


These instructions will lead you to step by step operations for the workshop introducing the NoSQL Databases technologies.
It doesn't matter if you join our workshop live or you prefer to do at your own pace, we have you covered. In this repository, you'll find everything you need for this workshop:
To get the verified badge, you have to complete the following steps:
- Complete the practice steps of this workshop as explained below, steps I-IV are mandatory, step V is optional. Take screenshots of the last completed step from either step IV or V. NOTE: When taking screenshots ensure NOT to copy your Astra DB key!
- Complete try-it-out scenario and make a screenshot of the "scenario completed" screen
- Submit the practice here attaching the screenshots.
ASTRA DB is the simplest way to run Cassandra with zero operations at all - just push the button and get your cluster. No credit card required, $25.00 USD credit every month, roughly 5M writes, 30M reads, 40GB storage monthly - sufficient to run small production workloads.
✅ Register (if needed) and Sign In to Astra DB https://astra.datastax.com: You can use your Github, Google accounts or register with an email.
Make sure to chose a password with minimum 8 characters, containing upper and lowercase letters, at least one number and special character
✅ Choose "Start Free Now"
Choose the "Start Free Now" plan, then "Get Started" to work in the free tier.
You will have plenty of free initial credit (renewed each month!), roughly corresponding to 40 GB of storage, 30M reads and 5M writes.
If this is not enough for you, congratulations! You are most likely running a mid- to large-sized business! In that case you should switch to a paid plan.
(You can follow this guide to set up your free-tier database with the $25 monthly credit.)

To create the database:
-
For the database name -
nosql_db. While Astra DB allows you to fill in these fields with values of your own choosing, please follow our recommendations to ensure the application runs properly. -
For the keyspace name -
nosql1. It's really important that you use the name "nosql1" for the code to work.
You can technically use whatever you want and update the code to reflect the keyspace. This is really to get you on a happy path for the first run.
-
For provider and region: Choose and provider (either GCP or AWS). Region is where your database will reside physically (choose one close to you or your users).
-
Create the database. Review all the fields to make sure they are as shown, and click the
Create Databasebutton.
You will see your new database pending in the Dashboard.
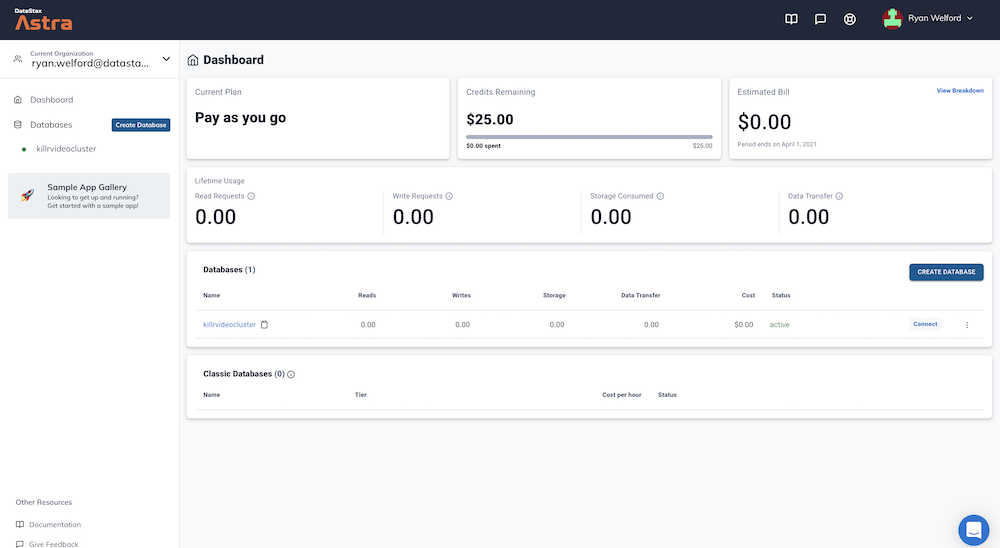
The status will change to Active when the database is ready, this will only take 2-3 minutes. You will also receive an email when it is ready.
👁️ Walkthrough

In a tabular database we will store ... tables! The Astra DB Service is built on Apache Cassandra™, which is tabular: it makes sense to start by this one.
Tabular databases organize data in rows and columns, but with a twist from the traditional RDBMS. Also known as wide-column stores or partitioned row stores, they provide the option to organize related rows in partitions that are stored together on the same replicas to allow fast queries. Unlike RDBMSs, the tabular format is not necessarily strict. For example, Apache Cassandra™ does not require all rows to contain values for all columns in the table. Like Key/Value and Document databases, Tabular databases use hashing to retrieve rows from the table. Examples include: Cassandra, HBase, and Google Bigtable.
✅ 2a. Describe your Keyspace
At Database creation you provided a keyspace, a logical grouping for tables. Let's visualize it. In Astra DB go to CQL Console to enter the following commands
-
Select your db
-
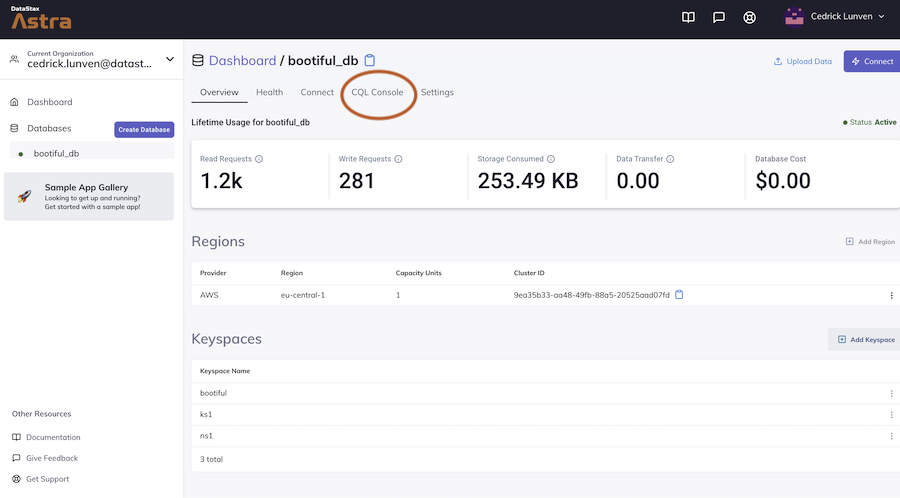
Select CqlConsole
-
Enter the command


describe keyspaces;
✅ 2b. Create tables
- Execute the following Cassandra Query Language
use nosql1;
CREATE TABLE IF NOT EXISTS videos (
videoid uuid,
email text,
title text,
upload timestamp,
url text,
tags set <text>,
frames list<int>,
PRIMARY KEY (videoid)
);- Visualize structure
describe keyspace nosql1;✅ 2c. Working with DATA :
- Insert some entries on first table
INSERT INTO videos(videoid, email, title, upload, url, tags, frames)
VALUES(uuid(),
'clu@sample.com',
'Introduction to Nosql Databases',
toTimeStamp(now()),
'https://www.youtube.com/watch?v=cMDHxsGbmC8',
{ 'nosql','workshop','2021'},
[ 1, 2, 3, 4]);
INSERT INTO videos(videoid, email, title, upload, url)
VALUES(uuid(),
'clu@sample.com',
'Demo video Y',
toTimeStamp(now()),
'https://www.youtube.com/watch?v=XXXX');
INSERT INTO videos(videoid, email, title, upload, url)
VALUES(e466f561-4ea4-4eb7-8dcc-126e0fbfd573,
'clu@sample.com',
'Yet another video',
toTimeStamp(now()),
'https://www.youtube.com/watch?v=ABCDE');- Read values
select * from videos;- Read by id
select * from videos
where videoid=e466f561-4ea4-4eb7-8dcc-126e0fbfd573;✅ 2d. Working with PARTITIONS :
But data can be grouped, we stored together what should be retrieved together.
- Create this new table
CREATE TABLE IF NOT EXISTS users_by_city (
city text,
firstname text,
lastname text,
email text,
PRIMARY KEY ((city), lastname, email)
) WITH CLUSTERING ORDER BY(lastname ASC, email ASC);
- Insert some entries
INSERT INTO users_by_city(city, firstname, lastname, email)
VALUES('PARIS', 'Lunven', 'Cedrick', 'clu@sample.com');
INSERT INTO users_by_city(city, firstname, lastname, email)
VALUES('PARIS', 'Yellow', 'Jackets', 'yj@sample.com');
INSERT INTO users_by_city(city, firstname, lastname, email)
VALUES('ORLANDO', 'David', 'Gilardi', 'dgi@sample.com');- List values with partitions keys
SELECT * from users_by_city WHERE city='PARIS';Let's do some hands-on with document database queries.
Document databases expand on the basic idea of key-value stores where “documents” are more complex, in that they contain data and each document is assigned a unique key, which is used to retrieve the document. These are designed for storing, retrieving, and managing document-oriented information, often stored as JSON. Since the Document database can inspect the document contents, the database can perform some additional retrieval processing. Unlike RDBMSs which require a static schema, Document databases have a flexible schema as defined by the document contents. Examples include: MongoDB and CouchDB. Note that some RDBMS and NoSQL databases outside of pure document stores are able to store and query JSON documents, including Cassandra.
✅ 3a. Cassandra knows JSON :
It is not a known fact but Cassandra accepts JSON query out of the box. You can find more information here.
- Insert data into Cassandra with JSON
INSERT INTO videos JSON '{
"videoid":"e466f561-4ea4-4eb7-8dcc-126e0fbfd578",
"email":"clunven@sample.com",
"title":"A JSON videos",
"upload":"2020-02-26 15:09:22 +00:00",
"url": "http://google.fr",
"frames": [1,2,3,4],
"tags": [ "cassandra","accelerate", "2020"]
}';In the same way you can retrieve JSON out of Cassandra (more info here).
- Retrieve data from Cassandra as JSON
select json title,url,tags from videos;
✅ 3b. Create your Application token :
You need to create an Astra DB token, which will used to interact with the database through the Swagger UI. Once created, store its value in a safe place (the Astra console won't show that to you again!) and do not post it in public.
To create the token go to the Astra dashboard, open the Organization menu on the top left and choose "Organization settings", then "Token Management" and finally you will be able to generate a new token. Choose the role "Database Administrator".
Download the token in CSV format and/or copy its value to a handy place such as a text editor: we will use it immediately!
See this documentation to create your application token.
The Astra DB Token looks like the following (do not copy, it's just an example)
AstraCS:KDfdKeNREyWQvDpDrBqwBsUB:ec80667c....
👁️ Walkthrough

This is what the token page looks like:

Swagger UI
Next go the connect page, locate the SWAGGER URL

Locate the Document part in the Swagger UI.

✅ 3c Create a new empty collection :
- Access Create a new empty collection in a namespace
- Click
Try it outbutton - Fill Header
X-Cassandra-Tokenwith<your_token> - For
namespace-idusenosql1 - For
bodyuse
{ "name": "col1" }- Click
Executebutton
You will get a 201 returned code
✅ 3d. Create a new document :
- Access Create a new document
- Click
Try it outbutton - Fill with Header
X-Cassandra-Tokenwith<your_token> - For
namespace-idusenosql1 - For
collection-idusecol1 - For
bodyuse
{
"videoid":"e466f561-4ea4-4eb7-8dcc-126e0fbfd573",
"email":"clunven@sample.com",
"title":"A Second videos",
"upload":"2020-02-26 15:09:22 +00:00",
"url": "http://google.fr",
"frames": [1,2,3,4],
"tags": [ "cassandra","accelerate", "2020"],
"formats": {
"mp4": {"width":1,"height":1},
"ogg": {"width":1,"height":1}
}
}- Click
Executebutton
👁️ Expected output
{
"documentId":"5d746e40-97cf-490b-ab0d-68cfbc5d2ef3"
}You can add a couple of documents changing values, new documents with new ids will be generated
✅ 3e Find all documents of a collection :
- Access Search documents in a collection
- Click
Try it outbutton - Fill Header
X-Cassandra-Tokenwith<your_token> - For
namespace-idusenosql1 - For
collection-idusecol1
Let other fields blank every query is paged in Cassandra.
- Click
Executebutton
👁️ Expected output:
{
"data": {
"84bd6ebc-a274-4dc3-ae7c-eb2fd913331b": {
"email": "clunven@sample.com",
"formats": {
"mp4": {
"height": 1,
"width": 1
},
"ogg": {
"height": 1,
"width": 1
}
},
"frames": [
1,
2,
3,
4
...✅ 3f Retrieve a document from its id :
- Access Get a document
- Click
Try it outbutton - Fill Header
X-Cassandra-Tokenwith<your_token> - For
namespace-idusenosql1 - For
collection-idusecol1 - For
document-iduse<doc_id_in_previous_call> - Click
Executebutton
👁️ Expected output:
{
"documentId": "84bd6ebc-a274-4dc3-ae7c-eb2fd913331b",
"data": {
"email": "clunven@sample.com",
"formats": {
"mp4": {
"height": 1,
"width": 1
},
"ogg": {
"height": 1,
"width": 1
}
},
"frames": [
1,
2,
3,
4
],
"tags": [
"cassandra",
"accelerate",
"2020"
],
"title": "A Second videos",
"upload": "2020-02-26 15:09:22 +00:00",
"url": "http://google.fr",
"videoid": "e466f561-4ea4-4eb7-8dcc-126e0fbfd573"
}
}✅ 3g Search document from a where clause :
- Access Search documents in a collection
- Click
Try it outbutton - Fill Header
X-Cassandra-Tokenwith<your_token> - For
namespace-idusenosql1 - For
collection-idusecol1 - For
whereuse{"email": { "$eq":"clunven@sample.com" } } - Click
Executebutton
👁️ Expected output
{
"data": {
"84bd6ebc-a274-4dc3-ae7c-eb2fd913331b": {
"email": "clunven@sample.com",
"formats": {
"mp4": {
"height": 1,
"width": 1
},
"ogg": {
"height": 1,
"width": 1
}
},
"frames": [
1,
2,
3,
4
],
"tags": [
"cassandra",
"accelerate",
"2020"
],
"title": "A Second videos",
"upload": "2020-02-26 15:09:22 +00:00",
"url": "http://google.fr",
"videoid": "e466f561-4ea4-4eb7-8dcc-126e0fbfd573"
}
}
}Key/Value databases are some of the least complex as all of the data within consists of an indexed key and a value. Key-value databases use a hashing mechanism such that given a key, the database can quickly retrieve an associated value. Hashing mechanisms provide constant time access, which means they maintain high performance even at large scale. The keys can be any type of object, but are typically a string. The values are generally opaque blobs (i.e., a sequence of bytes that the database does not interpret). Examples include: Redis, Amazon DynamoDB, Riak, and Oracle NoSQL database. Some tabular NoSQL databases, like Cassandra, can also service key/value needs.
✅ 4b. Create a table with GraphQL
Navigate to the GraphQL playground, by clicking Connect, then GraphQL API, and finally you should see the URL under Launching GraphQL Playground. Ctrl-click or right-click the link to launch into a new tab.

Then you need to enter in your Astra DB token to authenticate and talk to the database. Notice the "server cannot be reached" message. This is simply telling you it cannot make the connection because you are not authenticated. Click on HTTP Headers at the bottom and paste in your token.

Paste in your token.

Now you are ready to go.
Use this query. Since we are creating a table we want to use the graphql-schema tab
mutation {
kv: createTable(
keyspaceName:"nosql1",
tableName:"key_value",
partitionKeys: [ # The keys required to access your data
{ name: "key", type: {basic: TEXT} }
]
values: [ # The values associated with the keys
{ name: "value", type: {basic: TEXT} }
]
)
}

You can check in the CQL Console as well;
use nosql1;
describe table key_value;Expected output

✅ 4c. Populate the table
Any of the created APIs can be used to interact with the GraphQL data, to write or read data. Since we are working with data now and not creating schema you will need to swtich to the graphql tab. Also, ensure to fill in your Astra DB token again.
- Fill the header token again
{
"x-cassandra-token":"AstraCS:fjlsgehrre;ge"
}
Now, let’s navigate to your new keyspace nosql1 inside the playground. Change tab to graphql and pick url /graphql/nosql1

Then paste in the following query and click "play".

- Execute this query
mutation insert2KV {
key1: insertkey_value(value: {key:"key1", value:"bbbb"}) {
value {
key,value
}
}
key2: insertkey_value(value: {key:"key2", value:"bbbb"}) {
value {
key,value
}
}
}
- Check with CQL Console
select * from key_value;Expected output:

- Execute this query
mutation insert2KV {
key1: insertkey_value(value: {key:"key1", value:"cccc"}) {
value {
key,value
}
}
}
- Check with CQL Console the values should have been updated. Indeed with Cassandra there are no integrity constraints, so you can de-duplicate values easily.
Graph databases store their data using a graph metaphor to exploit the relationships between data. Nodes in the graph represent data items, and edges represent the relationships between the data items. Graph databases are designed for highly complex and connected data, which outpaces the relationship and JOIN capabilities of an RDBMS. Graph databases are often exceptionally good at finding commonalities and anomalies among large data sets. Examples of Graph databases include DataStax Graph, Neo4J, JanusGraph, and Amazon Neptune.
Astra DB does not contain yet a way to implement Graph Databases use cases. But at Datastax Companny we do have a product called DataStax Graph that you can use for free when not in production.
Today it will be a demo to be quick but you can as well do and start the demo with the following steps
✅ 5a. Prerequisites
Minimal Configuration: You need to have a computer with this minimal configuration requirements
- At least 2CPU
- At least 3GB or RAM
Install Docker and Docker Compose
You need to install Docker and Docker-compose on your machine
✅ 5b. Create a docker network named 'graph'
docker network create graph🖥️ Expected output
$workshop_introduction_to_nosql> docker network create graph
64f8bcc2dda416d6dc80ef3c1ac97902b9d90007842808308e9d741d179d9344✅ 5c.Clone this repository (or download ZIP from the github UI)
git clone https://github.com/datastaxdevs/workshop-introduction-to-nosql.git
cd workshop-introduction-to-nosql✅ 5d.Start the containers
Folder
datastax-studio-configis mapped to docker container (see:docker-compose.yamlfile) and dse studio runs as userstudiowithuid=997and >gui=997which needs RW access to that folder.Run this command if you are on a linux system:
sudo chown -R 997:997 ./datastax-studio-config
Start containers:
docker-compose up -d🖥️ Expected output
$workshop_introduction_to_nosql> docker-compose up -d
Creating dse ... done
Creating workshop-introduction-to-nosql_studio_1 ... doneWait for the application to start (30s) and open http://localhost:9091

✅ 5e.Check database connection
Open the ellipsis and click Connections

Select the default localhost connection

Check that dse is set for the host (pointing to a local cassandra)

Click the button Test and expect the output Connected Successfully

✅ 5f. Open the notebook Work
Use the ellipsis to now select Notebooks
Once the notebook opens it asks you to create the graph: click the Create Graph button (and leave all settings to default)

Execute cell after cell spotting the Real Time > button in each cell (top right)

Voila !

✅ 5g. Close Notebook
To close open notebooks you can now use
docker-compose down🖥️ Expected output
$workshop_introduction_to_nosql> docker-compose down
Stopping workshop-introduction-to-nosql_studio_1 ... done
Stopping dse ... Congratulations! You made it to the END.
See you next time!