实体关系抽取是文本结构化、构建专业知识图谱的核心step。
本算法是GPLinker的pytorch复现(简单易懂,杜绝花里胡哨),该方法的核心是:
- 对输入文本 S={w1,w2,...,wn} 的编码向量以【token-pair】标记方式建模 n×n 大小的词元矩阵,进而做实体识别、实体关系抽取任务。
- 与之相似的工作有:TP-Linker、multi-head selection、Word-pair 等。较之传统的 BIO 序列标注、span指针网络标注方式,token-pair 建模方式现在是实体关系抽取 sota 的必备。
中文医疗信息处理挑战榜CBLUE 中CMeIE数据集,同样是 CHIP2020/2021 的医学实体关系抽取数据集。
- python 3.8.1
- pytorch==1.8.1
- transformer==4.9.2
- configparser
请把 config.ini 中对应的【paths】换为你自己的
python main.py
python predict.py
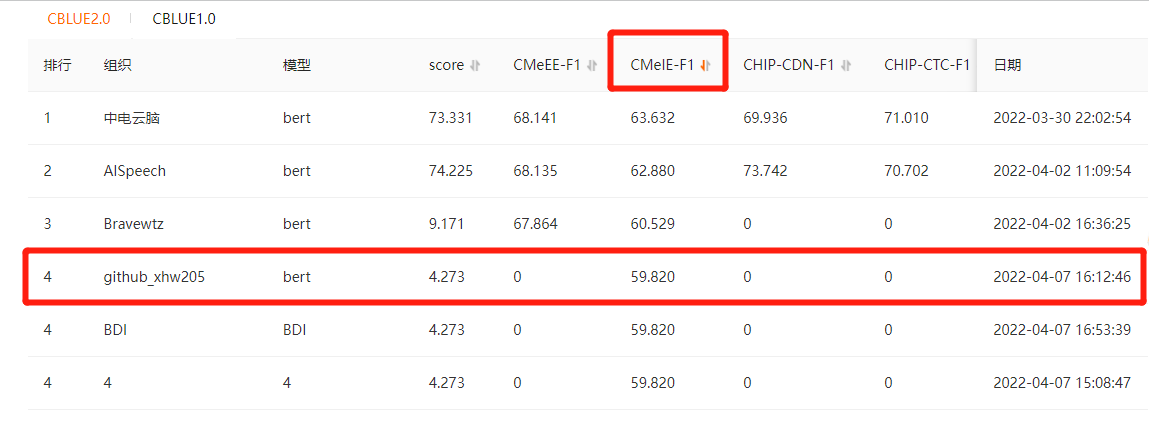
- 使用医学实体关系抽取数据集,阿里天池在线测试F1分数【59.82%】,提交的测试结果在./result文件夹中
- 之前复现的CasRel方法,在线F1分数为【60%】
- 注意最新的 CBLUE 打榜,需要把生成的CMeIE_test.json后缀改为jsonl,再压缩提交
- 训练过程未根据验证集的F1分数保存最优模型,直接用的最后一个epoch的权重,有需要的自行实现就好了
- 把globalpointer 替换 Efficient-GlobalPointer,torch的源码本人都已经公布,自行实现就好