
![]()
Next-generation developer-first NoSQL database.
AnnaDB is an in-memory data store with disk persistence. It can work as the main data storage and the cache layer as well. Rust lang under the hood makes it memory-safe and fast.
Features
- Flexible object structure - simple primitives and complicated nested containers could be stored in AnnaDB
- Relations - you can link any object to another, and AnnaDB will resolve this relation on finds, updates, and other operations.
- Transactions - out of the box
AnnaDB stores objects in collections. Collections are analogous to tables in SQL databases.
Every object and sub-object (item of a vector or map) that was stored in AnnaDB has a link (id). This link consists of the collection name and unique uuid4 value. One object can contain links to objects from any collections - AnnaDB will fetch and process them on all the operations automatically without additional commands (joins or lookups)
The AnnaDB query language uses the TySON format. The main difference from other data formats is that each item has a value and prefix. The prefix can mark the data or query type (as it is used in AnnaDB) or any other useful for the parser information. This adds more flexibility to the data structure design - it is allowed to use as many custom data types as the developer needs.
You can read more about the TySON format here
There are primitive and container data types in AnnaDB.
Primitive data types are a set of basic types whose values can not be decoupled. In TySON, primitives are represented as prefix|value| or prefix only. Prefix in AnnaDB shows the data type. For example, the string test will be represented as s|test|, where s - is a prefix that marks data as a string, and test is the actual value.
Container data types keep primitive and container objects using specific rules. There are only two container types in AnnaDB for now. Maps and vectors.
- Vectors are ordered sets of elements of any type. Example:
v[n|1|,n|2|,n|3|,] - Maps are associative arrays. Example:
m{ s|bar|: s|baz|,}
More information about AnnaDB data types can be found in the documentation
Query in AnnaDB is a pipeline of steps that should be applied in the order it was declared. The steps are wrapped into a vector with the prefix q - query.
collection|test|:q[
find[
],
sort[
asc(value|num|),
],
limit(n|5|),
];
If the pipeline has only one step, the q vector is not needed.
collection|test|:find[
gt{
value|num|:n|4|,
},
];
To run AnnaDB locally please type the next command in the terminal:
docker run --init -p 10001:10001 -t romanright/annadb:0.1.0If you want to persist your data use this volume:
docker run --init -p 10001:10001 -t -v "$(pwd)/data:/app/warehouse" romanright/annadb:0.1.0AnnaDB shell client is an interactive terminal application that connects to the DB instance, validates and handles queries. It fits well to play with query language or work with the data manually.
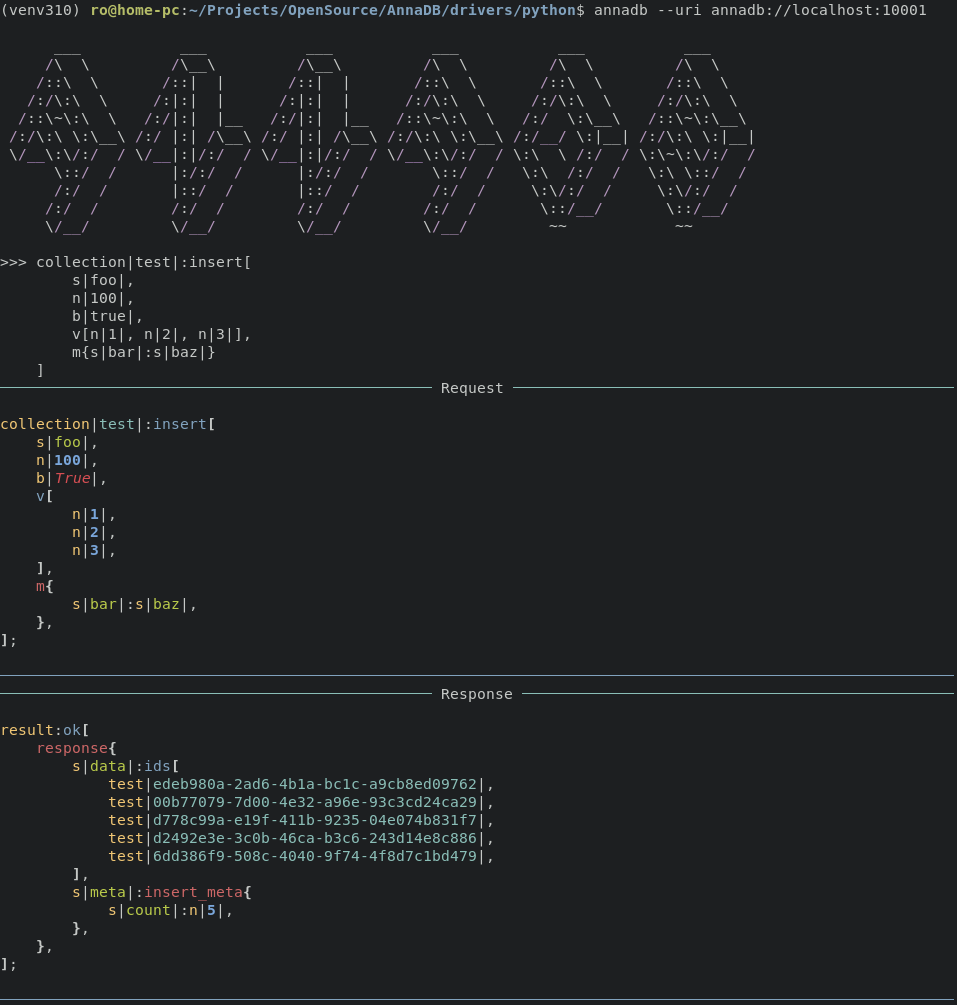
It can be installed via pip
pip install annadbRun
annadb --uri annadb://localhost:10001