
This repository is a summary of the content of lesson six of the Introduction to Machine Learning on Azure course which is part of the Microsoft Scholarship Foundation course Nanodegree Program on Udacity (July - September 2020).
As part of our role as student leaders, we will not only write this guide book, but also answer commonly asked question of the community. Furthermore, we will provide a list of resources to support your success in this course.
You can do it!
Managed services for Machine Learning can be used to outsource your local Machine Learning processes (Training, Inference and Notebook Testing) to the cloud. By using end-to-end automation via pipelines (DevOps for ML / MLOps), you can deploy to production environments easily. The examples in this lesson will use services provided by Azure Machine Learning.
In comparison to local development, you don't need to install any applications and libraries, as all this has been done already. You don't have to take care of the low level layers, so you can jump right in using your webbrowser!
Speaking of using your webbrowser, you might already know from the previous lessions, that you need to prelaunch your lab environment to get the scholarship account details. Visit this page and click on the blue Prelaunch Lab button before moving on.

Click here to view the notes of this lesson, written by @PriyankaUmre.
In this section, you will find step-by-step introductions for each lab, so you can easily progress. If there are any known errors in the original lab guide, corrections and workarounds are included in these steps.
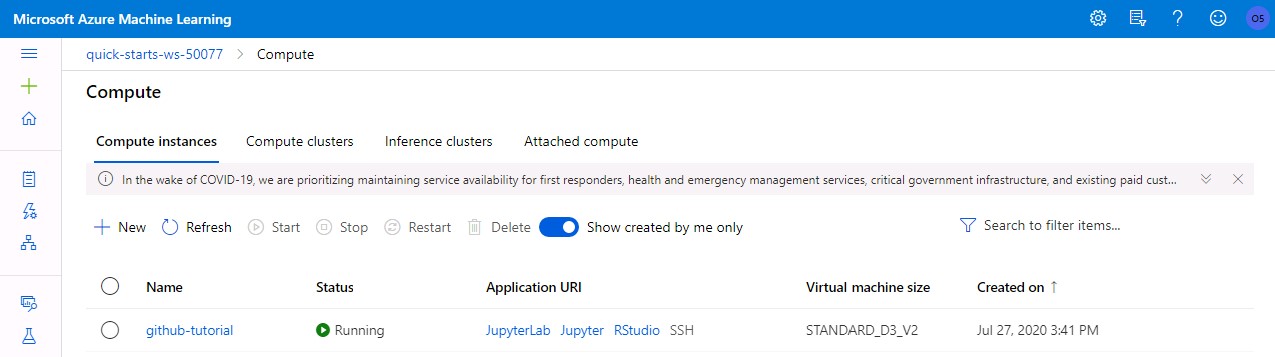
In this lab, you will learn how to create a new compute resource, how to modify an existing one and how to stop, restart or delete it.
- Open Workspace
- Enter the Studio by clicking Launch now and select a subscription and workspace as mentioned in the lab guide.
- Select Compute in the right menu.
- Select the Compute instances tab.
- Click on the Create button, choose a unique name of your choice and select a virtual machine from the dropdowns. For this lession, we will be using a CPU-based VM with size Standard_D3_v2.
- Click on Create and wait a few seconds (took 8 minutes in my case) until the shown status changes to Running.
- Select your compute resource in the list and click on its name to view details about the compute. You can also click on any of the buttons to stop, delete or restart the resource.
- Go back to the list of computes and take a look at the Application URI column. By clicking on any of the links, a new browser tab with the respective development environment will be launched.

In this lab, you will learn how to train a simple SciKit learn model using a managed jupyter notebook environment.
- Open Workspace
- Open the Studio and navigate to the Compute list, just as you did in the last lab. Note that you won't need to create a new instance this time, as the workspace will already have one prepared for you.
- In the Application URI column, click on the Jupyter link.
- In Jupyter, open a terminal by clicking on New and Terminal
- Download an example notebook by using
git clone https://github.com/solliancenet/udacity-intro-to-ml-labs.git - From within the Jupyter interface, navigate to directory
udacity-intro-to-ml-labs/aml-visual-interface/lab-19/notebookand open1st-experiment-sdk-train-model.ipynb. - Read through the notebook to get a quick overview
- Select "Cell" and "Run All" ´, click on the login-link in the first cells output and then wait for the run to be completed. If the run stops after the login cell, even though you logged in, just click on "Run All" again.
- in the directory
udacity-intro-to-ml-labs/aml-visual-interface/lab-19/notebook/outputs, you will find the trained.pklmodel file for each iteration (run).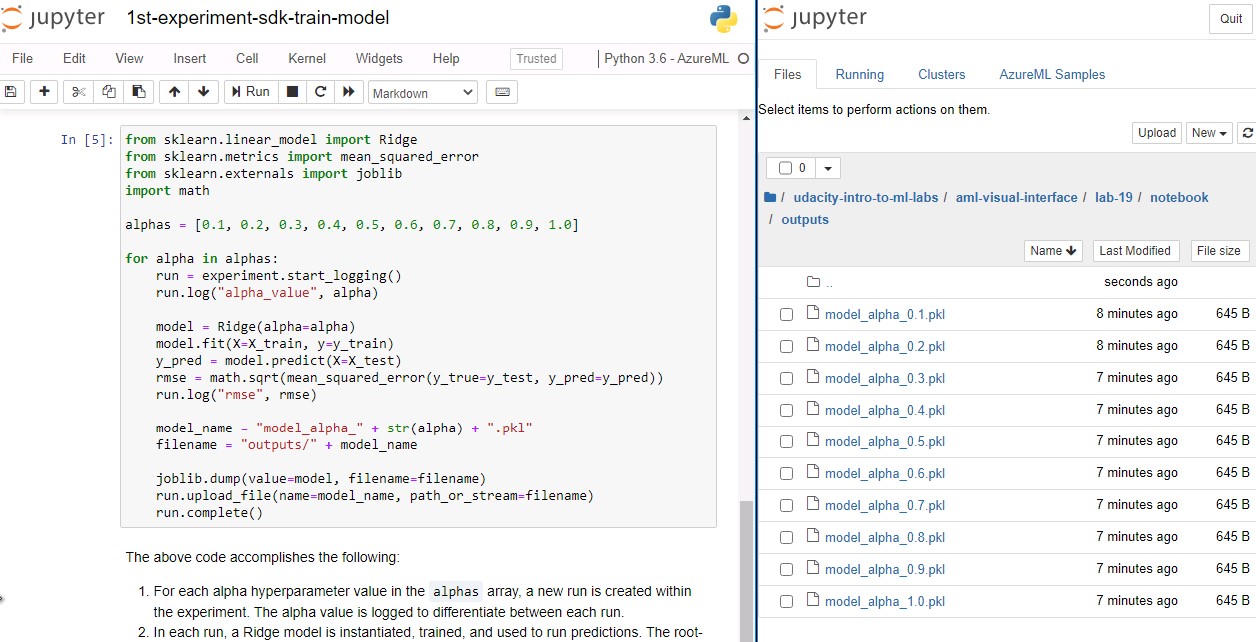
- Optional: Modify the notebook as you want and re-run code by clicking on "Kernel" and "Restart & Run All".

In this lab, you will learn how to create an experiment process and how to create and execute a run based on the experiment (which will train a model for you). We will also save the generated model to a model registry.
- Open Workspace
- Open the Jupyter Terminal and download the git repository just as you did in the last lab.
- From within the Jupyter interface, navigate to directory
udacity-intro-to-ml-labs/aml-visual-interface/lab-20/notebookand open1st-experiment-sdk-train-model.ipynb. - Run all of the code and check if the output has been generated, just as you did in the last lab. The output directory will this time be
udacity-intro-to-ml-labs/aml-visual-interface/lab-20/notebook/outputs. - Within Azure Machine Learning Studio, select Experiments in the left-hand menu, then select the diabetes-experiment, which is created by the notebook you just executed.
- Take a look at the dashboard and view details about the experiment and its runs.
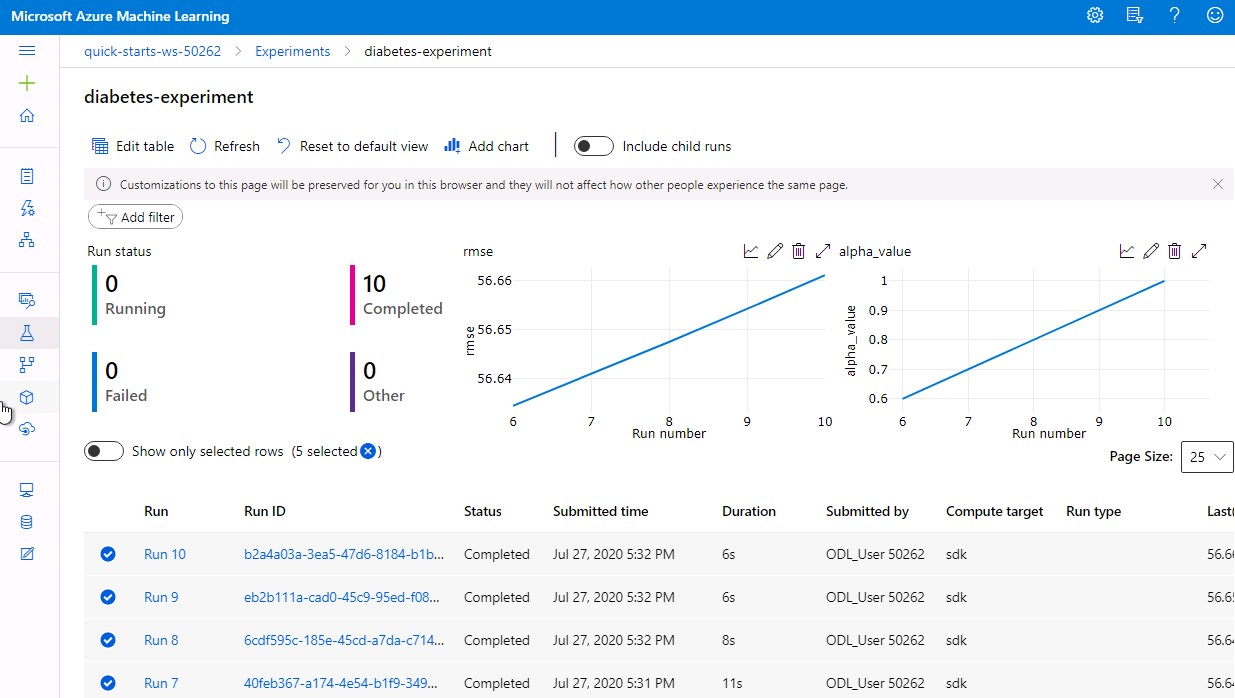
- Add additional columns to the run list by clicking on Edit table and moving the Start Time and End Time entries to the right. Close the window using the Save button.
- Click on one of the Run IDs to view information about a specific run. In the Outputs + logs tab, you should be able to see one of the outputs you previously saw inside the jupyter filebrowser. You can download the model if you like.

In this lab, you will learn how to create a ML pipeline including obtaining, importing and preparing data, building and training Models as well as deploying (=operationalizing) and predicting them. Such a MLOps integrated process will ensure model repoducibility, model validation, model deployment and model retraining.
A typical model deployment consists of:
- getting the model file
- creating a scoring script
- in some cases creating a schema file describing the web service input
- creating a (real-time or batch) inference web service which can be called from your application
- repeating the process for each time the model is retrained
These are the steps you need to do in the lab:
- Open Workspace
- Open the Studio just as you did in the previos labs
- Click on Designer in the left menu and create a new pipeline based on the Sample 1: Regression - Automobile Price Prediction... template.
- In the now open visual pipeline authoring editor settings, click on Select compute target and chose the existing entry from the list. Then, click Save and Submit, to open a popup window.
- In the Set up pipeline run popup, create a new experiment with a unique name of your choice.
- Wait for the pipeline run to complete (~10min). In the top-right corner, you will see the status of your experiment.
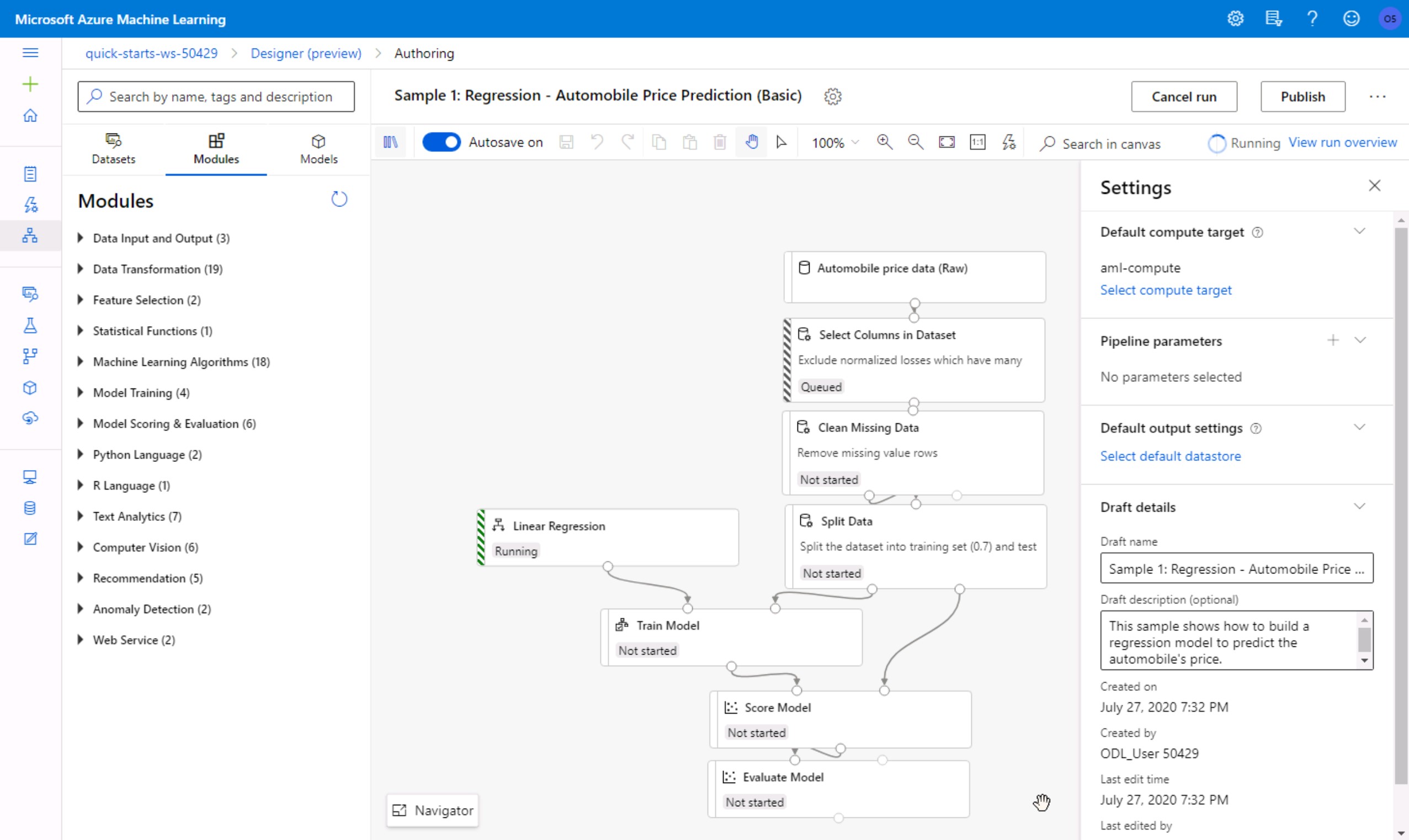
- Create a new real-time inference pipeline using the top-right button
- Click on the submit button, in the popup select your experiment and submit the popup. If you have trouble clicking the submit button, click the button to the right of the deploy button (three dots) and choose cloning. Once you clone, try again and the issue should be resolved.
- Wait for the pipeline run to finish (~7 min) and then click on Deploy.
- Deploy a new real-time endpoint using your existing compute target and wait for the deployment to complete.
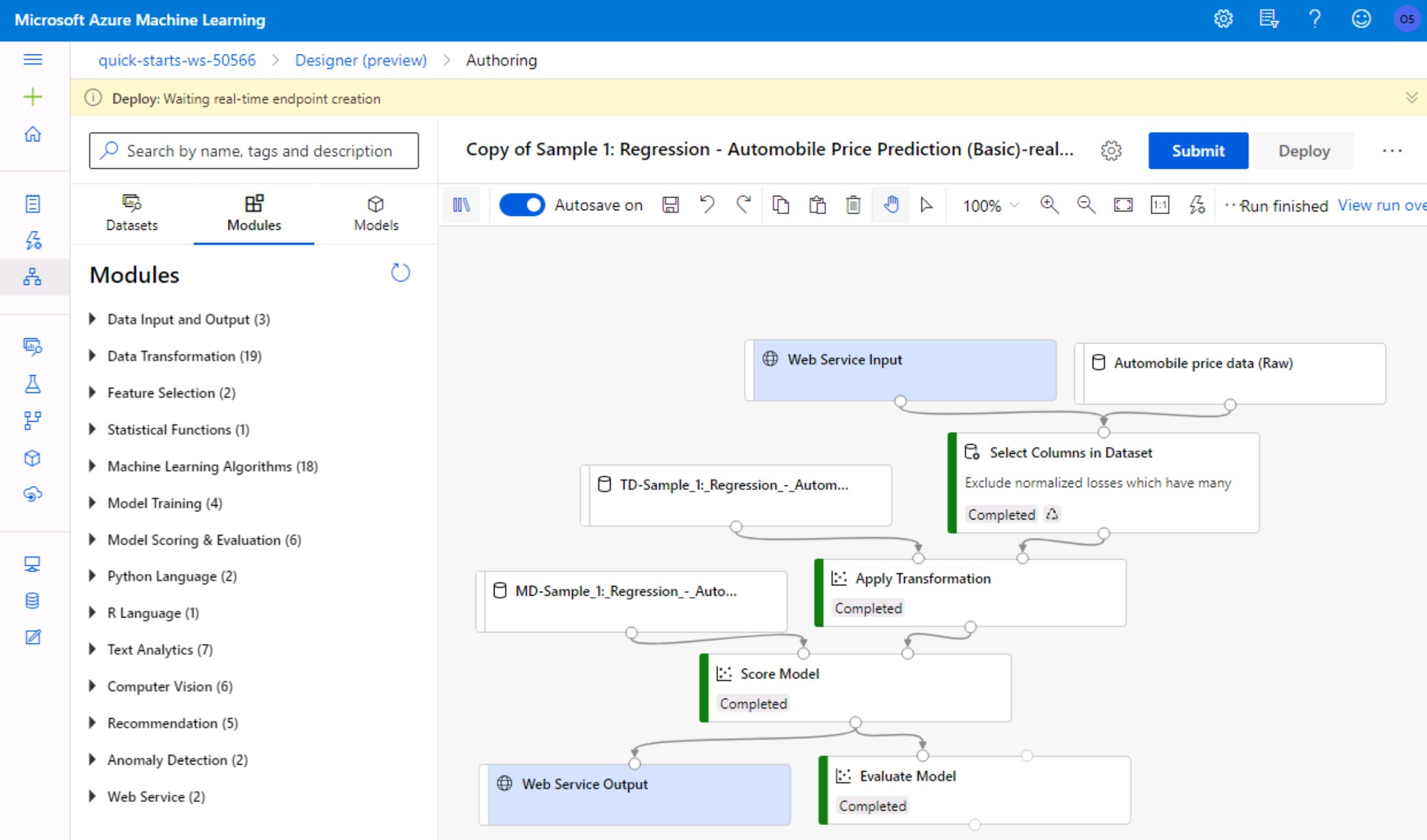
- To view information about the deployed web service, select Endpoints in the left menu and then click on the name of your created real-time endpoint.
- Change to the Consume tab to read the REST endpoint and authentification keys as well as code samples for calling the endpoint in C#, Python and R.
- Optional: If you want, you can copy the python code to a new compute notebook and run it, to see if you can access the web service endpoint.



In this lab, you will use the Azure ML Python SDK to register, package, deploy and test a trained model from source code instead of the GUI you used before.
- Open Workspace
- Open the Studio and open Jupyter from the Compute list, just as you did in the last labs.
- Open a new Terminal in Jupyter and clone the example code using
git clone https://github.com/solliancenet/udacity-intro-to-ml-labs.git. - From within the Jupyter interface, navigate to the directory
udacity-intro-to-ml-labs/aml-visual-interface/lab-22/notebookand opendeployment-with-AML.ipynb. - From your workspaces homepage (with the Launch Now button), copy the subsription id, resource group, workspace name and workspace region to the empty string variables in the jupyter notebook.

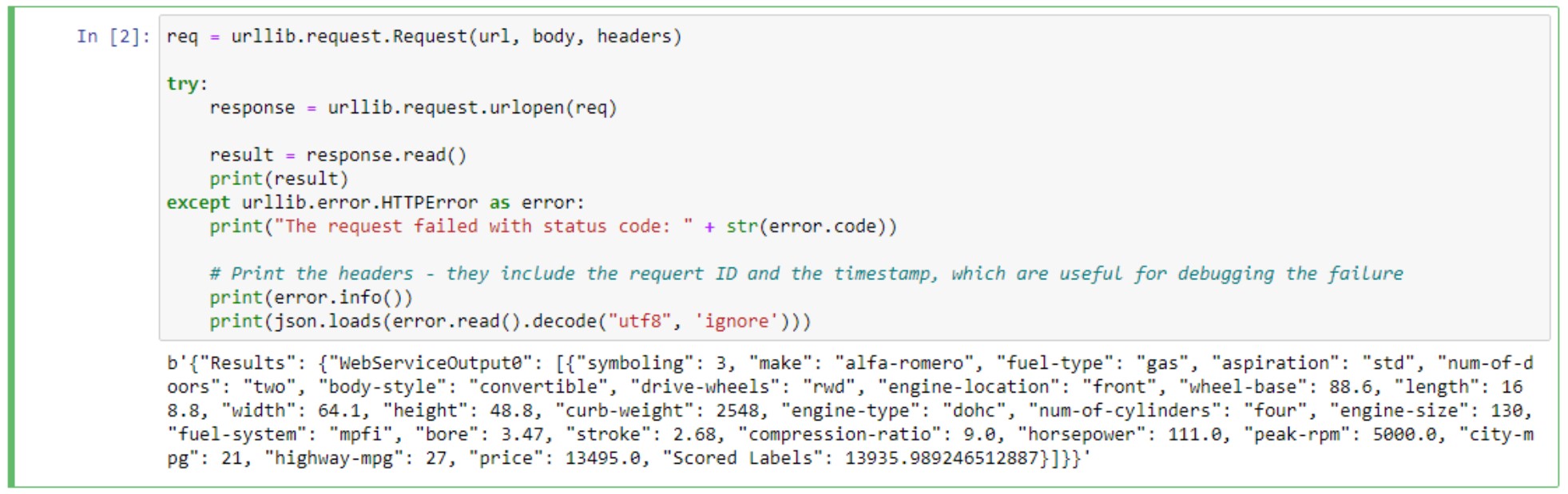
- Read through and run all the notebook cells. The notebook will create a docker container that will be run as our webservice and then make calls to this webservice.
- Check the Studio page, and you will see a new entry in the endpoints list.
This guide was written by the student leaders of lesson six: Kuldeep Singh Sidhu (🇮🇳 @singhsidhukuldeep), Ramkrishna Kundu (🇮🇳 @ramkundu) and Alexander Melde (🇩🇪 @AlexanderMelde).
Feel free to send pull requests or open an issue if you have any questions.
All commit messages should follow the Udacity Git Commit Message Style Guide.
The content of this repository is released under the MIT license.