- 面向篇章级文档的细粒度知识模型自动构建技术
- 研究概念类型、复杂关系类型、属性结构等细粒知识结构的自动构建技术, 形成篇章级知识模型
- 研究篇章级文档中人物、组织、事件等核心概念间的上下位关系、整体与部分关系、时空关系等细粒度关联。
- 概念层次
3层 ACC>80%
- 目前没有找到领域概念体系自动构建的端到端方法(即直接从文本构建出对应的上下位关系、整体与部分关系、时空关系等)。
- 可以把概念体系构建的整个流程可以分为两个阶段:
- 领域概念抽取
- 概念领域上下位关系的检测
- 输入:文本语料
- 输出:领域概念集合
主要分为基于无监督的领域概念抽取和基于有监督的领域概念抽取,大部分是某领域的概念抽取,并且要带标签的数据,对本工作较为有帮助的部分工作如下:
- Shvets, Alexander, 和Leo Wanner. 《Concept Extraction Using Pointer–Generator Networks and Distant Supervision for Data Augmentation》. 收入 Knowledge Engineering and Knowledge Management, 编辑 C. Maria Keet和Michel Dumontier, 120–35. Cham: Springer International Publishing, 2020. https://doi.org/10.1007/978-3-030-61244-3_8.
- Zhang, Xiao, Dejing Dou和Ji Wu. 《Learning Conceptual-Contextual Embeddings for Medical Text》. Proceedings of the AAAI Conference on Artificial Intelligence 34, 期 05 (2020年4月3日): 9579–86. https://doi.org/10.1609/aaai.v34i05.6504.
- Zhu, Henghui, Ioannis Ch Paschalidis和Amir Tahmasebi. 《Clinical Concept Extraction with Contextual Word Embedding》. arXiv, 2018年11月26日. https://doi.org/10.48550/arXiv.1810.10566.
准备分小模型和大模型两条线进行
ICLR 2023的一篇工作指出大语言模型(文中用的ChatGPT)对抽象概念的理解非常差,如何mitigate gap是一个有研究意义的方向(Camacho-Collados, Jose, Claudio Delli Bovi, Luis Espinosa Anke, Sergio Oramas, Tommaso Pasini, Enrico Santus, Vered Shwartz, Roberto Navigli和Horacio Saggion. 《SemEval-2018 Task 9: Hypernym Discovery》. 收入 Proceedings of The 12th International Workshop on Semantic Evaluation, 712–24. New Orleans, Louisiana: Association for Computational Linguistics, 2018. https://doi.org/10.18653/v1/S18-1115.)

- 没找到直接用大模型直接抽取领域概念的工作(哪怕是
Prompt Based的) - 小模型有一些相关工作可以借鉴
-
目前已经完成了
Shvets, A. and Wanner, L. 2020. Concept Extraction Using Pointer-Generator Networks and Distant Supervision for Data Augmentation. In International Conference on Knowledge Engineering and Knowledge Management. Springer, Cham.这篇工作的复现- 该工作能对通用领域的语料进行概念抽取,并且在大规模开放数据集上相较于其他通用领域概念抽取模型有所优势
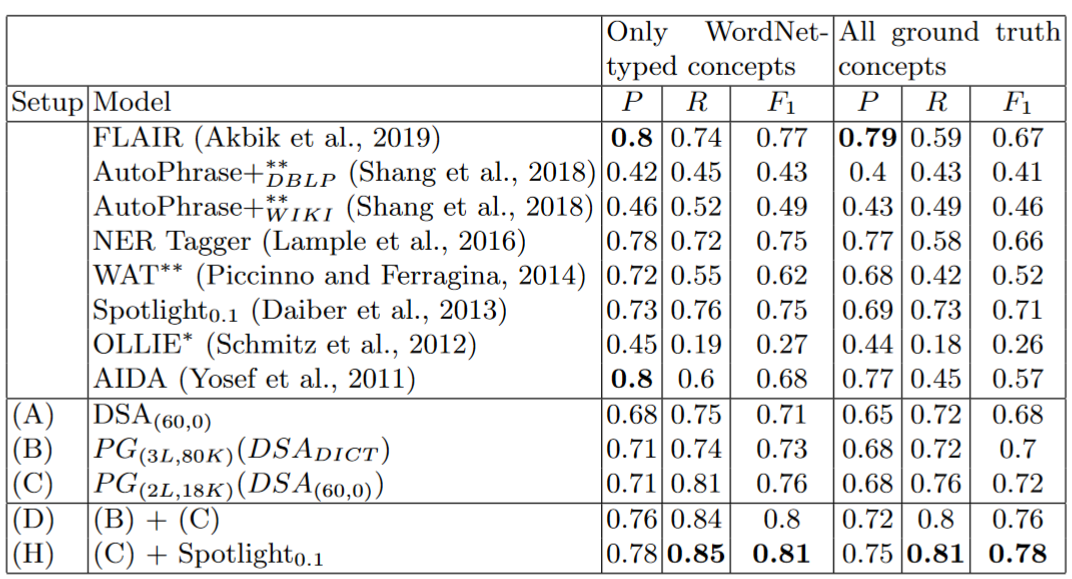
-
eg1.
- 输入:
China,[j] officially the People's Republic of China (PRC),[k] is a country in East Asia. With a population exceeding 1.4 billion, it is the world's second-most populous country. China spans the equivalent of five time zones and borders fourteen countries by land.[l] With an area of nearly 9.6 million square kilometers (3,700,000 sq mi), it is the third-largest country by total land area.[m] The country is divided into 33[n] province-level divisions,[o] inclusive of 22 provinces,[o] five autonomous regions, four municipalities, and two semi-autonomous special administrative regions. Beijing is the national capital, while Shanghai is its most populous city and largest financial center. - 输出:
[{"concept": "China", "postags": "NNP", "begin": 0, "end": 5, "type": "NOUN", "next_tag": ",", "next_word": ",", "sent_id": 0, "text_id": 0}, {"concept": "j", "postags": "NN", "begin": 7, "end": 8, "type": "NOUN", "next_tag": "NNP", "next_word": "]", "sent_id": 0, "text_id": 0}, {"concept": "People 's Republic of China", "postags": "NNP POS NNP IN NNP", "begin": 25, "end": 51, "type": "NOUN", "next_tag": "(", "next_word": "(", "sent_id": 0, "text_id": 0}, {"concept": "PRC", "postags": "NNP", "begin": 53, "end": 56, "type": "NOUN", "next_tag": ")", "next_word": ")", "sent_id": 0, "text_id": 0}, {"concept": "k", "postags": "NN", "begin": 59, "end": 60, "type": "NOUN", "next_tag": "NNP", "next_word": "]", "sent_id": 0, "text_id": 0}, {"concept": "country", "postags": "NN", "begin": 67, "end": 74, "type": "NOUN", "next_tag": "IN", "next_word": "in", "sent_id": 0, "text_id": 0}, {"concept": "East Asia", "postags": "NNP NNP", "begin": 78, "end": 87, "type": "NOUN", "next_tag": ".", "next_word": ".", "sent_id": 0, "text_id": 0}, {"concept": "population", "postags": "NN", "begin": 96, "end": 106, "type": "NOUN", "next_tag": "VBG", "next_word": "exceeding", "sent_id": 1, "text_id": 0}, {"concept": "1.4 billion", "postags": "CD CD", "begin": 117, "end": 128, "type": "NOUN", "next_tag": ",", "next_word": ",", "sent_id": 1, "text_id": 0}, {"concept": "world", "postags": "NN", "begin": 140, "end": 145, "type": "NOUN", "next_tag": "POS", "next_word": "'s", "sent_id": 1, "text_id": 0}, {"concept": "populous country", "postags": "JJ NN", "begin": 160, "end": 176, "type": "NOUN", "next_tag": ".", "next_word": ".", "sent_id": 1, "text_id": 0}, {"concept": "China", "postags": "NNP", "begin": 178, "end": 183, "type": "NOUN", "next_tag": "VBZ", "next_word": "spans", "sent_id": 2, "text_id": 0}, {"concept": "equivalent", "postags": "NN", "begin": 194, "end": 204, "type": "NOUN", "next_tag": "IN", "next_word": "of", "sent_id": 2, "text_id": 0}, {"concept": "five", "postags": "CD", "begin": 208, "end": 212, "type": "NOUN", "next_tag": "NN", "next_word": "time", "sent_id": 2, "text_id": 0}, {"concept": "time zones", "postags": "NN NNS", "begin": 213, "end": 223, "type": "NOUN", "next_tag": "CC", "next_word": "and", "sent_id": 2, "text_id": 0}, {"concept": "borders", "postags": "NNS", "begin": 228, "end": 235, "type": "NOUN", "next_tag": "JJ", "next_word": "fourteen", "sent_id": 2, "text_id": 0}, {"concept": "countries", "postags": "NNS", "begin": 245, "end": 254, "type": "NOUN", "next_tag": "IN", "next_word": "by", "sent_id": 2, "text_id": 0}, {"concept": "land", "postags": "NN", "begin": 258, "end": 262, "type": "NOUN", "next_tag": ".", "next_word": ".", "sent_id": 2, "text_id": 0}, {"concept": "l", "postags": "NN", "begin": 264, "end": 265, "type": "NOUN", "next_tag": "NN", "next_word": "]", "sent_id": 3, "text_id": 0}, {"concept": "area", "postags": "NN", "begin": 275, "end": 279, "type": "NOUN", "next_tag": "IN", "next_word": "of", "sent_id": 3, "text_id": 0}, {"concept": "nearly 9.6 million square kilometers", "postags": "RB CD CD JJ NNS", "begin": 283, "end": 319, "type": "NOUN", "next_tag": "(", "next_word": "(", "sent_id": 3, "text_id": 0}, {"concept": "3,700,000", "postags": "CD", "begin": 321, "end": 330, "type": "NOUN", "next_tag": "NN", "next_word": "sq", "sent_id": 3, "text_id": 0}, {"concept": "sq", "postags": "NN", "begin": 331, "end": 333, "type": "NOUN", "next_tag": "NN", "next_word": "mi", "sent_id": 3, "text_id": 0}, {"concept": "mi", "postags": "NN", "begin": 334, "end": 336, "type": "NOUN", "next_tag": ")", "next_word": ")", "sent_id": 3, "text_id": 0}, {"concept": "country", "postags": "NN", "begin": 363, "end": 370, "type": "NOUN", "next_tag": "IN", "next_word": "by", "sent_id": 3, "text_id": 0}, {"concept": "total land area", "postags": "JJ NN NN", "begin": 374, "end": 389, "type": "NOUN", "next_tag": ".", "next_word": ".", "sent_id": 3, "text_id": 0}, {"concept": "m", "postags": "NN", "begin": 391, "end": 392, "type": "NOUN", "next_tag": "IN", "next_word": "]
- 输入:
-
该工作在能够提取出文本中的一些概念,比如
country、polulation、borders、land、area、autonomous regions等,但是提取的有些概念虽然被视作概念 ,但是与主题无关,无法加入到该知识概念体系构建中,所以这部分概念不应该输入到上下位关系的检测中。 -
该模型提取的概念相对比较保守,不会有大模型容易出现的离谱的输出
-
后续可以探索小模型与大模型结合的方式,如用小模型对概念进行初步提取,再输入给大模型,相当于给大模型提供一个可选的列表,保证大模型不会出现离谱操作
-
目前选用的模型是
Qwen(https://github.com/QwenLM/Qwen),该模型中英文能力较为均衡,原生支持`QLoRA`、`LoRA`、`Int8量化`等,并且近期有些特定领域模型也是以该模型为基座模型进行构建的(如明医 (MING)中文医疗问诊大模型 (https://github.com/MediaBrain-SJTU/MING)) -
目前部署情况
- Qwen-7B
- 3卡3090可以部署
- Qwen-14B
- 3卡3090可以部署
- Qwen-7B
-
eg1.
- ChatGPT4
-
- Qwen-14B
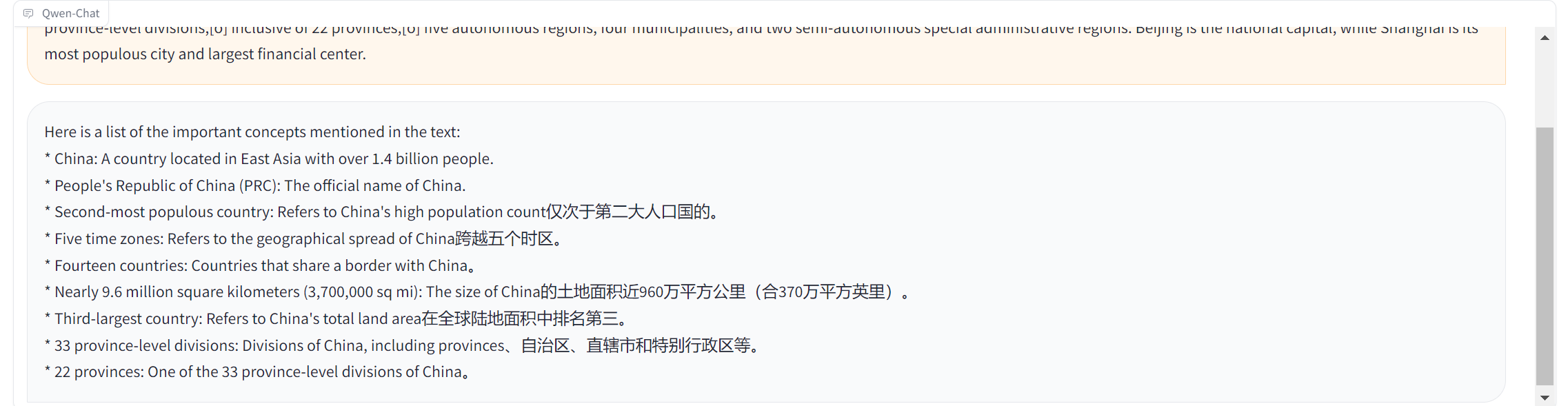
- 模型更容易去关注细节,并没有正确地抽取概念,并且没有按照要求格式返回概念
- ChatGPT4
-
eg2.
- 尝试让ChatGPT4和Qwen-14B去抽取以下维基百科条目中的概念,结果也非常差
-
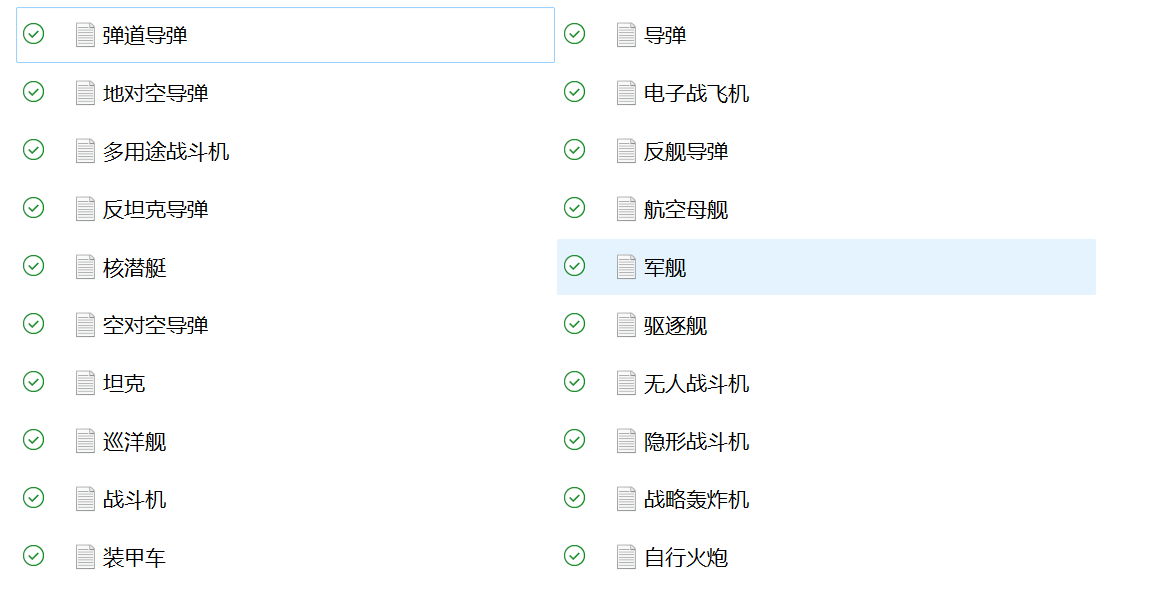
- 大模型对概念的理解似乎很差
-
之后尝试让小模型先初筛,把初筛的结果给大模型选,避免大模型出现类似的回答




- 输入:根据文本构造好的概念集合或概念对
- 输出:上下位关系
- 基于模版
- Held, William, 和Nizar Habash. 《The Effectiveness of Simple Hybrid Systems for Hypernym Discovery》. 收入 Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 编辑 Anna Korhonen, David Traum和Lluís Màrquez, 3362–67. Florence, Italy: Association for Computational Linguistics, 2019. https://doi.org/10.18653/v1/P19-1327.
- Le, Matt, Stephen Roller, Laetitia Papaxanthos, Douwe Kiela和Maximilian Nickel. 《Inferring Concept Hierarchies from Text Corpora via Hyperbolic Embeddings》. arXiv, 2019年2月3日. https://doi.org/10.48550/arXiv.1902.00913.
- Roller, Stephen, Douwe Kiela和Maximilian Nickel. 《Hearst Patterns Revisited: Automatic Hypernym Detection from Large Text Corpora》. arXiv, 2018年6月8日. https://doi.org/10.48550/arXiv.1806.03191.
- Shi, Yu, Jiaming Shen, Yuchen Li, Naijing Zhang, Xinwei He, Zhengzhi Lou, Qi Zhu, Matthew Walker, Myunghwan Kim和Jiawei Han. 《Discovering Hypernymy in Text-Rich Heterogeneous Information Network by Exploiting Context Granularity》. 收入 Proceedings of the 28th ACM International Conference on Information and Knowledge Management, 599–608. CIKM ’19. New York, NY, USA: Association for Computing Machinery, 2019. https://doi.org/10.1145/3357384.3357866.
- Tikhomirov, Mikhail, 和Natalia Loukachevitch. 《Exploring Prompt-Based Methods for Zero-Shot Hypernym Prediction with Large Language Models》. arXiv, 2024年1月9日. https://doi.org/10.48550/arXiv.2401.04515.
- Yu, Changlong, Jialong Han, Peifeng Wang, Yangqiu Song, Hongming Zhang, Wilfred Ng和Shuming Shi. 《When Hearst Is not Enough: Improving Hypernymy Detection from Corpus with Distributional Models》. arXiv, 2020年10月10日. https://doi.org/10.48550/arXiv.2010.04941.
- 基于分布式
- Chang, Haw-Shiuan, ZiYun Wang, Luke Vilnis和Andrew McCallum. 《Distributional Inclusion Vector Embedding for Unsupervised Hypernymy Detection》. arXiv, 2018年5月29日. https://doi.org/10.48550/arXiv.1710.00880.
- Shwartz, Vered, Enrico Santus和Dominik Schlechtweg. 《Hypernyms under Siege: Linguistically-motivated Artillery for Hypernymy Detection》. arXiv, 2017年1月8日. https://doi.org/10.48550/arXiv.1612.04460.
- Wang, Chengyu, 和Xiaofeng He. 《BiRRE: Learning Bidirectional Residual Relation Embeddings for Supervised Hypernymy Detection》. 收入 Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 编辑 Dan Jurafsky, Joyce Chai, Natalie Schluter和Joel Tetreault, 3630–40. Online: Association for Computational Linguistics, 2020. https://doi.org/10.18653/v1/2020.acl-main.334.
- Yu, Changlong, Jialong Han, Peifeng Wang, Yangqiu Song, Hongming Zhang, Wilfred Ng和Shuming Shi. 《When Hearst Is not Enough: Improving Hypernymy Detection from Corpus with Distributional Models》. arXiv, 2020年10月10日. https://doi.org/10.48550/arXiv.2010.04941.
- 大模型直接Prompt, Zero-shot
- Camacho-Collados, Jose, Claudio Delli Bovi, Luis Espinosa Anke, Sergio Oramas, Tommaso Pasini, Enrico Santus, Vered Shwartz, Roberto Navigli和Horacio Saggion. 《SemEval-2018 Task 9: Hypernym Discovery》. 收入 Proceedings of The 12th International Workshop on Semantic Evaluation, 712–24. New Orleans, Louisiana: Association for Computational Linguistics, 2018. https://doi.org/10.18653/v1/S18-1115.
- Tikhomirov, Mikhail, 和Natalia Loukachevitch. 《Exploring Prompt-Based Methods for Zero-Shot Hypernym Prediction with Large Language Models》. arXiv, 2024年1月9日. https://doi.org/10.48550/arXiv.2401.04515.
- 暂时参考Meta提出的三个指标,最近很多相关工作都在用

- 目前主要尝试各种Prompt在ChatGPT4和Qwen-14B上做概念抽取和上下位关系识别
- 一个效果比较好的例子
- 输入的语料:先给模型一些上位词和下位次,让他生成语料,然后在另一个对话中让模型抽取概念,然后根据这些概念来生成上下位关系(一些研究证实大模型会对自己生成的东西更敏感)
- 目前尝试出的最好的结果
- ChatGPT4
-

-

- ChatGPT4基本上能从自己生成的语料中找出正确的上下位关系
-
- Qwen-14B


- Qwen生成的上下位关系更像是概念的组合,很多不符合逻辑关系
- 之后的计划:在概念集合构建比较准确的前提下,用
nltk中的大量的领域上下位关系来微调模型



