Auto-bootstrapping a Nomad cluster
In a previous post, we explored how Consul discovers other agents using cloud metadata to bootstrap a cluster. This post looks at Nomad's auto-joining functionality and how we can use Terraform to create an autoscaled cluster.
Unlike Consul, Nomad's auto bootstrapping functionality does not use cloud metadata because when Nomad pairs with Consul, we inherit the functionality. Consul's service discovery and health checking is the perfect platform to use for bootstrapping Nomad.
The startup process for the Nomad server or agent is as follows:
- The instance bootstraps and installs Nomad and Consul Agent
- The init system starts Consul Agent
- Consul Agent discovers the Consul cluster using AWS Metadata
- The init system starts Nomad with the location of a locally running Consul agent
- On start, Nomad queries the service catalog in Consul to discover other instances
- Nomad joins the discovered instances
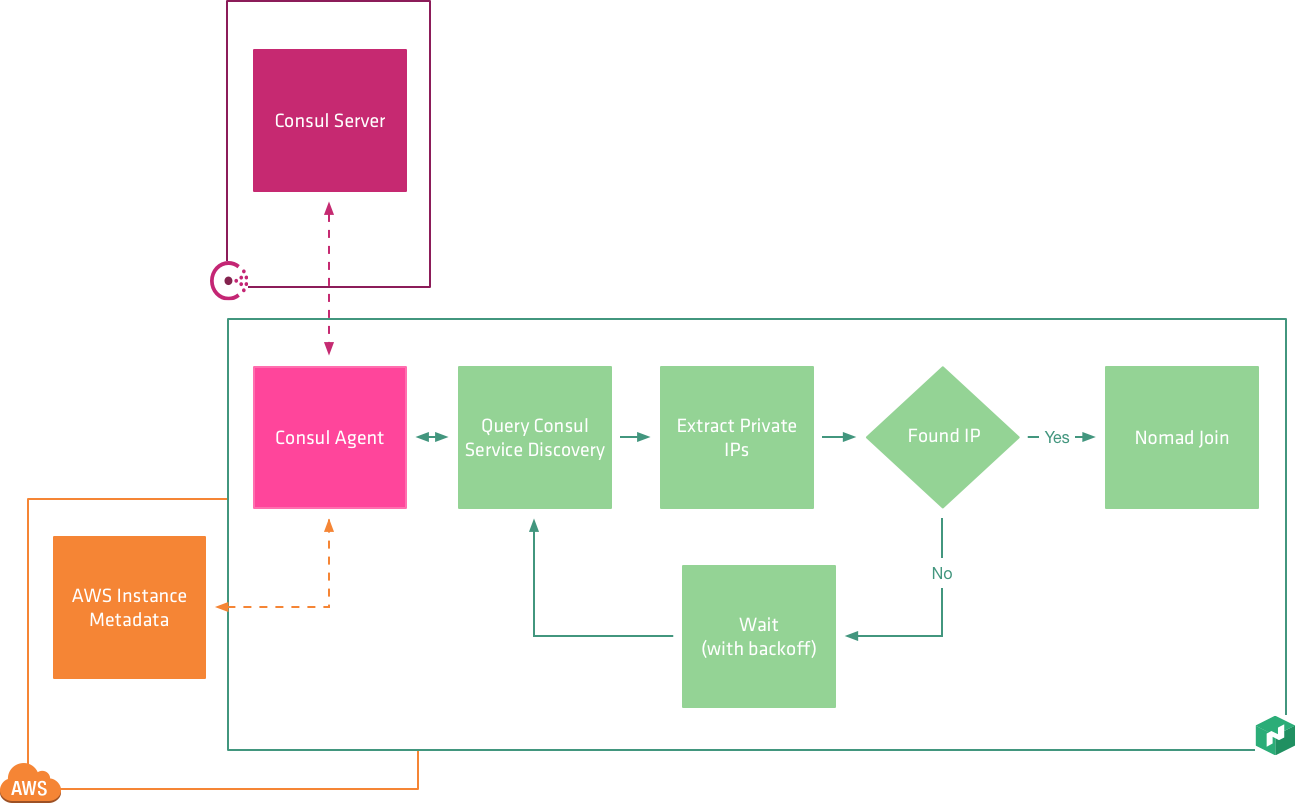
For servers, we still require the initial number of instances that is expected in the bootstrap process to ensure that we have a healthy cluster before we start to schedule work. The requirement for the initial cluster size is to ensure that the cluster can elect a leader and establish a quorum.
Setting up a Nomad cluster
The repository at https://github.com/hashicorp/nomad-auto-join includes an example Terraform configuration to demonstrate this functionality. Clone this repository to your local filesystem:
$ git clone https://github.com/hashicorp/nomad-auto-joinTo initiate and bootstrap the cluster, first set the following environment variables with your AWS credentials.
$ export AWS_REGION = "[AWS_REGION]"
$ export AWS_ACCESS_KEY = "[AWS_ACCESS_KEY]"
$ export AWS_SECRET_ACCESS_KEY = "[AWS_SECRET_ACCESS_KEY]"There are many ways to authenticate to AWS with Terraform, for details of all the authentication options, please see the Terraform AWS provider documentation for more information.
Once we have the environment variables set we can then initialise the terraform modules using the terraform get command. Using modules in our setup allows us to keep our code dry. For more information on this features please see the Terraform documentation: https://www.terraform.io/docs/modules/usage.html
$ terraform getWe can then run plan to create check the configuration before running apply to create the resources
$ terraform plan
Refreshing Terraform state in-memory prior to plan...
The refreshed state will be used to calculate this plan, but will not be
persisted to local or remote state storage.
#..
.
Plan: 30 to add, 0 to change, 0 to destroy.Running terraform apply will create 5 t2.micro instances, 3 servers to form a quorum and 2 agents which run the jobs. These settings are configurable in the terraform.tfvars file if you would like to change them.
$ terraform applyOnce this is all up and running, the Terraform output shows the details of the created servers and clients.
Apply complete! Resources: 30 added, 0 changed, 0 destroyed.
The state of your infrastructure has been saved to the path
below. This state is required to modify and destroy your
infrastructure, so keep it safe. To inspect the complete state
use the `terraform show` command.
State path:
Outputs:
alb_arn = arn:aws:elasticloadbalancing:eu-west-1:773674589724:loadbalancer/app/nomad-consul-external/3cca7be97ab6d28d
alb_dns = nomad-consul-external-723193890.eu-west-1.elb.amazonaws.com
ssh_host = 34.251.93.86Because the Nomad API is not exposed publicly, we need to log into the SSH host which is attached to the same VPC.
ssh ubuntu@$(terraform output ssh_host)We can then run nomad server-members to see a list of the servers in the cluster.
ubuntu@ip-10-1-1-216:~$ nomad server-members
Name Address Port Status Leader Protocol Build Datacenter Region
ip-10-1-1-99.global 10.1.1.99 4648 alive false 2 0.5.6 dc1 global
ip-10-1-2-107.global 10.1.2.107 4648 alive false 2 0.5.6 dc1 global
ip-10-1-2-48.global 10.1.2.48 4648 alive true 2 0.5.6 dc1 globalMoreover, we can run nomad node-status to see a list of the clients.
ubuntu@ip-10-1-1-131:~$ nomad node-status
ID DC Name Class Drain Status
ec268e26 dc1 ip-10-1-2-5 <none> false ready
ec21954b dc1 ip-10-1-1-44 <none> false readyRunning jobs on Nomad
To run a job on Nomad, we need to create a job specification which defines the schema. The job file uses the HashiCorp Configuration Language (HCL) that aims to strike a balance between a human readable and editable, and machine-friendly format.
The overall hierarchy of our job file is as follows:
- job
- group
- task
- group
Each file only has a single job. However, a job can have multiple groups, and each group may have multiple tasks. When a group contains multiple tasks, Nomad co-locates these on the same client. This hierarchy allows you the flexibility of configuring a single service or groups of services which define an application in the one file.
Let's take a look at the file jobs/syslog.hcl which defines a system for running syslog-ng.
job "system_utils" {
datacenters = ["dc1"]
type = "system"
# ...
group "system_utils" {
constraint {
distinct_hosts = true
}
# ...
task "syslog" {
driver = "docker"
# ...
}
}
}
}Job Stanza
The job stanza is the top most configuration in the job specification, in our job we are assigning the name "system_utils" this name must be globally unique across the whole cluster.
job "system_utils" {
datacenters = ["eu-west-1", “eu-west-2”]
type = "system"
update {
stagger = "10s"
max_parallel = 1
}
# ...We are then setting the datacenter, which is a required option and which has no default. We could have also specified the region which is another attribute for job placement. The datacenters and region attributes allow fine-grained control over where a job runs. For example, you may have the following cluster deployed:
- region: Europe-AWS * datacenter: eu-west-1 * datacenter: eu-east-1
The type definition allows you to set the three different job types that are available to the scheduler:
- service - long-lived services that should never go down
- batch - short lived or periodic jobs
- system - schedule job on all running on all clients which that meet the job’s constraint
https://www.nomadproject.io/docs/runtime/schedulers.html
The update stanza configures how we would like the job to be updated for example when we want to deploy a new version. In our case the settings give us the capability to do rolling deploys:
- max_parallel configures the number of task groups updated at any one time
- stagger specifies the delay between sets of updates
https://www.nomadproject.io/docs/job-specification/update.html
Group Stanza
The next level is the group stanza, and the group stanza defines a series of tasks that should be co-located on the same Nomad client. To determine on which client the tasks get placed, we can specify some constraints. Constraints filter on attributes and metadata,
In our example we are only setting the constraint distinct_host, this means that we would never schedule any more than one group to the same host. Constraints can also apply to the Task and Job level; this gives you complete flexibility over the placement, all constraints evaluate on a hierarchical level which starts at a Job level and filters down.
Full details on this capability can is available in the Nomad documentation:
https://www.nomadproject.io/docs/job-specification/constraint.html
Task Stanza
The task stanza is an individual unit of work, such as running a Docker container or application. If we take a look at our example, we are going to run the docker image syslog-ng.
task "syslog" {
driver = "docker"
config {
image = "balabit/syslog-ng:latest"
port_map {
udp = 514
tcp = 601
}
}
// ..
}The first attribute in this stanza is the driver; we are using the value docker as we would like to run a Docker container however many different values are possible:
- docker - run a docker container
- exec - execute a particular command, isolating primitives of the operating system to limit the tasks access to resources
- java - run a Java application packaged into a Jar file
- lxc - run LXC application containers
- qemu - execute any regular qemu image
- raw_exec - execute a particular command with no isolation, runs the command as the same user as the Nomad process. Disabled by default
- rkt - run CoreOS rkt application containers
Finally, we are going to set the config for the task, which is unique to each driver. For our task we are using the Docker driver, the minimum we can specify is the image attribute to select the docker image. However, the driver supports most of the parameters which could are passed directly to Docker with the docker run command.
https://www.nomadproject.io/docs/drivers/docker.html
Resources
To ensure that Nomad correctly allocates the task to the client we need to specify the resources that it consumes. The resources stanza allows us to set limits for the CPU and memory, and network that the task can consume. By limiting the resources, we can bin pack more tasks onto a single instance. However, the tasks get throttled to these limits, if we set them too small, we could inadvertently reduce the performance of the running application.
resources {
cpu = 500 # 500 MHz
memory = 256 # 256MB
network {
mbits = 10
port "udp" {
static = "514"
}
port "tcp" {
static = "601"
}
}The port section of the network stanza allows us to allocate ports either dynamically or statically; we reference the ports which were defined in the config stanza earlier. In this example we are statically allocating the http and admin ports as we want to map these to the load balancer however if we only need ports available for internal use then we can omit the static = “514” from the configuration and Nomad with dynamically allocate the port number to the container.
https://www.nomadproject.io/docs/job-specification/resources.html
Running the jobs
Now that we understand the job configuration let's now see how to execute a job on our cluster. Log into the remote ssh server by running:
$ ssh ubuntu@$(terraform output ssh_host)In this example we are using the terraform output variable for the ssh_host direct in our command, there is no need to cut and paste the IP address.
When the SSH host was provisioned it downloaded the two example job files from the GitHub repository, you should see two files, syslog.hcl and http_test.hcl in the home directory. Like Terraform Nomad has a plan command which checks the syntax of our config file and determines if it can allocate the resources on the server, let’s run this command:
$nomad plan syslog.hcl
+ Job: "system_utils"
+ Task Group: "system_utils" (2 create)
+ Task: "syslog" (forces create)
Scheduler dry-run:
- All tasks successfully allocated.
Job Modify Index: 0
To submit the job with version verification run:
nomad run -check-index 0 syslog.hcl
When running the job with the check-index flag, the job will only be run if the
server side version matches the job modify index returned. If the index has
changed, another user has modified the job and the plan's results are
potentially invalid. We can now use the nomad run -check-index 0 syslog.hcl command to execute the plan and provision the application.
$nomad run syslog.hcl
==> Monitoring evaluation "711e028a"
Evaluation triggered by job "system_utils"
Allocation "82d60ade" created: node "ec25ffd9", group "system_utils"
Allocation "a449140e" created: node "ec2d8914", group "system_utils"
Evaluation status changed: "pending" -> "complete"
==> Evaluation "711e028a" finished with status "complete"
We can check the status of the job by running the nomad status system_utils command, you will see that there has been 2 allocations one for each Nomad client.
$nomad status system_utils
ID = system_utils
Name = system_utils
Type = system
Priority = 50
Datacenters = dc1
Status = running
Periodic = false
Parameterized = false
Summary
Task Group Queued Starting Running Failed Complete Lost
system_utils 0 0 2 0 0 0
Allocations
ID Eval ID Node ID Task Group Desired Status Created At
82d60ade 711e028a ec25ffd9 system_utils run running 06/29/17 16:39:18 BST
a449140e 711e028a ec2d8914 system_utils run running 06/29/17 16:39:18 BSTNow we have seen how we can create a system job let’s create a standard job for the http-echo server.
$ nomad plan http_test.hcl
# ...
$ nomad run -check-index 0 http_test.hcl
# ...$ nomad status
ID Type Priority Status
system_util system 50 running
http-test service 50 runningIf you open another terminal window and curl the external alb address you should see the following response.
$curl $(terraform output external_alb_dns)
'hello world'Destroying the cluster
Don’t forget that running resources in AWS incur cost, once you have finished with your cluster you can destroying by running:
$ terraform destroySummary
The auto-bootstrapping functionality built into Nomad and Consul makes it possible to manage and auto-scale our clusters easily and not restricted to AWS. This capability is available for most major cloud providers. We have barely scratched the surface on the capacity of Nomad, but I hope you can see how Nomads power and simplicity could be a real benefit to your infrastructure.