Click here to visit the website of the event.
This repository contains the news media & respiratory diseases dataset as part of one of the challenges of the Eitri Medical Datathon 2022.
It contains data but also scripts to expand the dataset.
Clone this repository :
git clone https://github.com/AdrienC21/eitridatathon2022_media.gitOr download the files manually.
All files are located inside the folder datasets.
msis_data.csv
Daily data for different diseases in Norway (at the national level) such as respiratory diseases. Source: MSIS.
IMPORTANT: Data can be obtained at the regional level, can be stratified by gender, age group and/or place of infection. We can also extract data from 1976 (instead of 2010). If needed, please ask a mentor to retrieve such data automatically.
NOR.csv
Daily COVID data at the national level (cases, deaths, vaccines, school closing, etc).
covid_cases_regions_norway.csv
Daily COVID cases data at the kommune level in Norway. The fylke of each kommune is also indicated. Extracted from John Hopkins University database.
New Media Cloud and GoogleTrends data can be downloaded using the scripts generate_mediacloud.py and generate_googletrends.py, located inside the folder datasets.
You can find a list of countries in the excel files collections_country.csv (worldwide) and norway_collections.csv (specific for Norway).
Before running the scripts:
-
To fetch data for specific keywords, modify the keyword list in the file keywords.csv.
-
Change the configuration file
config.py(instructions below)
config.py allows one to change the list of countries, the timeframe, and the keywords for data retrieval.
IMPORTANT: If you need help to extract Media Cloud and Google Trends data, please call a mentor.
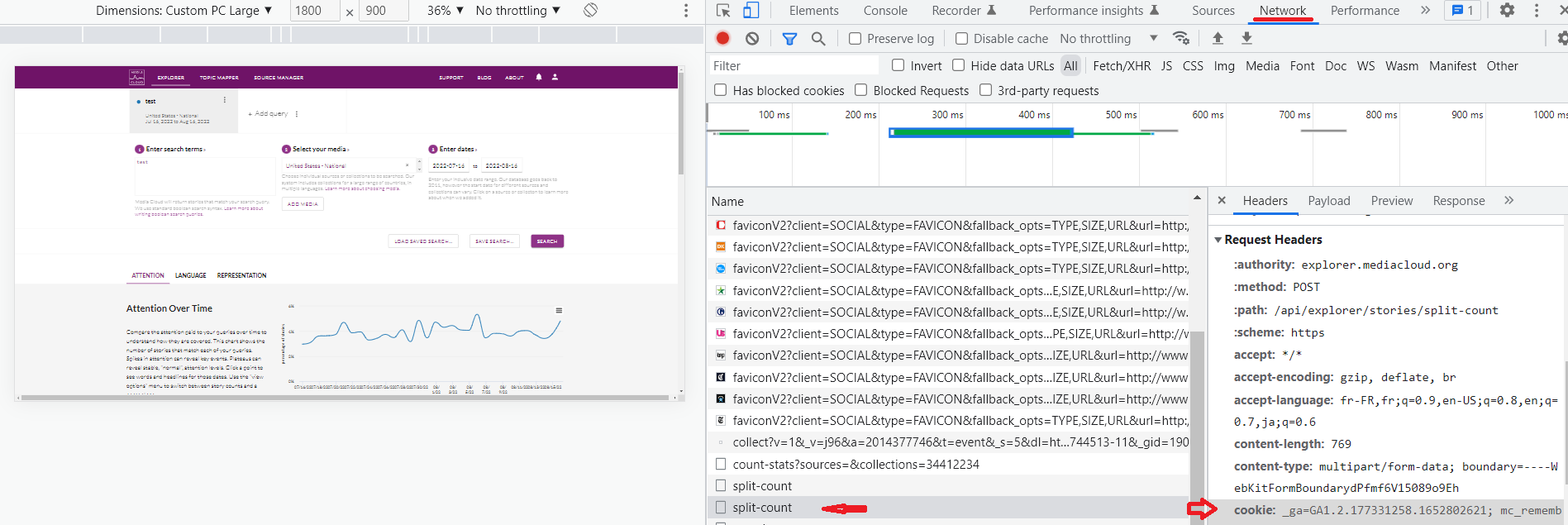
For Media Cloud data, the dictionnary entitled login_info needs to be modified. To do so, connect to your Media Cloud account and open the Explorer tool. Inspect the webpage and go to the Network tab. After making a query, click on split-count. On the right, in Request Headers and cookie, retrieve the mc_remember_token and mc_session values and insert them into config.py.
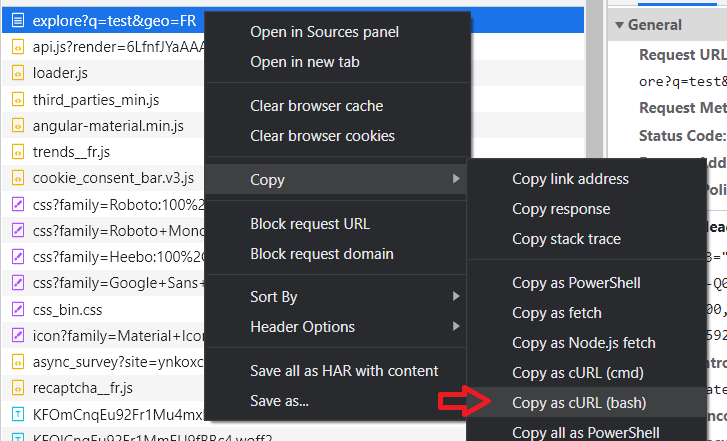
For Google Trends data, the header dictionnary must be updated. First, visit the Google Trends website, inspect the webpage and go to the Network tab. After making a query, right click on explore, and click on Copy as cURL (bash). Convert the command into a Python request using curlconverter. Retrieve only the header dictionnary.
collections_country.csv
Contains the Media Cloud collection ids and the Google trends ISO codes of almost all the countries in the world.
norway.csv
Raw list of Media Cloud collection id for all regions in Norway.
norway_collections.csv
List of Media Cloud collection id for all regions in Norway & collection id for the national level.
fylke.csv
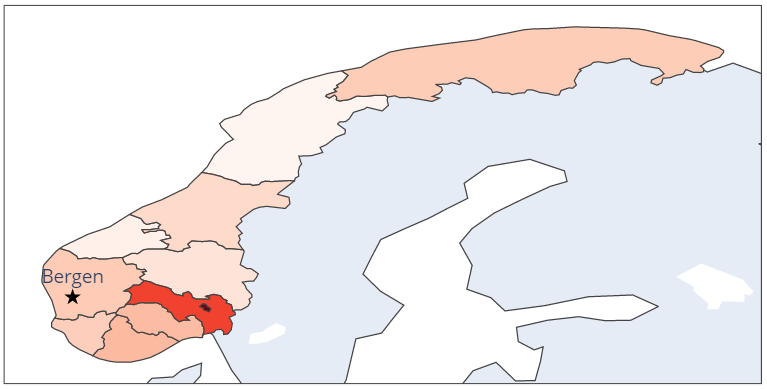
Map each counties in Norway to the corresponding fylke (county after 1 January 2020). Source.
fylker_komprimert.csv
Geojson file with the boundaries of each county. Useful to plot choropleth map (an exemple of such plot is provided in the workshop: Leveraging Non-traditional Sources of Data).
Below is an example of plot that can be made using this file: