The repository contains lists of papers on causality and how relevant techniques are being used to further enhance deep learning era computer vision solutions.
The repository is organized by Maheep Chaudhary and Haohan Wang as an effort to collect and read relevant papers and to hopefully serve the public as a collection of relevant resources.
-
The Seven Tools of Causal Inference with Reflections on Machine Learning
-
Maheep's notes
The author proposes the 7 tools based on the 3 ladder of causation, i.e. Associaion, Intervention and Counterfactual. the paper proposes a diagram which describes that we have some assumptions from which we answer our query and from our data we validate our assumptions, i.e. "Fit Indices".The author proposes the 7 tools as :-
1. Transparency and Testability : Transparency indicates that the encoded form is easily usable and compact. The testability validates that the assumption encoded are compatible with the available data
2. Do-Calculas and the control of Confounding : It is used for intervention, mainly used when we are trying to shift from 1st layer to 2nd.
3. The Algorithmization of Counterfactuals : When we can analyse the counterfactual reasoning using the experimental or observational studies.
4. Mediation Analysis and the Assessment of Direct and Indirect Effects : We find out the direct and indirect effects, such as what fraction of effect does X on Y mediated by variable Z.
5. Adaptability, External Validity and Sample Selection Bias : Basically it deals with the robustness of the model and offers do-calculas for overcoming the bias due to environmental changes.
6. Recovering from Missing Data : The casual inference is made to find out the data-generating principles through probablisitic relationship and therefore promises to fill the missing data.
7. Causal Discovery : The d-separation can ebable us to detect the testable implications of the casual model therefore can prune the set of compatible models significantly to the point where causal queries can be estimated directly from that set.
-
-
On Pearl’s Hierarchy and the Foundations of Causal Inference
-
Maheep's notes
The pearl causal hierarchy encodes different concepts like : association. intervention and counterfactual.
Corollary1 : It is genrally impossible to draw higher-layer inferences using only lower-layer informatio but the authors claim that they have atleast developed a framework to move from layer 1 to layer 2 just from the layer 1 data using Causal Bayesian Network that uses do-calculas, i.e. intervention to get insight of layer 2 using the layer 1 data.
A SCM includes 4 variables, i.e. exongenous "U", endogneous "V", set of functions and P(U).
A structural model is said to be markovian if the variable in the exogenous part are independent.
Observing : Joint porobability distribution for the Y(u) = y
Interventional SCM : SCM computed by fixing some varibales X = x. where X is in V.
Potential Response : It is the solution of Y caluclated thorugh the set of eqautions of SCM when we intervene on it. Intervening : observing just when we do(X = x) Effectiveness : P(v|do(x)) is effectiveness when for every v, P(v|do(x)) = 1
Collapse : The layers collapse when we can compute the results of the upper layer using the lower layer. For ex:- if Layer 2 collapses to layer 1, then it implies that we can draw all possible causal conculsion with mere correlation.
Theorem 1: PCH never collapses.
It could be easily observed/seen that SCM agrees on all lower layers but disagrees on all higher layers. A typical rdata-generating SCM encodes rich information at all threee layers but even very small changes might have substantial effect, which is generally seen in the higher layers.
Truncated Factorization Product is the equation stating P(v|do(x)) = pi P(v|pai)
When two variables are correlated it does not mean that one is causing the other, i.e. P(y|do(x)) = P(y) and P(x|do(y)) =P(x), in this case what happens is there is another unobserved variable that is influencing both x and y variable which is often indicated by the bi-directed line in the graph.
Factorization implied by the semi-markovian model does not act like chain rule, i.e. P(e|a,b,c,d) = P(a)P(b|a)P(c|b,a)P(d|c,b,a) but the factorization looks something like: P(e|d,c,b,a) = P(a)P(b|a)P(c|a)P(e|b.c) which implies that b and c are only affected by a also seen by a direct edge in SCM.
-
-
Unit selection based on counterfactual logic
-
Maheep's notes
The unit selection problem entails two sub-problems, evaluation and search. The evaluation problem is to find an objective function that, ensure a counterfactual behaviour when optimized over the set of observed characteristics C for the selected group. The search task is to devise a search algorithm to select individuals based both on their observed characteristics and the objective function devised above.
The paper only focuses on the evaluation sub-problem and focuses on the previous effort to solve this problem, i.e. A/B testing so as to maximizes the percentage of compliers and minimizes the percentages of defiers, always-takers, and never-takers. But the author argues that the proposed term for it does not satisfy the criteria as P(positive response|c, encouraged) - P(positive response|c, not encouraged) represents "compilers + always-takers" - "defiers + always-takers", therefore the author suggest to have two theorems, i.e. "monotonicity" and "gain equality" which can easily optimize the A/B testing. Monotonicity expresses the assumption that a change from X = false to X = true cannot, under any circumstance make Y change from true to false. Gain-equality states that the benefit of selecting a complier and a defier is the same as the benefit of selecting an always-taker and a never-taker (i.e., β + δ = γ + θ).
Taking into account the following theorems the author proposes a alternate term of A/B testing which stands for maximizing the benefit.
argmax c βP (complier|c) + γP (always-taker|c) + θP (never-taker|c) + δP (defier|c)
where benefit of selecting a complier is β, the benefit of selecting an always-taker is γ, the benefit of selecting a never-taker is θ, and the benefit of selecting a defier is δ. Our objective, then, should be to find c.
Theorem 4 says that if Y is monotonic and satisfies gain equallity then the benefit function may be defined as: -
(β − θ)P (y,x |z) + (γ − β)P (y,x′ |z) + θ
"Third, the proposed approach could be used to evaluate machine learning models as well as to generate labels for machine learning models. The accuracy of such a machine learning model would be higher because it would consider the counterfactual scenarios."
-
-
Unit Selection with Causal Diagram
-
Maheep's notes
Same as above
Additionoal content continues here..........
After proposing the technioques to account for unit selection in general the author proposes a new kind of problem by introducing the confounders in the causal Diagram. The following discovery was partially made by the paper "Causes of Effects: Learning Individual responses from Population Data ". The author proposes a new equation to handle these scenarios.
W + σU ≤ f ≤ W + σL if σ < 0,W + σL ≤ f ≤ W + σU if σ > 0, where "f" is the objective function. Previously in normal case the objective fucntion is bounded by the equation:
max{p 1 , p 2 , p 3 , p 4 } ≤ f ≤ min{p 5 , p 6 , p 7 , p 8 } if σ < 0,
max{p 5 , p 6 , p 7 , p 8 } ≤ f ≤ min{p 1 , p 2 , p 3 , p 4 } if σ > 0,
In the extension of the same the author proposes the new situations which arise such as the when "z" is partially observable. and if "z" is a pure mediator.
The author then discusses about the availablity of the observational and experimantal data. If we only have experimantal data then we can simply remove the observationa terms in the theorem
max{p 1 , p 2 } ≤ f ≤ min{p 3 , p 4 } if σ < 0,
max{p 3 , p 4 } ≤ f ≤ min{p 1 , p 2 } if σ > 0,
but if we have only onservational data then we can take use of the observed back-door and front-door variables to generate the experimental data, but if we have partially observable back-dorr and front-door variables then we can use the equation:
LB ≤ P (y|do(x)) ≤ UB
The last topic which author discusses about is the reduciton of the dimensionality of the variable "z" which satisfies the back-door and front-door variable by substituting the causal graph by substiuting "z" by "W" and "U" which satisfies the condition that "no_of_states_of_W * no_of_states_of_U = no_of_states_of_z".
-
-
The Causal-Neural Connection: Expressiveness, Learnability, and Inference
-
Maheep's notes
The author proposes Neural Causal Models, that are a type of SCM but are capable of amending Gradient Descent. The author propses the network to solve two kinds of problems, i.e. "causal effect identification" and "estimation" simultaneously in a Neural Network as genrative model acting as a proxy for SCM.
"causal estimation" is the process of identifying the effect of different variables "Identification" is obtained when we apply backdoor criterion or any other step to get a better insight. The power of identification has been seen by us as seen in the papers of Hanwang Zhang.
Theorem 1: There exists a NCM that is in sync with the SCM on ladder 3
-
-
The Causal Loss: Driving Correlation to Imply Causation(autonomus)
-
Maheep's notes
The paper introduces a loss function known as causal loss which aims to get the intervening effect of the data and shift the model from rung1 to rung2 of ladder of causation. Also the authors propose a Causal sum Product Network(CaSPN).
Basically the causal loss measures the prob of a variable when intervened on another variable. They extend CaSPN from iSPN be reintroducing the conditional vaaribales, which are obtained when we intervene on the observational data. They argue that the CaSPN are causal losses and also are very expressive.
The author suggests a way(taken from iSPN) consitional variables will be passed with adjacency matrix while weight training and target varibales are applied to the leaf node.
They train the CaSPN, NN with causal loss, standard loss and standard loss + alpha*causal loss and produce the results. Also they train a Decision tree to argue that their technique also works on Non-Differential Networks, therefore they propose to substitute the Gini Index with the Causal Decision Score which measures the average probability of a spit resulting in correct classification.
-
-
Double Machine Learning Density Estimation for Local Treatment Effects with Instruments
-
Maheep's notes
The LTE measures the affect of among compilers under assumptions of monotonicity. The paper focuses on estimating the LTE Density Function(not expected value) using the binary instrumental variable which are used to basically counteract the effect of unobserved confounders.
Instrumental Variables : These are the variables to counteract the affect of inobserved confounders. To be an instrumental varibale these are the following conditions it should consist of:
Relevance: The instrument Z has a causal effect on the treatment X.
Exclusion restriction: The instrument Z affects the outcome Y only through the treatment X.
Exchangeability (or independence): The instrument Z is as good as randomly assigned (i.e., there is no confounding for the effect of Z on Y).
Monotonicity: For all units i, Xi(z1)⩾Xi(x2) when z1⩾z2 (i.e., there are no units that always defy their assignment).
The author develops two methods to approximate the density function, i.e. kernel - smoothing and model-based approximations. For both approaches the author derive double/deboased machine learning estimators.
Kernel Smoothing method: They smoothes the density by convoluting with a smooth kernel function............................
Model-based approximators: It projects the density in the dfinite-dimenional density class basedon a distributional distance measure..........
The author argues that by obtaining the PDF may give very valuable information as compared to only estimating the Cumlative Distribution Function.
-
-
-
Maheep's notes
The paper focuses on shedding the light upon action-guiding explanations or causal explanations by defining three types of explanations i.e.Sufficient Explanations(SE), Counterfactual Explanations(CE) and Actual Causations(AC). These all kinds of explanations are based on intervention on feature to generate explanation. The AC lies between the SE and CE, as it consist of the features when changed do not change the prediction but are sufficient for explanation. The author introduces the concept of Independence, which states that a causal model that agrees with a function that mimics it mapping the input to output by making sure that the Endogenous Variables(V), V = Input U {output}, where every V have only exogenous(U) parents and not any endogenous.
In addition to that the author argues for a very important point, i.e.
successful explanation must show factors that may not be manipulated for the explanation to hold, which is distinct from stating which variables must be held fixed at their actual values.
To give a more detailed view of the terms defined above, the author defines them in a detailed way:
1.) Sufficient Explanations: The author describes the phenomenon when it is explained that forXhaving values asxfixed then theYwill take valueyis known as weak sufficiency, but if only a subset of values inXare set fixed tox, ensureY = yregardless of the values other leftover variables takes, is known as Direct Sufficiency. In addition to that variablesN, that are not to be manipulated for the explanations or in other words safeguarded from intervention andYtakes the valuey, the notion is called Strong Sufficiency. The varibales inNcan be thought of as a network that transmits the Causal Inference onY. The actual sufficient explanation can be thought as the pair of(X = x, N)whereXis strongly sufficient forY = y. The sufficient explanation may dominate other one if the variables in it explains the same and has a subset of the varibles in the other equation.
2.) Counterfactual Explanations: It informs us the variables that needs to be changed fromX = xtoX = x'so as to change the output fromY = ytoY = y', which is divided into two parts: direct counterfactual dependence which deals by the above fact but fixing all the other variables constant and counterfactaul dependence which also holds the above fact but does not intervene on any other variables. The author generalizes these two methods by introducing a new varibaleWthat contains the fixed variables. In the latter caseWremians null but in former case it contains all the varibles excluding the ones intervened upon, where the dominance of one explanation over another takes place as in the SEThe author concludes the paper by defining Actual Causation and concludes that sufficient explanations are of little value for action-guidance, compared to counterfactual aspect. Contrary to CE the AC guides towards actions that would not ensure the actual output under the same conditions as the actual action. The author actual causation naturally accommodates this replacement as well,define fairness by for actual causation occurs along a network
Ndemanding that protected variables do not cause the outcome along an unfair network, i.e., a network that consists entirely of unfair paths.
-
-
Counterfactual Samples Synthesizing and Training for Robust Visual Question Answering
-
Maheep's notes
In this research paper the author focuses on 2 major questions, i.e.
1) Visual-explainable: The model should rely on the right visual regions when making decisions.
2) Question-sensitive: The model should be sensitive to the linguistic variations in questions.
The author proposes a technique, i.e. CSST which consist of CSS and CST which do counterfactual in VQA as the CSS generates the counterfactual samples by masking critical objects in the images and words. The CST model tackles the second challenge of sensitivity is handled by the CST which make the model learn to distinguish between the origianl samples and counterfactal ones. Addtionally it trains the model to learn both kind of samples, i.e. origianl and counterfactual ones, making the model robust.
-
-
How Should Pre-Trained Language Models Be Fine-Tuned Towards Adversarial Robustness?
-
Maheep's notes
The fine-tuning of pre-trained language models has a great success in many NLP fields but it is strikingly vulnerable to adversarial examples, as it suffers severely from catastrophic forgetting: failing to retain the generic and robust linguistic features that have already been captured by the pre-trained model. The proposed model maximizes the mutual information between the output of an objective model and that of the pre-trained model conditioned on the class label. It encourages an objective model to continuously retain useful information from the pre-trained one throughout the whole fine-tuning process.
I(S; Y, T ) = I(S; Y ) + I(S; T|Y ),
The author proposes by this equation that the two models overlap, i.e. the objective model and the pretrained model. S represents the features extracted the model by the objective model and T is the features extracted by the pretrained model.
-
-
Counterfactual Zero-Shot and Open-Set Visual Recognition
-
Maheep's notes
The author proposes a novel counterfactual framework for both Zero-Shot Learning (ZSL) and Open-Set Recognition (OSR), whose common challenge is generalizing to the unseen-classes by only training on the seen-classes. all the unseen-class recognition methods stem from the same grand assumption: attributes (or features) learned from the training seen-classes are transferable to the testing unseen-classes. But this does not happen in practise.
ZSL is usually provided with an auxiliary set of class attributes to describe each seen- and unseen-class whereas the OSR has open environment setting with no information on the unseen-classes [51, 52], and the goal is to build a classifier for seen-classes. Thae author describers previous works in which the generated samples from the class attribute of an unseen-class, do not lie in the sample domain between the ground truth seen and unseen, i.e., they resemble neither the seen nor the unseen. As a result, the seen/unseen boundary learned from the generated unseen and the true seen samples is imbalanced.
The author proposes a technique using counterfactual, i.e. to generate samples using the class attributes, i.e. Y and sample attrubute Z by the counterfactual, i.e. X would be x̃, had Y been y, given the fact that Z = z(X = x) and the consistency rule defines that if the ground truth is Y then x_bar would be x. The proposed genrative causal model P(X|Z, Y ) generate exapmles for ZSL and OSR.
-
-
Counterfactual VQA: A Cause-Effect Look at Language Bias
-
Maheep's notes
Besides, counterfactual training samples generation [12, 1, 58, 19, 31] helps to balance the training data, and outperform other debiasing methods by large margins on VQA-CP.
The statement specifies the reason why the author in the origianl paper mentioned that we can generate missing labels with that process in Machine Leanring. They formulate the language bias as the direct causal effect of questions on answers, and mitigate the bias by subtracting the direct language effect from the total causal effect. They proposed a very simple method to debias the NLP part in VQA using the Causal Inference, i.e. they perform VQA using different layers for different part, i.e. for visual, question and visual+question which is denoted by Knowledge base K. They argue that if we train a model like this then we would have result with Z_q,k,v, then to get the Total Indirect Effect, they train another model with parameters as Z_q,v*k* and are subtracted from each other. to eliminate the biasness of the language model.
-
-
CONTERFACTUAL GENERATIVE ZERO-SHOT SEMANTIC SEGMENTATION
-
Maheep's Notes
The paper proposes a zero-shot semantic segmentation. One of the popular zero-shot semantic segmentation methods is based on the generative model, but no one has set their eyes on the statstical spurious correlation. In this study the author proposes a counterfactual methods to avoid the confounder in the original model. In the spectrum of unsupervised methods, zero-shot learning always tries to get the visual knowledge of unseen classes by learning the mapping from word embedding to visual features. The contribution of the paper accounts as: (1) They proposed a new strategy to reduce the unbalance in zero-shot semantic segmentation. (2) They claim to explain why recent different structures of models can develop the performance of traditional work. (3) They extend the model with their structures and improve its performance.The model will contain a total of 4 variables R, W, F and L. The generator will to generate the fake features using the word embeddings and real features of the seen class and will generate fake images using word embeddings after learning. However, this traditional model cannot capture the pure effect of real features on the label because the real features R not only determine the label L by the link R !L but also indirectly influence the label by path R ! F ! L. This structure, a.k.a. confounder. Therefore they remove the R!F!L and let it be W!F!L, removing the confounding effect of F. Also they use GCN to generate the image or fake features from eord embeeddings using the GCN which alos provides to let the generator learn from similar classes.
-
-
Adversarial Visual Robustness by Causal Intervention
-
Maheep's notes
The paper focuses on adverserial training so as to prevent from adverserial attacks. The author use instrumental variable to achieve casual intervention. The author proposes 2 techniques, i.e.-
Augments the image with multiple retinoptic centres
-
Encourage the model to learn causal features, rather than local confounding patterns.
They propose the model to be such that max P (Y = ŷ|X = x + delta) - P(Y = ŷ|do(X = x + delta)), subject to P (Y = ŷ|do(X = x + delta)) = P (Y = ŷ|do(X = x)), in other words they focus on annhilating the confounders using the retinotopic centres as the instrumental variable.
-
-
-
What If We Could Not See? Counterfactual Analysis for Egocentric Action Anticipation
-
Maheep's notes
Egocentric action anticipation aims at predicting the near future based on past observation in first-person vision. In addition to visual features which capture spatial and temporal representations, semantic labels act as high-level abstraction about what has happened. Since egocentric action anticipation is a vision-based task, they consider that visual representation of past observation has a main causal effect on predicting the future action. In the second stage of CAEAA, we can imagine a counterfactual situation: “what action would be predicted if we had not observed any visual representation?"They ask this question so as to only get the effect of semantic label. As the visual feature is the main feature the semantic label can act as a confouder due to some situations occuring frequently. Therfore the author proposes to get the logits "A" from the pipeline without making any changes to the model and then also getting the logits "B" when they provide a random value to visual feature denoting the question of counterfactual, i.e. “what action would be predicted if we had not observed any visual representation?" getting the unbiased logit by:
Unbiased logit = A - B
-
-
Transporting Causal Mechanisms for Unsupervised Domain Adaptation
-
Maheep's notes
Existing Unsupervised Domain Adaptation (UDA) literature adopts the covariate shift and conditional shift assumptions, which essentially encourage models to learn common features across domains, i.e. in source domain and target domain but as it is unsupervised, the feature will inevitably lose non-discriminative semantics in source domain, which is however discriminative in target domain. This is represented by Covariate Shift: P (X|S = s) != P (X|S = t), where X denotes the samples, e.g., real-world vs. clip-art images; and 2) Conditional Shift: P (Y |X, S = s) != P (Y |X, S = t). In other words covariate dhift defiens that the features or images of both the target and source domain will be different. The conditional shift represents the logit probability from same class images in source and target domain will vary. The author argues that the features discartrded but are important say "U" are confounder to image and features extracterd. Therefore the author discovers k pairs of end-to-end functions {(M i , M i inverse )}^k in unsupervised fashion, where M(Xs) = (Xt) and M i_inverse(Xt) = Xs , (M i , M i 1 ) corresponds to U i intervention. Specifically, training samples are fed into all (M i , M i 1 ) in parallel to compute L iCycleGAN for each pair. Only the winning pair with the smallest loss is updated. This is how they insert images with same content but by adding U in both target and source domain using image generation.
-
-
WHEN CAUSAL INTERVENTION MEETS ADVERSARIAL EXAMPLES AND IMAGE MASKING FOR DEEP NEURAL NETWORKS
-
Maheep's notes
To study the intervention effects on pixel-level features for causal reasoning, the authors introduce pixel-wise masking and adversarial perturbation. The authors argue that the methods such as Gradient information from a penultimate convolutional layer was used in GradCAM are good to provide the saliency map of the image but it is not justifiable inmany situaitons as the Saliency maps onlyCAM establish a correlation for interpretability while it is possible to trace a particular image region that is responsible for it to be correctly classified; it cannot elucidate what would happen if a certain portion of the image was masked out.Effect(xi on xj , Z) = P (xj |do(xi_dash ), Z_Xi) - P (xj |Z_Xi ) ......................................(1) The excepted casual effect has been defined as: E_Xi[Effect(xi on xj , Z)] = (P(Xi = xi |Z)*(equation_1))
The author proposes three losses to get the above equaitons, i.e. the effect of pixels. The losses are interpretability loss, shallow reconstruction loss, and deep reconstruction loss. Shallow reconstruction loss is simply the L 1 norm of the difference between the input and output of autoencoder to represent the activations of the network. For the second equation they applied the deep reconstruction loss in the form of the KL-divergence between the output probability distribution of original and autoencoder-inserted network.
These losses are produced afer perturbtaing the images by maksing the images and inserting adverserial noise.
-
-
Interventional Few-Shot Learning
-
Maheep's notes
In this paper the author argues that in the prevailing Few-Shot Learning (FSL) methods: the pre-trained knowledge of the models is used which is indeed a confounder that limits the performance. They develop three effective IFSL algorithmic implementations based on the backdoor adjustment, the fine-tuning only exploits the D’s knowledge on “what to transfer”, but neglects “how to transfer”. Though stronger pretrained model improves the performance on average, it indeed degrades that of samples in Q dissimilar to S. The deficiency is expected in the meta-learning paradigm, as fine-tune is also used in each meta-train episodeThe author proposes the solution by proposing 4 variables, i.e. "D", "X", "C", "Y" where D is the pretrained model, X is the feature representaiton of the image, C is the low dimesion representation of X and Y are the logits. The author says the D affects both the X and C, also X affects C, X and C affects the logit Y. The autho removes the affect of D on X using backdoor.
-
-
CLEVRER: COLLISION EVENTS FOR VIDEO REPRESENTATION AND REASONING
-
Maheep's notes
The authors propose CoLlision Events for Video REpresentation and Reasoning (CLEVRER) dataset, a diagnostic video dataset for systematic evaluation of computational models on a wide range of reasoning tasks. Motivated by the theory of human causal judgment, CLEVRER includes four types of question: descriptive (e.g., ‘what color’), explanatory (‘what’s responsible for’), predictive (‘what will happen next’), and counterfactual (‘what if’).The dataset is build on CLEVR dataset and has predicitive both predictive and counterfactual questions, i.e. done by, Predictive questions test a model’s capability of predicting possible occurrences of future events after the video ends. Counterfactual questions query the outcome of the video under certain hypothetical conditions (e.g. removing one of the objects). Models need to select the events that would or would not happen under the designated condition. There are at most four options for each question. The numbers of correct and incorrect options are balanced. Both predictive and counterfactual questions require knowledge of object dynamics underlying the videos and the ability to imagine and reason about unobserved events.
The dataset is being prepared by using the pysics simulation engine.
-
-
Towards Robust Classification Model by Counterfactual and Invariant Data Generation
-
Maheep's notes
The paper is about augmentaiton using the counterfactual inference by using the human annotations of the subset of the features responsible (causal) for the labels (e.g. bounding boxes), and modify this causal set to generate a surrogate image that no longer has the same label (i.e. a counterfactual image). Also they alter non-causal features to generate images still recognized as the original labels, which helps to learn a model invariant to these features.They augment using the augmentaions as: None, CF(Grey), CF(Random), CF(Shuffle), CF(Tile), CF(CAGAN) and the augmentaions which alter the invariant features using: F(Random) F(Shuffle) F(Mixed-Rand) F(FGSM)
-
-
Unbiased Scene Graph Generation from Biased Training
-
Maheep's Notes
The paper focuses on scene graph generation (SGG) task based on causal inference. The author use Total Direct Effect for an unbiased SGG. The author proposes the technique, i.e.- To take remove the context bias, the author compares it with the counterfactual scene, where visual features are wiped out(containing no objects).
The author argues that the true label is influenced by Image(whole content of the image) and context(individual objects, the model make a bias that the object is only to sit or stand for and make a bias for it) as confounders, whereas we only need the Content(object pairs) to make the true prediction. The author proposes the TDE = y_e - y_e(x_bar,z_e), the first term denote the logits of the image when there is no intervention, the latter term signifies the logit when content(object pairs) are removed from the image, therfore giving the total effect of content and removing other effect of confounders.
-
-
Counterfactual Visual Explanations
-
Maheep's Notes
The paper focuses on Counterfactual Visual Explanations. The author ask a very signifiant question while developing the technique proposed in the paper, i.e. how I could change such that the system would output a different specified class c'. To do this, the author proposes the defined technique: -- He selects ‘distractor’ image I' that the system predicts as class c' and identify spatial regions in I and I' such that replacing the identified region in I with the identified region in I' would push the system towards classifying I as c'.
The author proposes the implementation by the equation:
f(I*) = (1-a)*f(I) + a*P(f(I'))
where
I*represents the image made using theIandI'*represents the Hamdard product.
f(.)represents the spatial feature extractor
P(f(.))represents a permutation matrix that rearranges the spatial cells off(I')to align with spatial cells off(I)The author implements it using the two greedy sequential relaxations – first, an exhaustive search approach keeping a and P binary and second, a continuous relaxation of a and P that replaces search with an optimization.
-
-
Counterfactual Vision and Language Learning
-
Maheep's Notes
The paper focuses on VQA models using the counterfactual intervention to make it robust. They ask a crucial question, i.e. “what would be the minimum alteration to the question or image that could change the answer”. The author uses the observational data as well as the counterfactual data to predict the answer. To do this, the author proposes the defined technique: -- The author replaces the embedding of the question or image using another question or image so as to predict the correct answer and minimize counterfactual loss.
-
-
Counterfactual Vision-and-Language Navigation via Adversarial Path Sampler
-
Maheep's Notes
The paper focuses on Vision-and-Language Navigation (VLN). The author combine the adversarial training with counterfactual conditions to guide models that might lead to robust model. To do this, the author proposes the defined techniques: -- The author APS, i.e. adversarial path sampler which samples batch of paths P after augmenting them and reconstruct instructions I using Speaker. With the pairs of (P,I), so as to maximize the navigation loss L_NAV.
- The NAV, i.e. navigation model trains so as to minimize the L_Nav making the whole process more robust and increasing the performance.
The APS samples the path based on the visual features v_t which are obtained using the attention on the feature space f_t and history h_t-1 and previous action taken a_t-1 to output the path using the predicted a_t and the features f_t.
-
-
Beyond Trivial Counterfactual Explanations with Diverse Valuable Explanations
-
Maheep's Notes
The paper system DiVE in a world where the works are produced to get features which might change the output of the image and learns a perturbation in a disentangled latent space that is constrained using a diversity-enforcing loss to uncover multiple valuable explanations about the model’s prediction. The author proposes these techniques to get the no-trivial explanations and making the model more diversified, sparse and valid: -- DiVE uses an encoder, a decoder, and a fixed-weight ML model.
- Encoder and Decoder are trained in an unsupervised manner to approximate the data distribution on which the ML model was trained.
- They optimize a set of vectors E_i to perturb the latent representation z generated by the trained encoder.
The author proposes 3 main losses:
Counterfatual loss: It identifies a change of latent attributes that will cause the ML model f to change it’s prediction.Proximity loss: The goal of this loss function is to constrain the reconstruction produced by the decoder to be similar in appearance and attributes as the input, therfore making the model sparse.Diversity loss: This loss prevents the multiple explanations of the model from being identical and reconstructs different images modifing the different spurious correlations and explaing through them. The model uses the beta-TCVAE to obtain a disentangled latent representation which leads to more proximal and sparse explanations and also Fisher information matrix of its latent space to focus its search on the less influential factors of variation of the ML model as it defines the scores of the influential latent factors of Z. This mechanism enables the discovery of spurious correlations learned by the ML model.
-
-
SCOUT: Self-aware Discriminant Counterfactual Explanations
-
Maheep's Notes
The paper proposes to connect attributive explanations, which are based on a single heat map, to counterfactual explanations, which seek to identify regions where it is easy to discriminate between prediction and counter class. They also segments the region which discriminates between the two classes of a class image.The author implements using a network by giving a query image x of class y , a user-chosen counter class y' != y, a predictor h(x), and a confidence predictor s(x), x is then forwarded to get the F_h(x) and F_s(x). From F_h(x) we predict h_y(x) and h_y'(x) which are then combined with the original F_h(x) to produce the A(x, y) and A(x, y') to get the activation tensors and they are then combined with A(x, s(x)) to get the segmented region of the image which is discriminative of the counter class.
-
-
Born Identity Network: Multi-way Counterfactual Map Generation to Explain a Classifier’s Decision
-
Maheep's Notes
The paper proposes a system BIN that is used to produce counterfactual maps as a step towards counterfactual reasoning, which is a process of producing hypothetical realities given observations. The system proposes techniques: -
- The author proposes Counterfactual Map Generator (CMG), which consists of an encoder E , a generator G , and a discriminator D . First, the network design of the encoder E and the generator G is a variation of U-Net with a tiled target label concatenated to the skip connections. This generator design enables the generation to synthesize target conditioned maps such that multi-way counterfactual reasoning is possible.
- The another main technique porposes is the Target Attribution Network(TAN) the objective of the TAN is to guide the generator to produce counterfactual maps that transform an input sample to be classified as a target class. It is a complementary to CMG.
The author proposes 3 main losses:
`Counterfatual Map loss` : The counterfactual map loss limits the values of the counterfactual map to grow as done by proximity loss in DiVE.
`Adverserial loss` : It is an objective function reatained due to its stability during adversarial training.
`Cycle Consistency loss` : The cycle consistency loss is used for producing better multi-way counterfactual maps. However, since the discriminator only classifies the real or fake samples, it does not have the ability to guide the generator to produce multi-way counterfactual maps. - The author proposes Counterfactual Map Generator (CMG), which consists of an encoder E , a generator G , and a discriminator D . First, the network design of the encoder E and the generator G is a variation of U-Net with a tiled target label concatenated to the skip connections. This generator design enables the generation to synthesize target conditioned maps such that multi-way counterfactual reasoning is possible.
-
-
Introspective Distillation for Robust Question Answering
-
Maheep's Notes
The paper focuses on the fact that the present day systems to make more genralized on OOD(out-of-distribution) they sacrifice their performance on the ID(in-distribution) data. To achieve a better performance in real-world the system need to have accuracy on both the distributions to be good. Keeping this in mind the author proposes: -- The author proposes to have a causal feature to teach the model both about the OOD and ID data points and take into account the
P_OODandP_ID, i.e. the predictions of ID and OOD. - Based on the above predictions the it can be easily introspected that which one of the distributions is the model exploiting more and based on it they produce the second barnch of the model that scores for
S_IDandS_OODthat are based on the equationS_ID = 1/XE(P_GT, P_ID), whereXEis the cross entropy loss. further these scores are used to compute weightsW_IDandW_OOD, i.e.W_OOD = S_OOD/(S_OOD + S_ID)to train the model to blend the knowledge from both the OOD and ID data points. - The model is then distilled using the knowledge distillation manner, i.e.
L = KL(P_T, P_S), whereP_Tis the prediction of the teacher model and theP_Sis the prediction of the student model.
- The author proposes to have a causal feature to teach the model both about the OOD and ID data points and take into account the
-
-
Counterfactual Explanation and Causal Inference In Service of Robustness in Robot Control
-
Maheep's Notes
The paper focuses on the generating the features using counterfactual mechanism so as to make the model robust. The author proposes to generate the features which are minimal and realistic in an image so as to make it as close as the training image to make the model work correctly making the model robust to adverserial attacks, therfore robust. The generator has two main components, a discriminator which forces the generator to generate the features that are similar to the output class and the modification has to be as small as possible.
The additonal component in the model is the predictor takes the modified image and produces real-world output. The implementation of it in mathematics looks like:
min d_g(x, x') + d_c(C(x'), t_c), where d_g is the distance b/w the modified and original image, d_c is the distance b/w the class space and C is the predictor that x' belongs to t_c class.
The loss defines as:total_loss = (1-alpha)*L_g(x, x') + (alpha)*L_c(x, t_c), where L_c is the lossxbelongs tot_cclass
-
-
Counterfactual Explanation Based on Gradual Construction for Deep Networks
-
Maheep's Notes
The paper focuses on gradually construct an explanation by iterating over masking and composition steps, where the masking step aims to select the important feature from the input data to be classified as target label. The compostition step aims to optimize the previously selected features by perturbating them so as to prodice the target class.
The proposed also focuses on 2 things, i.e. Explainability and Minimality. while implementing the techniue the authors observe the target class which were being generated were getting much perturbated so as to come under asverserial attack and therfore they propose the logit space of x' to belong to the space of training data as follows:
argmin(sigma(f_k'(x') - (1/N)*sigma(f_k'(X_i,c_t))) + lambda(X' - X))
wheref'gives the logits for class k,X_i,c_trepresents the i-th training data that is classified into c_k class and the N is the number of modifications.
-
-
CoCoX: Generating Conceptual and Counterfactual Explanations via Fault-Lines
-
Maheep's Notes
The paper focuses a model for explaining decisions made by a deep convolutional neural network (CNN) fault-lines that defines the main features from which the humans deifferentiate the two similar classes. The author introduces 2 concepts: PFT and NFT, PFT are those xoncepts to be added to input image to change model prediction and for NFT it subtracts, whereas the xconcepts are those semantic features that are main features extracted by CNN and from which fault-lines are made by selecting from them.
The proposed model is implemented by taking the CNN captured richer semantic aspect and construct xconcepts by making use of feature maps from the last convolution layer. Every feature map is treated as an instance of an xconcept and obtain its localization map using the Grad-CAM and are spatially pooled to get important weights, based on that top p pixels are selected and are clustered using K-means. The selection is done using the TCAV tecnique.

-
-
-
Maheep's Notes
The paper is kind of an extension of the above paper(CoCoX), i.e. it also uses fault-lines for explainability but states a dialogue between a user and the machine. The model is made by using the fault-lines and the Theory of Mind(ToM).
The proposed is implemented by taking an image and the same image is blurred and given to a person, then the machine take out the crucial features by thinking what the person may have understood and what is the information it should provide. The person is given more images and then the missing parts are told to be predicted after the dialogue, if the person is able to predict the parts that it was missing before then the machine gets a positive reward and functions in a RL training technique way.
-
-
DeDUCE: Generating Counterfactual Explanations At Scale
-
Maheep's Notes
The paper focues to detect the erroneous behaviour of the models using counterfatctual as when an image classifier outputs a wrong class label, it can be helpful to see what changes in the image would lead to a correct classification. In these cases the counterfactual acrs as the closest alternative that changes the prediction and we also learn about the decision boundary.
The proposed model is implemented by identifying the Epistemic uncertainity, i.e. the useful features using the Gaussian Mixture Model and therfore only the target class density is increased. The next step would be to change the prediction using a subtle change therefore the most slaient pixel, identified usign the gradient are changed.
-
-
Designing Counterfactual Generators using Deep Model Inversion
-
Maheep Notes
The paper focues on the scenario when the we have access only to the trained deep classifier and not the actual training data. The paper proposes a goal to develop a deep inversion approach to generate counterfactual explanations. The paper propses methods to preserve metrics for semantic preservation using the different methods such as ISO and LSO. The author also focuses on manifold consistency for the counterfactual image using the Deep Image Prior model. -argmin(lambda_1*sigma_on_l(layer_l(x'), layer_l(x)) + lambda_2*L_mc(x';F) + lambda_3*L_cf(F(x'), y'))
where,
layer_l:The differentiable layer "l" of the neural network, it is basically used for semantic preservation.
L_mc: It penlaizes x' whcih do not lie near the manifold. L_mc can be Deterministic Uncertainty Quantification (DUQ).
L_fc: It ensures that the prediction for the counterfactual matches the desired target
-
-
ECINN: Efficient Counterfactuals from Invertible Neural Networks
-
Maheep's Notes
The paper utilizes the generative capacities of invertible neural networks for image classification to generate counterfactual examples efficiently. The main advantage of this network is that it is fast and invertible, i.e. it has full information preservation between input and output layers, where the other networks are surjective in nature, therfore also making the evaluation easy. The network claims to change only class-dependent features while ignoring the class-independence features succesfully. This happens as the INNs have the property that thier latent spaces are semantically organized. When many latent representations of samples from the same class are averaged, then class-independent information like background and object orientation will cancel out and leaves just class-dependent information
x' = f_inv(f(x) + alpha*delta_x)
where,
x':Counterfactual image.
f: INN and therforef_invis the inverse off.
delta_x: the infoprmation to be added to convert the latent space of image to that of counterfactual image.
||z + alpha_0*delta_x- µ_p || = ||z + alpha_0*delta_x - µ_q ||where the z + alpha_0*delta_x is the line separating the two classes and µ_q and µ_q are the mean distance from line. Therefore
alpha = alpha_0 + 4/5*(1-alpha_0)
-
-
EXPLAINABLE IMAGE CLASSIFICATION WITH EVIDENCE COUNTERFACTUAL
-
Maheep's Notes
The author proposes a SDEC model that searches a small set of segments that, in case of removal, alters the classification
The image is segemented with l segments and then the technique is implemented by using the best-first search avoid a complete search through all possible segment combinations. The best-first is each time selected based on the highest reduction in predicted class score. It continues until one or more same-sized explanations are found after an expansion loop. An additional local search can be performed by considering all possible subsets of the obtained explanation. If a subset leads to a class change after removal, the smallest set is taken as final explanation. When different subsets of equal size lead to a class change, the one with the highest reduction in predicted class score can be selected.
-
-
Explaining Visual Models by Causal Attribution
-
Maheep Notes
The paper focuses on the facts that there are limitations of current Conditional Image Generators for Counterfactual Generation and also proposes a new explanation technique for visual models based on latent factors.
The paper is implemented using the Distribution Causal Graph(DCG) where the causal graph is made but the nodes is represented the MLP, i.e. `logP(X = (x1,x2,x3...xn)) = sigma(log(P(X = xi|theta_i)))` and the Counterfactual Image Generator which translate the latent factor into the image using the original image as anchor while genrating it which is done using Fader Networks which adds a critic in the latent space and AttGAN adds the critic in the actual output.
-
-
Explaining the Black-box Smoothly-A Counterfactual Approach
-
Maheep's Notes
The paper focuses on explaining the outcome of medical imaging by gradually exaggerating the semantic effect of the given outcome label and also show a counterfactual image by introducing the perturbations to the query image that gradually changes the posterior probability from its original class to its negation. The explanation therfore consist of 3 properties:
1.) **Data Consistency**: The resembalance of the generated and orignal data should be same. Therefore cGAN id introduced with a loss asL_cgan = log(P_data(x)/q(x)) + log(P_data(c|x)/q(c|x))where P_data(x) is the data distribtion and learned distribution q(x), whreas P_data(c|x)/q(c|x) = r(c|x) is the ratio of the generated image and the condition.
2.) Classification model consistency: The generated image should give desired output. Therefore the condition-aware loss is introduced, i.e.L := r(c|x) + D_KL (f(x')||f (x) + delta),, where f(x') is the output of classifier of the counterfactual image is varied only by delta amount when added to original image logit. They take delta as a knob to regularize the genration of counterfactual image.
3.) Context-aware self-consistency: To be self-consistent, the explanation function should satisfy three criteria(a) Reconstructing the input image by setting = 0 should return the input image, i.e., G(x, 0) = x.
(b) Applying a reverse perturbation on the explanation image x should recover x.To mitigate this conditions the author propose an identity loss. The author argues that there is a chance that the GAN may ignore small or uncommon details therfore the images are compared using semantic segemntation with object detection combined in identity loss. The identity loss is : L_identity = L_rec(x, G(x, 0))+ L_rec(x, G(G(x,delta), -delta))
-
-
Explaining the Behavior of Black-Box Prediction Algorithms with Causal Learning
-
Maheep's Notes
The paper using proposes causal graphical models so as to indicate which of the interpretable features, if any, are possible causes of the prediction outcome and which may be merely associated with prediction outcomes due to confounding. The choose causal graphs consistent with observed data by directly testing focus on type-level explanation rather token-level explanations of particular events. The token-level refers to links between particular events, and the type-level refers to links between kinds of events, or equivalently, variables. Using the causal modelling they focus on obtaining a model that is consistent with the data.
They focus on learning a Partial Ancestral Graph(PAG) G, using the FCI algorithm and the predicted outcome Y' whereas Z are the high-level which are human interpretable and not like pixels.
V = (Z,Y')
Y' = g(z1,.....zs, epsilon)On the basis of possible edge types, they find out which high level causes, possible causes or non-causes of the balck-box output Y'.
-
-
Explaining Classifiers with Causal Concept Effect (CaCE)
-
Maheep's Notes
The paper proposes a system CaCE, which focuses on confounding of concepts, i.e higher level unit than low level, individual input features such as pixels by intervening on concepts by taking an important assumption that intervention happens atomically. The effect is taken asEffect = E(F(I)|do(C = 1)) - E(F(I)|do(C = 0))where F gives output on image I and C is the concept. This can be done at scale by intervening for a lot of values in a concept and find the spurious corrlation. But due to the insufficient knowlegde of the Causal Graph teh author porposes a VAE which can calculate the precise CaCE by by generating counterfactual image by just changing a concept and hence computing the difference between the prediction score.
-
-
Fast Real-time Counterfactual Explanations
-
Maheep's Notes
The paper proposes a transformer is trained as a residual generator conditional on a classifier constrained under a proposal perturbation loss which maintains the content information of the query image, but just the class-specific semantic information is changed. The technique is implemented as :
1.) Adverserial loss: It measures whether the generated image is indistinguishable from the real world images
2.) Domain classification loss: It is used to render the generate image x + G(x,y') conditional on y'.L = E[-log(D(y'|x + G(x,y')))]where G(x, y') is the perterbuation introduced by generator to convert image from x to x'
3.) Reconstruction loss: The Loss focuses to have generator work propoerly so as to produce the image need to be produced as defined by the loss.L = E[x - (x + G(x,y') + G(x + G(x,y'), y))]4.) Explanation loss: This is to gurantee that the generated fake image produced belongs to the distribution of H.L = E[-logH(y'|x + G(x,y'))]
5.) Perturbation loss: To have the perturbation as small as possible it is introduced.L = E[G(x,y') + G(x + G(x,y'),y)]
All these 5 losses are added to make the final loss with different weights.
-
-
GENERATIVE_COUNTERFACTUAL_INTROSPECTION_FOR_EXPLAINABLE_DEEP_LEARNING
-
Maheep's Notes
The paper propose to generate counterfactual using the Generative Counterfactual Explanation not by replacing a patch of the original image with something but by generating a counterfactual image by replacing minimal attributes uinchanged, i.e. A = {a1, a2, a3, a4, a5....an}. It is implemented by: -
min(lambda*loss(I(A')) + ||I - I(A')), where loss is cross-entropy for predicting image I(A') to label c'.
-
-
Generative_Counterfactuals_for_Neural_Networks_via_Attribute_Informed_Perturbations
-
Maheep's Notes
The paper focues on generating counterfactuals for raw data instances (i.e., text and image) is still in the early stage due to its challenges on high data dimensionality, unsemantic raw features and also in scenario when the effictive counterfactual for certain label are not guranteed, therfore the author proposes Attribute-Informed-Perturbation(AIP) which convert raw features are embedded as low-dimension and data attributes are modeled as joint latent features. To make this process optimized it has two losses: Reconstruction_loss(used to guarantee the quality of the raw feature) + Discrimination loss,(ensure the correct the attribute embedding) i.e.min(E[sigma_for_diff_attributes*(-a*log(D(x')) - (1-a)*(1-D(x)))]) + E[||x - x'||]where D(x') generates attributes for counterfactual image.
To generate the counterfactual 2 losses are produced,one ensures that the perturbed image has the desired label and the second one ensures that the perturbation is minimal as possible, i.e.
L_gen = Cross_entropy(F(G(z, a)), y) + alpha*L(z,a,z_0, a_0)
The L(z,a,z0,a0) is the l2 norm b/w the attribute and the latent space.
-
-
Question-Conditioned Counterfactual Image Generation for VQA
-
Maheep's Notes
The paper on generating the counterfactual images for VQA, s.t.
i.) the VQA model outputs a different answer
ii.) the new image is minimally different from the original
iii) the new image is realistic
The author uses a LingUNet model for this and proposes three losses to make the perfect.
1.) Negated cross entropy for VQA model.
2.) l2 loss b/w the generated image and the original image. 3.) Discriminator that penalizes unrealistic images.
-
-
FINDING AND FIXING SPURIOUS PATTERNS WITH EXPLANATIONS
-
Maheep's Notes
The paper proposes an augmeting technique taht resamples the images in such a way to remove the spurious pattern in them, therfore they introduce their framework Spurious Pattern Identification and REpair(SPIRE). They view the dataset as Both, Just Main, Just Spurious, and Neither. SPIRE measures this probability for all (Main, Spurious) pairs, where Main and Spurious are different, and then sorts this list to find the pairs that represent the strongest patterns. After finding the pattern the dataset is redistributes as:
P(Spurious | Main) = P(Spurious | not Main) = 0.5
The second step consist of minimizing the potential for new SPs by setting theP(Main|Artifact) = 0.5).
SPIRE moves images from {Both, Neither} to {Just Main, Just Spurious} if p > 0.5, i.e. p = P(Main|Spurious) but if p < 0.5 then SPIRE moves images from {Just Main, Just Spurious} to {Both, Neither}.
-
-
Contrastive_Counterfactual_Visual_Explanations_With_Overdetermination
-
Maheep's Notes
The paper proposes a system CLEAR Image that explains an image’s classification probability by contrasting the image with a corresponding image generated automatically via adversarial learning. It also provides an event with a label of "*overdetermination*", which is given when the model is more than sure that the label is something. CLEAR Image segments x into different segments S = {s1 ,...,sn } and then applies the same segmentation to x' creating S' = {s'1,...., s'n}. CLEAR Image determines the contributions that different subsets of S make to y by substituting with the corresponding segments of S'. This is impelmeted by:
A counterfactual image is generated by GAN which is then segmented and those segments by a certian threshold replace the segment in the original image and therfore we get many perturbed images. Each perturbed image is then passed through the model m to identify the classification probability of all the classes and therfore the significance of every segment is obtained that is contributing in the layer. If the
-
-
Training_calibration‐based_counterfactual_explainers_for_deep_learning
-
Maheep's Notes
The paper proposes TraCE for deep medical imaging that trained using callibaration-technique to handle the problem of counterfactual explanation, particularly when the model's prediciton are not well-callibrated due to which it produces irrelevant feature manipulation. The system is implemeted using the 3 methods, i.e.
(1.) an auto-encoding convolutional neural network to construct a low-dimensional, continuous latent space for the training data
(2.) a predictive model that takes as input the latent representations and outputs the desired target attribute along with its prediction uncertainty
(3.) a counterfactual optimization strategy that uses an uncertainty-based calibration objective to reliably elucidate the intricate relationships between image signatures and the target attribute.
TraCE works on the following metrics to evaluate the counterfactual images, i.e.
Validity: ratio of the counterfactuals that actually have the desired target attribute to the total number of counterfactuals
The confidence of the image and sparsity, i.e. ratio of number of pixels altered to total no of pixels. Th eother 2 metrcs are proximity, i.e. average l2 distance of each counterfactual to the K-nearest training samples in the latent space and Realism score so as to have the generated image is close to the true data manifold.
TraCE reveals attribute relationships by generating counterfactual image using the different attribute like age "A" and diagnosis predictor "D".
delta_A_x = x - x_a';delta_D_x = x - x_d'
The x_a' is the counterfactual image on the basis for age and same for x_d'.
x' = x + delta_A_x + delta_D_xand hence atlast we evaluate the sensitivity of a feature byF_d(x') - F_d(x_d'), i.e. F_d is the classifier of diagnosis.
-
-
Generating Natural Counterfactual Visual Explanations
-
Maheep's Notes
The paper proposes a counterfactual visual explainer that look for counterfactual features belonging to class B that do not exist in class A. They use each counterfactual feature to replace the corresponding class A feature and output a counterfactual text. The counterfactual text contains the B-type features of one part and the A-type features of the remaining parts. Then they use a text-to-image GAN model and the counterfactual text to generate a counterfactual image. They generate the images using the AttGAN and StackGAN and they take the image using the function.
`log(P(B)/P(A))` where P(.) is the classifier probability of a class for obtaining the highest-scoring counterfactual image.
-
-
On Causally Disentangled Representations
-
Maheep's Notes
The paper focuses on causal disentanglement that focus on disentangle factors of variation and therefore proposes two new metrics to study causal disentanglement and one dataset named CANDLE. Generative factors G is said to be disentangled only if they are influenced by their parents and not confounders. The system is implemented as:
A latent model M (e,g, pX ) with an encoder e, generator g and a data distribution pX , assumes a prior p(Z) on the latent space, and a generator g is parametrized as p(X|Z), then posterior p(Z|X) is approzimated using a variational distribution q (Z|X) parametrized by another deep neural network, called the encoder e. Therefore we obtain a z for every g and acts as a proxy for it.
1.) **Unconfoundess metric**: If a model is able to map each Gi to a unique ZI ,the learned latent space Z is unconfounded and hence the property is known as unconfoundedness.
2.)**Counterfactual Generativeness**: a counterfactual instance of x w.r.t. generative factor Gi , x'(i.e., the counterfactual of x with change in only Gi) can be generated by intervening on the latents of x corresponding to Gi , ZIx and any change in the latent dimensions of Z that are x not responsible for generating G i , i.e. Z\I, should have no influence on the generated counterfactual instance x' w.r.t. generative factor Gi. It can be computed using the Avergae Causal Effect(ACE).
-
-
INTERPRETABILITY_THROUGH_INVERTIBILITY_A_DEEP_CONVOLUTIONAL_NETWORK
-
Maheep's Notes
The paper proposes a model that generates meaningful, faithful, and ideal counterfactuals. Using PCA on the classifier’s input, we can also create “isofactuals”, i.e. image interpolations with the same outcome but visually meaningful different features. The author argues that a system should provide power to the users to discover hypotheses in the input space themselves with faithful counterfactuals that are ideal. They claim that it could be easily done by combining an invertible deep neural network z = phi(x) with a linear classifier y = wT*phi(x) + b. They generate a counterfatual by altering a feature representation of x along the direction of weight vector, i.e.
z' = z + alpha*wwherex' = phi_inverse(z + alpha*w). Any change orthogonal to w will create an “isofactual. To show that their counterfactuals are ideal, therfore they verify that no property unrelated to the prediction is changed. Unrealted properties = e(x),e(x) = vT*z, where v is orthogonal to w.e(x') = vT*(z + alpha* w) = vT*z = e(x). To measure the difference between the counterfactual and image intermediate feature map h, i.e.m = |delta_h|*cos(angle(delta_h, h))for every location of intermediate feature map.
-
-
Model-Based Counterfactual Synthesizer for Interpretation
-
Maheep's Notes
The paper focues on eridicating the algorithm-based counterfactual generators which makes them ineffcient for sample generation, because each new query necessitates solving one specific optimization problem at one time and propose Model-based Counterfactual Synthesizer. Existing frameworks mostly assume the same counterfactual universe for different queries. The present methods do not consider the causal dependence among attributes to account for counterfactual feasibility. To take into account the counterfactual universe for rare queries, they novelly employ the umbrella sampling technique, i.e. by using the weighted-sum technique, calculating the weight of each biased distribution, we can then reconstruct the original distribution and conduct evaluations with the umbrella samples obtained. The counterfactual can be generated by giving a specific query q0, insttead of a label using the hypthetical distribution.
-
-
The Intriguing Relation Between Counterfactual Explanations and Adversarial Examples
-
Maheep's Notes
The paper provides the literature regarding the difference between the Counterfactual and Adverserial Example. Some of the points are:
1.) AEs are used to fool the classifier whereas the CRs are used to generate constructive explantions.
2.) AEs show where an ML model fails whereas the Explanations sheds light on how ML algorithms can be improved to make them more robust against AEs
3.) CEs mainly low-dimensional and semantically meaningful features are used, AEs are mostly considered for high-dimensional image data with little semantic meaning of individual features.
4.) Adversarials must be necessarily misclassified while counterfactuals are agnostic in that respect
5.) Closeness to the original input is usually a benefit for adversarials to make them less perceptible whereas counterfactuals focus on closeness to the original input as it plays a significant role for the causal interpretation
-
-
Discriminative Attribution from Counterfactuals
-
Maheep's Notes
The paper proposes a novel technique to combine feature attribution with counterfactual explanations to generate attribution maps that highlight the most discriminative features between pairs of classes. This is implemented as:
They use a cycle-GAN to translate real images x of class i to counterfactual images x'. Then both the images are fed into the Discriminative Attribution model which finds out the most discriminative features separting the 2 image. The most important part is masked out. The part is extracted from the original image x and is combined with the counterfactual image by intiallly masking the region to get the original image.
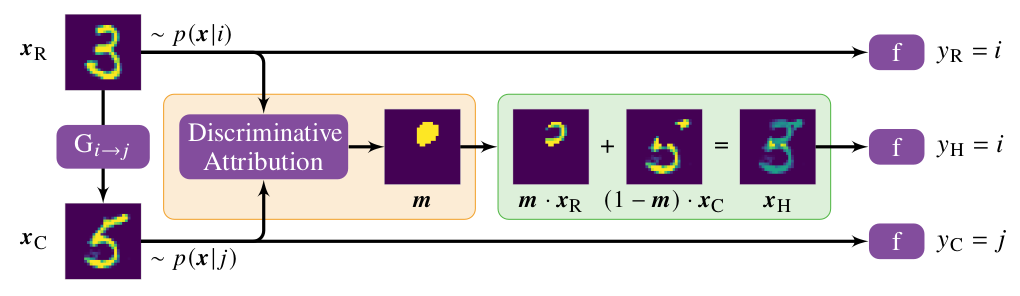
-
-
Causal Interventional Training for Image Recognition
-
Maheep's Notes
The paper focuses on proposing an augmentaiton technique which focuses on eradicating the bias that is bad and keeping the bias that is good for the model. Therefore the author proposes a causal graph consisting of x:image; y:label; C:context; A:good bias and B:bad bias. The author considers B as the confounding variable b/w the x and C, therefore tries to remove it using the backdoor criteria.
-






-
Improving_Weakly_supervised_Object_Localization_via_Causal_Intervention
-
Maheep's Notes
The paper proposes CI-CAM which explores the causalities among image features, contexts, and categories to eliminate the biased object-context entanglement in the class activation maps thus improving the accuracy of object localization. The author argues that in WSCOL context acts as a confounder and therefore eliminates it using backdoor-adjustment. The implement it by the following procedure: -
The architecture contains a backbone network to extract the features. The extracted features are then processed into CAM module where a GAP and classifier module outputs scores which are multipluied by weights to produce class activation maps.
The features are then passed through Causal Context Pool which stores the context of all images of every class, then other CAM module repeats the same procudure as of CAM1 and outputs image with class activation map.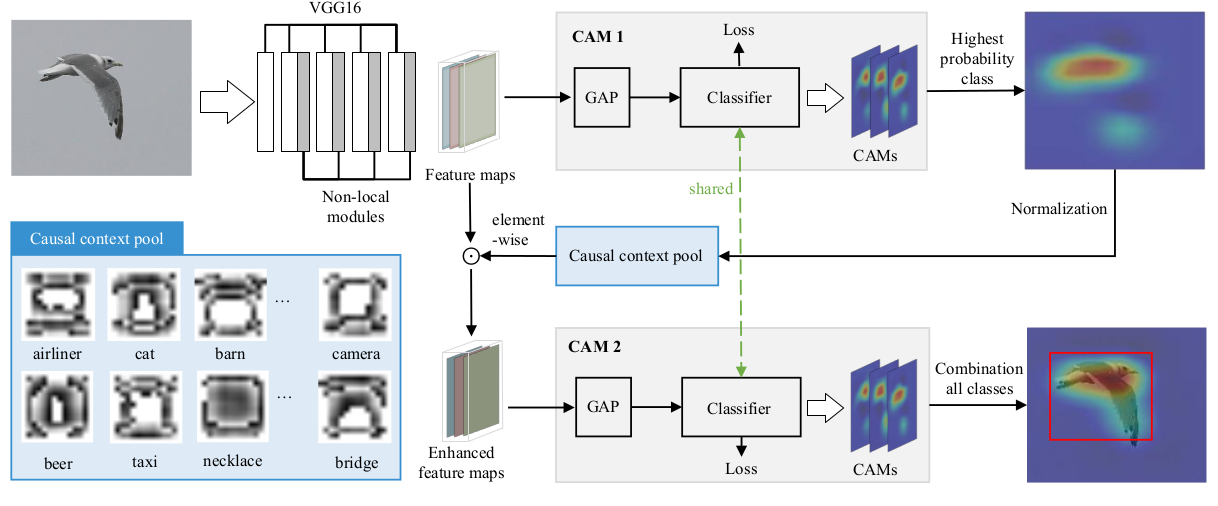
-
-
COUNTERFACTUAL GENERATIVE NETWORKS
-
Maheep's Notes
The paper aims to propose a method so as to train the model having robustness on OOD data. To achieve this the author uses the concept of causilty, i.e. *independent mechanism(IM)* to generate counterfactual images. The author considers 3 IM's:
1.) One generates the object’s shape.
2.) The second generates the object’s texture.
3.) The third generates the background.
In this way the author makes a connection b/w the fields of causality, disentangled representaion, and invariant classifiers. The author uses cGAN with these learned IM to generate images based on the attributes given above.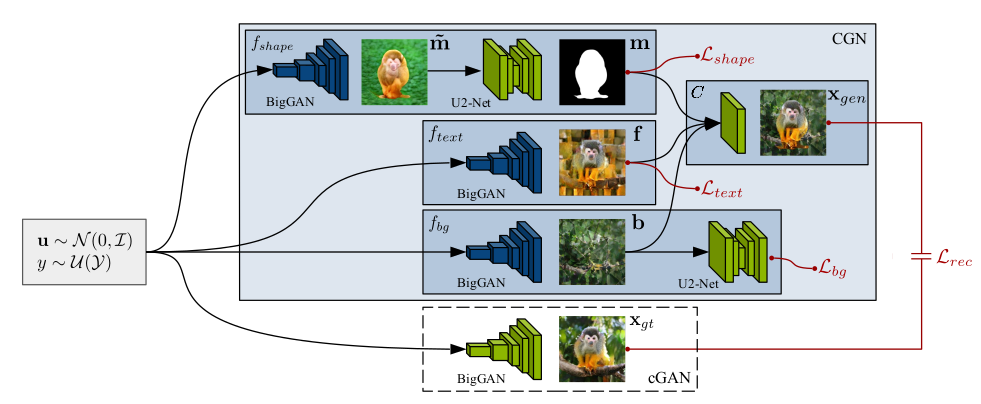
-
-
Discovering Causal Signals in Images
-
Maheep's Notes
A classifier is proposed that focuses on finding the causal direction between pairs of random variables, given samples from their joint distribution. Additionally they use causal direction classifier to effectively distinguish between features of objects and features of their contexts in collections of static images. In this framework, causal relations are established when objects exercise some of their causal dispositions, which are sometimes informally called the powers of objects. Based on it the author provides two hypothesis:
1.) Image datasets carry an observable statistical signal revealing the asymmetric relationship between object categories that results from their causal dispositions.
2.) There exists an observable statistical dependence between object features and anticausal features, basically anticausal features are those which is caused by the presence of an object in the scene. The statistical dependence between context features and causal features is nonexistent or much weaker.
The author proposes a Neural Causation Coefficient (NCC), able to learn causation from a corpus of labeled data. The author argues that the for joint distributions that occur in the real world, the different causal interpretations may not be equally likely. That is, the causal direction between typical variables of interest may leave a detectable signature in their joint distribution. Additionally they assume that wheneverX causes Y, the cause, noise and mechanism are independent but we can identify the footprints of causality when we try toY causes Xas the noise and Y will not be independent.
-
-
Learning to Contrast the Counterfactual Samples for Robust Visual Question Answering
-
Maheep's Notes
The paper proposes we introduce a novel self-supervised contrastive learning mechanism to learn the relationship between original samples, factual samples and counterfactual samples. They implement it by generating facutal and counterfactual image and try to increase the mutual information between the joint embedding ofQandV(mm(Q,V) = a), and joint embedding ofQandV_+ (factual)(mm(Q,V+) = p)by taking a cosine similarity b/w them. They also aim to decrease mutual information b/wmm(Q,V-) = nandaby taking cosine similarity(s(a,n)). The final formula becomes:
L_c = E[-log(e^s(a,p)/e^s(a,p)+e^s(a,n))]
The total loss becomesL = lambda_1*L_c + lambda_2*L_vqa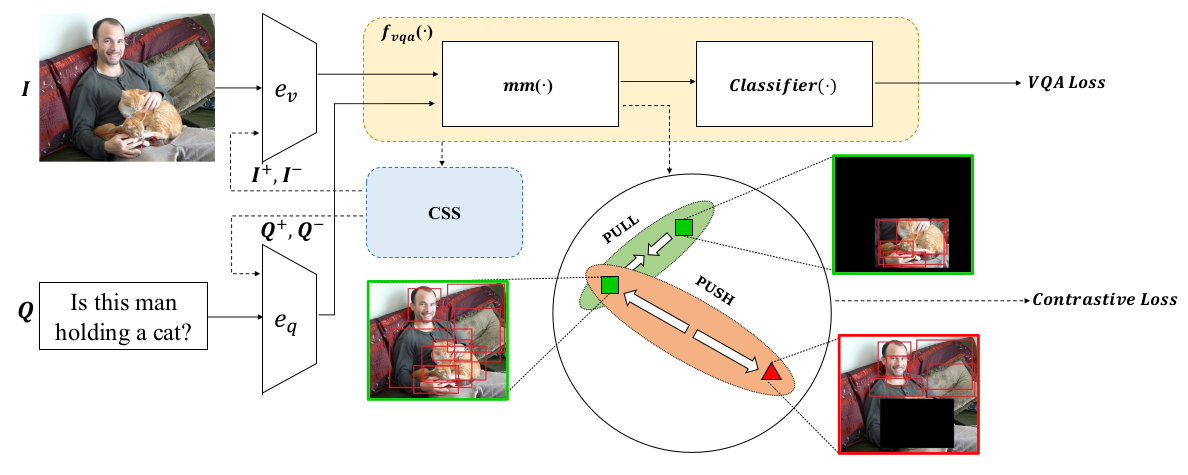
-
-
-
Maheep's Notes
The paper focus on issue of generalization and therefore propose Latent Causal Invariance Model(LaCIM). The author introduce variables that are separated into (a) output-causative factors, i.e.Sand (b) others that are spuriously correlatedZfrom V(latent variable).
There exists a spurious correlation b/wSandZ. The author argues that we will get ap(y|do(s*)) = p(y|s*)
-
-
Two Causal Principles for Improving Visual Dialog
-
Maheep's Notes
The paper focuses to eliminate the spurious correltaions in the task of Visual Dialogue and therfore proposes 2 principles:
1.) The dialog history to the answer model provides a harmful shortcut bias threfore the direct effect of history on answer should be eliminated.
2.) There is an unobserved confounder for history, question, and answer, leading to spurious correlations from training data which should be identified and be eliminated using the backdoor method.
Now the main crunch of the paper arises as the confounder is unobserved so how can we apply the backdoor method? To solve it the author argues that this confounder comes from the annotator and thus can be seen in thea_i(answer) is a sentence observed from the “mind” of user u during dataset collection. Then,sigma(P(A)*P(u|H)),His history andAis answer can be approximated assigma(P(A)P(a_i|H)).They further usep(a_i|QT), whereQTis Question Type to approximateP(a_i|H)because of two reasons: First,P (a_i|H)essentially describes a prior knowledge abouta_iwithout comprehending the whole{Q, H, I} triplet.
-
-
Weakly-Supervised Video Object Grounding via Causal Intervention
-
Maheep's Notes
The paper aims to localize objects described in the sentence to visual regions in the video by deconfounding the object-relevant associations given the video-sentence annotations. The author argues that the frame is made up of the content(C), i.e. factors that cause the object’s visual appearances in spatial and temporal throughout the video are grouped into a category and Style(S) is the background or scenes. The author argues that the S does not play any role in object grounding and only act a confounder. In addition to that there exist one more confounder, i.e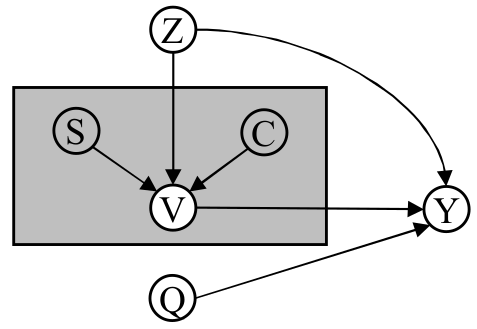
Zthat occurs due to some specific objects occuring frequently. The style confounder is replaced by using the contrastive learning, where the counterfactual examples are created by taking the vectors from a memory bank by taking the top sleected top regions for described object and then the selected regions and frames are grouped together into frame-level content(H_c) and region-level content(U_c), and the rest of the regions are grouped as U_s and H_s. These regions are the converted to counterfactual using these memory vectors which were created by taking the randomly selected regions in training set. The most similar one and replaces the original one, to generate examples to have them hard to distinguish from real ones contrastive learning is used. The equation looks like:IE(p|do(U_s = U_s_generated)) < IE(p|do(U_c = U_c_generated))
IE(p|do(H_s = H_s_generated)) < IE(p|do(H_c = H_c_generated))
where theIEis Interventional Effect. As for the next confounder they uses the textual embedding of o_k(object) essentially provides the stable cluster center in common embedding space for its vague and diverse visual region embeddings in different videos. Therefore, by taking the textual embedding of the object as the substitute of every possible object z and apply backdoor adjustment.
-
-
Towards Unbiased Visual Emotion Recognition via Causal Intervention
-
Maheep's Notes
The paper we propose a novel Interventional Emotion Recognition Network (IERN) to achieve the backdoor adjustment on the confounder, i.e. context of the image(C). The author implements it as:
IERN, which is composed of four parts:
1.) Backbone
> It extracts the feature embedding of the image.
2.) Feature Disentanglement
> It disentangles the emotions and context from the image, having emotion dicriminator(d_e) and context discriminator(d_c) which ensures that the extracted feature are separated and has the desired feature. The loss comprises as :
L = CE(d_e(g_e(f_b(x))), y_e) + MSE(d_c(g_e(f_b(x))), 1/n)where g_e is emotion generator and y_e is the emotion label and n is the number of counfounder and the same loss is for context replacing d_e, g_e and d_c by d_c, g_c and d_e, here n represents number of emotions. To ensure that the separated features fall within reason-able domains, IERN should be capable of reconstructing the base feature f_b(x), i.e.L =MSE(g_r(g_e(f_b(x)), g_c(f_b(x))), f_b(x))
3.) Confounder Builder
> The purpose of the confounder builder is to combine each emotion feature with different context features so as to avoid the bias towards the observed context strata.
4.) Classifier
> It is simply used for prediciton.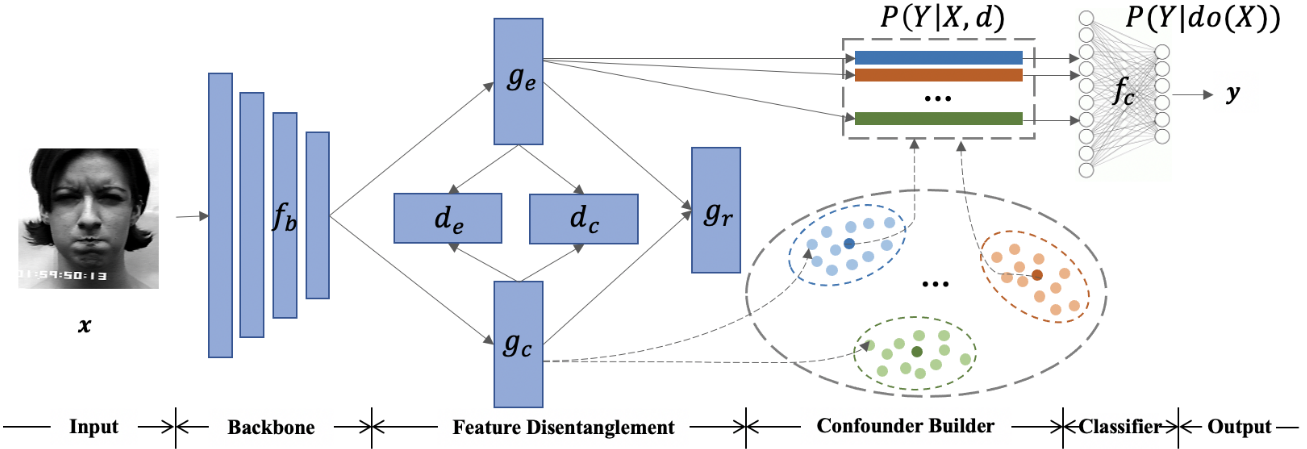
-
-
Human Trajectory Prediction via Counterfactual Analysis
-
Maheep's Notes
The paper propose a counterfactual analysis method for human trajectory prediction. They cut off the inference from environment to trajectory by constructing the counterfactual intervention on the trajectory itself. Finally, they compare the factual and counterfactual trajectory clues to alleviate the effects of environment bias and highlight the trajectory clues.
They Y_causal is defined as
Y_causal = Y_i - Y-i(do(X_i = x_i))
They define a generative model which generates trajectory by a noise latent variable Z indicated byY*_i. Finally the loss is defined as:
Y_causal = Y*_i - Y*_i(do(X_i = x_i))
L_causalGAN = L2(Y_i, Y_causal) + log(D(Y_i)) + log(1-D(Y_causal)), where D is the discriminator.
-
-
Proactive Pseudo-Intervention: Contrastive Learning For Interpretable Vision Models
-
Maheep's Notes
The paper present a novel contrastive learning strategy called Proactive Pseudo-Intervention (PPI) that leverages proactive interventions to guard against image features with no causal relevance. The PPI consists of three main components:
(i) a saliency mapping module that highlights causally relevant features which are obtained using the WBP which backpropagates the weights through layers to compute the contributions of each input pixel, which is truly faithful to the model, and WBP tends to highlight the target objects themselves rather than the background
(ii) an intervention module that synthesizes contrastive samples
(iii) the prediction module, which is standard in recent vision models
The prediction module is encouraged to modify its predictions only when provided with causally-relevant synthetic interventions.
The saliency map wchich are uniquely determined by thef(theta)are produced and the main features are masked out of the image giving usx*. Now the loss becomesL = sigma(l(x*,not_y;f(theta)))
A trivbial solution can be the saliency maps copvers the whole image therefore L1-norm of saliency map is used to encourage succinct (sparse) representations. The another problem that now arises is that the model can learn a shortcut that when it get a masked image then it has to always givenot_yas prediction, so as to counter it the author proposes to send images with random masks on them, making the lossL = sigma(l(x',y;f(theta)))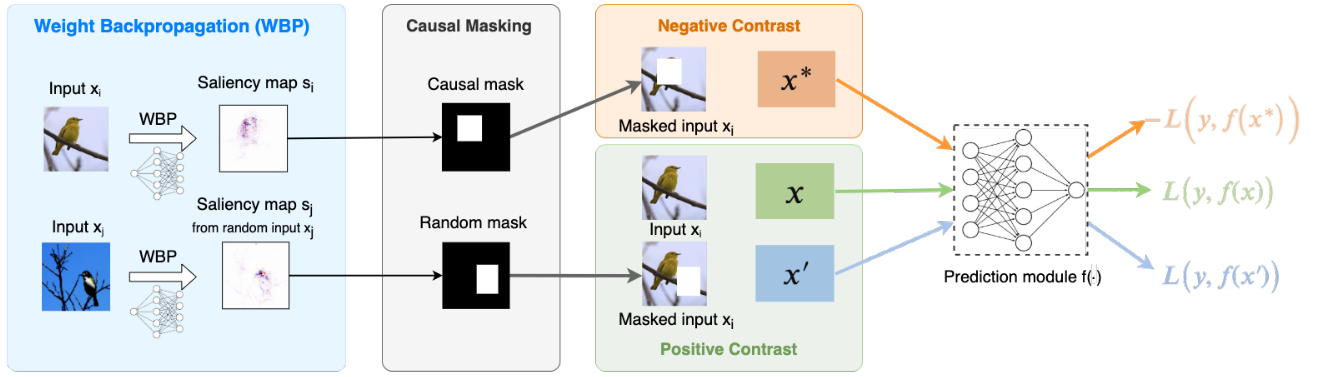
-
-
Interventional Video Grounding with Dual Contrastive Learning
-
Maheep's Notes
The paper proposes interventional video grounding (IVG) that leverages backdoor adjustment to deconfound the selection bias based on structured causal model.They introduce a dual contrastive learning approach (DCL) to better align the text and video by maximizing the mutual information (MI) between query and video clips so as to deconfounded video grounding that will aim to localize a moment from an untrimmed video for a given textual query after deconfounding it. The author implements the system in major 5 steps:
1) Given an input query and video, the two encoders output contextualized visual and textual representations respectively.
2) Then, these representations will be fed into two contrastive modules VV-CL and QV-CL respectively to learn high-quality representations with two contrastive losses L_vv and L_qv, where the QV-CL module focuses on increasing the Mutual information of the positive frames of video and the query. The VV-CL aims to increse the mutual information b/w the start and end boundaries of the video, which looks like as shown in the diagram below:
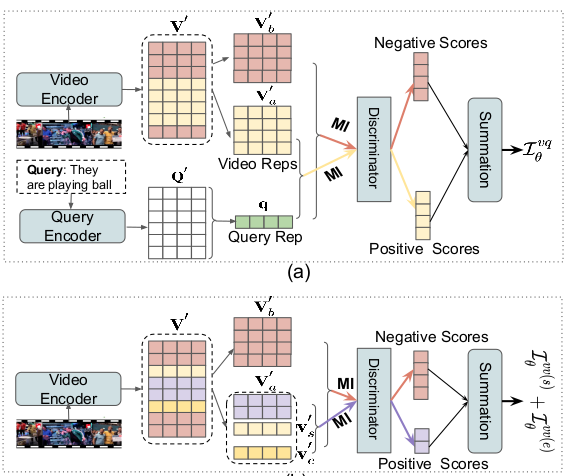
- The output of two feature encoders are fed to a fusion module with a context-query attention mechanism to capture the cross-modal interactions between visual and textual features.
- As the confounder is unobserved, therefore to mitigate the spurious correlations between textual and visual features, the author develops a surrogate confounder. It includes the the vocabulary of roles, actions and objects extracted from captions. Based on these, it computes the prior probability of every phrase z in each set and incoporates every phrase uniformly using the Normalized Geometric Mean(NWGM).
- Finally, two losses L_s and L_e for the start and end boundaries are introduced.
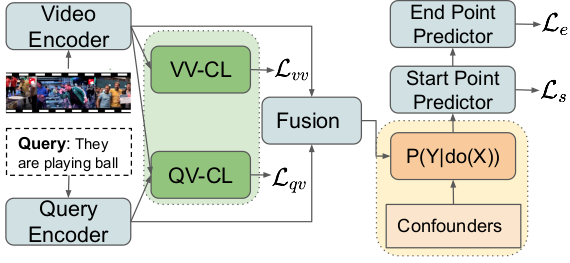
- The output of two feature encoders are fed to a fusion module with a context-query attention mechanism to capture the cross-modal interactions between visual and textual features.
-
-
Causality matters in medical imaging
-
Maheep's Notes
The paper proposes the establishment of causal relationship between images and their annotations as it provides a clear and precise framework for expressing assumptions about the data. The author argues that when taking a look at different field like data scarcity, data-mismatch etc. We can easily find the generalization is not achieved and sometimes the performace becomes very poor due to some factors which are explained through causality in the research paper.
Taking a look at Data Scarcity Semi-supervised learning (SSL) aims to leverage readily available unlabelled data in the hope of producing a better predictive model than is possible using only the scarce annotated data but a model trained on image-derived annotations will attempt to replicate the (most often manual) annotation process, rather than to predict some pre-imaging ground truth therefore consisting of a confounding variable that comes from the annotator.
Data mismatch is the second issue the author discusses and argues that the mismatch between data distributions, typically between training and test sets or development and deployment environments, tends to hurt the generalisability of learned models and therefore it can be said that Dataset shift is any situation in which the training and test data distributions disagree due to exogenous factors. Moreover when analysing dataset shift, it is helpful to conceptualise an additional variable Z, representing the unobserved physical reality of the subject’s anatomy. There are also another types of shifts like manifestation shift(under which the way anticausal prediction targets (e.g. disease status) physically manifest in the anatomy changes between domains), acquisition shift which result from the use of different scanners or imaging protocols and Data mismatch due to sample selection bias where the indicator variables in sample selection concern alterations in the data-gathering process rather than in the data-generating process.
-
-
TSMOBN GENERALIZATION FOR UNSEEN CLIENTS IN FEDERATED LEARNING
-
Maheep's Notes
The paper proposes TsmoBN method which can reduce divergence between training and testing feature distributions and also achieves a lower generalization gap than standard model testing. The author argues that in Federated Learning the performance degrades during the test phase as a global model trained on heterogeneous feature distributions fails to be an accurate estimation for a different distribution on the unseen client. Therefore the author propose to use test-specific and momentum tracked batch normalization (TsmoBN) to solve the unseen client generalization problem for varying feature distributions. The author implements it as:
The author takes the approach of causality and defines a SCM having the terms asD_s_ifor datasets of different domain, i.e. coming from different users but used in training,Xare the samples,Rare the raw extracted features ofX,Fis the normalized feature representaiton ofRandYis the classifier. To remove the confounding effects brought byD_u, a direct way is using causal intervention on normalized features (i.e., do(F)) to let the feature distribution similar to training distributions. This intervention by introducing the surrogate variableS, which is test-specific statistics of raw featuresRduring testing by obtaining the test normalized features that have similar distributions as the training normalized features. More specifically by calculating the mean and variance pair at test time in BN to normalize features. Additionally they further propose to use momentum to integrate relations among different batches, thus reducing the variances. Precisely by giving the unseen client with M batches of data to be tested in sequential manner.
-
-
Learning Domain Invariant Relationship with Instrumental Variable for Domain Generalization
-
Maheep's Notes
The paper proposes an instrumental variable-based approach to learn the domain-invariant relationship between input features and labels contained in the conditional distribution as the input features of one domain are valid instrumental variables for other domains. Therefore they propose a model Domain-invariant Relationship with Instrumental VariablE (DRIVE) via a two-stage IV method.
1.) It learns the conditional distribution of input features of one domain given input features of another domain with Maximum Mean Discrepancy(MMD) that minimizes the distance b/w the feature representation of two different domains.
2.) In second step it estimates the domain-invariant relationship by predicting labels with the learned conditional distribution by sampling from the first step distribtion.
-
-
Latent Space Explanation by Intervention
-
Maheep's Notes
The study in this R.P. aims to reveal hidden concepts by employing an intervention mechanism that shifts the predicted class based on discrete variational autoencoders based on the high concepts(human interpretale and not low level features like pixels). We could easily intervene on the latent space of the high concepts to find out the most discriminative concepts but they are not human interpretable therefore they use visualization to make it human interpretable. To accomplish the first step they use discrete variational autoencoder(DVAE). The boolean latent space cosnist ofZ = {z1, z2,....., zn}which is intervened to flip the output of the model and are finally vsualized from the hidden representation using the lossL = l(g(phi'(x), x)), wherephi'(x)is the counterfactual model. The next goal is to ensure that the generated concepts follow the same concepts the discriminator employ. They achieve this by maximizing the amount of information that the explanatory learner (i.e., g) extracted from the latent representation with respect to the discriminative learner’s (i.e., f_K) information.
-
-
The Blessings of Unlabeled Background in Untrimmed Videos
-
Maheep's Notes
The paper propose a Temporal Smoothing PCA-based (TS-PCA) deconfounder, which exploits the unlabelled background to model an observed substitute for the unobserved confounder, to remove the confounding effect in Weakly-supervised Temporal Action Localization(WTAL), which aims to detect the action segments with only video-level action labels in training. The author proposes to take all different input video and argues that if by extracting the distribution of the input video features the if we have an unobsereved confounder "z", then we can identify it by using the equationP(x_1, x_2,....., x_n | Z = z) = TT P(x_t | Z = z), i.e. the features will become independent if we are able to obeserveZbut if there exists an unobserved confounder c, which affects multiple input video features within x and segment-level labels A. Then, x would be dependent, even conditional on z, due to the impact of c, in this case with the blessings of weak ignorability we can replace the expectation over C with a single z inE[E[A|X = x, C = c]] = A
-
-
Selecting Data Augmentation for Simulating Interventions
-
Maheep's Notes
The paper argue that causal concepts can be used to explain the success of data augmentation by describing how they can weaken the spurious correlation between the observed domains and the task labels. The following can also be used to decide which augmentation to use so as to do intervention and achieve generalization. If one needs to do causal intervention using augmentaiton then he/she needs to make assumptions about the causal data generating process so as to identify hihg-level features h_d caused by a particular domain. To keep all this in mind they propose an algorithm that is able to select data augmentaion techniques that will improve domain genralization, i.e. Select Data Augmentaion(SDA). The proposed SDA consist of mainly 3 steps:
1.) Dividing all samples from the training domains into a training and validation set.
2.) By training a classifier to predict the domain d from input x. During training, apply the first data augmentation in the list to the samples of the training set. Save the domain accuracy on the validation set after training. This step is repeated all data augmentations in the list.
3.) The data augmentation is slected with the lowest domain accuracy averaged over five seeds. If multiple data augmentations lie within the standard error of the selected one they are selected as well, i.e., there is no statistically significant difference between the augmentations.
-
-
Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification
-
Maheep's Notes
The paper proposes counterfactual attention learning(CAL) to learn the attention with counterfactual causality. The author analyze the effect of the learned visual attention on network prediction through counterfactual intervention and maximize the effect to encourage the network to learn more useful attention for fine-grained image recognition. The basic idea is to quantitate the quality of attentions by comparing the effects of facts and the counterfactuals on the final prediction. The author implements it as :
They apply counterfactual intervention do(A= A') by imagining non-existent attention maps Ā to replace the learned attention maps and keeping the feature maps X unchanged using the random attention. uniform attention or reversed attention an then the evaluate the equation.Y_effect = E[Y(A = A, X = X)] - E[Y(A = A', X = X)]
The loss comprises as:
L = L_crossentropy(Y_effect, y) + L_others, where L_others represents the original objective such as standard classification loss.
-
-
Meaningful Explanations of Black Box AI Decision Systems
-
Maheep's Notes
The paper discusses about the Black-box models and how they can be used for explanation. The author proposes 2 different flavours of this problem.
1.) **eXplanation by Design (XbD)**: given a dataset of training decision records, how to develop a machine learning decision model together with its explanation;
2.) **Black Box eXplanation (BBX)**: given the decision records produced by an obscure black box decision model, how to reconstruct an explanation for it.
The author propose a new local-first explanation framework: expressive logic rule languages for inferring local explanations(by local they mean the explanation of data point), together with bottom-up generalization algorithms to aggregate an exhaustive collection of local explanations into a global one, optimizing jointly for simplicity and fidelity in mimicking the black box. The author argues that more informative causal explanation should be provided and the local level information availability can be quite beneficial for the progress of the field. Therefore the author cite it's previous work LORE, a local explanator that builds a focused exploration around the target point, and delivers explanations in the form of highly expressive rules together with counterfactuals, suggesting the changes in the instance’s features that would lead to a different outcome. The athor argues that a black box explanation framework should be:
1.) model-agnostic
2.) logic-based
3.) both local and global explanability
4.) high-fidelity: provides a reliable and accurate approximation of black-box behaviour.
-
-
Are VQA Systems RAD? Measuring Robustness to Augmented Data with Focused Interventions
-
Maheep's Notes
The paper proposes a new robustness measure, Robustness to Augmented Data (RAD), which measures the consistency of model predictions between original and augmented examples. They define it as:
RAD =|J(D;F) and J(D';F)|/|J(D;F)|
, whereJ(D;F)as the set of example indices for which a modelfcorrectly predictsy.D'represents the augmented example which is prepared as VQA dataset there are three answer types: “yes/no”, “number” and “other”, and 65 question types. In augmentations, they generate “yes/no” questions from “number” and “other” questions, i.e. What color is the ? is changed to Is the color of is ?
RAD is in [0, 1] and the higher the RAD of f is, the more robust f is.
-
-
Adversarial Robustness through the Lens of Causality
-
Maheep's Notes
The paper propose the adversarial distribution alignment method to eliminate the difference between the natural distribution and the adversarial distribution by incorporating cauality into mitigating adverserial vulnerability. They define the adverserial example as
P_theta(X, Y) = sigma(P_theta(Y,s|X)*P_theta(X)),
where s is the spurious correlation. As we know that the distribtuion ofXcan be hardly changed thereforeP_theta(X) = P(X). Therefore it can be assumed that the difference b/wP_theta(Y,s|X)andP(Y,s|X)is the main reason of the adverserial inrobustness. Therefore they define the loss as:
min CE(h(X + E_adv ; theta), Y) + CE(h(X; theta), Y) + CE[P(Y| g(X, s)), P(Y|g(X + E_edv, s))]
whereE_advadverserail perturbation, theta are parameters of the model, and g represents the paramter optimized to minimize theCE, i.e. Cross Entropy loss.
-
-
-
Maheep's Notes
The paper proposes that counterfactual approach developed to deconfound linear structural causal models can still be used to deconfound the feature representations learned by deep neural network (DNN) models, so as to implement it the author argues that in a learned DNN the second last layer(just behind the softmax layer) has a very linear realtionship with the labels and can be used to intervene and generate counterfactual example to make the model robust. The author develops the causal diagram having 4 variables, P_ix, Y, C, S which represent the data distribution, label, indicates the presence of a selection mechanism generating an association between Y and C. The C represents the confounder.
In order to remove/reduce the influence of C on the predictive performance of the classifier, they apply the causality-aware adjustment proposed to generate counterfactual features, X'. These counterfactual examples are used to train a logistic regression classifier, and then use the same algorithm to generate counterfactual in test set X_test' to generate predictions that are no longer biased by the confounder.
-
-
Domain Generalization using Causal Matching
-
Maheep's Notes
The paper proposes MatchDG is an iterative algorithm that starts with randomly matched inputs from the same class and builds a representation using contrastive learning such that inputs sharing the same causal features are closer to one another. It is a two-phase method that first learns a representation independent of the ERM loss, so that classification loss does not interfere with the learning of stable features. The author argues that the a common objective is to learn representations independent of the domain after conditioning on the class label. They show that this objective is not sufficient: there exist counter-examples where a model fails to generalize to unseen domains even after satisfying class-conditional domain invariance. If there are 3 data-points (x_d_i, y), (x_d'_j, y) and (x_d_k, y') then the distance in causal features between x_i and x_j is smaller than distance between x_i and x_k or x_j and x_k. Based on this they represent a contrastive loss which bring lables of same class closer and increases the distances b/w different class label.
-
-
Counterfactual Debiasing Inference for Compositional Action Recognition
-
Maheep's Notes
The paper proposes Counterfactual Debiasing Network (CDN) Compositional action recognition by inhibiting the co-occurrence bias in the same action with distinct objects and also to deconfound the direct effect of appearance. The model consist of only 2 simple steps:
1.) Building the model as usual by training it.
2.) Taking the prediction from only visual appearance and subtracting it from the output of the model considering both brances.
The only losses which gets constituted in the model are: Appearance loss, Structural Loss and fusion Loss by using the cross-entropy.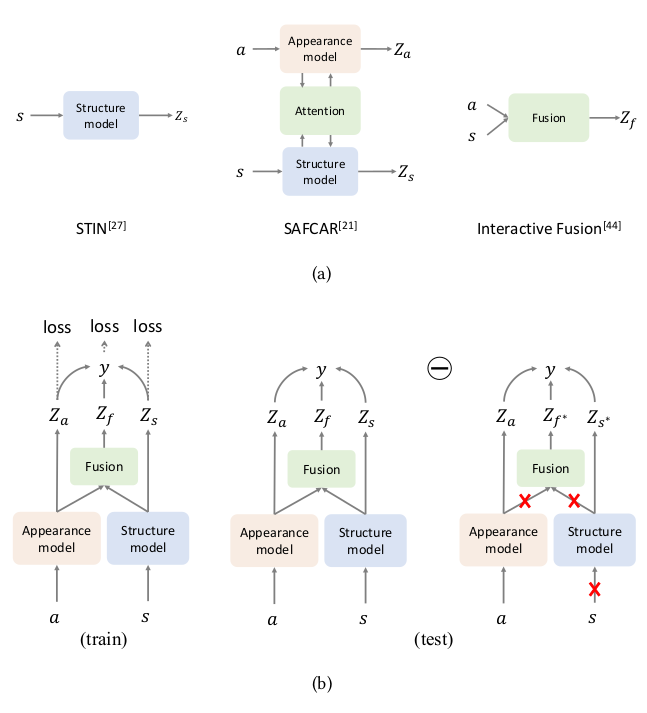
-
-
Deconfounded Video Moment Retrieval with Causal Intervention
-
Maheep's Notes
The paper proposes Deconfounded Cross-modal Matching(DCM) method for a causality-inspired VMR framework that builds structural causal model to capture the true effect of query and video content on the prediction to remove the confounding effects of moment location. It first disentangles moment representation to infer the core feature of visual content, and then applies causal intervention on the disentangled multimodal input based on backdoor adjustment. The feature disentanglement is used to separate the location feature from the visual context feature which act a spurious feature in it and as it act as a spurious feature for the label by directly effecting it the use the second method to eridicate it. This is implemented as:
1.) The disentanglement is done by using the two fully connected layers. It is ensured by reconstruction loss that the `"l"` vector reconstructs the location and the loss `"L_inde"` so as to force the `l` to be independent of `c`.
2.) As for the second point backdoor method is used to eradicate the spurious correlation.
-
-
Intervention Video Relation Detection
-
Maheep's Notes
The paper proposes Interventional video Relation Detection(IVRD) approach that aims just not only to improve the accuracy but to improve the robustness of the model for Video Visual Relation Detection (VidVRD). It contains of 2 components:
1.) They first learn the set of predicate prototype where each prototype describes a set of relation references with the same predicate.
2.) They apply a causality-inspired intervention to model input , which forces the model to fairly incorporate each possible predicate prototype into consideration using the backdoor method.
The model only consist of only 2 types of losses:
L = L_obj + lambda*L_pred, whereL_objis the cross entropy loss function to calculate the loss of classifying video object trajectories andL_predis binary cross entropy loss used for predicate prediciton.
-
-
-
Maheep's Notes
The paper proposes VC R-CNN which uses causal intervention for the prediction of label "Y". The author implements it as:
The possible confounders are put into a dictionary. From the image objects are detected by Faster R-CNN, where each RoI is then fed into two sibling branches: a Self Predictor to predict its own class, e.g., x_c , and a Context Predictor to predict its context labels, e.g., y_c, where it is used to caluculate theE[g(z)]to get the top confounders from the dictionary. Now there is a complexity arise where the confounder is the doctionary act as the colliders therefore they are eridacted through the use of Neural Causation coefficient(NCC).
-
















-
Causal Attention for Vision-Language Tasks
-
Maheep's Notes
The paper proposes to eradicate unobserved confounder using the front-door adjustment. The author implements the same using the two methods, i.e. **In-Sample Attention** and **Cross-Sample Attention**. The causal effect from the input set X to the target Y through a mediator Z. The attention mechanism can be split into two parts: a selector which selects suitable knowledge Z from X, i.e.P(Z = z|X)known as In-Sampling and a predictor which exploits Z to predict Y.
P(Y|X) = sigma P(Z = z|X)P(Y|Z = z)
But the predictor may learn the spurious correlation brought by the backdoor path from X to Z, and thus the backdoor method is used to block the path from X to Z, making it:
P(Y|do(Z)) = sigma P(X = x)P(Y|X = x,Z)
whereP(X = x)is known as Cross-Sampling and making the whole equation:
P(Y|do(X)) = sigma P(Z = z|X) sigma P(X = x)P(Y|Z = z, X = x)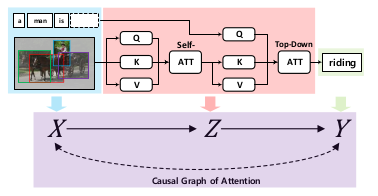
-
-
Causal Attention for Unbiased Visual Recognition
-
Maheep's Notes
Background plays a very common role as confounder and demands to train the model in way such as all the objectys come with various background so as to prevent bias in the model, e.g., a “dog” model is learned within “grass+dog” and “road+dog” respectively, so the “grass” and “road” contexts will no longer confound the “dog” recognition. But it faces with two types of problem:
1.) Such annotation is not only prohibitively expensive, but also inherently problematic, as the confounders are elusive in nature.
2.) Such coarser contexts will lead to the over-adjustment problem. The intervention not only removes the context, but also hurts beneficial causalities.
Also splitting the context split, to merge the ground-truth contexts into bigger splits to include all classes also faces problem as this kind of intervention removes the non-causal features of different contexts. Therefore the author proposes a causal attention module(CaaM) that self-annotates the confounders in unsupervised fashion which the causal featuresMare retained while the non-causal featuresSare eradicated as shown in the figure below. Therefore to disentangle the theSandM, the equation can be derived as:
P(Y|do(X)) = sigma_for_s sigma_for_m P(Y|X, s, m)P(m|X,s)P(s)P(Z = z|X)known as In-Sampling and a predictor which exploits Z to predict Y.
P(Y|X) = sigma P(Z = z|X)P(Y|Z = z)
But the predictor may learn the spurious correlation brought by the backdoor path from X to Z, and thus the backdoor method is used to block the path from X to Z, making it:
P(Y|do(Z)) = sigma P(X = x)P(Y|X = x,Z)
whereP(X = x)is known as Cross-Sampling and making the whole equation:
P(Y|do(X)) = sigma P(Z = z|X) sigma P(X = x)P(Y|Z = z, X = x)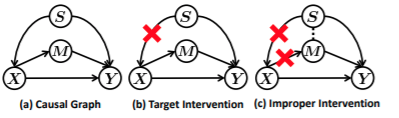
-
-
Causal Intervention for Weakly-Supervised Semantic Segmentation
-
Maheep's Notes
In Weakly-Supervised Semantic Segmentation(WSSS) the confounder creates a major problem as the non-causal features gets associated with positively correlated pixels to labels, and also disassociates causal but negatively correlated ones. The author proposes to eradicate it using the backdoor adjustment. The Ground Truth(GT) is extracted using the CAM and therefore pseudo-labels with is used to train the model. The author proposes 4 main varibales for the SCM, i.e. Confounder "C", Mediator "M" which act as the image-specific representation, Input "X" and Output "Y", where the direct effect of "C" is cutoff from "X", by using class-specific average mask to approzimate the confounderC = {c1, c2, c3,.....,cn}wherenis the class size to finally compute the equation.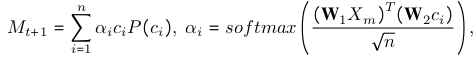
-
-
Confounder Identification-free Causal Visual Feature Learning
-
Maheep's Notes
The paper aims to eradicate all the confounders that are present without observing them using the frontdoor adjustment criteria and also try to explain the success of MAML algorithm. The work deals with two major questions:
1.) How to model the intervening effects from other samples on a given sample in the training process.
2.) How to estimate the global-scope intervening effect across all samples in the training set to find a suitable optimization direction.
and therefore proposes a gradient-based optimization strategy to mitigate the intervening effects using an efficient cluster then-sample algorithm to approximate the global-scope intervening effects for feasible optimization. The author implements it by explicitly modelling the intervening effects of another sample x̃ on Z = h(x) effecting Y by instantiating P (Y |Z = h(x), x̃) with the calculated gradients of the sample x̃ with respect to f
P(Y|Z = h(x), x̃) = f(Z = h(x))P(x̃)
after clustering-then-sampling using the k-mean.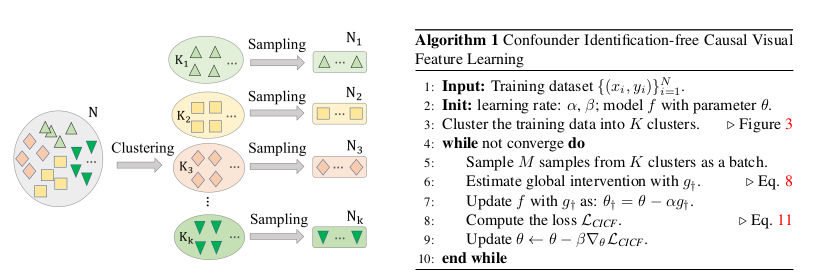
-
-
Comprehensive Knowledge Distillation with Causal Intervention
-
Maheep's Notes
The paper proposes CID for an efficient biased free knowledge distillation, which is able to transfer the class representations which are largely ignored by the existing literature and by using softened logits as sample context information removes biases with causal intervention. The author implements it as:
1.) They distill the feature vector in the last layer.
2.) They use MSE on noramlized vectors so as to get the MSE not to get biased towards the samples that have large-norm features.
3.) They integrate the class representations using the class shapes to incorporate it into the student model as so not to only transfer the sample representation. 4.) By using the backdoor adjustment the effect of the prior knowledge of the teacher model because of the object and background co-occurences by setting each item to the prior knowledge to a class.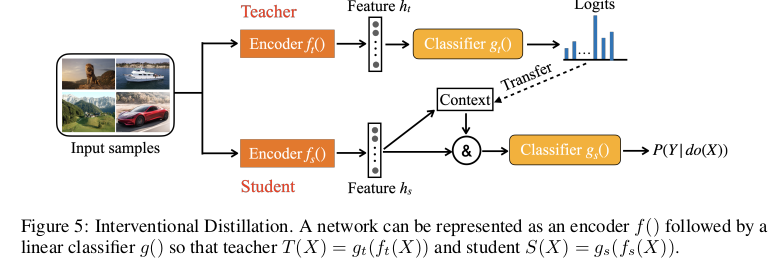
-
-
Counterfactual Contrastive Learning for Weakly-Supervised Vision-Language Grounding
-
Maheep's Notes
The paper aim to solve the problem of Weakly supervised Vision Language Grounding, i.e. to localize target moments in a video using a query. The author uses counterfactual scenario to make the process more robust, based on the feature-level, relation-level and interaction level.
The two types of approaches are introduced so as to generate the counterfactual scenarios, namely **DCT** and **RCT**, where the **DCT** aims to generate negative counterfactual scenarios by damaging the essential part of the visual content and **RCT** aims to generate positive counterfactual scenarios by damaging inessential part of the visual content based on the above defined 3 approaches.
A ranking loss is also developed so as to develop the difference between the positive and negative samples.
The feature-level focuses on the critical region proposals, which are modified using the memory bank containing the proposal features from randomly selected different samples, whereas the interaction-level features also uses memory bank to modify the interaction-level features, i.e. the word level features that correspond to the proposal features. The memory-bank contains the language features from different samples.
The relational-level approach focuses on the relation, i.e. the edges connecting the propsal "j" from proposal "i". The crucial edges are then destroyed by **DCT** whereas the inessential by **RCT**.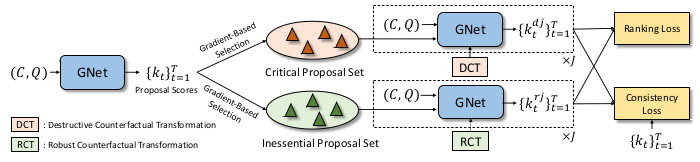
-
-
C_3 : Compositional Counterfactual Constrastive Learning for Video-grounded Dialogues
-
Maheep's Notes
The paper focuses on the video-grounding using the diaglouges and inputs, where the author inlcudes the turn based events which let the model give high priority to some instances rather than uniformly giving to all. Also the author separates the dialogue context and video input into object and action, through which they are able to parse through if the query is about object or any action taken, as shown in the figure below.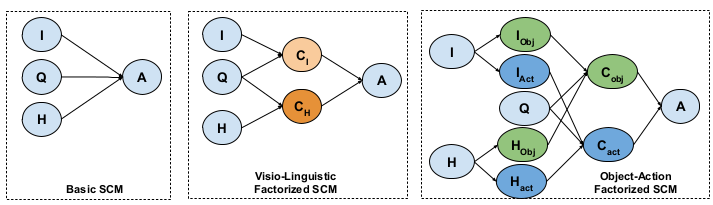
Also they generate counterfactual scenarios by removing irrelavant objects or actions to create factual data and by removing relevant object or actions, they generate counterfactual data, finally making the equations as:
H_t^- = H_{t, obj}^- + H_{t, act}
H_t^+ = H_{t, obj}^+ + H_{t, act}
I^- = I_obj + I_act^-
I^+ = I_obj + I_act^+where
H_t^-denotes counterfactual dialogue context in instancetandI^-represents the counterfactual image input.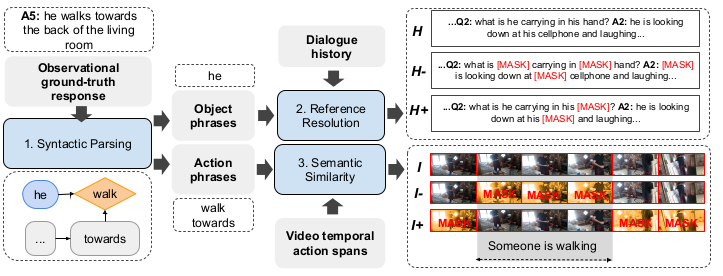
-
-
COIN: Counterfactual Image Generation for VQA Interpretation
-
Maheep's Notes
The paper focuses on interpretability approach for VQA models by generating counterfactual images by minimal possible change, ensuring the image looks realistic. This paper introduces an attention mechanism that identifies question-critical objects in the image and guides the counterfactual generator to apply the changes on specific regions. Moreover, a weighted reconstruction loss is introduced in order to allow the counterfactual generator to make more significant changes to question-critical spatial regions than the rest of the image.
This is implemented by instead of generating a counterfactual imageI'based on the original image , the latter is concatenated with the attention mapM, such that the concatenation[ I; M]serves as an input to the generatorG, where the answer is passed into theGso as to createI', where the regions are identified using GRAD-CAM, where the discriminatorDensures that image looks realistic and reconstruction loss is used to do miimal changes. The whole process happens as shown in the figure.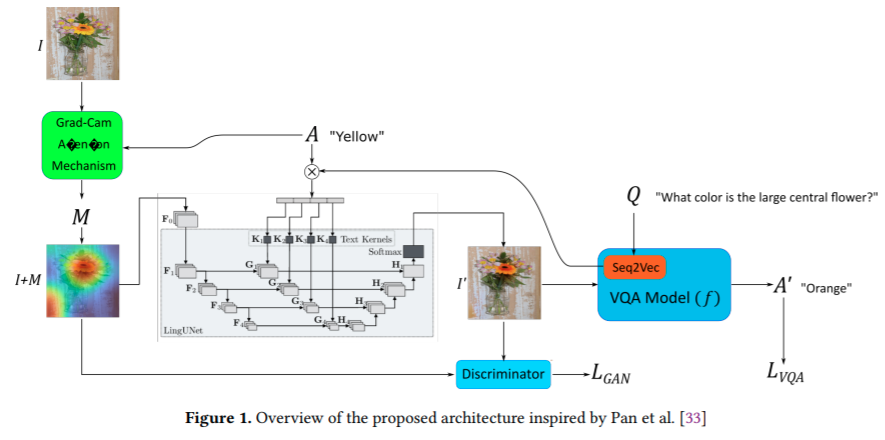
-
-
Causal Intervention for Object Detection
-
Maheep's Notes
The paper proposes to remove bias from the object detection models using the intervention, where the author uses the idea of two-stage detectors and apply backdoor adjustment to virtually obtainP(Y|do(X))where the author proposes 4 variables namely inputX, outputY, context confounderCand mediatorMaffected by bothXandC, where theC = {c1. c2, ..., cn}belonging to differentncategories in the dataset. The outputP(Y|do(X))is represented as:P(Y|do(X)) = sigma P(c)P(Y|X,M = f(X,c))whereMis represented as
M = sigma a_i*c_i*P(c_i)
wherea_iis the attention for category specific entryc_i.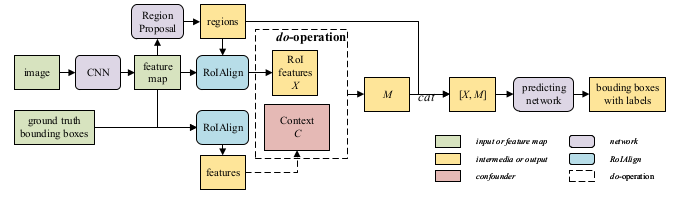
-
-
Efficient Counterfactual Debiasing for Visual Question Answering
-
Maheep's Notes
The paper proposes a novel model-agnostic counterfactual training procedure, namely Efficient Counterfactual Debiasing (ECD). The author implements the technique by defining the three modules in this work:
1.) **ECD-V**: The module focuses on creating the counterfactual and factual scenes in the the visual regions which are identified by extracting the nouns using POS tagger from questions and similarity is defined between the nouns and object categories. The ones with highest scores are removed from the image.
2.) **ECD-Q**: The module focuses on creating the counterfactual and factual questions in the question regions by separating *question-type words* and *stop-words* to identify the critical words, which are removed to create counterfactual questions and factual are created by removing the inessential words, i.e. *question-type words* or *stop-words*.
3.) **Negative Answer Assignment**: The module assign ground-truth answers to counterfatual pairs. To make this effective the author analyzes the number of occurrences of each answer and normalize the number of occurrences of an answer for a specific question by the total number of occurrences of that question type in the training set. The top-N answers with the highest predicted probabilities are selected as A+ and the Ground-truth answers(GT) and the negative answers A- as all answers of GT but those in A+.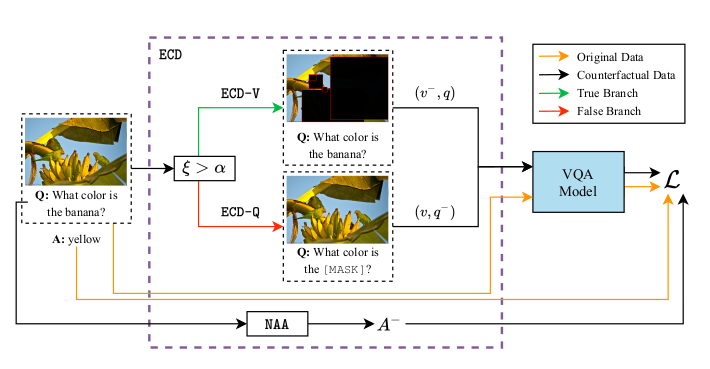
-
-
Causality-inspired Single-source Domain Generalization for Medical Image Segmentation
-
Maheep's Notes
The paper proposes solve the problem of Domain Generalization for image segementation m using the two modules:
1.) **GIN**: It promotes to preserve the shape of information as it is one of the most improtant information that remains invariant while domain shift and also is intuitively causal to segmentation results.
This is implemented by augmenting the image to have diverse appearances via randomly-weighted shallow convolutional networks, as shown in the diagram below.
2.) **IPA**: It focuses on removing the confounding factors from the image like thebackground and also the acquisiton process, where different tissues are given different color. The author usesdo(.)to remove the confouning nature of onAonSby transforming theAusing theT_i(.)photometric transformation.
The psuedo-correlation is proposed so as to deconfound background that is correlted with the output by changing the pixels that correspond to different values are given different values unsupervised fashion. The pseudo-correlation map is impelemnted by using the continous random-valued control points with low spatial frequency, which are multiplied with theGINaugmented image.
-
-
Distilling Causal Effect of Data in Class-Incremental Learning
-
Maheep's Notes
The paper proposes to immune the forgetfull nature of NN while shifting to new data from old data. The author discusses the three main methods which are used now to mitigate this problem.
1.) **Data Replay**: This focus on to include a small percentage of old data in the new data.
2.) **Feature Distillation** and **Logit Distillation**: This focuses on to the effect is the features/logits extracted from the new data by using the old network, which is imposed on the new training by using the distillation loss, regulating that the new network behavior should not deviate too much from the old one.
The paper focuses on to explain the causal effect of these methods. The work proposes to calculate the effect of old data on the current predicition
Y, making the equationEffect = P(Y|D = d) - P(Y|D = 0), which comes0when the old data has no influence onY, while if we calculate the impact in replay or distillation, will not be0. The work proposes to further enhace the replay method by passing down the causal effect of the old data, rather than the data. Therefore making the whole process computationally inexpensive by conditioning onXo, i.e. the old data representaiton and therefore making the equation:
Effect = P(Y|I, Xo)(P(I|Xo, D = d) - P(I|Xo, D = 0))
further defining it as:
Effect = P(Y|I, Xo)W(I = i, Xo, D)
The paper aims to increase the value ofW(.)expression as it depends the close similarity between the representation of the similar image in old model and new model.
-
-
-
Maheep's Notes
The paper proposes to generate counterfactual explanation for multi-class classification of fMRI data. The author proposes **CAG** which is build upon **StarGAN**. The explanation is based upon the **Correct Classification** and **Incorrect Classification**, where the CAG converts the input to the target class and subtracts it pixel-wise so as to extract the activated regions, giving red(blue) output activation as to answer why the classifier predicted(not predicted) the target class. Auxillary discriminator is introduced so as to have a single discriminator to control multiple classes and produce their probability distribution, based on source and target class.
-
-
How Well do Feature Visualizations Support Causal Understanding of CNN Activations?
-
Maheep's Notes
The paper proposes to identify the benefits of providing users with visualization of unit's activation based on different features of the input, so as to provide humnas with precise information about the image features that casuse a unit to be activated.
The author uses the counterfactually inspired task to evaluate how well do feature visualization support causal understanding of CNN activations. The author implements it by using 5 kiond of images, namely:
1.) Synthetic Reference : These are image that are generated from optimized result of feature visualization method.
2.) Natural Reference : Most strong actiavted samples are taken from the dataset.
3.) Mixed Reference : 4 synthetic and 5 Natural refernce are taken, to take the best of both worlds
4.) Blurred Reference : Everything is blurred, except a patch.
5.) No Reference : Only query image is given and no other image.The author concludes the research by concluding that the performance of humans with visualization and no visualization did not have very significant differences.
-
-
CausalAF__Causal_Autoregressive_Flow_for_Goal_Directed_Safety_Critical
-
Maheep's Notes
The paper proposes to generate goal-direceted data satisfying a given goal for safety-critical situations. The author argues that theBehavioural Graph unearths the causality from the Causal Graph so as to include in the generated samples. This is done using two methods namely:
1.) COM : It maintians the Q , to ensure that the cause is generated in terms of nodes only after the effect. It is also noted that the node have many parents, therefore the node is considered valid only when all of it's parents have been generated.
2,) CVM : The correct order of causal order is not sufficient for causality therefore CVM is proposed so as to only consider the nodes when the information of it's parents are available and the information only flow to a node from it's parents.
-
-
Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification
-
Maheep's Notes
The paper proposes to improve attention using a counterfactual attention learning method based on causal inference. The author argues that the most existing methods learns the attention in a weakly-supervised way. The basic idea is to quantitate the quality of attentions by comparing the effects of facts (i.e., the learned attentions) and the counterfactuals (i.e., uncorrected attentions) on the final prediction (i.e., the classification score). Then, we propose to maximize the difference to encourage the network to learn more effective visual attentions and reduce the effects of biased training set. The author implements it by:
1.) The attention maps are extracted from the image,A = {A1, A2, A3,....., An}, the attention maps are used to extract the respective feature from the image.hi = gamma(X*Ai), where all thehiare normalized to get theh = normalize(h, h2,...., hn)which is used to predict. 2.) The attention is intervened to get the effect on the output of the model, i.e.
Y_effect = E[Y(A = A, X = X) - Y(do(A = bar(A))), X = X]
It is expected to achieve two-conditions using this method:
a. ) The attention model should improve the prediction based on wrong attentions as much as possible, which encourages the attention to dis- cover the most discriminative regions and avoid sub-optimal results
b.) The prediction based on wrong attentions is penalized, which forces the classifier to make decision based more on the main clues instead of the biased clues and reduces the influence of biased training set.
-
-
Improving Users’ Mental Model with Attention-directed Counterfactual Edits
-
Maheep's Notes
The paper show that showing controlled counterfactual image-question examples are more effective at improving the mental model of users as compared to simply showing random examples. The statement is evaluated by asking the users to predict the model’s performance on a test counterfactual image. It is noted that, overall an improvement in users’ accuracy to predict answer change when shown counterfactual explanations. The counterfactual image is generated either by retrieving an image where the answer is different or by removing the visually important patch from the image, which is identified using the attention maps, using a GAN network. The patch with high and low attention are removed to evaluate the decision of VQA. Based on it a user can hypothetically learn whether the VAQ model is behaving rationally or not.
-
-
Free Lunch for Co-Saliency Detection: Context Adjustment
-
Maheep's Notes
The paper focus on collecting dataset for co-saliency detection system called Context Adjustment Training. The author introduces counterfactual training to mitigate the finite dataset to achieve the true data distribution. Based on it the author proposes to use context adjustment using thegroup-cut-paste method to imporve the data distribution. GCP turns image
Iinto a canvas to be completed and paint the remaining part through the following steps:
(1) classifying candidate images into a semantic group Z (e.g., banana) by reliable pretrained models
(2) cutting out candidate objects (e.g., baseball, butterfly, etc.)
(3) pasting candidate objects into image samples as shown in the figure below.
To make the process more robust the author proposes to have three metrics, namely:
a.) Abduction: In the new generated data the co-saliency image should remina unchanged.
b.) Action: The mask sould remain unchanged from the GT of the image and should be optimal for it's value.
c.) Prediction: The probability distribution of the image should remian unchanged.
-
-
Counterfactual Explanation Based on Gradual Construction for Deep Networks
-
Maheep's Notes
The work focuses on modifying the charecteristic of the image given the features of the Deep Neural Network classifier. The author takes in two measures, i.e. the image shold be easily explainable and should only be minimally modified.
The author impelements it using the two steps, namely:
1.) Masking Step: It mask the appropriate region of the image, to which the model pays most attention, extracted using the gradients.
2.) Composition Steps: It perturbs the regions minimally so as to change the logits to the target class.
-
-
-
Maheep's Notes
The work proposes to create counterfactual explanation images for medical images by taking in two measures, i.e. there should be minimal change in the original image and the classifier predicts it in to the target class. The author accomplishes this goal using the image-to-image translation using StarGAN as shown in the picture below.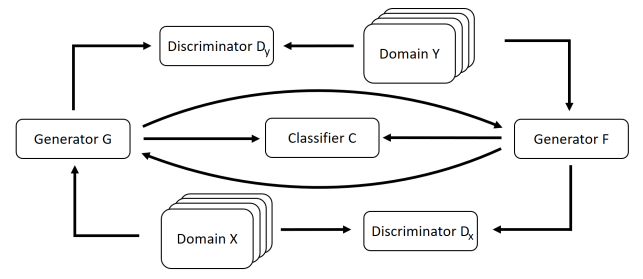
-
-
Using Causal Analysis for Conceptual Deep Learning Explanation
-
Maheep's Notes
The work proposes to explain the model's decision using the hidden unit cells of the network in radiology. The author uses the associating the hidden units of the classifier to clinically relevant concepts using a linear sparse logistic regression. But to evaluate that the identified units truly influence the classifier’s outcome, they use mediation analysis through counterfactual interventions. A low-depth decision tree is constructed so as to translate all the discovered concepts into a straightforward decision rule, expressed to the radiologist. Technically the author implements it by using:
1.) **Concept Associations**: The network is divided intophi1(.)andphi2(.), where thephi1(.)gives different concept in terms of features andphi2(.)do prediction. The output ofphi1(.)gives a vector oflbhdimension with each unit having a binary prediction, i.e. if concept is present or absent.
2.) Causal concept ranking: A counterfactualx'for the inputxis generated for causal inference using a cGAN, where the concepts are denoted withVk(x)and the left over hidden units are denoted bybar(Vk(x))and the effect is measured by:
A = phi2(phi1(do(Vk(x)), bar(Vk(x'))))
B = phi2(phi1(Vk(x), bar(Vk(x))))
Effect = E[A/B - 1]
3.) Surrogate explanation function: A functiong(·)is introduced as a decision tree because many clinical decision-making procedures follow a rule-based pattern, based on the intial classifierf(.)based on the logits produced for different concepts.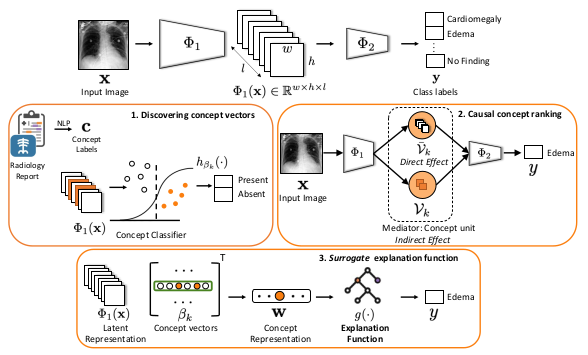
-
-
-
Maheep's Notes
The work proposes to unify diagnostic model learning, visual explanation generation using the counterfactual explanation using a target class, and trained diagnostic model reinforcement guided by the visual explanation on the discriminative features extracted by the counterfactual explanation on the mSRI data for the muti-class classification. The author implements the system by learning the counterfactual map for explanation which consist of three modules **Counterfactual Map Generator(CMG)**, **Reasoning Evaluator(RE)** and a **Discriminator(DC)**, where CMG generates the counterfactual image using the U-net technique giving a Mask and adding it to the input as given in the image below. RE directly evaluates the effect of the generated counterfactual map in producing the targeted label, and Discriminator makes it sure that the generated image look realistic. The **Reinforcement Representation Learning** tries to create a guide map using the above counterfactual map which highlight the extreme regions, i.e. the normal and the regions that have high probability that are abnormal.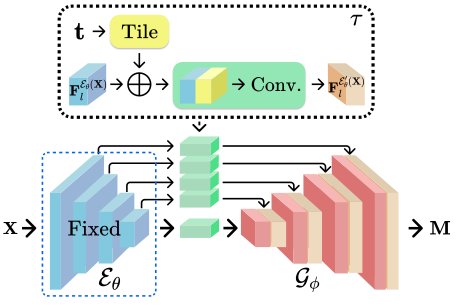
-
-
Causal affect prediction model using a facial image sequence
-
Maheep's Notes
The work proposes to learn the causal affect prediction network (CAPNet), which uses only past facial images to predict corresponding affective valence and arousal, after learning the causal inference between the past images facial-expressions and the current affective state. The author implements it as:
The system mainly consist of 2 modules:
1.) **Feature Extractor**: The module consist of REsNeXt and SENet to extract the features from the image using the FER model as it is and output the valence and arousal of the subject.
2.) **Causality Extractor**: It consist of a LSTM layer and two FC layers. During the integration of sequential data into the single hidden state, the LSTM layer learn the causal inference between the past facial images and the affective state. The FC layers eventually convert the single hidden state to the predicted affective state.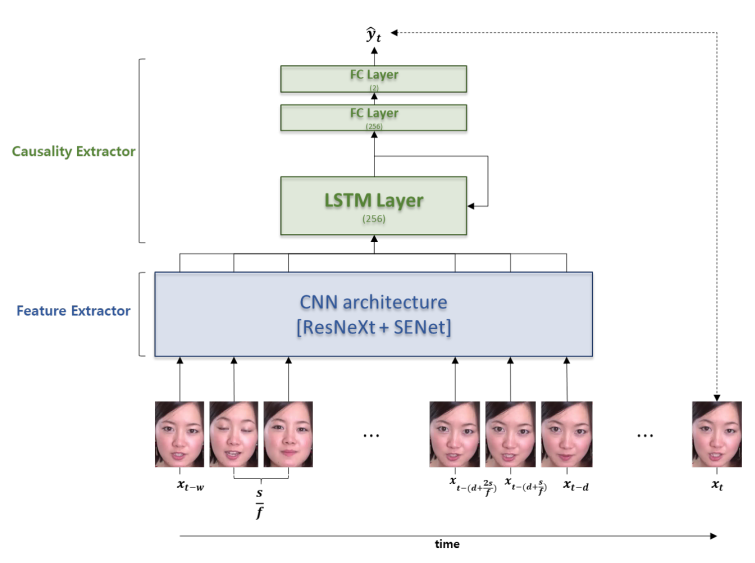
-

























-
iReason: Multimodal Commonsense Reasoning using Videos and Natural Language with Interpretability
-
Maheep's Notes
The work proposes to extract the causal events using the videos and text. The author claimes that objects in the video and time-ordered nature of events promotes causality, therefore removing bias. The author implememnts by using the architecture given below.
The CFDM module localize the said events in the video and outputs a pair of images, i.e.
I1andI2from the video. The aim is to infer causality from the event inI1intoI2. The Causality Rationalization Module outputs a string explaining the commonsense reasoning using natural language for causal eventse1fromI1ande2fromI2.
-
-
CausalCity: Complex Simulations with Agency for Causal Discovery and Reasoning
-
Maheep's Notes
The work proposes to generate a data with rare events in substantial amount for safety-critical decisions of driving using a simulated environment having the ability to introduce confounders, observed and unobserved using the agency or high-level controls, that define the agents behaviour in an abstract format. The author implements it as:
The author introduces two main things that totallly build up the whole simulated environment, i.e.
JSON file that contains the vehicles that should be present, their start location, and high-level features which are flexible and can be regulated using the Python API. To make the whole enviroment 6 types of varibales are introduced, namely:
1.) Environment Features: It contains the information about the basic objects in the environment like trees, pole, etc.
2.) Vehicles: It contains the vehicle positions, their velocities and information about the collision.
3.) Traffic Lights: It contains the information where the traffic lights will be and how will they react at different time frame.
4.) Environment: It contains the information about the weather, from which the confounders can be easily added.
5.) Views/Cameras: It has the ability where to place the camera for recording, therefore providing the dataset with third person or bird eye view.
6.) Logging: The log of different vehicles and state of traffic lights are recorded in it. Although other things can also be included.Using the author prepares two types of dataset:
a.) Toy Dataset: It contains no confounders, agency but only causal relationship.
b.) CausalityCity: It contains confounders, agency and also causal relationship.
-
-
Driver-centric Risk Object Identification
-
Maheep's Notes
The work proposes to preapre the dataset for identifying risk objects using the Intention and Response of the driver, where a model is deployed to match the response prediction from the driver prediction. The author implements by having the modules ofPerception, which represents different embeddings of the objects present, Comprehension which evaluates the interaction between the driver and thing or stuff using the Ego-Thing Graph and Ego-Stuff Graph, where Ego-Thing Graph have the embedding of how the driver react with the things such as the car, person, bicycle and the Ego-Stuff Graph have the embedding of how the driver reacts with the Stuff in the envionment such as roads, footpath, and Traffic Sign. The last module is of Projection which is used to predict the future forecasts.
The Causal reasoning module is added to the model so as to augment the data only in "GO" scenarion, i.e. no risk objects are present to remove the non-causal features by randomly selecting top k ransdom objects. It is also used in "STOP" scenarios, to identify the risk object identification by using the same intervention maethod of inpainting. The "GO" score is computed by removing the different object and the one object with removal that gives the highest "GO" score is identified as the risk object.
-
-
Dependent Multi-Task Learning with Causal Intervention for Image Captioning
-
Maheep's Notes
The work proposes to enhance the capability of Image Captioning systems by creating the content consistency to have non-contradicting views and provide informative information. The author implements it by eradicating the counfounder, cutting the link between the visual features and possible confounders. This is done by introducing a mediatormand the proxy confoundercto eradicate the real confounderz_c. In these type of systems it is to be considered that the mediator is not affected by the counfounder after the intervention.
-
-
Structure by Architecture: Disentangled Representations without Regularization
-
Maheep's Notes
The work focuses on the problem of self-supervised structured representation learning using autoencoders for generative modeling. The author proposes the structural autoencoder architecture inspired by structural causal models, which orders information in the latent space, while also, encourages independence. Notably, it does so without additional loss terms or regularization. The SAE architec- ture produces high quality reconstructions and generated samples, improving extrapolation, as well as achieving a significant degree of disentanglement across a variety of datasets.
-
-
EXTRACTING CAUSAL VISUAL FEATURES FOR LIMITED LABEL CLASSIFICATION
-
Maheep's Notes
The work focuses to extract causal featuresC, separating them from context featuresBwhile computed from Grad-CAM using the Huffman encoding which increases the performance by 3% in terms of accuracy and also retains 15% less size in bit size.
The author implements it by arguing that given the just featuresG = C U Bare given. By taking the analogy of the sets given below, the author extractsBas given in the following equations below:
C_p = G_p - B_p,.....................(1) i.e. for predicitonp
B_p = C_(p,q) - C_(bar(p),bar(q)) - C_(bar(p),p)...................(2)
which denotes the following things:
C_(p,q): "Why p or q?"
C_(bar(p),bar(q)): "Why neither P nor Q"
C_(bar(p),p): "Why not P with 100% confidence?"Therefore (1) can be eaily be obtained after substituting the value of (2) in it.
-
-
ALIGN-DEFORM-SUBTRACT: AN INTERVENTIONAL FRAMEWORK FOR EXPLAINING OBJECT DIFFERENCES
-
Maheep's Notes
The work focuses to define the differences betwen the objects by intervening on the image of the source objectX_sconverting into the target object imageX_t, by modifying it and quantifying the parameters via changing it's affnity by changing the scalings, translation∆tand in-plane rotation∆θ. Shape acts as the second parameter by which the image is changed. The transformation takes place in the same order as if shape is changed before that it will also have the effect of changing the pose of the image. Subtract act as the third module to change the image via removing the background using a segmentaion model to see the apperance difference using MSE.
-
-
Translational Lung Imaging Analysis Through Disentangled Representations
-
Maheep's Notes
The work focuses on retrieving relevant information from the images of inter-species pathological processes by proposing the following features:
1.) able to infer the animal model, position, damage present and generate a mask covering the whole lung.
2.) Generate realistic lung images
3.) Generate counterfactual images, i.e. healthy versions of damaged input slice.
The author implements it by considering 3 factors for generating and masking the image, namely: animal model,
A, the realtive position of axial slice,Sand estimated lung damage,Mtb, via the hierarchy at different resolution scalesk. By using the Noveau VAE to extract the latent spacezvariables to generate the maskyand imagex.
-
-
CRAFT: A Benchmark for Causal Reasoning About Forces and inTeractions
-
Maheep's Notes
The work proposes a dataset named CRAFT visual question answering dataset that requires causal reasoning about physical forces and object interactions. It contains three question categories, namely:
1.) Descriptive Questions : It requires extracting the attributes of objects, especially those involving counting, need temporal analysis as well
2.) Counterfactual Questions : It requires understanding what would happen if one of the objects was removed from the scene. For ex: “Will the small gray circle enter the basket if any of the other objects are removed?”
3.) Causal Questions : It involves understanding the causal interactions between objects whether the object is causing, enabling, or preventing it.
-
-
Explanatory Paradigms in Neural Networks
-
Maheep's Notes
The work present a study on explainability in Neural Networks. The author explores the Observed Explanatory Paradigms through reasoning especially theAbductive Reasoning from the three reasoning methods, including Deductive Reasoning and Inductive Reasoning. The author explains the Abductive Reasoning hypothesises to support a prediction and if seen abstractly defines it into three major fields, explained clearly by taking manifold into the picture, dealing with:
1.) Observed Correlation: It majorly deals with the question Why P?, where P is a class. The goal here is find all the dimensions of the manifold, denoted byT_ffrom the constructerd manifold, denoted byTthat justifies the class P classification from the network, denoted byM_cu(.)
2.) Observed Counterfactual: It majorly deals with the counterfactual question, i.e. What if not P?. It deals with interventions so as to change the direction of some of the dimensions by intervention usingdo(.)calculus to indetify the most non-trivial features a specific attribute of P denoted byM_cf(.)
3.) Observed Contrastive Explanations: It majorly deals with the counterfactual question, i.e. What P rathre than Q?. It deals with interventions so as to change the direction of some of the dimensions to chenge the prediciton of network fromPtoQ, to identify the most non-trivial features separating class from P and Q denoted byM_ct(.)
The authors discusses Probabalistic Components of Explanations that can take into consideration the questions defined above and make explanation more substatial by:
M_c(x) = M_cu(x) + M_ct(x) + M_cf(x)
Besides this the author discusses about the Contrast-CAM, Counterfactual-CAM, Grad-CAM technique which is generally used for observing Observed Correlations. The Counterfactual-CAM is used for Observed Counterfactual negates the gradient to decrease the effect of the predicted class resulting in highlighted regions in case when the object used to make the decision were not present intially. The Contrast-CAM is used for third scenario of Observed Contrastive Explanations where a loss between class P and Q is constructed to backpropogate it and find contrastive features.
-
-
A Closer Look at Debiased Temporal Sentence Grounding in Videos: Dataset, Metric, and Approach
-
Maheep's Notes
The work focuses on Temporal Sentence Grounding in Videos, where SOTA models are being proposed but harness correlated features to increase the accuracy as tested by the author by creating a new dataset via merging two datasets and making the test data out of OOD examples. The author also argues on the metrics used by the previous works to get to optimal performance as the traditional metrics often fails when dataset contains over-long ground-truth moments get hit especialy with the small IOU threshold. Therefore the author proposes a new metric, i.e. *dR@n, IOU@m* that takes temporal distances between the predicted moments and ground-truth. To de-confound the network they propose to cut the different confounders effects on the label using the backdoor method and also to get the good/robust feature on language they exploit a semantic role labeling toolkit to parse the sentence into a three-layer semantic role tree, and a more fine-grained sentence feature is obtained by adopting hierarchical attention mechanism on the tree. For visual information, in order to discriminate video moments and distinguish different temporal relationships, a reconstruction loss function is created to enhance the video moment features.
-
-
Causal Intervention for Subject-deconfounded Facial Action Unit Recognition
-
Maheep's Notes
The work focuses on Facial expressions and the confounging factors that come due to individual's subject particular a slight variant in style to express an expression. The author solves this problem with a very unique method by taking into account the **Action Unit**, i.e. different sub-parts or muscles in a face where an individual may have some other mucles also getting activated than the muscles that are universal for that expression. The author proposes a model-agnostic system that not only considers the low-level facial-appearance features but also high level semantics relations among Action Units as they depend upon each other. The author builds and SCM by proposing 4 varibales, i.e. ImageX, Subject(Confounder) S, Latent Representation R and output Y, where the author eradicates the effect of S on X. The author implements it by having three modules:
1.) Attention Module: It takes the attention of the extracted feature and the different AU for each Subject which are computed by taking the average of all the samples of the Subject, denoted bys_i
2.) Memory Module: It consists_ias defined above
3.) Confounder Priors: It consist of the sample distribution of differents_iby taking the number of (samples in that subject)/(total samples)
-
-
Causal Scene BERT: Improving object detection by searching for challenging groups of data
-
Maheep's Notes
The work is based on the rare scenarios that occur in the self-driving where the model is built and then when it fails for a group, the dataset is collected, annotated and the model is trained on that, which is a very time-consuming and risky process. The author proposes to identify these groups during the training of the model such as specificweather patterns, Vehicle types and Vehicle positioning. The author harnesses the Simulation and MLM(Masked Language Model) to apply causal intervention so as to generate counterfactual scenarios while MLM, acts as a Denoising Autoencoder to generate data near true distribution. The different tokens represent different groups such as weather, agent asset, rotations, etc. and are masked to generate counterfactual image. The author uses the score function
f(phi, I, L)wherephiis the model,Iis the image andLis the label. The score function is used to identify the vulnerable groups using therhofunction:
rho=f(phi, I', L')-f(phi, I, L)
if|rho| >= t, wheretis the threshold, which defines if therhois very negative or positive then the modified group is vulnerable.
-







