Code has been run on Google Colab, thanks Google for providing computational resources
Contents
-
Natural Language Processing(自然语言处理)
-
-
IMDB(English Data)
Abstract: 1. we show the classic ML model (tfidf + logistic regression) is able to reach 89.6% which is decent for its simplicity, efficiency and low-cost 2. we show FastText model is able to reach 90% accuracy 3. we show cnn-based model is able to improve the accuracy to 91.7% 4. we show rnn-based model is able to improve the accuracy to 92.6% 5. we show pretrained model (bert) is able to improve the accuracy to 94% 6. we show pretrained model (roberta) is able to improve the accuracy to 94.7% 7. we use back-translation, label smoothing, cyclical lr as training helpers
-
-
-
SNLI(English Data)
Abstract: 1. we show dam (lots of interact) is able to reach 85.3% accuracy 2. we show pyramid (rnn + image processing) is able to improve the accuracy to 87.1% 3. we show esim (rnn + lots of interact) is able to improve the accuracy to 87.4% 4. we show re2 (rnn + lots of interact + residual) is able to improve the accuracy to 88.3% 5. we show bert (pretrained model) is able to improve the accuracy to 90.4% 6. we show roberta (pretrained model) is able to improve the accuracy to 91.1% 7. we use label smoothing and cyclical lr as training helpers -
微众银行智能客服(Chinese Data)
Abstract: 1. we show esim, pyramid, re2 are able to reach 82.5% ~ 82.9% accuracy (very close) 2. we show re2 is able to be improved to 83.8% by using cyclical lr and label smoothing 3. we show bert (pretrained model) is able to further improve the accuracy to 84.75% 4. we show char-level re2 actually performs better than word-level re2 on this dataset
-
-
Spoken Language Understanding(对话理解)
- ATIS(English Data)
-
- Large-scale Chinese Conversation Dataset
-
Multi-turn Dialogue Rewriting(多轮对话改写)
-
20k 腾讯 AI 研发数据(Chinese Data)
Highlight: 1. our implementation of rnn-based pointer network reaches 60% exact match without bert which is higher than other implementations using bert e.g. (https://github.com/liu-nlper/dialogue-utterance-rewriter) 57.5% exact match 2. we show how to deploy model in java production 3. we explain this task can be decomposed into two stages (extract keywords & recombine query) the first stage is fast (tagging) and the second stage is slow (autoregressive generation) for the first stage, we show birnn extracts keywords at 79.6% recall and 42.6% exact match then we show bert is able to improve this extraction task to 93.6% recall and 71.6% exact match 4. we find that we need to predict the intent as well (whether to rewrite the query or not) in other words, whether to trigger the rewriter or not at the first place we have finetuned a bert to jointly predict intent and extract the keywords the result is: 97.9% intent accuracy; 90.2% recall and 64.3% exact match for keyword extraction
-
-
-
Facebook AI Research Data(English Data)
Highlight: our implementation of pointer-generator reaches 80.3% exact match on testing set which is higher than all the results of the original paper including rnng (78.5%) we further improve exact match to 81.1% by adding more embeddings (char & contextual) (https://aclweb.org/anthology/D18-1300)
-
-
- bAbI(Engish Data)
-
-
Knowledge Graph(知识图谱)
-
- Movielens 1M(English Data)
Text Classification
└── finch/tensorflow2/text_classification/imdb
│
├── data
│ └── glove.840B.300d.txt # pretrained embedding, download and put here
│ └── make_data.ipynb # step 1. make data and vocab: train.txt, test.txt, word.txt
│ └── train.txt # incomplete sample, format <label, text> separated by \t
│ └── test.txt # incomplete sample, format <label, text> separated by \t
│ └── train_bt_part1.txt # (back-translated) incomplete sample, format <label, text> separated by \t
│
├── vocab
│ └── word.txt # incomplete sample, list of words in vocabulary
│
└── main
└── attention_linear.ipynb # step 2: train and evaluate model
└── attention_conv.ipynb # step 2: train and evaluate model
└── fasttext_unigram.ipynb # step 2: train and evaluate model
└── fasttext_bigram.ipynb # step 2: train and evaluate model
└── sliced_rnn.ipynb # step 2: train and evaluate model
└── sliced_rnn_bt.ipynb # step 2: train and evaluate model
-
Task: IMDB(English Data)
Training Data: 25000, Testing Data: 25000, Labels: 2-
Model: TF-IDF + Logistic Regression
-
PySpark
-
<Notebook> Unigram + TF + IDF + Logistic Regression
-> 88.2% Testing Accuracy
-
-
Sklearn
-
<Notebook> Unigram + TF + IDF + Logistic Regression
-> 88.3% Testing Accuracy
-
<Notebook> Unigram + TF (binary) + IDF + Logistic Regression
-> 88.8% Testing Accuracy
-
<Notebook> Unigram + Bigram + TF (binary) + IDF + Logistic Regression
-> 89.6% Testing Accuracy
-
-
-
Model: FastText
-
-
-> 87.3% Testing Accuracy
-
<Notebook> (Unigram + Bigram) FastText
-> 89.8% Testing Accuracy
-
-> 90.1% Testing Accuracy
-
-
TensorFlow 2
-
-> 89.1 % Testing Accuracy
-
<Notebook> (Unigram + Bigram) FastText
-> 90.2 % Testing Accuracy
-
-
-
Model: Feedforward Attention
-
TensorFlow 2
-
<Notebook> Feedforward Attention
-> 89.5 % Testing Accuracy
-
<Notebook> CNN + Feedforward Attention
-> 90.7 % Testing Accuracy
-
<Notebook> CNN + Feedforward Attention + Back-Translation + Char Embedding + Label Smoothing
-> 91.7 % Testing Accuracy
-
-
-
Model: Sliced RNN
-
TensorFlow 2
-
-> 91.4 % Testing Accuracy
-
<Notebook> Sliced LSTM + Back-Translation
-> 91.7 % Testing Accuracy
Back-Translation increases training data from 25000 to 50000 which is done by "english -> french -> english" translationfrom googletrans import Translator translator = Translator() translated = translator.translate(text, src='en', dest='fr').text back = translator.translate(translated, src='fr', dest='en').text
-
<Notebook> Sliced LSTM + Back-Translation + Char Embedding
-> 92.3 % Testing Accuracy
-
<Notebook> Sliced LSTM + Back-Translation + Char Embedding + Label Smoothing
-> 92.5 % Testing Accuracy
-
<Notebook> Sliced LSTM + Back-Translation + Char Embedding + Label Smoothing + Cyclical LR
-> 92.6 % Testing Accuracy
This result (without transfer learning) is higher than CoVe (with transfer learning)
-
-
-
Model: BERT
-
TensorFlow 2 + transformers
-
<Notebook> BERT (base-uncased) { batch_size=32, max_len=128 }
-> 92.6% Testing Accuracy
-
<Notebook> BERT (base-uncased) { batch_size=16, max_len=200 }
-> 93.3% Testing Accuracy
-
<Notebook> BERT (base-uncased) { batch_size=12, max_len=256 }
-> 93.8% Testing Accuracy
-
<Notebook> BERT (base-uncased) { batch_size=8, max_len=300 }
-> 94% Testing Accuracy
-
-
-
Model: RoBERTa
-
TensorFlow 2 + transformers
-
<Notebook> RoBERTa (base) { batch_size=8, max_len=300 }
-> 94.7% Testing Accuracy
-
-
Text Matching
└── finch/tensorflow2/text_matching/snli
│
├── data
│ └── glove.840B.300d.txt # pretrained embedding, download and put here
│ └── download_data.ipynb # step 1. run this to download snli dataset
│ └── make_data.ipynb # step 2. run this to generate train.txt, test.txt, word.txt
│ └── train.txt # incomplete sample, format <label, text1, text2> separated by \t
│ └── test.txt # incomplete sample, format <label, text1, text2> separated by \t
│
├── vocab
│ └── word.txt # incomplete sample, list of words in vocabulary
│
└── main
└── dam.ipynb # step 3. train and evaluate model
└── esim.ipynb # step 3. train and evaluate model
└── ......
-
Task: SNLI(English Data)
Training Data: 550152, Testing Data: 10000, Labels: 3-
TensorFlow 2
-
Model: DAM
-
-> 85.3% Testing Accuracy
The accuracy of this implementation is higher than UCL MR Group's implementation (84.6%)
-
-
Model: Match Pyramid
-
-> 87.1% Testing Accuracy
The accuracy of this model is 0.3% below ESIM, however the speed is 1x faster than ESIM
-
-
Model: ESIM
-
-> 87.4% Testing Accuracy
The accuracy of this implementation is comparable to UCL MR Group's implementation (87.2%)
-
-
Model: RE2
-
-> 87.7% Testing Accuracy
-
-> 88.0% Testing Accuracy
-
<Notebook> RE3 + Cyclical LR + Label Smoothing
-> 88.3% Testing Accuracy
-
-
Model: BERT
-
<Notebook> BERT (base-uncased)
-> 90.4% Testing Accuracy
-
-
Model: RoBERTa
-
-> 91.1% Testing Accuracy
-
-
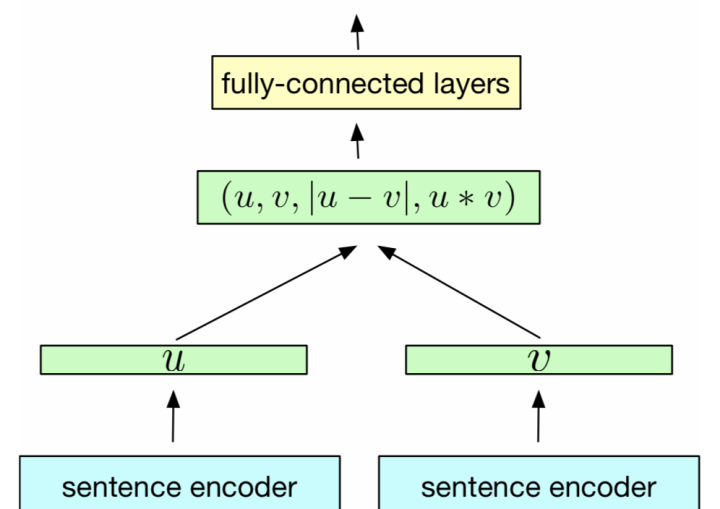
└── finch/tensorflow2/text_matching/chinese
│
├── data
│ └── make_data.ipynb # step 1. run this to generate char.txt and char.npy
│ └── train.csv # incomplete sample, format <text1, text2, label> separated by comma
│ └── test.csv # incomplete sample, format <text1, text2, label> separated by comma
│
├── vocab
│ └── cc.zh.300.vec # pretrained embedding, download and put here
│ └── char.txt # incomplete sample, list of chinese characters
│ └── char.npy # saved pretrained embedding matrix for this task
│
└── main
└── pyramid.ipynb # step 2. train and evaluate model
└── esim.ipynb # step 2. train and evaluate model
└── ......
-
Task: 微众银行智能客服(Chinese Data)
Training Data: 100000, Testing Data: 10000, Labels: 2-
Model
-
TensorFlow 2
-
-> 82.5% Testing Accuracy
-
-> 82.7% Testing Accuracy
-
-> 82.9% Testing Accuracy
-
<Notebook> RE2 + Cyclical LR + Label Smoothing
-> 83.8% Testing Accuracy
The result of RE2 actually catches up with Bert base below (both 83.8%)
These results are higher than the repo here and the repo here
-
-
TensorFlow 2 + transformers
-
<Notebook> BERT (chinese_base)
-> 83.8% Testing Accuracy
-
-
TensorFlow 1 + bert4keras
-
-> 84.75% Testing Accuracy
Weights downloaded from here
-
-
-
About word-level vs character-level
-
All these models above have been implemented on character-level
-
We have attempted word-level modelling by using jieba to split words
-
but word-level RE2 (82.5% accuracy) does not surpass char-level RE2 above (83.8%)
-
Spoken Language Understanding
└── finch/tensorflow2/spoken_language_understanding/atis
│
├── data
│ └── glove.840B.300d.txt # pretrained embedding, download and put here
│ └── make_data.ipynb # step 1. run this to generate vocab: word.txt, intent.txt, slot.txt
│ └── atis.train.w-intent.iob # incomplete sample, format <text, slot, intent>
│ └── atis.test.w-intent.iob # incomplete sample, format <text, slot, intent>
│
├── vocab
│ └── word.txt # list of words in vocabulary
│ └── intent.txt # list of intents in vocabulary
│ └── slot.txt # list of slots in vocabulary
│
└── main
└── bigru_clr.ipynb # step 2. train and evaluate model
└── bigru_self_attn_clr.ipynb # step 2. train and evaluate model
└── bigru_clr_crf.ipynb # step 2. train and evaluate model
-
Task: ATIS(English Data)
Training Data: 4978, Testing Data: 893-
Model: Conditional Random Fields
-
-
92% Slot Micro-F1 on Testing Data
-
-
-
Model: Bi-directional RNN
-
TensorFlow 2
-
97.4% Intent Acc, 95.4% Slot Micro-F1 on Testing Data
-
<Notebook> Bi-GRU + Self-Attention
97.6% Intent Acc, 95.7% Slot Micro-F1 on Testing Data
-
97.2% Intent Acc, 95.8% Slot Micro-F1 on Testing Data
-
-
-
Model: ELMO Embedding
-
TensorFlow 1
-
97.5% Intent Acc, 96.1% Slot Micro-F1 on Testing Data
-
<Notebook> ELMO + Bi-GRU + CRF
97.3% Intent Acc, 96.3% Slot Micro-F1 on Testing Data
-
-

Generative Dialog
└── finch/tensorflow1/free_chat/chinese_lccc
│
├── data
│ └── LCCC-base.json # raw data downloaded from external
│ └── LCCC-base_test.json # raw data downloaded from external
│ └── make_data.ipynb # step 1. run this to generate vocab {char.txt} and data {train.txt & test.txt}
│ └── train.txt # processed text file generated by {make_data.ipynb}
│ └── test.txt # processed text file generated by {make_data.ipynb}
│
├── vocab
│ └── char.txt # list of chars in vocabulary for chinese
│ └── cc.zh.300.vec # fastText pretrained embedding downloaded from external
│ └── char.npy # chinese characters and their embedding values (300 dim)
│
└── main
└── lstm_seq2seq_train.ipynb # step 2. train and evaluate model
└── lstm_seq2seq_export.ipynb # step 3. export model
└── lstm_seq2seq_infer.ipynb # step 4. model inference
└── transformer_train.ipynb # step 2. train and evaluate model
└── transformer_export.ipynb # step 3. export model
└── transformer_infer.ipynb # step 4. model inference
-
Task: Chinese Conversation Dataset
Training Data: 2000000, Testing Data: 19008-
Data
-
Model: RNN Seq2Seq + Attention
-
TensorFlow 1
-
LSTM Encoder + LSTM Decoder -> 39.331 Testing Perplexity
-
-
Model Inference
-
-
Model: Transformer
-
TensorFlow 1 + texar
-
Transformer Encoder + LSTM Decoder -> 40.127 Testing Perplexity
-
-
Model Inference
-
-
If you want to deploy model in Java production
└── FreeChatInference │ ├── data │ └── transformer_export/ │ └── char.txt │ └── libtensorflow-1.14.0.jar │ └── tensorflow_jni.dll │ └── src └── ModelInference.java-
If you don't know the input and output node names in Java, you can call:
!saved_model_cli show --dir ../model/xxx/1587959473/ --tag_set serve --signature_def serving_defaultwhich will display the node names:
The given SavedModel SignatureDef contains the following input(s): inputs['history'] tensor_info: dtype: DT_INT32 shape: (-1, -1, -1) name: history:0 inputs['query'] tensor_info: dtype: DT_INT32 shape: (-1, -1) name: query:0 The given SavedModel SignatureDef contains the following output(s): outputs['output'] tensor_info: dtype: DT_INT32 shape: (-1, -1) name: Decoder/decoder/transpose_1:0 Method name is: tensorflow/serving/predict
-
Semantic Parsing
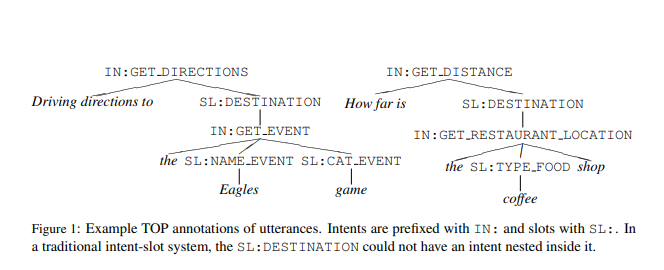
└── finch/tensorflow2/semantic_parsing/tree_slu
│
├── data
│ └── glove.840B.300d.txt # pretrained embedding, download and put here
│ └── make_data.ipynb # step 1. run this to generate vocab: word.txt, intent.txt, slot.txt
│ └── train.tsv # incomplete sample, format <text, tokenized_text, tree>
│ └── test.tsv # incomplete sample, format <text, tokenized_text, tree>
│
├── vocab
│ └── source.txt # list of words in vocabulary for source (of seq2seq)
│ └── target.txt # list of words in vocabulary for target (of seq2seq)
│
└── main
└── lstm_seq2seq_tf_addons.ipynb # step 2. train and evaluate model
└── ......
-
Task: Semantic Parsing for Task Oriented Dialog(English Data)
Training Data: 31279, Testing Data: 9042-
TensorFlow 2
-
Model: RNN Seq2Seq + Attention
-
<Notebook> GRU + Seq2Seq + Cyclical LR + Label Smoothing ->
74.1% Exact Match on Testing Data
-
<Notebook> LSTM + Seq2Seq + Cyclical LR + Label Smoothing ->
74.1% Exact Match on Testing Data
-
-
Model: Pointer-Generator
-
<Notebook> GRU + Pointer-Generator + Cyclical LR + Label Smoothing ->
80.3% Exact Match on Testing Data
Pointer Generator = Pointer Network + Seq2Seq Network This result is quite strong which beats all the exact match results in the original paper (https://aclweb.org/anthology/D18-1300) -
<Notebook> Char Embedding + Bert Embedding + GRU + Pointer-Generator + Cyclical LR + Label Smoothing ->
81.1% Exact Match on Testing Data
-
-
Knowledge Graph Inference
└── finch/tensorflow2/knowledge_graph_completion/wn18
│
├── data
│ └── download_data.ipynb # step 1. run this to download wn18 dataset
│ └── make_data.ipynb # step 2. run this to generate vocabulary: entity.txt, relation.txt
│ └── wn18 # wn18 folder (will be auto created by download_data.ipynb)
│ └── train.txt # incomplete sample, format <entity1, relation, entity2> separated by \t
│ └── valid.txt # incomplete sample, format <entity1, relation, entity2> separated by \t
│ └── test.txt # incomplete sample, format <entity1, relation, entity2> separated by \t
│
├── vocab
│ └── entity.txt # incomplete sample, list of entities in vocabulary
│ └── relation.txt # incomplete sample, list of relations in vocabulary
│
└── main
└── distmult_1-N.ipynb # step 3. train and evaluate model
-
Task: WN18
Training Data: 141442, Testing Data: 5000-
We use 1-N Fast Evaluation to largely accelerate evaluation process
-
Model: DistMult
-
TensorFlow 2
-
-
Model: TuckER
-
TensorFlow 2
-
-
Model: ComplEx
-
TensorFlow 2
-
Knowledge Graph Tools
-
Data Scraping
-
SPARQL
-
Neo4j + Cypher
Knowledge Base Question Answering

-
Rule-based System(基于规则的系统)
For example, we want to answer the following questions:
宝马是什么? / what is BMW? 我想了解一下宝马 / i want to know about the BMW 给我介绍一下宝马 / please introduce the BMW to me 宝马这个牌子的汽车怎么样? / how is the car of BMW group? 宝马如何呢? / how is the BMW? 宝马汽车好用吗? / is BMW a good car to use? 宝马和奔驰比怎么样? / how is the BMW compared to the Benz? 宝马和奔驰比哪个好? / which one is better, the BMW or the Benz? 宝马和奔驰比哪个更好? / which one is even better, the BMW or the Benz?
Question Answering

└── finch/tensorflow1/question_answering/babi
│
├── data
│ └── make_data.ipynb # step 1. run this to generate vocabulary: word.txt
│ └── qa5_three-arg-relations_train.txt # one complete example of babi dataset
│ └── qa5_three-arg-relations_test.txt # one complete example of babi dataset
│
├── vocab
│ └── word.txt # complete list of words in vocabulary
│
└── main
└── dmn_train.ipynb
└── dmn_serve.ipynb
└── attn_gru_cell.py
-
Task: bAbI(English Data)
Text Processing Tools
-
Word Matching
-
Chinese
-
-
Word Segmentation
-
Chinese
- <Notebook> Jieba TensorFlow Op purposed by Junwen Chen
-
-
Topic Modelling
-
Data: 2373 Lines of Book Titles(English Data)
-
Model: TF-IDF + LDA
-
PySpark
-
Sklearn + pyLDAvis
-
-
-
Recommender System

└── finch/tensorflow1/recommender/movielens
│
├── data
│ └── make_data.ipynb # run this to generate vocabulary
│
├── vocab
│ └── user_job.txt
│ └── user_id.txt
│ └── user_gender.txt
│ └── user_age.txt
│ └── movie_types.txt
│ └── movie_title.txt
│ └── movie_id.txt
│
└── main
└── dnn_softmax.ipynb
└── ......
-
Task: Movielens 1M(English Data)
Training Data: 900228, Testing Data: 99981, Users: 6000, Movies: 4000, Rating: 1-5-
Model: Fusion
-
TensorFlow 1
MAE: Mean Absolute Error
-
<Notebook> Fusion + Sigmoid ->
0.663 Testing MAE
-
<Notebook> Fusion + Sigmoid + Cyclical LR ->
0.661 Testing MAE
-
<Notebook> Fusion + Softmax ->
0.633 Testing MAE
-
<Notebook> Fusion + Softmax + Cyclical LR ->
0.628 Testing MAE
The MAE results seem better than the all the results here and all the results here
-
-
Multi-turn Dialogue Rewriting

└── finch/tensorflow1/multi_turn_rewrite/chinese/
│
├── data
│ └── make_data.ipynb # run this to generate vocab, split train & test data, make pretrained embedding
│ └── corpus.txt # original data downloaded from external
│ └── train_pos.txt # processed positive training data after {make_data.ipynb}
│ └── train_neg.txt # processed negative training data after {make_data.ipynb}
│ └── test_pos.txt # processed positive testing data after {make_data.ipynb}
│ └── test_neg.txt # processed negative testing data after {make_data.ipynb}
│
├── vocab
│ └── cc.zh.300.vec # fastText pretrained embedding downloaded from external
│ └── char.npy # chinese characters and their embedding values (300 dim)
│ └── char.txt # list of chinese characters used in this project
│
└── main
└── baseline_lstm_train.ipynb
└── baseline_lstm_export.ipynb
└── baseline_lstm_predict.ipynb
-
Task: 20k 腾讯 AI 研发数据(Chinese Data)
data split as: training data (positive): 18986, testing data (positive): 1008 Training data = 2 * 18986 because of 1:1 Negative Sampling-
<Notebook>: Make Data & Vocabulary & Pretrained Embedding
There are six incorrect data and we have deleted them -
Model: RNN Seq2Seq + Attention + Multi-hop Memory
-
TensorFlow 1
-
<Notebook> LSTM Seq2Seq + Multi-hop Memory + Attention
-> Exact Match: 56.2%, BLEU-1: 94.6, BLEU-2: 89.1, BELU-4: 78.5
-
<Notebook> GRU Seq2Seq + Multi-hop Memory + Attention
-> Exact Match: 56.6%, BLEU-1: 94.5, BLEU-2: 88.9, BELU-4: 78.3
-
<Notebook> GRU Seq2Seq + Multi-hop Memory + Multi-Attention
-> Exact Match: 56.2%, BLEU-1: 95.0, BLEU-2: 89.5, BELU-4: 78.9
-
-
-
Model: RNN Pointer Networks
-
TensorFlow 1
Pointer Net returns probability distribution, therefore no need to do softmax again in beam search
Go to beam search source code, replace this line
step_log_probs = nn_ops.log_softmax(logits)
with this line
step_log_probs = math_ops.log(logits)
-
-> Exact Match: 59.2%, BLEU-1: 93.2, BLEU-2: 87.7, BELU-4: 77.2
-
<Notebook> GRU Pointer Net + Multi-Attention
-> Exact Match: 60.2%, BLEU-1: 94.2, BLEU-2: 88.7, BELU-4: 78.3
This result (only RNN, without BERT) is comparable to the result here with BERT
Pointer Network is better than Seq2Seq on this kind of task where the target text highly overlaps with the source text
-
-
-
If you want to deploy model
-
Python Inference(基于 Python 的推理)
-
Java Inference(基于 Java 的推理)
-
└── MultiDialogInference │ ├── data │ └── baseline_lstm_export/ │ └── char.txt │ └── libtensorflow-1.14.0.jar │ └── tensorflow_jni.dll │ └── src └── ModelInference.java
-
-
-
Despite End-to-End, this problem can also be decomposed into two stages
-
Stage 1 (Fast). Detecting the (missing or referred) keywords from the context
which is a sequence tagging task with sequential complexity
O(1) -
Stage 2 (Slow). Recombine the keywords with the query based on language fluency
which is a sequence generation task with sequential complexity
O(N)For example, for a given query: "买不起" and the context: "成都房价是多少 不买就后悔了成都房价还有上涨空间" First retrieve the keyword "成都房" from the context which is very important Then recombine the keyword "成都房" with the query "买不起" which becomes "买不起成都房" -
For Stage 1 (sequence tagging for retrieving the keywords), the experiment results are:
-
-> Recall: 79.6% Precision: 78.7% Exact Match: 42.6%
-
<Notebook> BERT (chinese_base)
-> Recall: 93.6% Precision: 83.1% Exact Match: 71.6%
-
-
-
However, there is still a practical problem to prefine whether the query needs to be rewritten or not
-
if not, we just simply skip the rewriter and pass the query to the next stage
-
there are actually three situations needs to be classified
-
0: the query does not need to be rewritten because it is irrelevant to the context
你喜欢五月天吗 超级喜欢阿信 中午出去吃饭吗 -
1: the query needs to be rewritten
你喜欢五月天吗 超级喜欢阿信 你喜欢他的那首歌 -> 你喜欢阿信的那首歌 -
2: the query does not need to be rewritten because it already contains enough information
你喜欢五月天吗 超级喜欢阿信 你喜欢阿信的那首歌
-
-
therefore, we aim for training the model to jointly predict:
-
intent: three situations {0, 1, 2} whether the query needs to be rewritten or not
-
keyword extraction: extract the missing or referred keywords in the context
-
-
<Notebook> BERT (chinese_base)
-> Intent: 97.9% accuracy
-> Keyword Extraction: 90.2% recall 80.7% precision 64.3% exact match
-