In this cooperative project with the bank, I integrated several state-of-the-art recommendation system algorithms to aid banks in enhancing their fund recommendation systems. I also suggested utilizing UMAP for dimensional reduction of user characteristic data and HDBSCAN for unsupervised clustering to effectively make recommendations to users even if they lack transaction records.
.
|-- .gitignore
|-- README.md
|-- data
|-- result
|-- examples
| |-- mf_example.py
| |-- clustering_example.py
| |-- explain_example.py
| `-- vaecf_example.py
|-- experience
|-- img
`-- recs
|-- __init__.py
|-- backtest.py
|-- datasets
| |-- __init__.py
| |-- base.py
| `-- preprocess.py
|-- metrics
| `-- base.py
|-- models
| |-- __init__.py
| |-- base.py
| |-- cluster
| | |-- __init__.py
| | `-- clustering.py
| |-- mf
| | |-- __init__.py
| | `-- mf.py
| `-- vaecf
| |-- __init__.py
| |-- recom_vaecf.py
| `-- vaecf.py
`-- utils
|-- __init__.py
|-- common.py
|-- config.py
`-- path.py
- 元資料結構其實已經對實驗性和使用的code進行區分
- 在
./experiments中的 ipynb 檔案即計畫過程中所進行實驗的程式碼
- 在
- 在
./examples/中有較簡便的使用示範
- df 資料格式:
user item rate USER A ITEM 1 1 USER B ITEM 2 1 USER B ITEM 3 1
-
範例程式碼
# import MF模型 from recs.models.mf import MatrixFactorization # 訓練模型 MF = MatrixFactorization(df, svds_k = 15) # 預測 u = df.user.tolist()[0] MF.rec_items(u)
-
預測結果示意圖
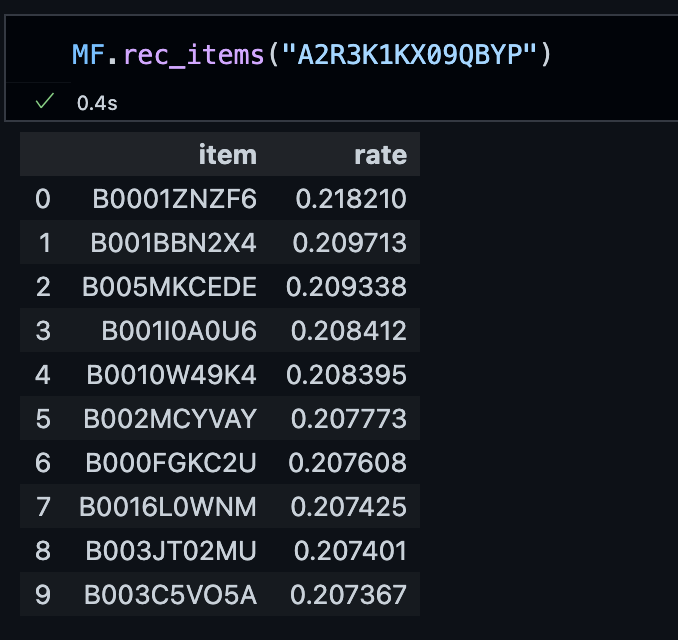

- 範例程式碼
import recs # 讀取資料給 Dataset train_set = recs.datasets.Dataset.from_uir(df.values, seed=35) # 初始化模型 vaecf = recs.models.VAECF( k=10, autoencoder_structure=[20], act_fn="tanh", # activate function likelihood="mult", # 論文提到效果最好是使用 multinomial likelihood n_epochs=30, batch_size=30, learning_rate=0.001, beta=1.0, seed=35, use_gpu=True, verbose=True, ) # 訓練 vaecf.fit(train_set) # 預測 pred = predict_ranking(vaecf, df, 'userId', 'itemId', 'rank', True)
MF與VAECF模型可調整參數細節寫在 models 資料夾各別模型中
- crm.csv
- fund_info.csv
- fund_info_web.csv
- trans_buy.csv
- crm_new.csv
- fund_crm_feature.csv
-
我方實驗所使用的前處理內容以編寫於
recs/datasets/preprocess.py中,分別以不同函式名稱對應./data/origin資料夾中的不同資料表,處理過後會產生新檔案在./data資料夾中,以下表所示:原始資料檔案路徑 處理函式名稱 產出檔案 ./data/origin/crm.csv preprocess_crm() crm.pkl ./data/origin/fund_info_web.csv preprocess_fund_web() fund_info_web.pkl ./data/origin/fund_info.csv preprocess_fund() fund_info.pkl ./data/origin/trans_buy.csv preprocess_trans_buy() trans_buy.pkl ./data/origin/crm_new.csv
./data/origin/fund_crm_feature.csvpreprocess_crm_cluster() crm_for_clustering_2020.csv :::warning 請確保執行順序一致:
- 前處理檔案順序如:
crm.csv
$\rightarrow$ fund_info_web.csv$\rightarrow$ fund.csv$\rightarrow$ crm_new.csv & fund_crm_feature.csv - 函式執行順序為:
preprocess_crm()
$\rightarrow$ preprocess_fund_web()$\rightarrow$ preprocess_fund()$\rightarrow$ preprocess_trans_buy()$\rightarrow$ preprocess_crm_cluster() :::
- 前處理檔案順序如:
crm.csv
-
或使在專案資料夾底下,開啟terminal直接執行以下指令,可一併處理完成
python -m recs.datasets.preprocess
VAE的V代表Variational,相較於原本的Autoencoder架構,其應用 Variational Inference 的理論到Autoencoder上。



- 將用戶對商品的評分紀錄,轉換成Shape 為 [用戶數量, 商品數量]的 Matrix,如下圖:
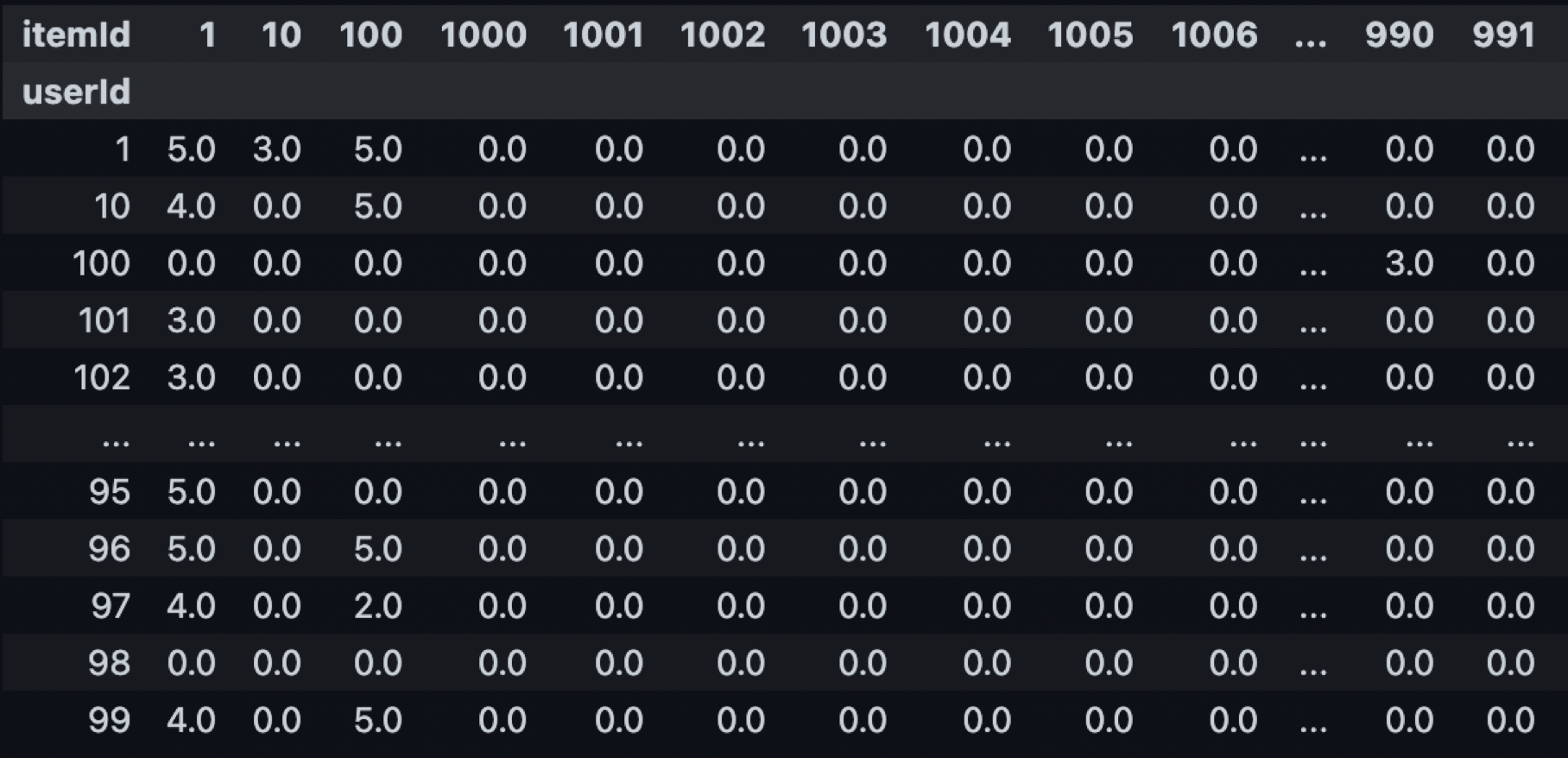
- 將個別用戶的row取出,作為VAE模型的Input
$r_{u_*}$ - 用戶

- shape 為 [1, 商品數量]
- batch_size 為設定模型每次訓練時的用戶數量,一個epoch要跑(訓練樣本數/batch_size)個 iterations
- 用戶
- 輸入$r_{u_}$ 進模型中,輸出新資料 $\hat{r}{u}$

- shape 同樣為 [1, 商品數量]
-
Training Phase:
- 將歷史的用戶資料作為Training Data,訓練模型在所有用戶資料下能夠盡可能的還原回原始的資料分佈
-
Inference Phase:
- 將 shape 為[1, 商品數量]的用戶評分資料進行 Encoder 與 Decoder 後所得到的新的用戶評分資料即為VAECF預測該用戶對全商品的評分結果


-
如上述說明,VAECF 主要透過用戶評分資料進行預測,因此我們需要透過 trans_buy 交易資料表產生一評分資料,來供 VAECF 進行預測,評分資料表格式如下:
User Item rating 用戶名 (Aiden) 商品名 (apple) 評分 (5.0) -
我方使用交易次數來代表評分,每購買一次評分 + 1,轉換程式碼如下,執行後即可產生評分資料格式:
trans_buy = pd.read_pickle(DATA_PATH / "trans_buy.pkl") # 讀取資料到 DataFrame rate_df = trans_buy.groupby(["<USER 欄位名>", "<ITEM 欄位名>"])\ .size()\ .reset_index(name="rating") -
另外為了訓練深度模型,需要將資料輸入是先定義好的
Dataset中,執行以下函式來取得深度學習所需要的Dataset資料結構:uir_data = rate_df[["<USER 欄位名>", "<ITEM 欄位名>", "rating"]] train_set = recs.datasets.Dataset.from_uir(uirdata, seed=0) -
產生模型實例,並使用上述Dataset來訓練模型:
vaecf = recs.models.VAECF( k=10, autoencoder_structure=[20], act_fn="tanh", likelihood="mult", n_epochs=100, batch_size=100, learning_rate=0.001, beta=1.0, seed=123, use_gpu=True, verbose=True, ) vaecf.fit(train_set) -
訓練完成後,調用事先定義好
predict_ranking函式進行預測:df = pd.DataFrame(columns=['userId', 'itemId', 'rating'], data=data) pred = predict_ranking(vaecf, df, 'userId', 'itemId', 'rating', True) -
將推薦結果資料儲存到
./data資料夾,供後續可解釋性使用pred.to_csv(DATA_PATH / "pred.csv", index=False) -
若要儲存模型,執行pytorch一般的 save 與 load 流程後,即可直接取用訓練好的模型
- crm_new.csv
- fund_xxx.csv
- trans_buy.csv
- 從前處理完成後的資料中取出已交易用戶的資料,如下圖:
u2idx = readjson2dict("crm_idx") i2idx = readjson2dict("fund_info_idx") tran_data = pd.read_pickle(DATA_PATH / "trans_buy.pkl") # 把 index 化的 id 轉回來 tran_data["id_number"] = tran_data["id_number"].progress_apply( lambda x: id2cat(u2idx, x)) tran_data["fund_id"] = tran_data["fund_id"].progress_apply( lambda x: id2cat(i2idx, x)) # 讀取分群用的 crm 資料表(透過 recs.datasets.preprocess.crm_new 產生) crm = pd.read_csv(DATA_PATH / "crm_for_clustering_2020.csv") crm = crm[crm.yyyymm == 202012] # 目標用戶 target_users = crm['id_number'].unique().tolist() - 我們要對
未交易用戶進行推薦,我們透過crm_for_clustering_2020.csv資料表中的has_traded欄位取出未交易資料者。並且取出我們需要做分群需要的資料:new_user = crm[crm['has_traded'] == 0]['id_number'].unique().tolist() # 分群需要的資料 user_data = crm.copy() u_data = user_data.drop(columns=['id_number', 'CIFAOCODE']) u_data = u_data.replace(-np.inf, -1) u_data.fillna(0, inplace=True) - 透過 umap 對特徵進行降維,使用在
./recs/models/cluster/clustering.py中定義好的feature_selecter函式進行特徵擷取,我方使用經回測得出效果最好的 Hyperparameter 進行降維:# Hyperparameter embedding_method = "umap" n_components = 25 x_embedded = feature_selecter(u_data, embedding_method, n_components) - 以 dbscan 演算法進行分群,使用在
./recs/models/cluster/clustering.py中定義好的clustering函式進行分群,並且在資料上添加cluster欄位來表示該 user 分配到哪個群體中c_user_data = clustering(user_data, x_embedded, 'dbscan', eps=6.5, min_samples=5) - 根據分群結果取各群體的Top N 銷售結果,同樣使用在
./recs/models/cluster/clustering.py中已定義好的recommender_method函式,即可得到各個群體所推薦的 Top N 推薦結果,程式碼如下:cluster_top10 = recommender_method(tran_data, c_user_data) - 最後以此結果推薦給未交易用戶
result_by_cluster = {} for u in tqdm(new_user): temp = user_data[user_data['身分證字號'] == u] # 或 id_number t_cluster = temp.cluster.tolist()[0] result_by_cluster[u] = cluster_top10[t_cluster]
- pred.csv (VAECF產生)
- 前處理後產生資料
- crm_for_clustering_2020.csv
- crm_idx.json
- fund_info_idx.json
- 讀取所需資料,並且將資料表一同合併
u2idx = readjson2dict("crm_idx") i2idx = readjson2dict("fund_info_idx") pred = pd.read_csv(DATA_PATH / "pred.csv") pred['userId'] = pred['userId'].progress_apply(lambda x: id2cat(u2idx, x)) pred['itemId'] = pred['itemId'].progress_apply(lambda x: id2cat(i2idx, x)) crm = pd.read_csv(DATA_PATH / "crm_for_clustering_2020.csv") crm['userId'] = crm['id_number'] crm.drop(columns=['id_number', 'index'], inplace=True) fund = pd.read_pickle(DATA_PATH / 'fund_info.pkl') fund['itemId'] = fund['fund_id'].progress_apply(lambda x: id2cat(i2idx, x)) fund.drop(columns=['fund_id', 'currency_type'], inplace=True) pred = pred.merge(crm, how='left', on=['userId']) pred = pred.merge(fund, how='left', on=['itemId']) - 切分訓練輸入
x與預測欄位ykeys = pred[['userId', 'itemId']] y = pred['rating'] x = pred.drop(columns=['userId', 'itemId', 'rating', 'CIFAOCODE']) - 訓練 LGBMRegressor 模型
model = LGBMRegressor( boosting_type="gbdt", verbose=1, random_state=47 ) model.fit(x, y) - 計算 shap value,來計算參數對模型輸出的影響
explainer = shap.Explainer(model) shap_vals = explainer(x) feature_names = shap_vals.feature_names - 將解釋性結果輸出
value_df_dict = {} base_val = shap_vals.base_values[0] for i in tqdm(shap_vals): i_sum = i.values.sum() for jidx, j in enumerate(feature_names): data_val = i.data[jidx] val = round(i.values[jidx] / (i_sum - base_val), 4) save_val = (val, data_val) if value_df_dict.get(j, 0) == 0: value_df_dict[j] = [save_val] else: value_df_dict[j].append(save_val) df = pd.DataFrame(value_df_dict)
- 個人化推薦,可執行
vaecf_example.py來得到與實驗相同的推薦結果,會產生檔案放在./result中- 執行
example/vaecf_example.py
- 執行
- 冷啟動推薦,可執行以下程式碼得到上月繳交的結果,同樣產生於
./result中- 執行
example/clustering_example.py
- 執行
- 可解釋性部分,同樣可執行以下程式碼得到上月繳交的結果於
./result資料夾中:- 執行
python examples/explain_example.py
- 執行