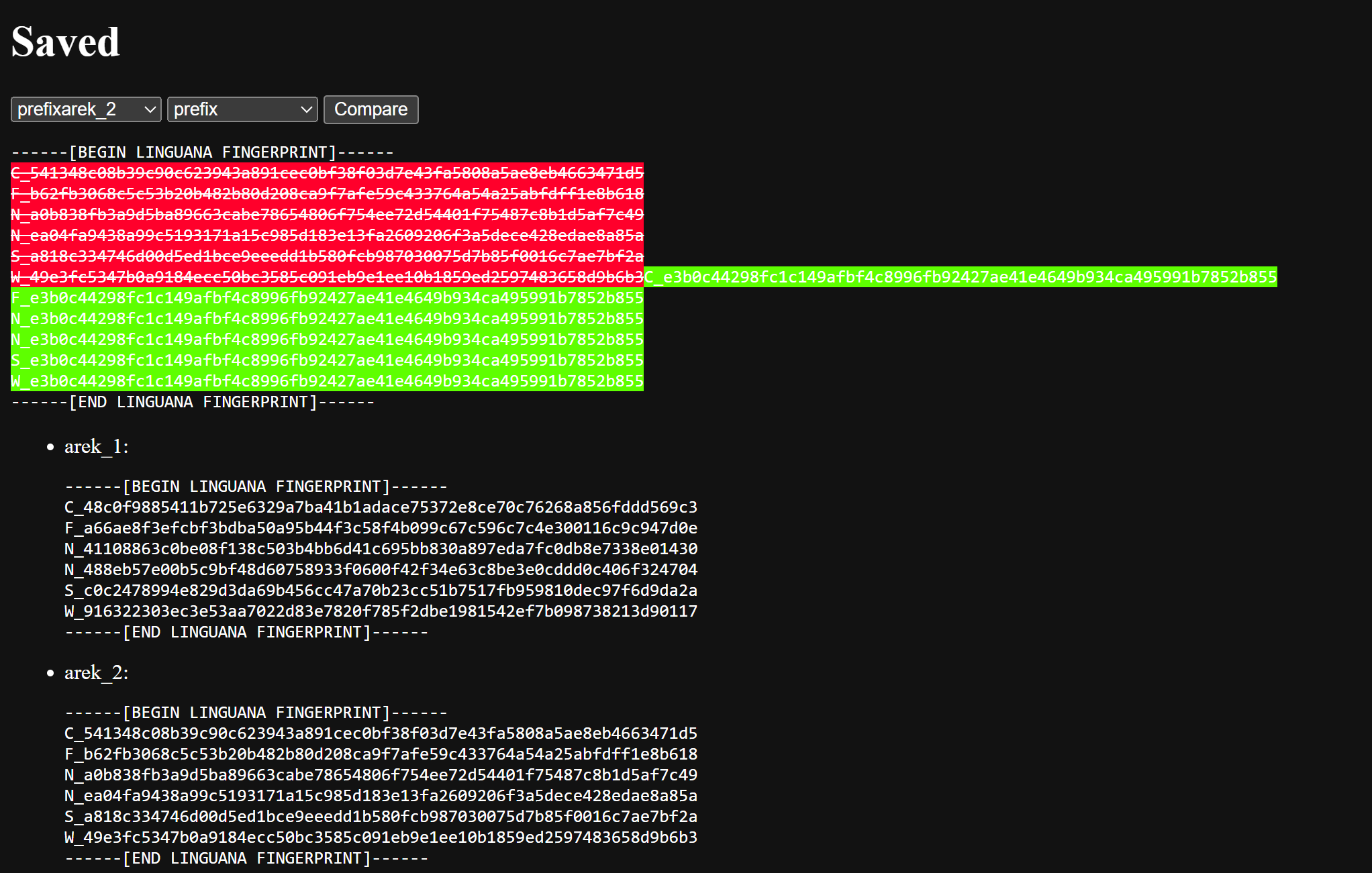 Linguana comparing saved fingerprints. Data is saved in memory. Allows for collaboration, data accessible across all visitors to contribute.
Linguana comparing saved fingerprints. Data is saved in memory. Allows for collaboration, data accessible across all visitors to contribute.
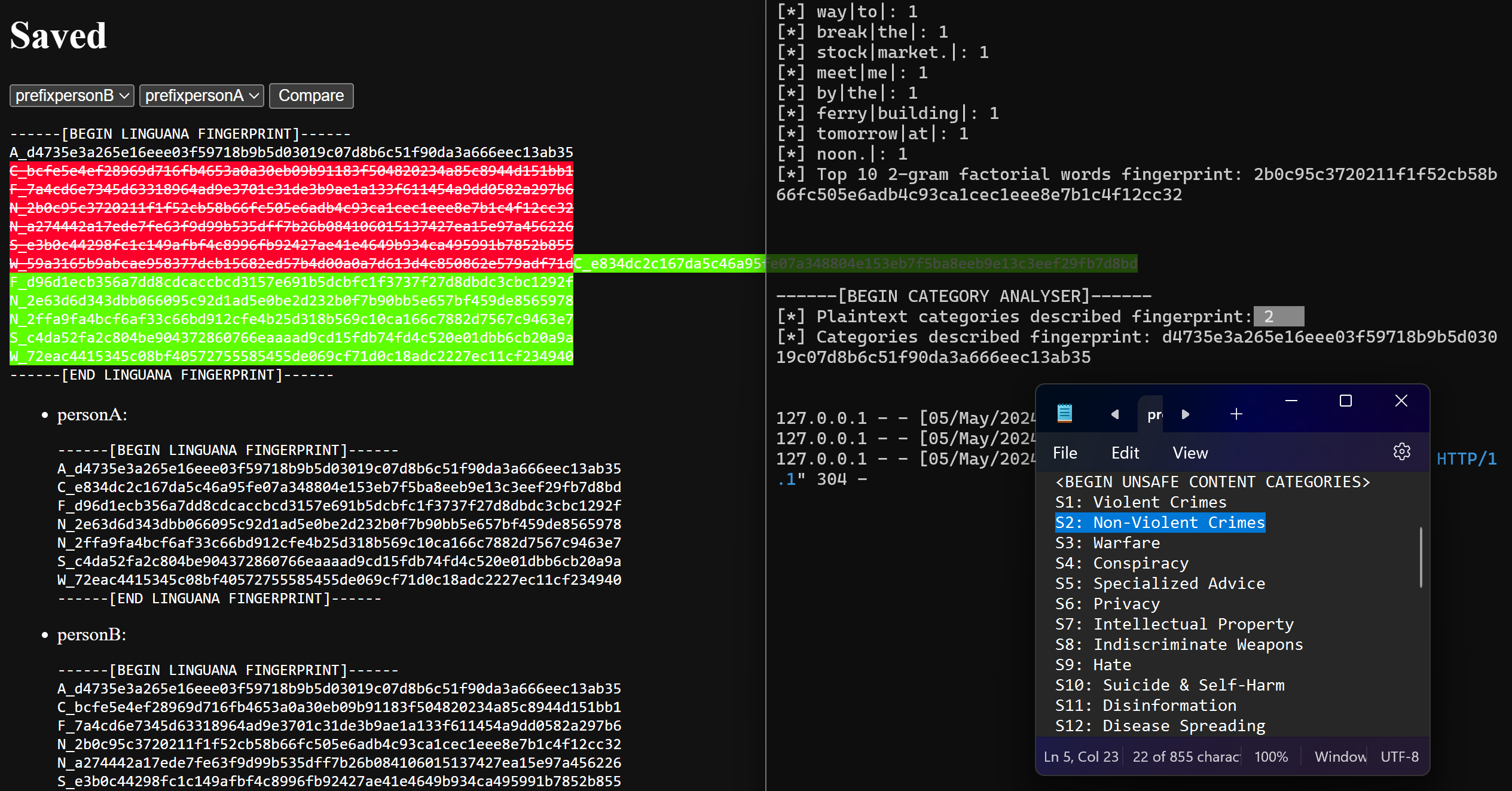 Linguana using its classifier local LLM inference to notice the language data given falls under one of the defined categories of interest.
Linguana using its classifier local LLM inference to notice the language data given falls under one of the defined categories of interest.