immudb 




![]()



Don't forget to ⭐ this repo if you like immudb!
Detailed documentation can be found at https://docs.immudb.io/

immudb is a database with built-in cryptographic proof and verification. It tracks changes in sensitive data and the integrity of the history will be protected by the clients, without the need to trust the database. It can operate both as a key-value store, and/or as relational database (SQL).
Traditional database transactions and logs are mutable, and therefore there is no way to know for sure if your data has been compromised. immudb is immutable. You can add new versions of existing records, but never change or delete records. This lets you store critical data without fear of it being tampered.
Data stored in immudb is cryptographically coherent and verifiable. Unlike blockchains, immudb can handle millions of transactions per second, and can be used both as a lightweight service or embedded in your application as a library. immudb runs everywhere, on an IoT device, your notebook, a server, on-premise or in the cloud.
immudb can be used as a key-value store or relational data structure and supports both transactions and blobs, so there are no limits to the use cases. Companies use immudb to secure and tamper-evident log data, sensor data, sensitive data, transactions, software build recipes, rule-base data, even artifacts and even video streams. Examples of organizations using immudb today.
Online demo environment
Click here to try out the immudb web console access in an online demo environment (username: immudb; password: immudb)
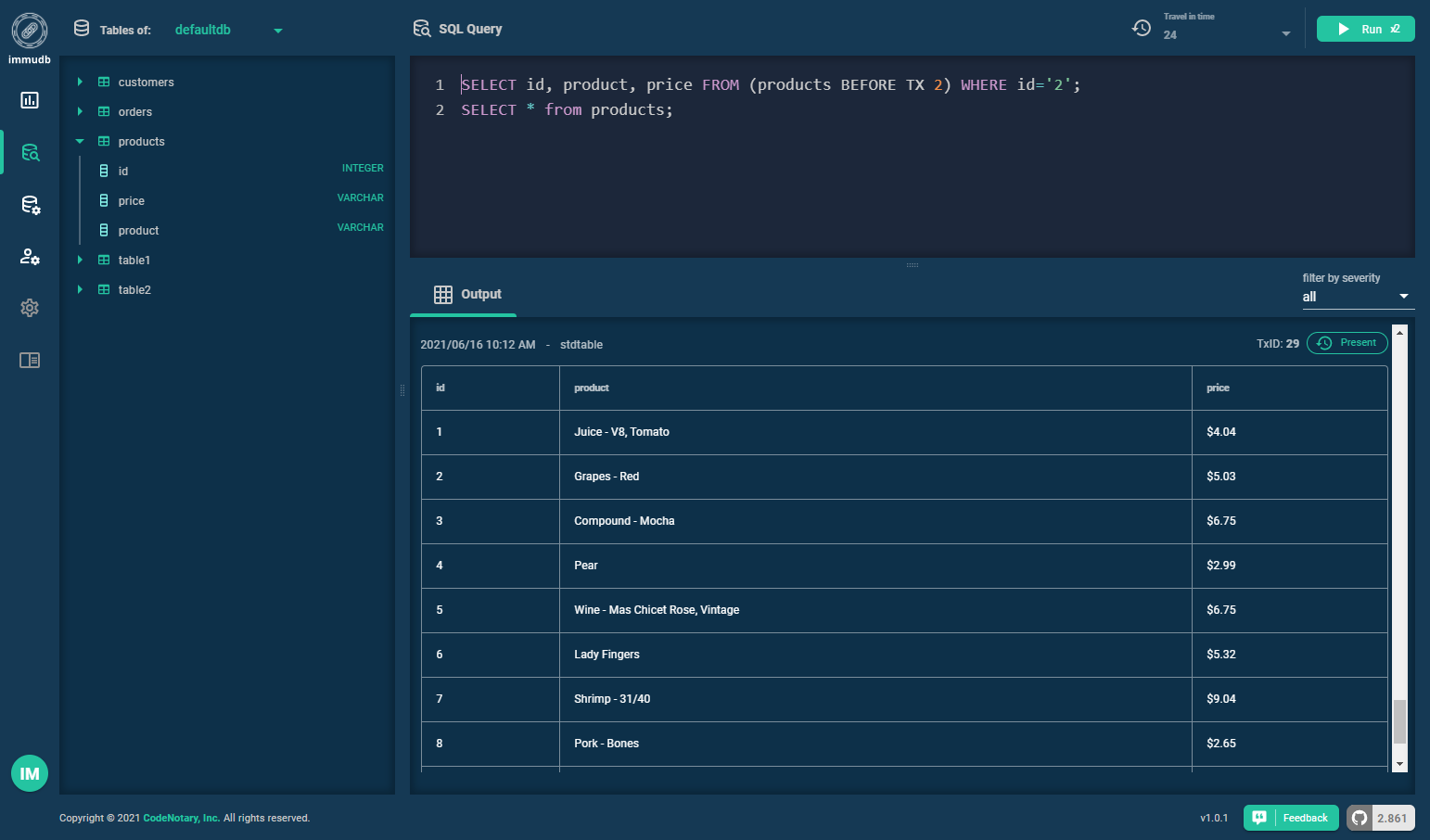
Some immudb tech specs
| Topic | Description |
|---|---|
| DB Model | Key-Value store with 3D access (tx-key-value), SQL |
| Data scheme | schema-free |
| Implementation design | Cryptographic commit log with parallel Merkle Tree, |
| (sync/async) indexing with extended B-tree | |
| Implementation language | Go |
| Server OS(s) | BSD, Linux, OS X, Solaris, Windows, IBM z/OS |
| Embeddable | Yes, optionally |
| Server APIs | gRPC |
| Partition methods | Sharding |
| Consistency concepts | Immediate Consistency |
| Transaction concepts | ACID with Snapshot Isolation (SSI) |
| Durability | Yes |
| Snapshots | Yes |
| High Read throughput | Yes |
| High Write throughput | Yes |
| Optimized for SSD | Yes |
Quickstart
Getting immudb running: executable
You may download the immudb binary from the latest releases on Github. Once you have downloaded immudb, rename it to immudb, make sure to mark it as executable, then run it. The following example shows how to obtain v1.5.0 for linux amd64:
wget https://github.com/codenotary/immudb/releases/download/v1.5.0/immudb-v1.5.0-linux-amd64
mv immudb-v1.5.0-linux-amd64 immudb
chmod +x immudb
# run immudb in the foreground to see all output
./immudb
# or run immudb in the background
./immudb -dGetting immudb running: Docker
Use Docker to run immudb in a ready-to-use container:
docker run -d --net host -it --rm --name immudb codenotary/immudb:latestIf you are running the Docker image without host networking, make sure to expose ports 3322 and 9497.
Getting immudb running: Kubernetes
In kubernetes, use helm for an easy deployment: just add our repository and install immudb with these simple commands:
helm repo add immudb https://packages.codenotary.org/helm
helm repo update
helm install immudb/immudb --generate-nameUsing subfolders
Immudb helm chart creates a persistent volume for storing immudb database. Those database are now by default placed in a subdirectory.
That's for compatibility with ext4 volumes that have a /lost+found directory that can confuse immudb. Some volume providers,
like EBS or DigitalOcean, are using this kind of volumes. If we placed database directory on the root of the volume,
that /lost+found would be treated as a database. So we now create a subpath (usually immudb) subpath for storing that.
This is different from what we did on older (<=1.3.1) helm charts, so if you have already some volumes with data you can set
value volumeSubPath to false (i.e.: --set volumeSubPath.enabled=false) when upgrading so that the old way is used.
You can alternatively migrate the data in a /immudb directory. You can use this pod as a reference for the job:
apiVersion: v1
kind: Pod
metadata:
name: migrator
spec:
volumes:
- name: "vol0"
persistentVolumeClaim:
claimName: <your-claim-name-here>
containers:
- name: migrator
image: busybox
volumeMounts:
- mountPath: "/data"
name: "vol0"
command:
- sh
- -c
- |
mkdir -p /data/immudb
ls /data | grep -v -E 'immudb|lost\+found'|while read i; do mv /data/$i /data/immudb/$i; doneAs said before, you can totally disable the use of subPath by setting volumeSubPath.enabled=false.
You can also tune the subfolder path using volumeSubPath.path value, if you prefer your data on a
different directory than the default immudb.
Enabling Amazon S3 storage
immudb can store its data in the Amazon S3 service (or a compatible alternative). The following example shows how to run immudb with the S3 storage enabled:
export IMMUDB_S3_STORAGE=true
export IMMUDB_S3_ACCESS_KEY_ID=<S3 ACCESS KEY ID>
export IMMUDB_S3_SECRET_KEY=<SECRET KEY>
export IMMUDB_S3_BUCKET_NAME=<BUCKET NAME>
export IMMUDB_S3_LOCATION=<AWS S3 REGION>
export IMMUDB_S3_PATH_PREFIX=testing-001
export IMMUDB_S3_ENDPOINT="https://${IMMUDB_S3_BUCKET_NAME}.s3.${IMMUDB_S3_LOCATION}.amazonaws.com"
./immudbWhen working with the external storage, you can enable the option for the remote storage to be the primary source of identifier. This way, if immudb is run using ephemeral disks, such as with AWS ECS Fargate, the identifier can be taken from S3. To enable that, use:
export IMMUDB_S3_EXTERNAL_IDENTIFIER=trueYou can also easily use immudb with compatible s3 alternatives such as the minio server:
export IMMUDB_S3_ACCESS_KEY_ID=minioadmin
export IMMUDB_S3_SECRET_KEY=minioadmin
export IMMUDB_S3_STORAGE=true
export IMMUDB_S3_BUCKET_NAME=immudb-bucket
export IMMUDB_S3_PATH_PREFIX=testing-001
export IMMUDB_S3_ENDPOINT="http://localhost:9000"
# Note: This spawns a temporary minio server without data persistence
docker run -d -p 9000:9000 minio/minio server /data
# Create the bucket - this can also be done through web console at http://localhost:9000
docker run --net=host -it --entrypoint /bin/sh minio/mc -c "
mc alias set local http://localhost:9000 minioadmin minioadmin &&
mc mb local/${IMMUDB_S3_BUCKET_NAME}
"
# Run immudb instance
./immudbConnecting with immuclient
You may download the immuclient binary from the latest releases on Github. Once you have downloaded immuclient, rename it to immuclient, make sure to mark it as executable, then run it. The following example shows how to obtain v1.5.0 for linux amd64:
wget https://github.com/codenotary/immudb/releases/download/v1.5.0/immuclient-v1.5.0-linux-amd64
mv immuclient-v1.5.0-linux-amd64 immuclient
chmod +x immuclient
# start the interactive shell
./immuclient
# or use commands directly
./immuclient helpOr just use Docker to run immuclient in a ready-to-use container. Nice and simple.
docker run -it --rm --net host --name immuclient codenotary/immuclient:latestUsing immudb
Lot of useful documentation and step by step guides can be found at https://docs.immudb.io/
Real world examples
We already learned about the following use cases from users:
- use immudb to immutably store every update to sensitive database fields (credit card or bank account data) of an existing application database
- store CI/CD recipes in immudb to protect build and deployment pipelines
- store public certificates in immudb
- use immudb as an additional hash storage for digital objects checksums
- store log streams (i. e. audit logs) tamperproof
- store the last known positions of submarines
- record the location where fish was found aboard fishing trawlers
How to integrate immudb in your application
We have SDKs available for the following programming languages:
- Java immudb4j
- Golang (golang sdk, Gorm adapter)
- .net immudb4dotnet
- Python immudb-py
- Node.js immudb-node
To get started with development, there is a quickstart in our documentation: or pick a basic running sample from immudb-client-examples.
Our immudb Playground provides a guided environment to learn the Python SDK.
We've developed a "language-agnostic SDK" which exposes a REST API for easy consumption by any application. immugw may be a convenient tool when SDKs are not available for the programming language you're using, for experimentation, or just because you prefer your app only uses REST endpoints.
Performance figures
immudb can handle millions of writes per second. The following table shows performance of the embedded store inserting 1M entries on a machine with 4-core E3-1275v6 CPU and SSD disk:
| Entries | Workers | Batch | Batches | time (s) | Entries/s |
|---|---|---|---|---|---|
| 1M | 20 | 1000 | 50 | 1.061 | 1.2M /s |
| 1M | 50 | 1000 | 20 | 0.543 | 1.8M /s |
| 1M | 100 | 1000 | 10 | 0.615 | 1.6M /s |
You can generate your own benchmarks using the stress_tool under embedded/tools.
Roadmap
The following topics are important to us and are planned or already being worked on:
- Data pruning
- Compression
- compatibility with other database storage files
- Easier API for developers
- API compatibility with other, well-known embedded databases
Contributing
We welcome contributors. Feel free to join the team!
Learn how to build immudb components in both binary and Docker image form.
To report bugs or get help, use GitHub's issues.
immudb is licensed under the Apache v2.0 License.
immudb re-distributes other open-source tools and libraries - Acknowledgements.