Python 3.6
-
Clone this repository
cd /path/to/anywhere/you/like git clone https://github.com/zengyu714/weibo-backupNow the directory looks like
. ├── README.md ├── configuration.py ├── main.py ├── requirements.txt ├── demo [directory] └── pages [directory] └── README.md └── articles [directory] └── comments [directory] -
Install dependencies
pip install -r requirements.txt
-
修改配置文件
configuration.pyCONFIG.url_template- 登录微博触屏版
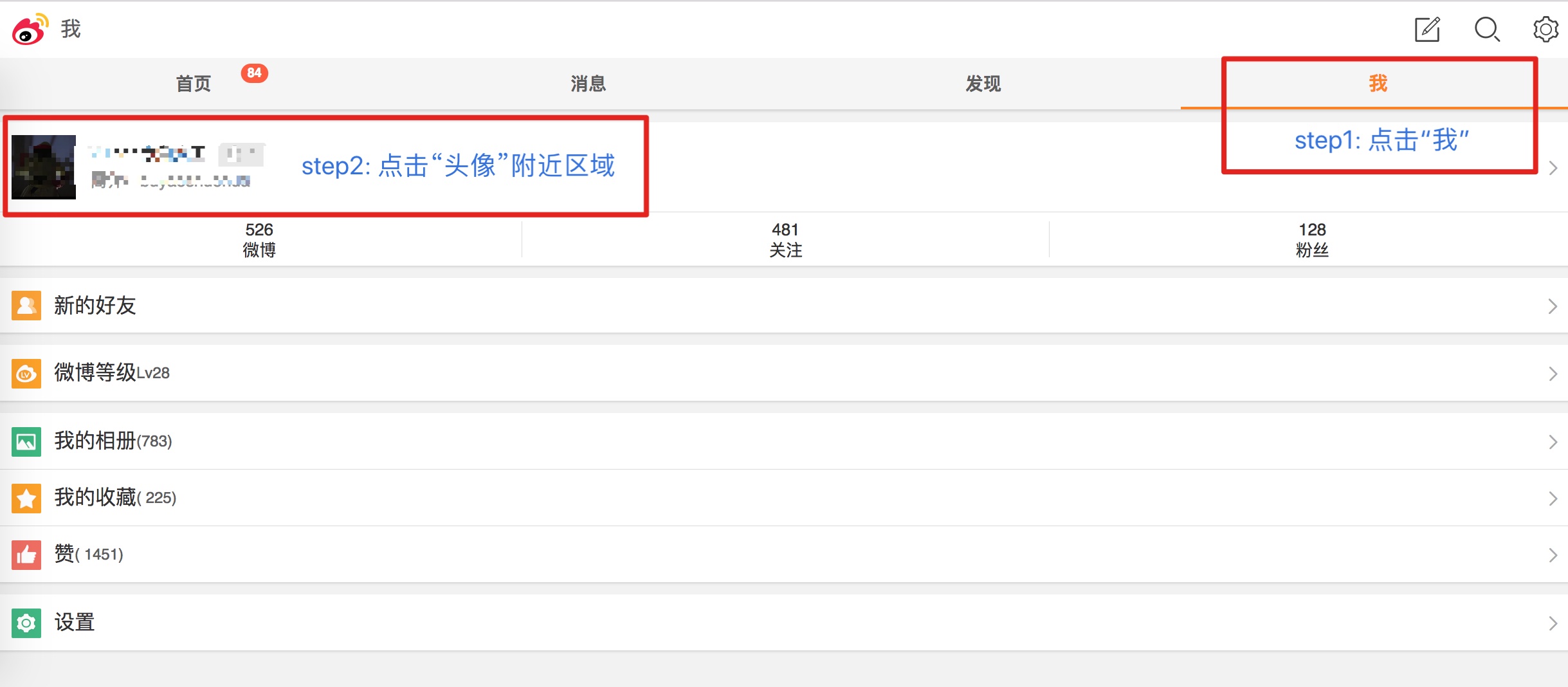 得到URL, E.g, https://m.weibo.cn/u/2146965345
得到URL, E.g, https://m.weibo.cn/u/2146965345 - 点击进入,打开浏览器调试工具
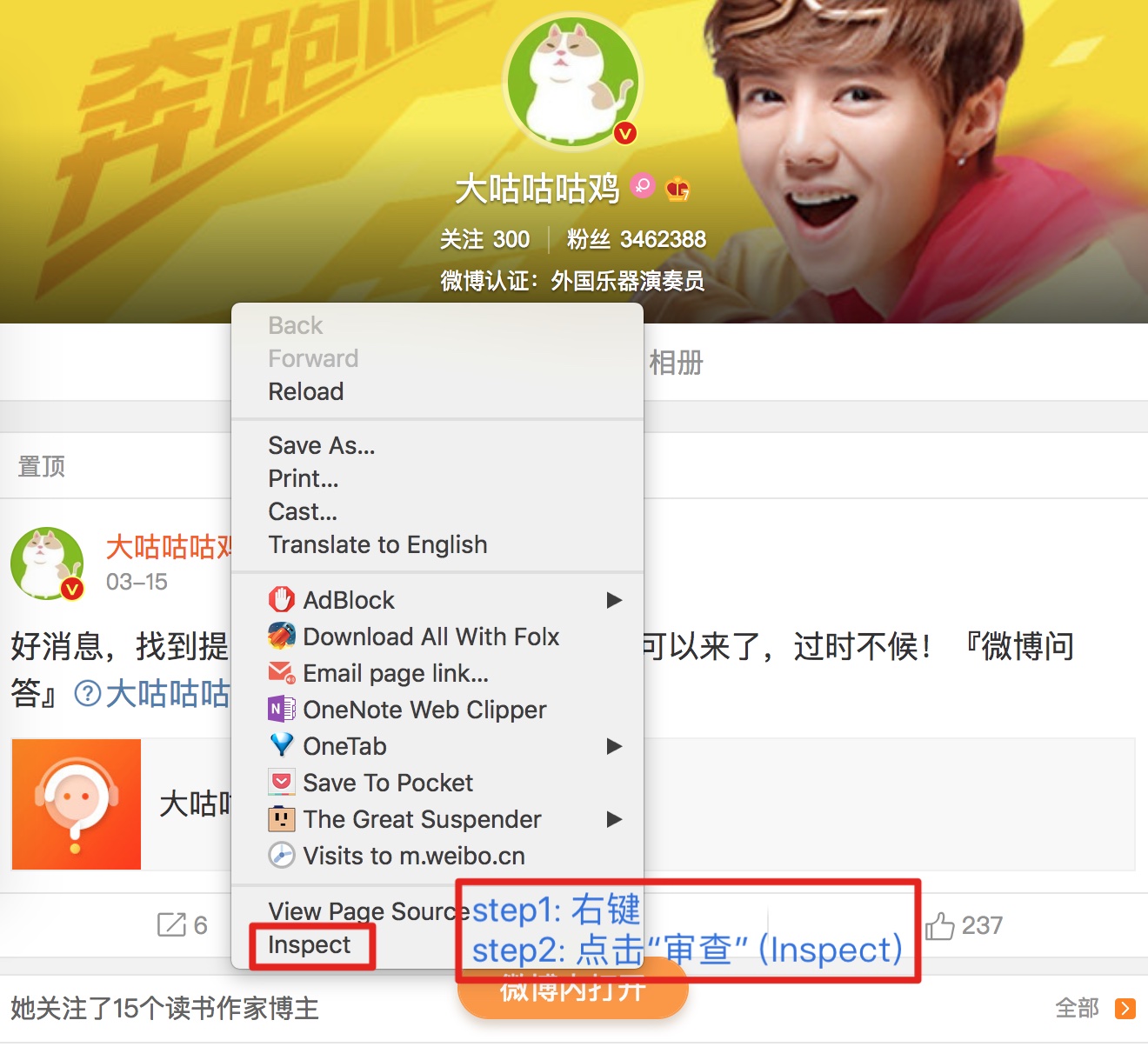
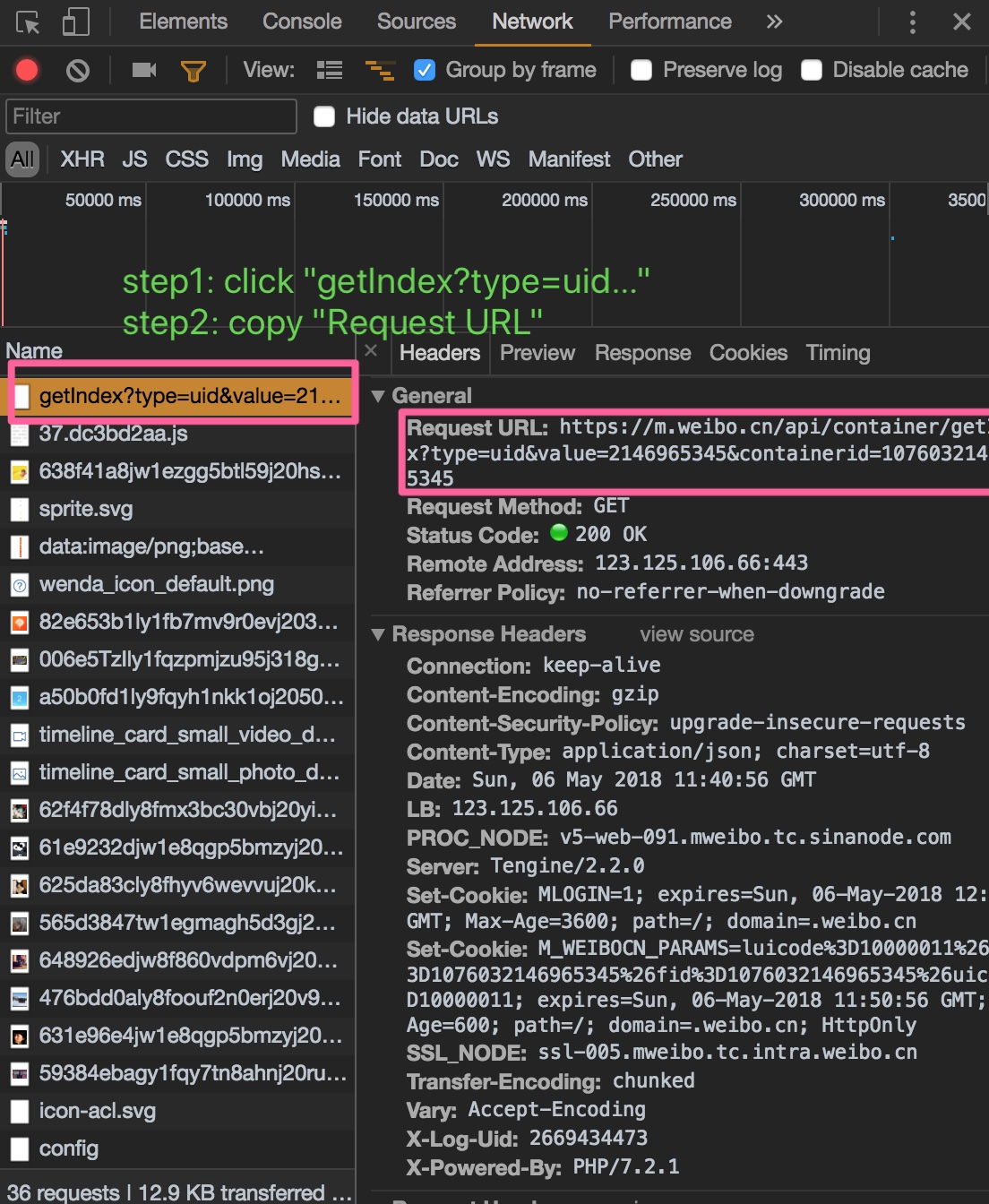
- 将复制得到的
Request URL粘贴到CONFIG.url_template ='your_url' E.g.,
CONFIG.url_template = 'https://m.weibo.cn/api/container/getIndex?type=uid&value=2146965345&containerid=1076032146965345'
- 登录微博触屏版
CONFIG.cookie- 同样是在调试界面,在
Headers栏往下翻到Cookie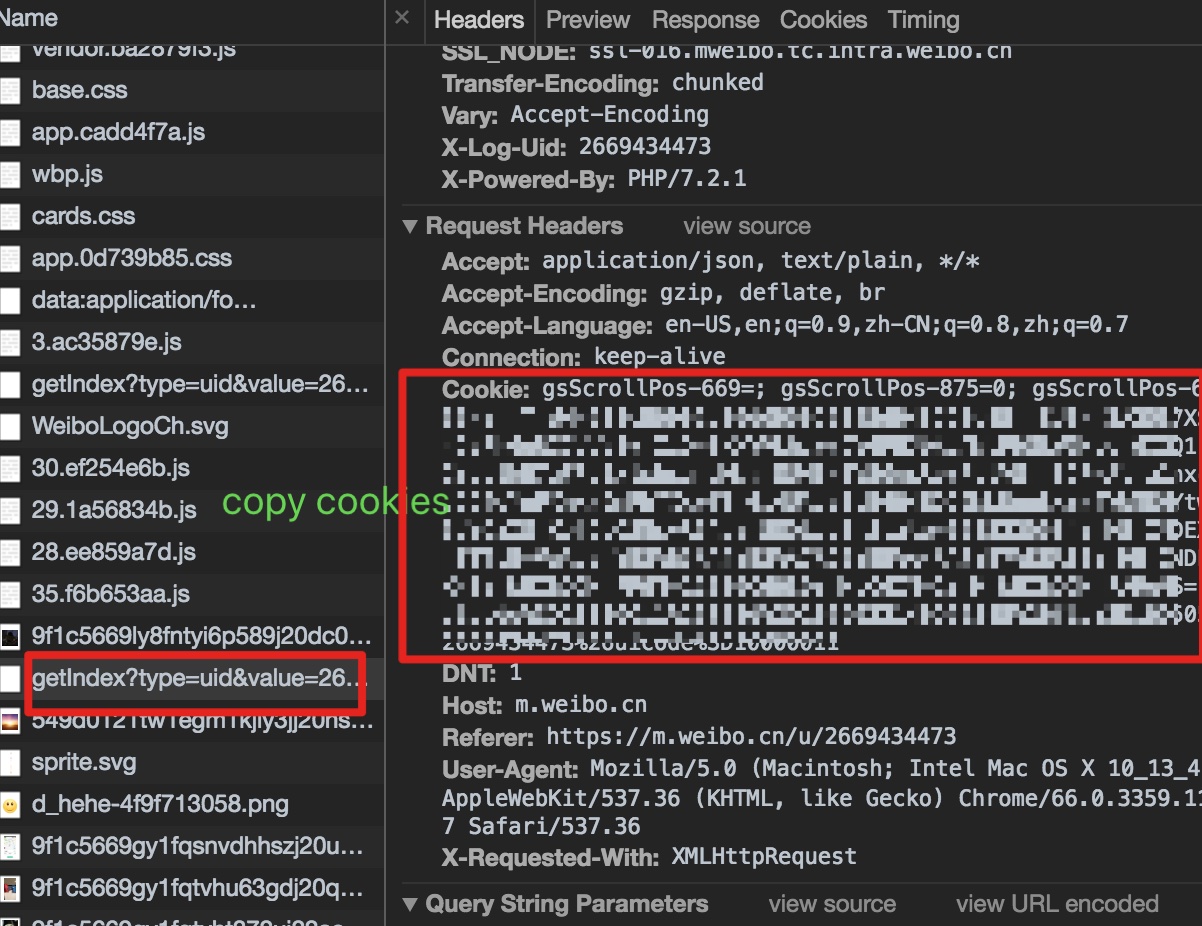
- 右键复制内容(目的是发送登录状态)
- 将复制得到的
Cookie粘贴到CONFIG.cookie ='your_cookie'
- 同样是在调试界面,在
-
注意看
configuration.py中的参数配置,适时调整参数




- 一般的,首次使用时,应将CONFIG.model改为'save_json_first'
- 从微博获取的数据会以json格式保存在pages文件夹中,所以之后应将CONFIG.model设置为空即''
- 如不想使用代理,将CONFIG.use_proxy设置为False
- 运行
main.py脚本python main.py
Note
- 自动生成
pages文件夹保存微博json文件 - 自动生成
articles文件夹保存原创或转载文章json文件 - 自动生成
comments文件夹保存微博评论json文件 - 自动生成结果文件
mblog_backup_<current_date>.html,可以在浏览器打开并打印成PDF
- 对于长文(>140),评论,点赞详情没有记录
- 优化备份页面排版
- 保存转载的微博
- 保存原创或转载长文
- 备份页面html从单行分成多行
- 保存评论
- 点赞
- 超长转载微博不完整显示,可通过 https://m.weibo.cn/status/retweeted_status_id 获取完整内容
- 保存基本信息
- 保存所有原创微博内容
- 保存所有转载微博内容
- 保存所有评论
- 保存原创或转载长文
- 保存微博附加的图片
This project is licensed under the MIT License