Cloudbreak is a powerful left surf that breaks over a coral reef, a mile off southwest the island of Tavarua, Fiji.
Cloudbreak is a cloud agnostic Hadoop as a Service API. Abstracts the provisioning and ease management and monitoring of on-demand clusters.
Cloudbreak API documentation.
##Overview
Cloudbreak is a RESTful Hadoop as a Service API. Once it is deployed in your favorite servlet container exposes a REST API allowing to span up Hadoop clusters of arbitrary sizes on your selected cloud provider. Provisioning Hadoop has never been easier. Cloudbreak is built on the foundation of cloud providers API (Microsoft Azure, Amazon AWS, Google Cloud Platform, OpenStack), Apache Ambari, Docker containers, Swarm and Consul.
##Benefits
###Secure Supports basic, token based and OAuth2 authentication model. The cluster is provisioned in a logically isolated network (Virtual Private Cloud) of your favorite cloud provider. Cloudbreak does not store or manage your cloud credentials - it is the end user's responsibility to link the Cloudbreak user with her/his cloud account.
###Elastic Using Cloudbreak API you can provision an arbitrary number of Hadoop nodes - the API does the hard work for you, and span up the infrastructure, configure the network and the selected Hadoop components and services without any user interaction. POST once and use it anytime after.
###Scalable As your workload changes, the API allows you to add or remove nodes on the fly. Cloudbreak does the hard work of reconfiguring the infrastructure, provision or decommission Hadoop nodes and let the cluster be continuously operational. Once provisioned, new nodes will take up the load and increase the cluster throughput.
###Declarative Hadoop clusters We support declarative Hadoop cluster creation - using blueprints. Blueprints are a declarative definition of your stack, the component/services layout and the configurations to materialize a Hadoop cluster instance.
###Flexible You have the option to choose your favorite cloud provider and their different pricing models. The API translates the calls towards different vendors. Nevertheless you integrate and use one common API, there is no need to rewrite your code when changing between cloud providers.
##How it works?
Cloudbreak launches on-demand Hadoop clusters on your favorite cloud provider in minutes. We have introduced 4 main notions - the core building blocks of the REST API.
###Templates
A template gives developers and systems administrators an easy way to create and manage a collection of cloud infrastructure related resources, maintaining and updating them in an orderly and predictable fashion.
Templates are cloud specific - and on top of the infrastructural setup they collect the information such as the used machine images, the datacenter location, instance types, and can capture and control region-specific infrastructure variations. We support heterogenous clusters - this means that one Hadoop cluster can be built by combining different templates.
A template can be used repeatedly to create identical copies of the same stack (or to use as a foundation to start a new stack).
The infrastructure specific configuration is available under the Cloudbreak resources. As an example for Amazon EC2, we use AWS Cloudformation to define the cloud infrastructure.
For further information please visit our API documentation.
###Stacks
Stacks are template instances - a running cloud infrastructure created based on a template. Stacks are always launched on behalf of a cloud user account. Stacks support a wide range of resources, allowing you to build a highly available, reliable, and scalable infrastructure for your application needs.
For further information please visit our API documentation.
###Blueprints
Ambari Blueprints are a declarative definition of a Hadoop cluster. With a Blueprint, you specify a stack, the component layout and the configurations to materialize a Hadoop cluster instance. Hostgroups defined in blueprints can be associated to different templates, thus you can spin up a highly available cluster running on different instance types. This will give you the option to group your Hadoop services based on resource needs (e.g. high I/O, CPU or memory) and create an infrastructure which fits your workload best.
We have a few default blueprints available from multinode, streaming to analytic ones.
For further information please visit our API documentation.
###Cluster
Clusters are materialized Hadoop services on a given infrastructure. They are built based on a Blueprint (running the components and services specified) and on a configured infrastructure Stack. Once a cluster is created and launched, it can be used the usual way as any Hadoop cluster. We suggest to start with the Cluster's Ambari UI for an overview of your cluster.
For further information please visit our API documentation.
##Technology
Cloudbreak is built on the foundation of cloud providers APIs, Apache Ambari, Docker containers, Swarm and Consul.
###Apache Ambari
The Apache Ambari project is aimed at making Hadoop management simpler by developing software for provisioning, managing, and monitoring Apache Hadoop clusters. Ambari provides an intuitive, easy-to-use Hadoop management web UI backed by its RESTful APIs.
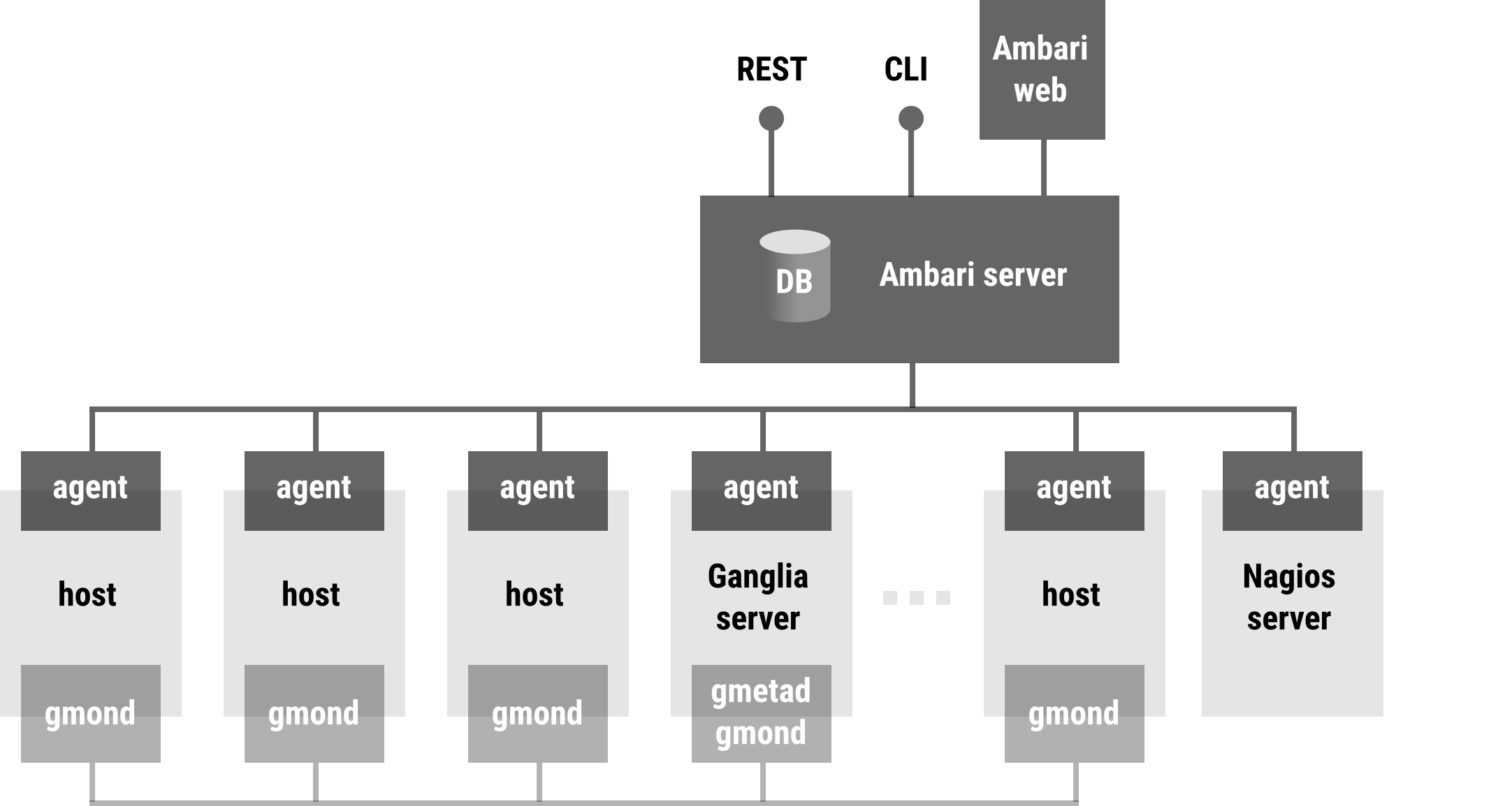
Ambari enables System Administrators to:
- Provision a Hadoop Cluster
- Ambari provides a step-by-step wizard for installing Hadoop services across any number of hosts.
- Ambari handles configuration of Hadoop services for the cluster.
- Manage a Hadoop Cluster
- Ambari provides central management for starting, stopping, and reconfiguring Hadoop services across the entire cluster.
- Monitor a Hadoop Cluster
- Ambari provides a dashboard for monitoring health and status of the Hadoop cluster.
- Ambari leverages Ganglia for metrics collection.
- Ambari leverages Nagios for system alerting and will send emails when your attention is needed (e.g. a node goes down, remaining disk space is low, etc).
Ambari enables to integrate Hadoop provisioning, management and monitoring capabilities into applications with the Ambari REST APIs. Ambari Blueprints are a declarative definition of a cluster. With a Blueprint, you can specify a Stack, the Component layout and the Configurations to materialise a Hadoop cluster instance (via a REST API) without having to use the Ambari Cluster Install Wizard.

###Docker
Docker is an open platform for developers and sysadmins to build, ship, and run distributed applications. Consisting of Docker Engine, a portable, lightweight runtime and packaging tool, and Docker Hub, a cloud service for sharing applications and automating workflows, Docker enables apps to be quickly assembled from components and eliminates the friction between development, QA, and production environments. As a result, IT can ship faster and run the same app, unchanged, on laptops, data center VMs, and any cloud.
The main features of Docker are:
- Lightweight, portable
- Build once, run anywhere
- VM - without the overhead of a VM
- Each virtualised application includes not only the application and the necessary binaries and libraries, but also an entire guest operating system
- The Docker Engine container comprises just the application and its dependencies. It runs as an isolated process in userspace on the host operating system, sharing the kernel with other containers.

- Containers are isolated
- It can be automated and scripted
###Swarm
Docker Swarm is native clustering for Docker. It turns a pool of Docker hosts into a single, virtual host. Swarm serves the standard Docker API.
- Distributed container orchestration: Allows to remotely orchestrate Docker containers on different hosts
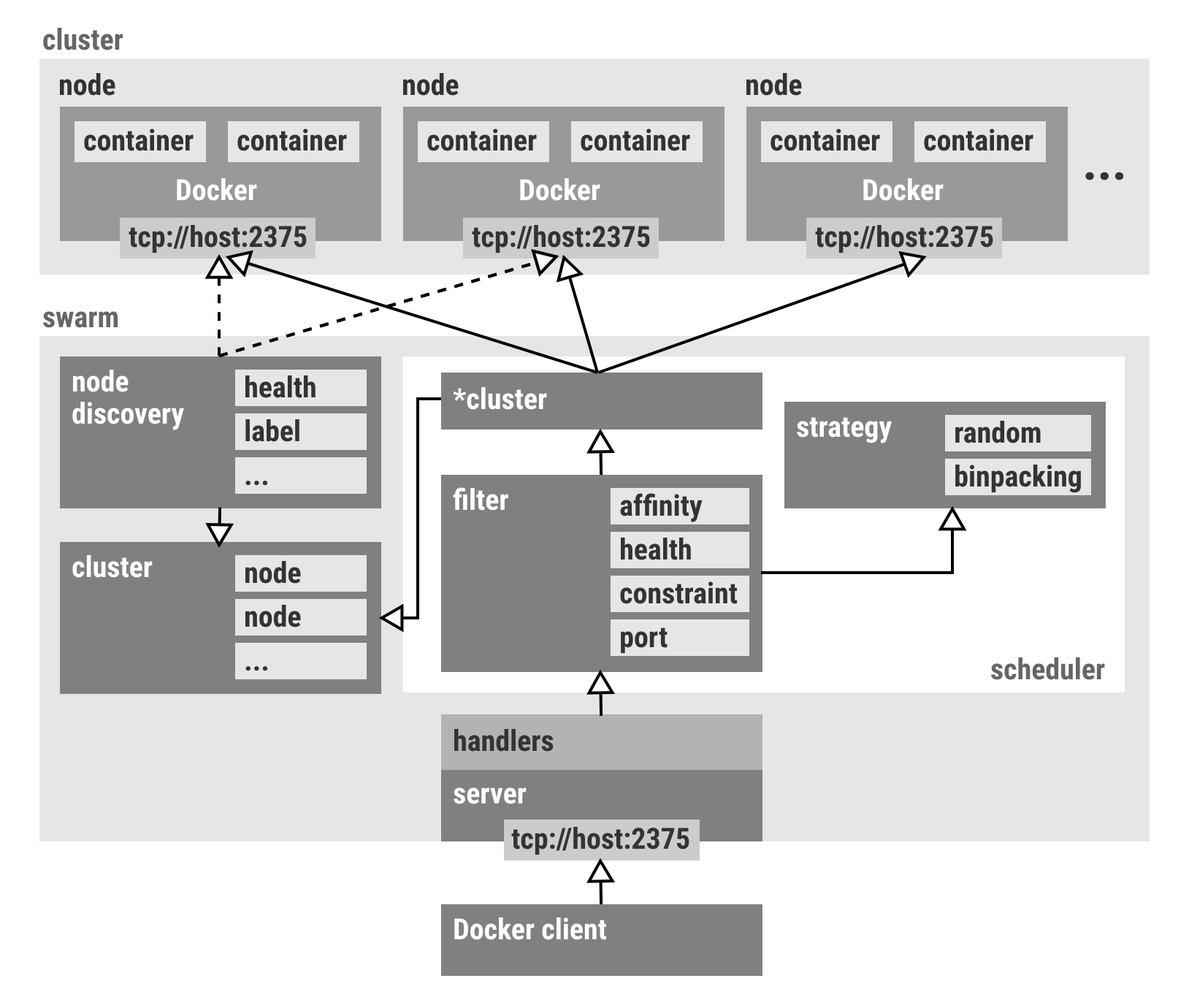
- Discovery services: Supports different discovery backends to provide service discovery, as such: token (hosted) and file based, etcd, Consul, Zookeeper.
- Advanced scheduling: Swarm will schedule containers on hosts based on different filters and strategies
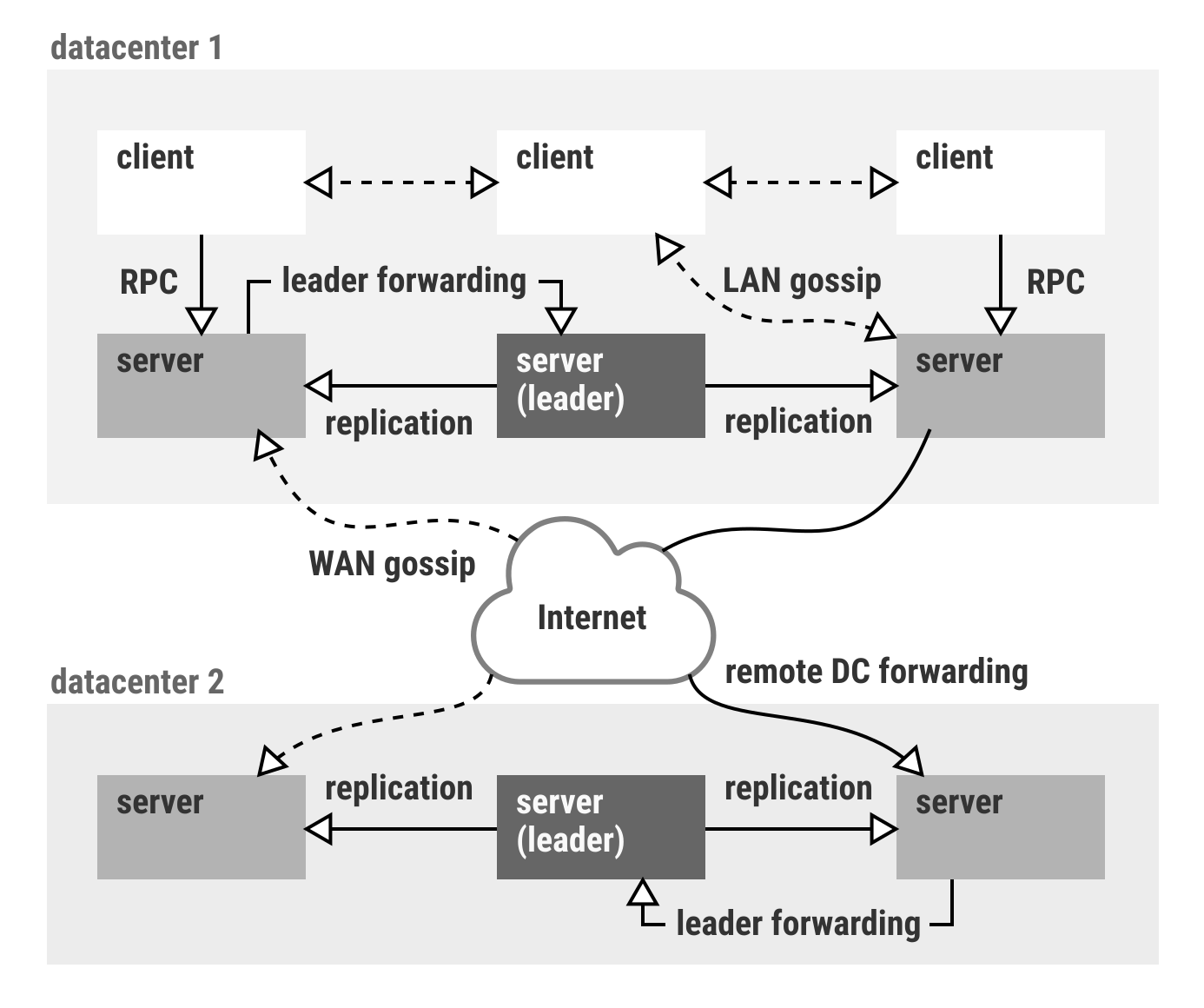
###Consul
Consul it is a tool for discovering and configuring services in your infrastructure. It provides several key features
-
Service Discovery: Clients of Consul can provide a service, such as api or mysql, and other clients can use Consul to discover providers of a given service. Using either DNS or HTTP, applications can easily find the services they depend upon.
-
Health Checking: Consul clients can provide any number of health checks, either associated with a given service ("is the webserver returning 200 OK"), or with the local node ("is memory utilization below 90%"). This information can be used by an operator to monitor cluster health, and it is used by the service discovery components to route traffic away from unhealthy hosts.
-
Key/Value Store: Applications can make use of Consul's hierarchical key/value store for any number of purposes, including dynamic configuration, feature flagging, coordination, leader election, and more. The simple HTTP API makes it easy to use.
-
Multi Datacenter: Consul supports multiple datacenters out of the box. This means users of Consul do not have to worry about building additional layers of abstraction to grow to multiple regions.
##Supported components
Ambari supports the concept of stacks and associated services in a stack definition. By leveraging the stack definition, Ambari has a consistent and defined interface to install, manage and monitor a set of services and provides extensibility model for new stacks and services to be introduced.
At high level the supported list of components can be grouped into main categories: Master and Slave - and bundling them together form a Hadoop Service.
| Services | Components |
|---|---|
| HDFS | DATANODE, HDFS_CLIENT, JOURNALNODE, NAMENODE, SECONDARY_NAMENODE, ZKFC |
| YARN | APP_TIMELINE_SERVER, NODEMANAGER, RESOURCEMANAGER, YARN_CLIENT |
| MAPREDUCE2 | HISTORYSERVER, MAPREDUCE2_CLIENT |
| GANGLIA | GANGLIA_MONITOR, GANGLIA_SERVER |
| HBASE | HBASE_CLIENT, HBASE_MASTER, HBASE_REGIONSERVER |
| HIVE | HIVE_CLIENT, HIVE_METASTORE, HIVE_SERVER, MYSQL_SERVER |
| HCATALOG | HCAT |
| WEBHCAT | WEBHCAT_SERVER |
| OOZIE | OOZIE_CLIENT, OOZIE_SERVER |
| PIG | PIG |
| SQOOP | SQOOP |
| STORM | DRPC_SERVER, NIMBUS, STORM_REST_API, STORM_UI_SERVER, SUPERVISOR |
| TEZ | TEZ_CLIENT |
| FALCON | FALCON_CLIENT, FALCON_SERVER |
| ZOOKEEPER | ZOOKEEPER_CLIENT, ZOOKEEPER_SERVER |
| SPARK | SPARK_JOBHISTORYSERVER, SPARK_CLIENT |
| RANGER | RANGER_USERSYNC, RANGER_ADMIN |
| AMBARI_METRICS | AMBARI_METRICS, METRICS_COLLECTOR, METRICS_MONITOR |
| KERBEROS | KERBEROS_CLIENT |
| FLUME | FLUME_HANDLER |
| KAFKA | KAFKA_BROKER |
| KNOX | KNOX_GATEWAY |
| NAGIOS | NAGIOS_SERVER |
We provide a list of default Hadoop cluster Blueprints for your convenience, however you can always build and use your own Blueprint.
- hdp-small-default - HDP 2.2 blueprint
This is a complex Blueprint which allows you to launch a multi node, fully distributed HDP 2.2 Cluster in the cloud.
It allows you to use the following services: HDFS, YARN, MAPREDUCE2, KNOX, HBASE, HIVE, HCATALOG, WEBHCAT, SLIDER, OOZIE, PIG, SQOOP, METRICS, TEZ, FALCON, ZOOKEEPER.
- hdp-streaming-cluster - HDP 2.2 blueprint
This is a streaming Blueprint which allows you to launch a multi node, fully distributed HDP 2.2 Cluster in the cloud, optimized for streaming jobs.
It allows you to use the following services: HDFS, YARN, MAPREDUCE2, STORM, KNOX, HBASE, HIVE, HCATALOG, WEBHCAT, SLIDER, OOZIE, PIG, SQOOP, METRICS, TEZ, FALCON, ZOOKEEPER.
- hdp-spark-cluster - HDP 2.2 blueprint
This is an analytics Blueprint which allows you to launch a multi node, fully distributed HDP 2.2 Cluster in the cloud, optimized for analytic jobs.
It allows you to use the following services: HDFS, YARN, MAPREDUCE2, SPARK, ZEPPELIN, KNOX, HBASE, HIVE, HCATALOG, WEBHCAT, SLIDER, OOZIE, PIG, SQOOP, METRICS, TEZ, FALCON, ZOOKEEPER.
##Accounts
###Cloudbreak account
First and foremost in order to start launching Hadoop clusters you will need to create a Cloudbreak account. Cloudbreak supports registration, forgotten and reset password, and login features at API level. All passwords that are stored or sent are hashed - communication is always over a secure HTTPS channel. When you are deploying your own Cloudbreak instance we strongly suggest to configure an SSL certificate. Users create and launch Hadoop clusters on their own namespace and security context.
Users can be invited under an account by the administrator, and all resources (e.g. resources, networks, blueprints, credentials, clusters) can be shared across account users.
-
Usage explorer: Cloudbreak gives you an up to date overview of cluster usage based on different filtering criteria (start/end date, users, providers, region, etc).
-
Account details: The account details of the user.
-
Manage users: You can invite, active and deactivate users under the account.
###Cloudbreak credentials
Cloudbreak is launching Hadoop clusters on the user's behalf - on different cloud providers. One key point is that Cloudbreak does not store your Cloud provider account details (such as username, password, keys, private SSL certificates, etc). We work around the concept that Identity and Access Management is fully controlled by you - the end user. The Cloudbreak deployer is purely acting on behalf of the end user - without having access to the user's account.
How does this work?
###Configuring the AWS EC2 account
Once you have logged in Cloudbreak you will have to link your AWS account with the Cloudbreak one. In order to do that you will need to configure an IAM Role.
You can do this on the management console, or - if you have aws-cli configured - by running a small script we're providing in the docs/aws folder.
####Create IAM role on the console
- Log in to the AWS management console with the user account you'd like to use with Cloudbreak
- Go to IAM, select "Roles", click Create New Role
- Give your role a name.
- Setup your role access:
-
Select Role for Cross-Account access
- Allows IAM users from a 3rd party AWS account to access this account.
Account ID: In case you are using our hosted solution you will need to pass SequenceIQ's account id: 755047402263
External ID: provision-ambari (association link)
-
Custom policy
Use this policy document to configure the permission to start EC2 instances on the end user's behalf, and use SNS to receive notifications.
####Create IAM role with the create script
- Download this script, e.g:
curl -O https://raw.githubusercontent.com/sequenceiq/cloudbreak/master/docs/aws/create-iam-role.sh - Make sure you have the AWS CLI installed and on your path.
- Run
./create-iam-role - Copy the resulting role ARN
Once this is configured, Cloudbreak is ready to launch Hadoop clusters on your behalf. The only thing Cloudbreak requires is the Role ARN (Role for Cross-Account access).
###Configuring the Microsoft Azure account
In order to launch Hadoop clusters on the Microsoft Azure cloud platform you'll need to link your Azure account with Cloudbreak. This can be achieved by creating a new Azure Credential in Cloudbreak.
You'll need an X509 certificate with a 2048-bit RSA keypair.
Generate these artifacts with openssl by running the following command, and answering the questions in the command prompt:
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout my_azure_private.key -out my_azure_cert.pem
The command generates the following files into the directory you run the command from: my_azure_private.key and my_azure_cert.pem
Fill the form by providing your Azure Subscription Id, and the content of the previously generated certificate (my_azure_cert.pem).
Note: Cloudbreak will generate a JKS file (stored by the backend) and a certificate with the passphrase. You will need to upload the generated certificate (that is automatically downloaded to you after the form submission, alternatively you can download it any time from Cloudbreak) to your Azure account:
On your Azure Management Console, Settings menu, click the Management Certificates tab and upload the downloaded cert file
The JKS file and certificate will be used to encrypt the communication between Cloudbreak and Azure in both directions.
You are done - from now on Cloudbreak can launch Azure instances on your behalf.
Note: Cloudbreak does not store any login details for these instances - you can specify a password or SSH Public key that can be used to login into the launched instances.
Note: Because Azure does not directly support third party public images Cloudbreak will copy the used image from VM Depot into your storage account. The steps below need to be finished ONCE and only ONCE before any stack is created for every affinity group - this is an automated step - it's only highlighted here as an explanation of why provisioning takes longer at first time:
1. Get the VM image - http://vmdepot.msopentech.com/Vhd/Show?vhdId=42480&version=43564
2. Copy the VHD blob from above (community images) into your storage account
3. Create a VM image from the copied VHD blob.
This process will take 20 minutes so be patient - but this step will have do be done once and only once.
###Configuring the Google Cloud account
Follow the instructions in Google Cloud's documentation to create a Service account and Generate a new P12 key.
Make sure that at API level (APIs and auth menu) you have enabled:
- Google Compute Engine
- Google Compute Engine Instance Group Manager API
- Google Compute Engine Instance Groups API
- BigQuery API
- Google Cloud Deployment Manager API
- Google Cloud DNS API
- Google Cloud SQL
- Google Cloud Storage
- Google Cloud Storage JSON API
When creating GCP credentials in Cloudbreak you will have to provide the email address of the Service Account and the project ID (from Google Developers Console - Projects) where the service account is created. You'll also have to upload the generated P12 file and provide an OpenSSH formatted public key that will be used as an SSH key.
##Roles
Cloudbreak defines three distinct roles:
- DEPLOYER
- ACCOUNT_ADMIN
- ACCOUNT_USER
###Cloudbreak deployer
This is the master role - the user which is created during the deployment process will have this role.
###Account admin We have introduced the notion of accounts - and with that comes an administrator role. Upon registration a user will become an account administrator.
The extra rights associated with the account admin role are:
- Invite users to join the account
- Share account wide resources (credential, blueprints, templates)
- See resources created by account users
- Monitor clusters started by account users
- Management and reporting tool available
###Account user An account user is a user who has been invited to join Cloudbreak by an account administrator. Account users activity will show up in the management and reporting tool for account wide statistics - accessible by the account administrator. Apart from common account wide resources, the account users can manage their own private resources.
##Cloudbreak UI
When we have started to work on Cloudbreak, our main goal was to create an easy to use, cloud and Hadoop distribution agnostic Hadoop as a Service API. Though we always like to automate everything and approach things with a very DevOps mindset, as a side project we have created a UI for Cloudbreak as well.
The goal of the UI is to ease to process and allow you to create a Hadoop cluster on your favorite cloud provider in one-click.
The UI is built on the foundation of the Cloudbreak REST API. You can access the UI here.
###User registration
While we consider the registration process quite simple, we'd like to explain the notion of companies. When a user registers as a company admin it means that he will be the administrator of that company - further colleagues will have the opportunity to join the company upon being invited by the admin user.
###Manage credentials Using manage credentials you can link your cloud account with the Cloudbreak account.
Amazon AWS
Name: name of your credential
Description: short description of your linked credential
Role ARN: the role string - you can find it at the summary tab of the IAM role
SSH public key: an SSH public key in OpenSSH format that's private keypair can be used to log into the launched instances later
Public in account: share it with others in the account
The ssh username is ec2-user
Azure
Name: name of your credential
Description: short description of your linked credential
Subscription Id: your Azure subscription id - see Accounts
File password: your generated JKS file password - see Accounts
SSH certificate: the SSH public certificate in OpenSSH format that's private keypair can be used to log into the launched instances later (The key generation process is described in the Configuring the Microsoft Azure account section)
The ssh username is cloudbreak
Google Cloud Platform
Name: name of your credential
Description: short description of your linked credential
Project Id: your GCP Project id - see Accounts
Service Account Email Address: your GCP service account mail address - see Accounts
Service Account private (p12) key: your GCP service account generated private key - see Accounts
SSH public key: the SSH public key in OpenSSH format that's private keypair can be used to log into the launched instances later
Public in account: share it with others in the account
The ssh username is cloudbreak.
OpenStack
Name: name of your credential
Description: short description of your linked credential
User: OpenStack user name
Password: OpenStack user's password name
Tenant Name: OpenStack tenant's (project) name
Endpoint: OpenStack API address endpoint's
SSH public key: the SSH public key to be used to log into the launched instances later
Public in account: share it with others in the account
###Manage resources Using manage resources you can create infrastructure templates.
Amazon AWS
Name: name of your template
Description: short description of your template
Instance type: the Amazon instance type to be used - we suggest to use at least small or medium instances
Volume type: option to choose are SSD, regular HDD (both EBS) or Ephemeral
Attached volumes per instance: the number of disks to be attached
Volume size (GB): the size of the attached disks (in GB)
Spot price: option to set a spot price - not mandatory, if specified we will request spot price instances (which might take a while or never be fulfilled by Amazon)
EBS encryption: this feature is supported with all EBS volume types (General Purpose (SSD), Provisioned IOPS (SSD), and Magnetic
Public in account: share it with others in the account
Azure
Name: name of your template
Description: short description of your template
Instance type: the Azure instance type to be used - we suggest to use at least D2 or D4 instances
Attached volumes per instance: the number of disks to be attached
Volume size (GB): the size of the attached disks (in GB)
Public in account: share it with others in the account
Google Cloud Platform
Name: name of your template
Description: short description of your template
Instance type: the Google instance type to be used - we suggest to use at least small or medium instances
Volume type: option to choose SSD or regular HDD
Attached volumes per instance: the number of disks to be attached
Volume size (GB): the size of the attached disks (in GB)
Public in account: share it with others in the account
OpenStack
Name: name of your template
Description: short description of your template
Public Net Id: the public net id
Attached volumes per instance: the number of disks to be attached
Volume size (GB): the size of the attached disks (in GB)
Public in account: share it with others in the account
###Manage blueprints Blueprints are your declarative definition of a Hadoop cluster.
Name: name of your blueprint
Description: short description of your blueprint
Source URL: you can add a blueprint by pointing to a URL. As an example you can use this blueprint.
Manual copy: you can copy paste your blueprint in this text area
Public in account: share it with others in the account
###Manage networks Manage networks allows you to create or reuse existing networks and configure them.
Name: name of the network
Description: short description of your network
Subnet (CIDR): a subnet in the VPC with CIDR block
Address prefix (CIDR): the address space that is used for subnets (Azure only)
Public network ID: the publuc network id (OpenStack only)
Public in account: share it with others in the account
###Manage security groups Security groups allows confoguration of traffic/access to the cluster. Currently there are two default groups, and leter versions will allow setup of new groups.
only-ssh-and-ssl: all ports are locked down (you can't access Hadoop servives outside of the VPN) but SSH (22) and HTTPS (443)
all-services-port: all Hadoop services + SSH/HTTP are accessible by default
###Create cluster Using the create cluster functionality you will create a cloud Stack and a Hadoop Cluster. In order to create a cluster you will have to select a credential first.
Note: Cloudbreak can maintain multiple cloud credentials (even for the same provider).
Cluster name: your cluster name
Region: the region where the cluster is started
Network: the network template
`Security Group:" the security group
Blueprint: your Hadoop cluster blueprint. Once the blueprint is selected we parse it and give you the option to select the followings for each hostgroup.
Hostgroup configuration
Group size: the number of instances to be started
Template: the stack template associated to the hostgroup
Public in account: share it with others in the account
Advanced features:
Consul server count: the number of Consul servers (odd number), by default is 3. It varies with the cluster size.
Minimum cluster size: the provisioning strategy in case of the cloud provider can't allocate all the requested nodes
Validate blueprint: feature to validate or not the Ambari blueprint. By default is switched on.
Ambari Repository config: you can take the stack RPM's from a custom stack repository
Once you have launched the cluster creation you can track the progress either on Cloudbreak UI or your cloud provider management UI.
###Manage cluster
The provisioned cluster can be managed from the Details tab. There are a few lifecycle management options available.
Termimate: terminates the infrastrucre and removes all cloud resources, including data
Stop: stops the infrastructure but keeps the data; a stopped cluster can be rebroight to the same state as previously been
Start: starts up the stopped cluster
Synch: resync the cluster state and metadata
Note: in a cloud based environment due to remote VM or Ambari service failures the local state of the cluster can be unsychronized from the remote cluster state - using the synch button the cluster is resynchronized and the right values are shown (e.g. number and types of instances, Ambari service health, etc).
Reinstall: due to wrong Blueprints sometimes the cluster can't be provisioned. With re-install the stack provisionig can be restarted using the already provisioned cloud infrastructure
Note: Because Azure does not directly support third party public images we will have to copy the used image from VM Depot into your storage account. The steps below need to be finished once and only once before any stack is created for every affinity group:
1. Get the VM image - http://vmdepot.msopentech.com/Vhd/Show?vhdId=42480&version=43564
2. Copy the VHD blob from above (community images) into your storage account
3. Create a VM image from the copied VHD blob.
This process will take 20 minutes so be patient - but this step will have do be done once and only once.
##Stack lifecycle
In order to understand the state of your Hadoop as a Servie stack and the potential outcomes we have put together a UML state diagram.
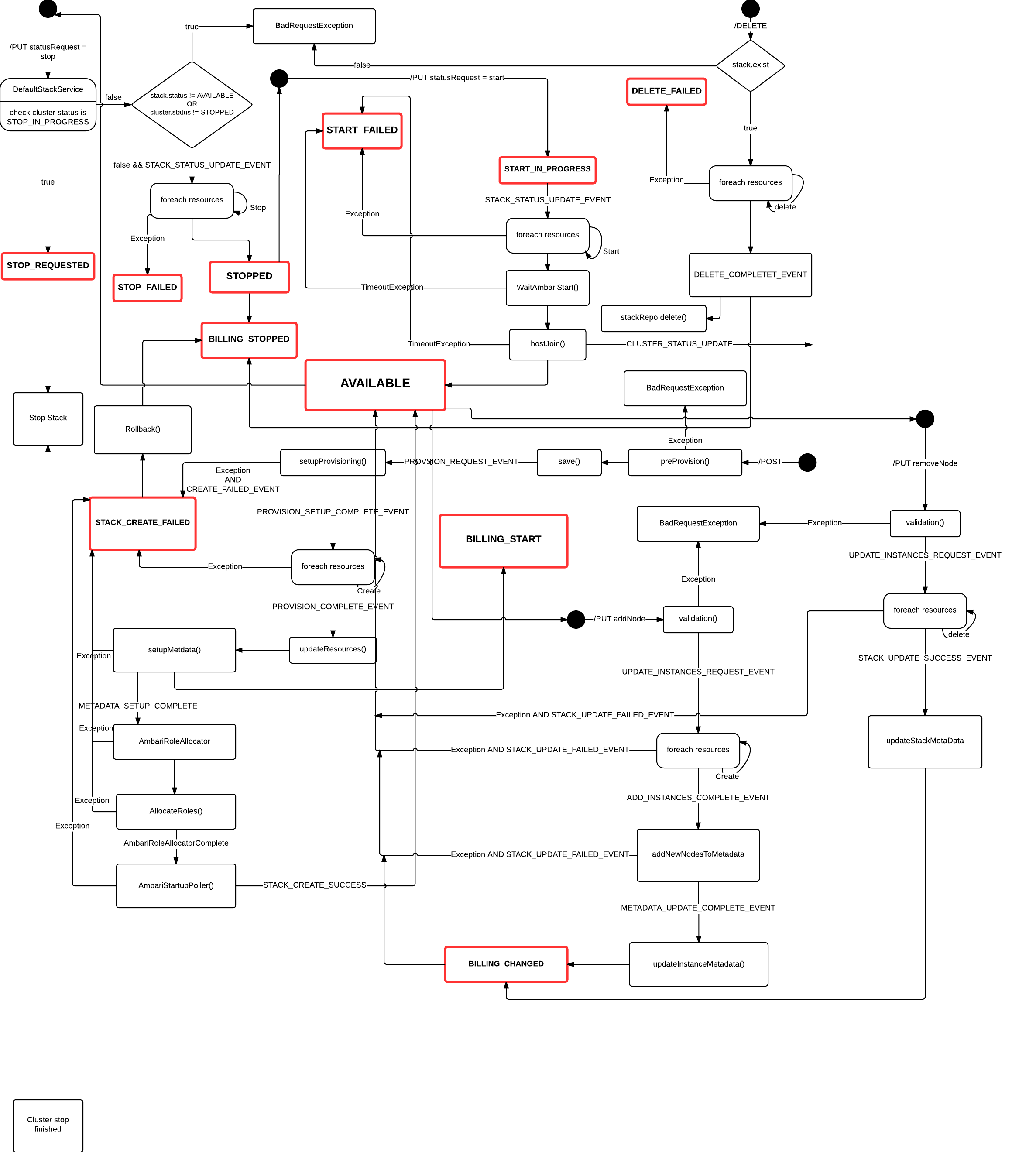
##QuickStart and installation
We provide you two different ways to start using Cloudbreak. The simplest and easiest solution is hosted by SequenceIQ, however we encourage you to get Cloudbreak and deployed it on-premise or on your favorite cloud provider. The hosted solution is for demo purposes only and not recommended for production systems.
###Hosted - Cloudbreak
The easiest way to start your own Hadoop cluster in your favorite cloud provider is to use our hosted solution. We host, maintain and support Cloudbreak for you.
Please note that Cloudbreak is launching Hadoop clusters on the user's behalf - on different cloud providers. We do not store your cloud provider account details (such as username, password, keys, private SSL certificates, etc), but work around the concept that Identity and Access Management is fully controlled by you - the end user.
Though Cloudbreak controls your Hadoop cluster lifecycle (start, stop, pause), we do not have access to the launched instances. The Hadoop clusters created by Cloudbreak are private to you.
###DIY - Deploying Cloudbreak
This is the recommended way to use Cloudbreak. Cloudbreak is deployed as orchestrated Docker containers. We have created a project which guides you through the self deployment. Use the following link.
##Misc
###Gateway node
All communication with the provisioned cluster goes through a gateway node. The communication is over TLS. The cluster is provisioned in a locked down VPC with all the access towards externally accessible Hadoop services closed. In order to access the services (Cloudbreak lists all the available services) the ports will have to be opened using the cloud provider's specific security group configuration.
###Base images
Cloudbreak comes with default base images - based on CentOS/RHEL 7. Should you want to use a different image please contact us.
AWS: RHEL 7.1 https://aws.amazon.com/marketplace/pp/B00VIMU19E
Microsoft Azure: Centos 7.1 Openlogic http://azure.microsoft.com/en-in/marketplace/partners/openlogic/centosbased71/
Google Cloud Platform: centos-7-v20150603
##Releases, future plans
When we have started to work on Cloudbreak the idea was to democratise the usage of Hadoop in the cloud and VMs. For us this was a necessity as we often had to deal with different Hadoop versions, distributions and cloud providers.
Also we needed to find a way to speed up the process of adding new cloud providers, and be able to ship Hadoop between clouds without re-writing and re-engineering our code base each and every time - welcome Docker.
All the Hadoop ecosystem related code, configuration and services are inside Docker containers - and these containers are launched on VMs of cloud providers or physical hardware - the end result is the same: a resilient and dynamic Hadoop cluster.
We needed to find a unified way to provision, manage and configure Hadoop clusters - welcome Apache Ambari.
###Public Beta The first public beta version of Cloudbreak supports Hadoop on Amazon's EC2, Microsoft's Azure, Google Cloud Platform and OpenStack cloud providers. The supported Hadoop platform is the Hortonworks Data Platform - the 100% open source Hadoop distribution.
Versions:
CentOS - 6.5 Hortonworks Data Platform - 2.2 Apache Hadoop - 2.6.0 Apache Tez - 0.6 Apache Pig - 0.14 Apache Hive & HCatalog - 0.14.0 Apache HBase - 0.98.4 Apache Phoenix - 4.2 Apache Accumulo - 1.6.1 Apache Storm - 0.9.3 Apache Spark - 1.2.0 Apache Slider - 0.5.1 Apache Solr - 4.10.0 Apache Kafka - 0.8.1 Apache Falcon - 0.6.0 Apache Sqoop - 1.4.5 Apache Flume - 1.5.0 Apache Ambari - 1.7.0 Apache Oozie - 4.1.0 Apache Zookeeper - 3.4.5 Apache Knox - 0.5.0 Docker - 1.6.2 Swarm - 0.2 Consul - 0.5
###Future releases
####Hadoop distributions
There is an effort by the community to bring Apache Bigtop - the Apache Hadoop distribution - under the umbrella of Ambari. Once this effort is finished, Cloudbreak will support Apache Bigtop as a Hadoop distribution as well.
Apache Ambari allows you to create your own custom Hadoop stack - and you can use Cloudbreak to provision a cluster based on that.
####Cloud providers
Supported cloud providers:
- Amazon AWS
- Microsoft Azure
- Google Cloud Platform
- OpenStack
While we have just released the first public beta version of Cloudbreak, we have already started working on other cloud providers - namely Rackspace and HP Helion Public Cloud. We have received many requests from people to integrate Cloudbreak with 3d party hypervisors and cloud providers - as IBM's SoftLayer. In case you'd like to have your favorite cloud provider listed don't hesitate to contact us or use our SDK and process to add yours. You can fill the following questionnaire and request your favorite cloud provider. In case you'd like to integrate your favorite provider we are happy to support you and merge your contribution.
Enjoy Cloudbreak - the Hadoop as a Service API which brings you a Hadoop ecosystem in minutes. You are literaly one click or REST call away from a fully functional, distributed Hadoop cluster.
##Contribution
So you are about to contribute to Cloudbreak? Awesome! There are many different ways in which you can contribute. We strongly value your feedback, questions, bug reports, and feature requests. Cloudbreak consist of the following main projects:
###Cloudbreak UI
Available: https://cloudbreak.sequenceiq.com
GitHub: https://github.com/sequenceiq/uluwatu
###Cloudbreak API
Available: https://cloudbreak-api.sequenceiq.com
GitHub: https://github.com/sequenceiq/cloudbreak
###Cloudbreak REST client
GitHub: https://github.com/sequenceiq/cloudbreak-rest-client
###Cloudbreak CLI
GitHub: https://github.com/sequenceiq/cloudbreak-shell
###Cloudbreak documentation
Product documentation: http://sequenceiq.com/cloudbreak
GitHub: https://github.com/sequenceiq/cloudbreak/blob/master/docs/index.md
API documentation: https://cloudbreak.sequenceiq.com/api
###Ways to contribute
- Use Cloudbreak
- Submit a GitHub issue to the appropriate GitHub repository.
- Submit a new feature request (as a GitHub issue).
- Submit a code fix for a bug.
- Submit a unit test.
- Code review pending pull requests and bug fixes.
- Tell others about these projects.
###Contributing code
We are always thrilled to receive pull requests, and do our best to process them as fast as possible. Not sure if that typo is worth a pull request? Do it! We will appreciate it. The Cloudbreak projects are open source and developed/distributed under the Apache Software License, Version 2.0. If you wish to contribute to Cloudbreak (which you're very welcome and encouraged to do so) then you must agree to release the rights of your source under this license.
####Creating issues
Any significant improvement should be documented as a GitHub issue before starting to work on it. Please use the appropriate labels - bug, enhancement, etc - this helps while creating the release notes for a version release. Before submitting issues please check for duplicate or similar issues. If you are unclear about an issue please feel free to contact us.
####Discuss your design
We recommend discussing your plans on the mailing list before starting to code - especially for more ambitious contributions. This gives other contributors a chance to point you in the right direction, give feedback on your design, and maybe point out if someone else is working on the same thing.
####Conventions
Please write clean code. Universally formatted code promotes ease of writing, reading, and maintenance.
-
Do not use @author tags.
-
New classes must match our dependency mechanism.
-
Code must be formatted according to our formatter.
-
Code must be checked with our checkstyle.
-
Contributions must pass existing unit tests.
-
The code changes must be accompanied by unit tests. In cases where unit tests are not possible or don’t make sense an explanation should be provided.
-
New unit tests should be provided to demonstrate bugs and fixes (use Mockito whenever possible).
-
The tests should be named *Test.java.
-
Use slf4j instead of commons logging as the logging facade.
###Thank you Huge thanks go to the contributors from the community who have been actively working with the SequenceIQ team. Kudos for that.
###Jobs Do you like what we are doing? We are looking for exceptional software engineers to join our development team. Would you like to work with others in the open source community? Please consider submitting your resume and applying for open positions at jobs@sequenceiq.com.
Brought to you courtesy of our legal counsel.
Use and transfer of Cloudbreak may be subject to certain restrictions by the
United States and other governments.
It is your responsibility to ensure that your use and/or transfer does not
violate applicable laws.
Cloudbreak is licensed under the Apache License, Version 2.0. See LICENSE for the full license text.