Problem Statement : SM445
Team : Anton3.0
Participants
- Pratik Baid | Vellore Institute of Technology, Chennai | pratikbaid3@gmail.com
- Rishikesh Sriram | Vellore Institute of Technology, Chennai | rishikesh.sriram06@gmail.com
- Siddharth Singha Roy | Vellore Institute of Technology, Chennai | siddharthsingha.roy2018@vitstudent.ac.in
- Bhavika Bajaj | Vellore Institute of Technology, Chennai | bhavikabenigopal.2018@vitstuent.ac.in
- Yash Jain | Vellore Institute of Technology, Chennai | yashjain.2018@vitstudent.ac.in
- Harshal Shree | Vellore Institute of Technology, Chennai | harshal.shree2018@vitstudent.ac.in
Mentor
- Syed Ibrahim Peer Mohamed | Vellore Institute of Technology, Chennai
- Introduction
- Prerequisites
- Installation
- Our Solution
- Technology Stack
- Hosting
- User Interface
- Data source for corporate actions
A corporate action is an event initiated by a public company that will bring an actual change to the securities—equity or debt—issued by the company. Corporate actions are typically agreed upon by a company's board of directors and authorized by the shareholders. Examples of corporate actions include stock splits, dividends, mergers and acquisitions, rights issues, and spin-offs. Corporate action instantly impacts security valuation and hence its timely and accurate information is very critical to financial institutes and investors. Information on current, upcoming, and historical corporate action can be purchased from various data vendors like Bloomberg, ICE Data Service, Refinitiv, MarketMap, etc. which could be expensive. Alternatively, data could be freely retrieved from public webpages and company portal. Challenge with free data approach is its accuracy, reliability and completeness
Goal of corporate action (CA) robot is to retrieve accurate, and complete information on historical, current, and future expected corporate action in timely manner from free sources.
This instance will be used to store the pdf and csv files. Create a bucket named smart-india-hackathon. You'll need to have an access key, secret key, region and bucket name.
You need to have one postgres server running with a database sih created. Also note the username, password, host and port
The code base uses features only available from python 3.6
This repository uses wkhtmltopdf library to convert html file to pdf.
Flutter is used to develop the Android and IOS platforms.
This application uses Google's Custom Search API to decide from which websites it needs to get extract information regarding corporate actions.
Used for storing data regarding the user and also for authentication of users
- Xcode(Only for MacOS) [This is optional. Install this if you want to run the Flutter app]
Xcode can be used for building the Flutter app for IOS and also run it on an emulator.
- Android Studio(For any OS) [This is optional. Install this if you want to run the Flutter app]
Android Studio can also be used for building the Flutter app for android and also run it on an emulator.
- Clone this repository
foo@bar:~$ git clone https://github.com/Anton-3-0-SIH2020/SIH2020_SM445_Team_Anton_3.0.git- Change directory to that folder
foo@bar:~$ cd SIH2020_SM445_Team_Anton_3.0/- Run the setup file
foo@bar:~$ sh setup.sh- Starting the scheduled task api
foo@bar:~$ cd SchedulerAPI/
foo@bar:~$ source env/bin/activate
foo@bar:~$ python3 app.py
foo@bar:~$ deactivateThe TaskSchedulerAPI will run on localhost:8000. If you want the BASE_URL to be different then,
foo@bar:~$ export BASE_URL=<URL GOES HERE>
foo@bar:~$ python3 app.py- Open another terminal. ( You may close this terminal however if you have any scheduled jobs setup, then those won't run.
- Starting the Scheduled Tasks ( Also build the database )
foo@bar:~$ cd ..
foo@bar:~$ cd ScheduledTask/
foo@bar:~$ cd BSE/
foo@bar:~$ source env/bin/activate
foo@bar:~$ python3 app.py
foo@bar:~$ deactivatefoo@bar:~$ cd ..
foo@bar:~$ cd NSE/
foo@bar:~$ source env/bin/activate
foo@bar:~$ python3 app.py
foo@bar:~$ deactivatefoo@bar:~$ cd ..
foo@bar:~$ cd MoneyControl/
foo@bar:~$ source env/bin/activate
foo@bar:~$ python3 app.py
foo@bar:~$ deactivate- Start the REST API server
foo@bar:~$ cd ..
foo@bar:~$ cd ../
foo@bar:~$ cd RESTAPI/
foo@bar:~$ source env/bin/activate
foo@bar:~$ python3 app.py
foo@bar:~$ cd ..
foo@bar:~$ cd ..The server will be running on localhost:5000
foo@bar:~$ cd SIH2020_SM445_Team_Anto.3.0_MobileApp/
foo@bar:~$ flutter packages get
foo@bar:~$ flutter package upgrade
foo@bar:~$ flutter runWe provide an intelligent crawler which can extract information related to corporate actions from every webpage. The crawler is designed to be able to extract information without requiring any knowledge of the DOM elements. So even if a website decides to change its CSS classes, identifiers etc, our crawler will still be able to gather information from that website. We use Google's Custom Search API to gather the sites which have a higher search index and get a list of url's pertaining to a company's corporate action. We then feed these urls to our crawler which returns all the extracted information from this site.
The extracted information may be in a structured format (Table, PDF, Word):
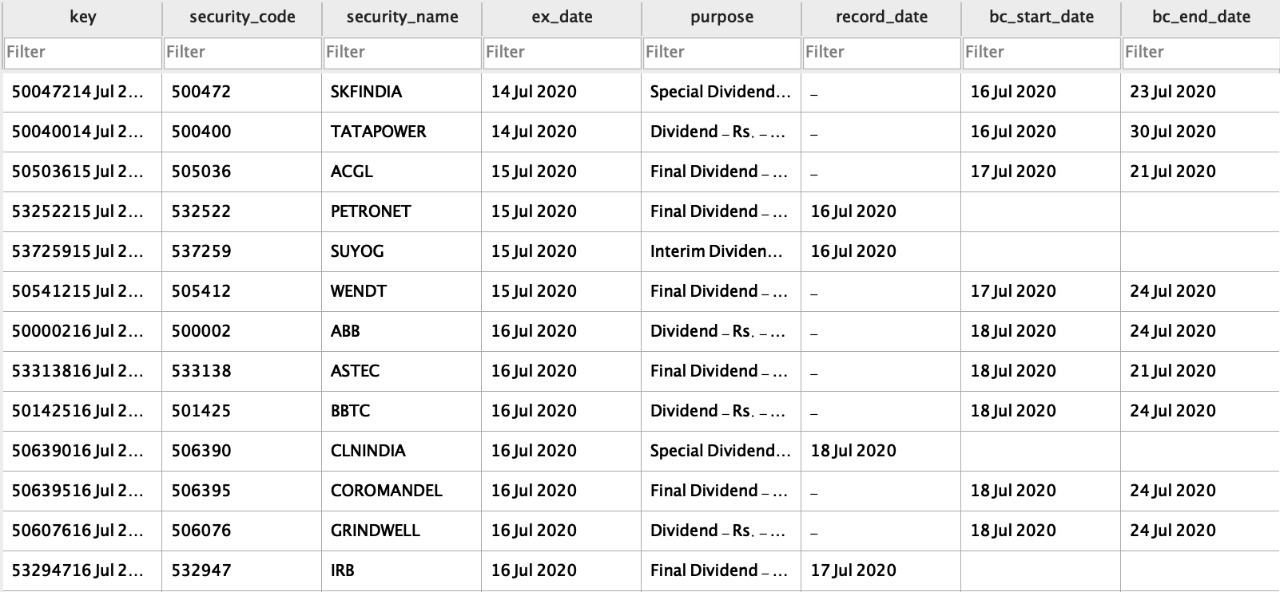
The extracted imformation may be unstructured (News, Free form text):

For the structured data we preprocess the data, assign it a key based on the name of the company and store it in the database. As for the unstructured data, information is passed through a NLP model to decide whether the given text is CA or Non-CA. The crawler will act as a pseudo pipeline-layer for the NLP model to remove any information that may not be a CA. After a text has been classified as CA, we'll pass it through a NER model to extract information (Organisation, Date, Ca Type, Purpose, Context, Source) from it and store it in the database.
The above steps will be scheduled to run every 'n' hours to update the database and get the latest information.
- Capability to crawl all webpage's and gather the requisite information regarding corporate actions.
- Intelegently identify which websites provide information related to the required corporate action.
- Data can be viewed on a mobile platform
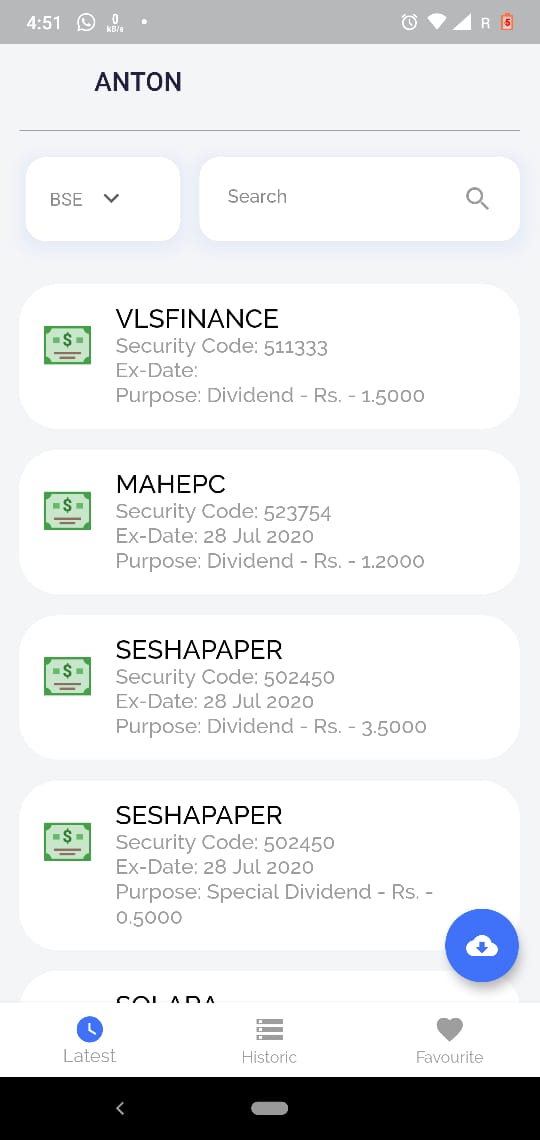
- Download the data as pdf or csv
- Extract important information from retrieved pages/files on corporate action
- Build accurate, and complete data from conflicting data retrieved from multiple sources.
- Ability to configure to look for CA on a set of securities, to all listed securities on specific exchange.
- Robot could be configured to continuously look for new data available for relevant corporate action.
- Add certain set of securities as favourites
Overview of our architecture
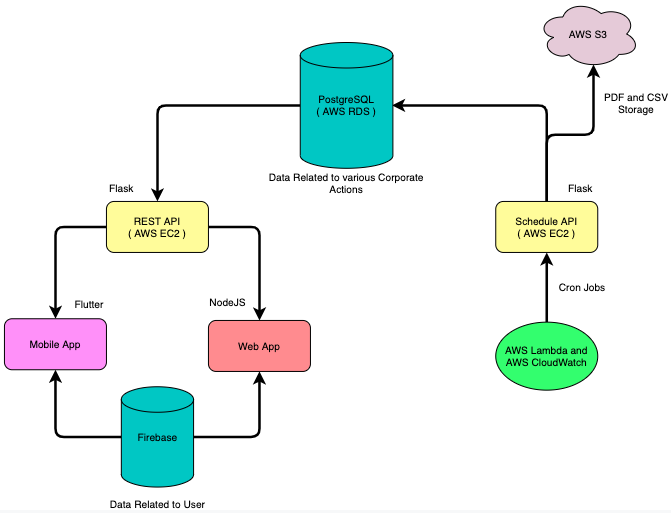
Architecture for Data Source ( 1 )
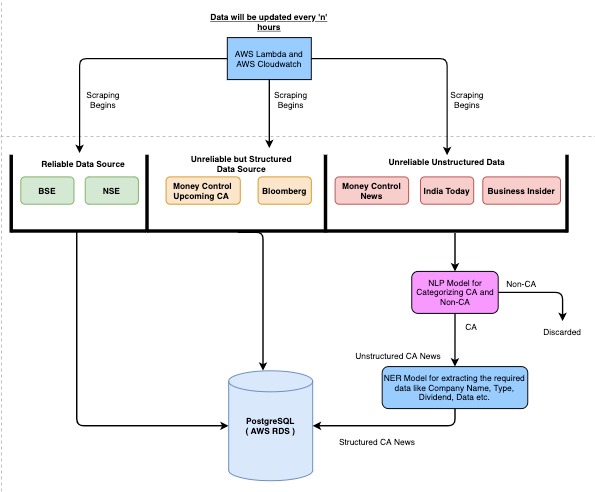
Architecture for Data Source ( 2 )
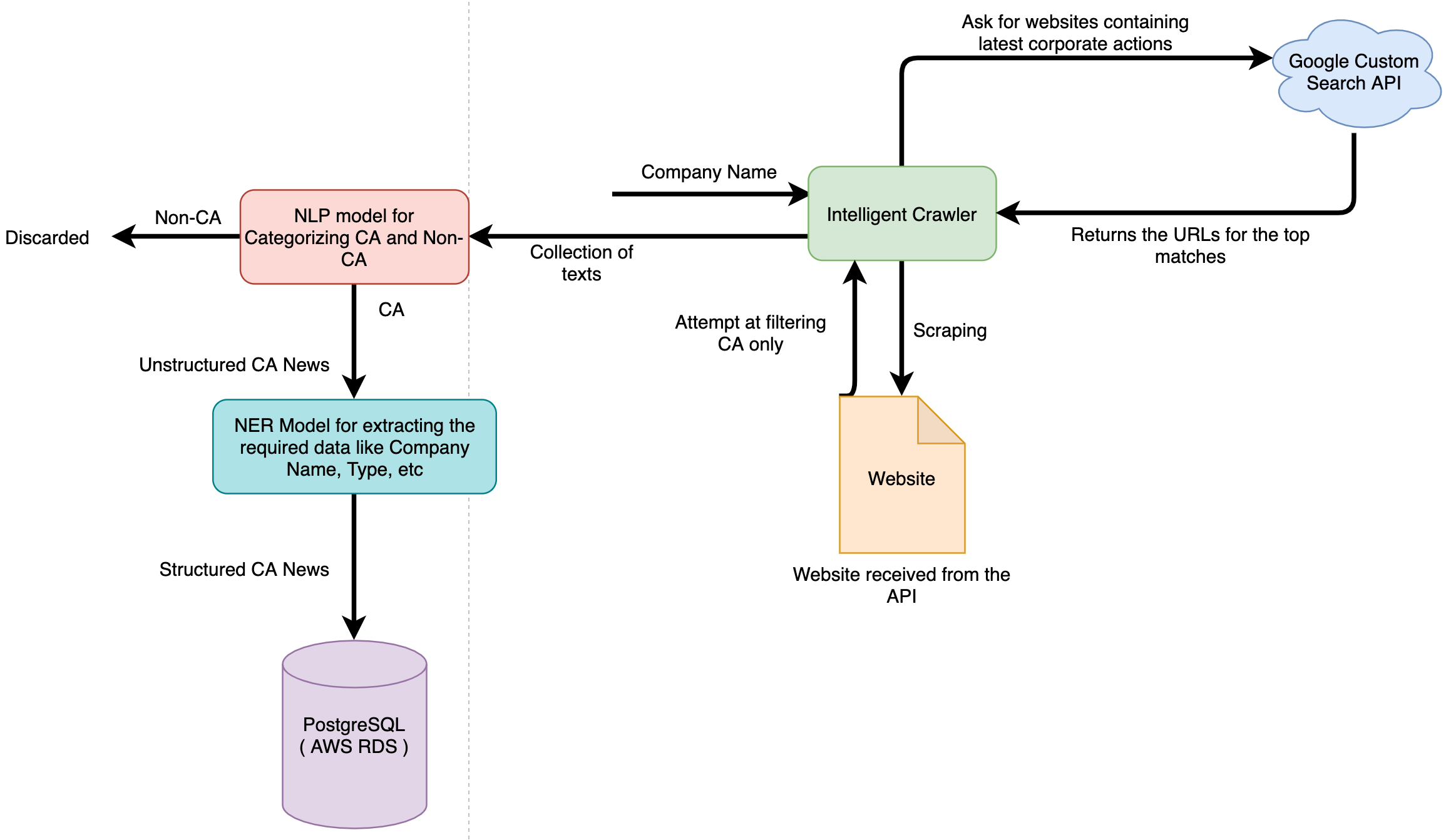
NLP Pipeline
- Flutter overcomes the traditional limitations of cross-platform approaches.
- Frontend & Backend with a single code
- Flutter moves to a widget, rendering, animation and gestures into this framework to give you to complete control over every pixel on the screen. It means you have the flexibility to build a custom design.
- spaCy is an industrial grade natural language processing toolkit.
- spaCy excels at large-scale information extraction tasks.
- spaCy is the best way to prepare text for deep learning.
- Used for developing highly scalable microservices
- It is based on Python and allows ease of integration with ML and NLP applications
- Concurrency, Performance, Reliability and Disaster Recovery
- Highly scalable for structured data
- Automated Multi-Region Backups
- Consistency & Reliability
- Simple Automated Scheduling
- Security and Scaling
- AWS CloudWatch, AWS S3, AWS Lambda, AWS RDS
The entire project is hosted on AWS. Currently we use the following AWS Services
- AWS EC2 Instance for hosting the two flask applications. One EC2 instance has its HTTP and HTTPS Port open whereas the the other EC2 instance is hidden from the world and can only be communicated over an VPC and a private API Key
- AWS RDS is used for hosting the PostgreSQL Server
- AWS Lambda which communicates with the EC2 instance over a VPC to refresh the database
- AWS Cloudwatch is used for scheduling the AWS Lambda function calls
- AWS VPC for secured cloud communication
- AWS SES for email sending
Landing Page

Login Page
Dashboard
Favourites
Detail View of CA
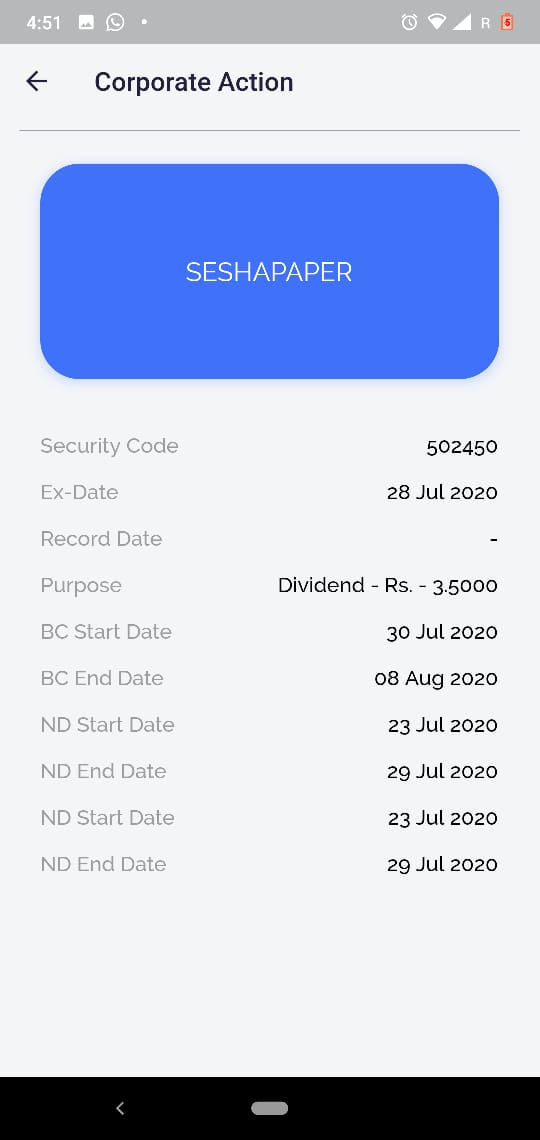
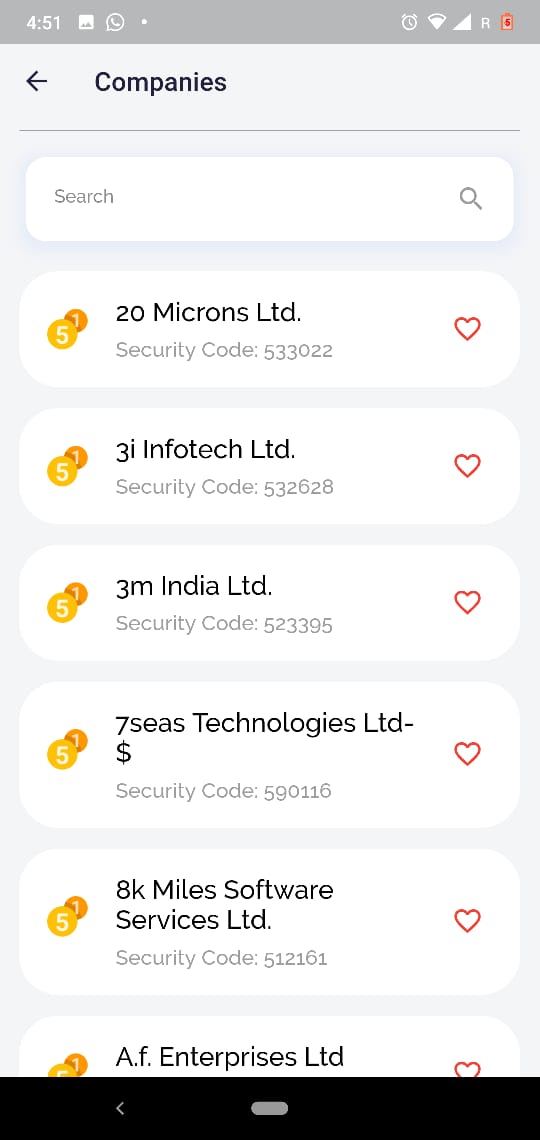
Filtering on basis of security
Currently we use Google's Custom Search API to search for corporate action of each company and then scrape all the websites as returned by the API.
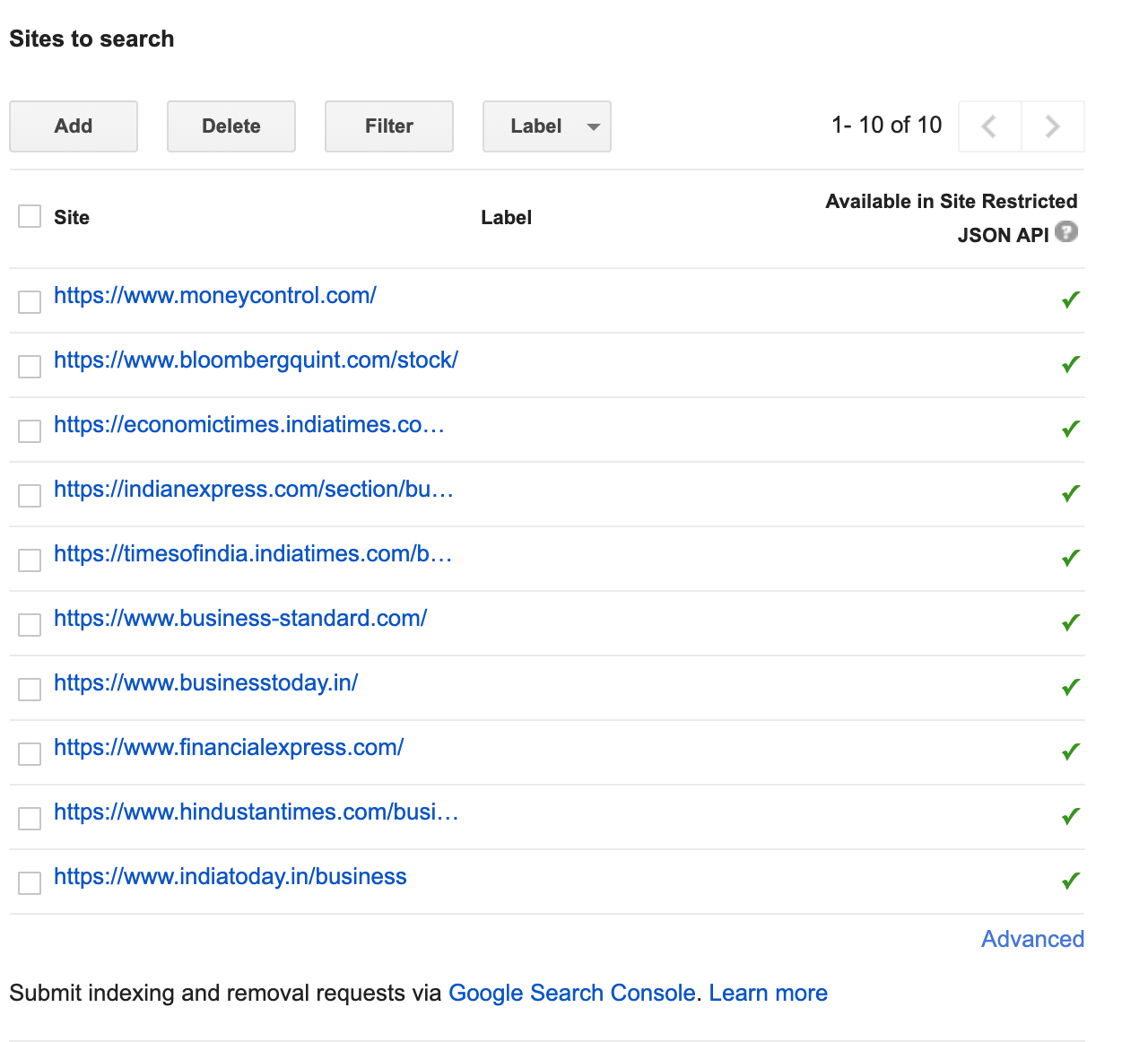
This part is entirely customizable and one can add as many number of websites they want. Once the data source is given to our intelligent crawler, it will go and scrape that website for any corporate actions information. The crawler has been designed as a DOM independent platform ie. it can be used to scrape any website and return a list of corporate action information it extracted. We used Google's Search Index to decide which sites to scrape as it may contain information pertaining to corporate actions for a company.
Currently the crawler can parse
- Free Text ( without external intervention )
- Tabular Data ( without external intervention )
- Excel ( requires external intervention )
- PDF ( requires external intervention and only in text format )
- API ( requires external intervention )
Data Collection is scheduled to run every 'n' hours which is totally customizable via AWS Cloudwatch.
We provide an intelligent crawler which can extract information related to corporate actions from every webpage. The crawler is designed to be able to extract information without requiring any knowledge of the DOM elements. So even if a website decides to change its CSS classes, identifiers etc, our crawler will still be able to gather information from that website. We use Google's Custom Search API to gather the sites which have a higher search index and get a list of url's pertaining to a company's corporate action. We then feed these urls to our crawler which returns all the extracted information from this site.
The extracted information may be in a structured format (Table, PDF, Word):
The extracted imformation may be unstructured (News, Free form text):
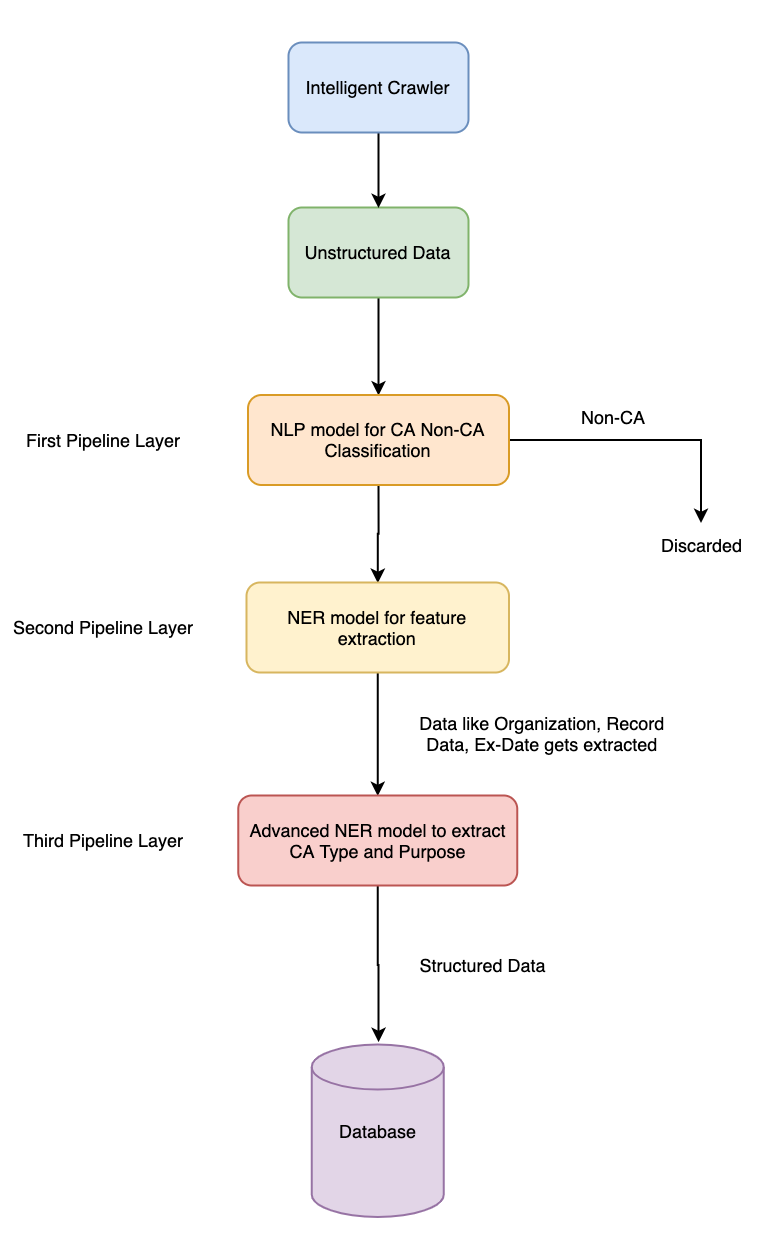
For the structured data we preprocess the data, assign it a key based on the name of the company and store it in the database. As for the unstructured data, information is passed through a NLP model to decide whether the given text is CA or Non-CA. The crawler will act as a pseudo pipeline-layer for the NLP model to remove any information that may not be a CA. After a text has been classified as CA, we'll pass it through a NER model to extract information (Organisation, Date, Ca Type, Purpose, Context, Source) from it and store it in the database.
The complete flow of the pipeline is mentioned below:
Pipeline Layer 1
Clacify the text into ca/non-ca:
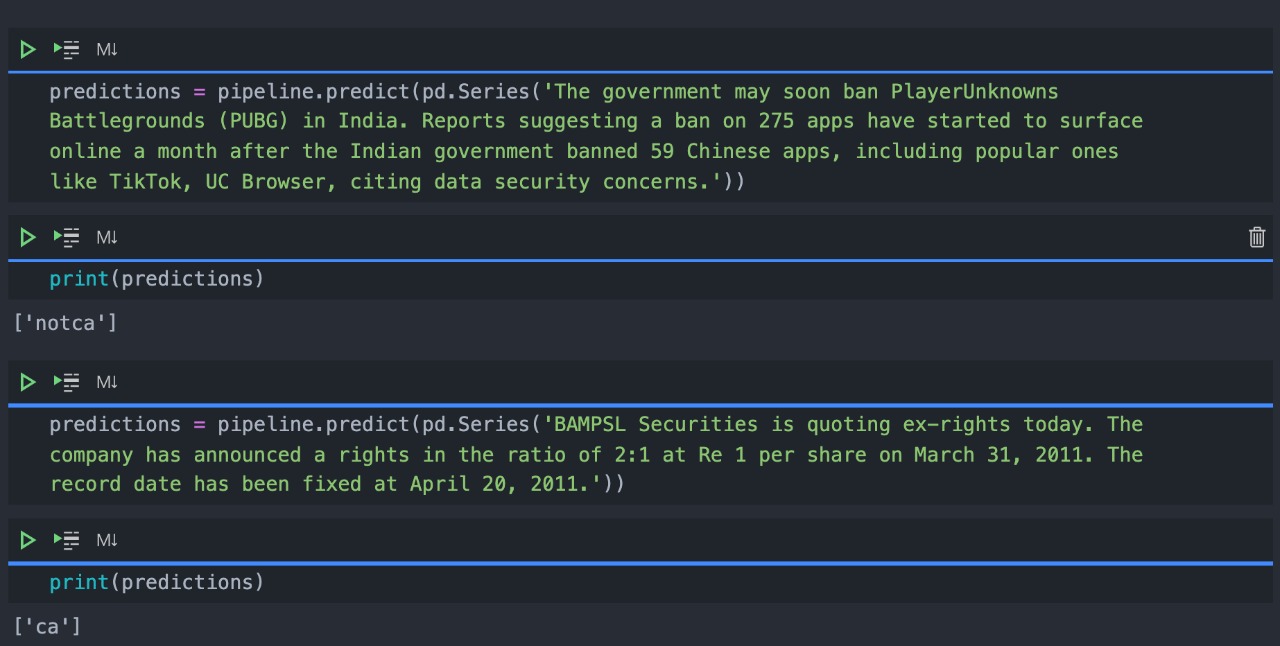
Accuracy of the clacifier:
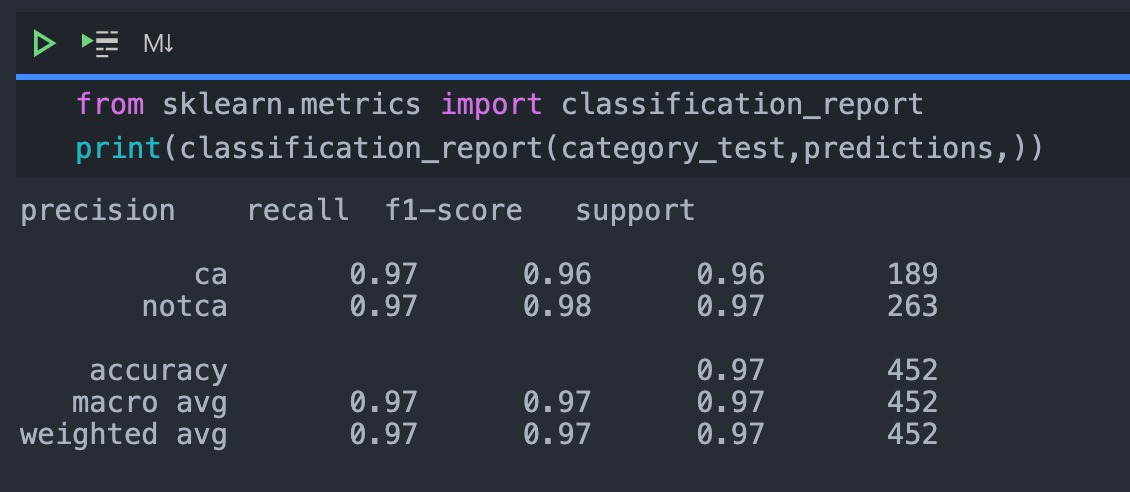
Pipeline Layer 2
Extract basic informations from text(Company, Date):

Pipeline Layer 3
Classifying the ca as approved or pending
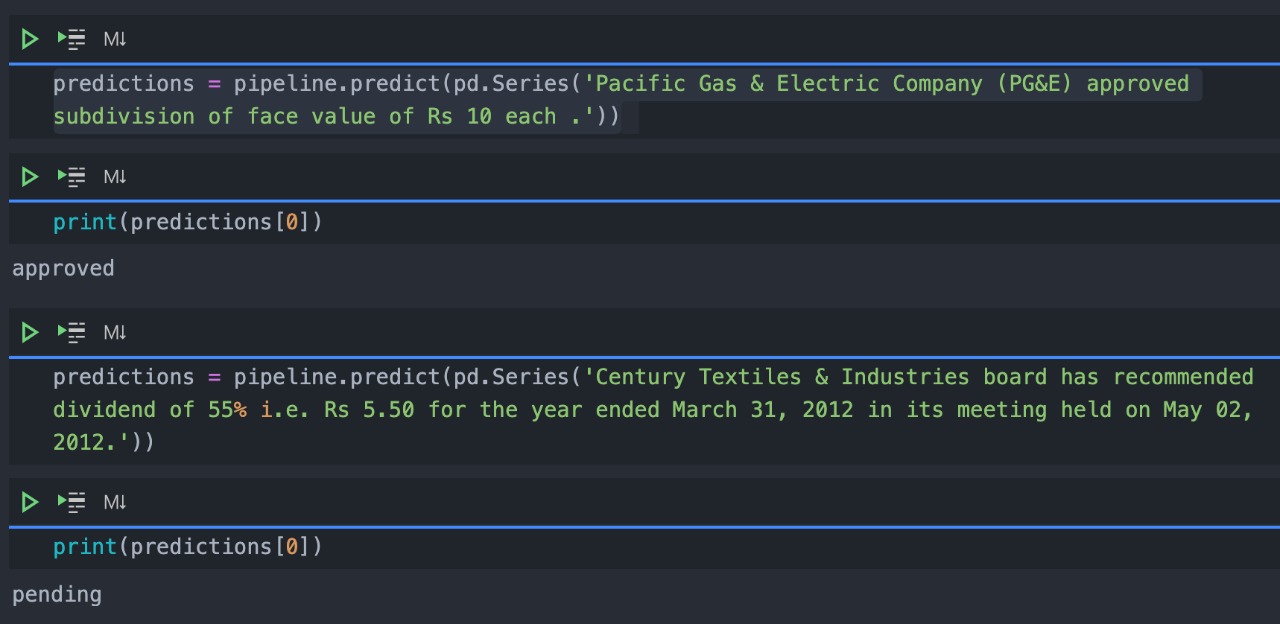
Pipeline Layer 4
Extract advanced information from the text(Ca Type,Purpose):
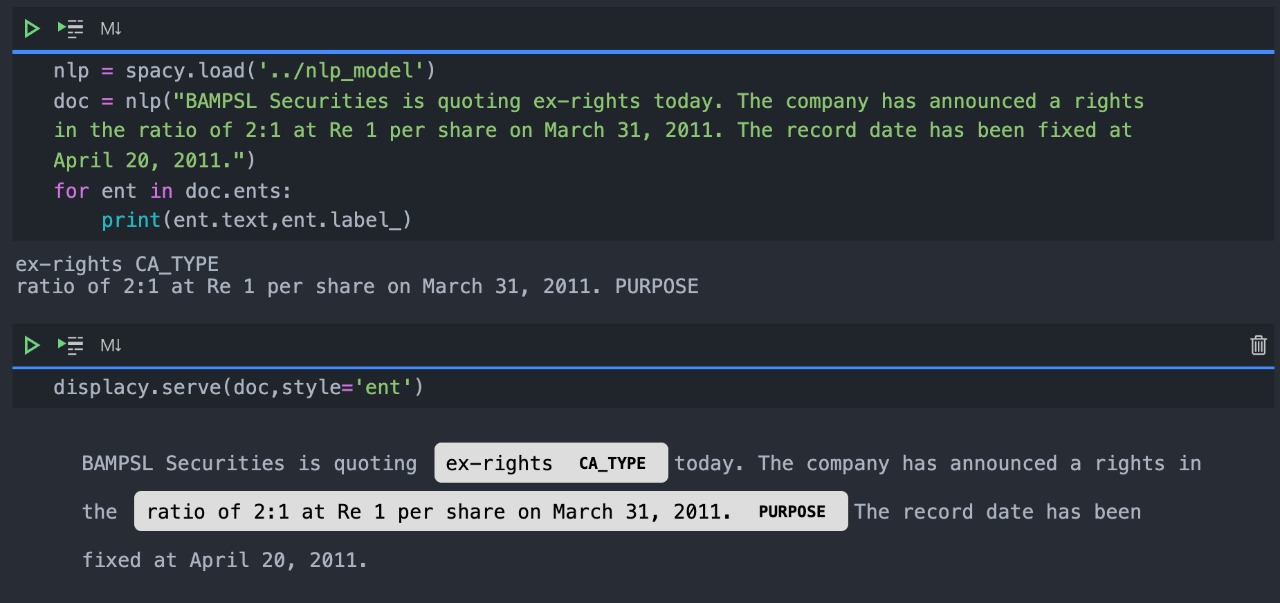
Store the data in the database is a structured format:
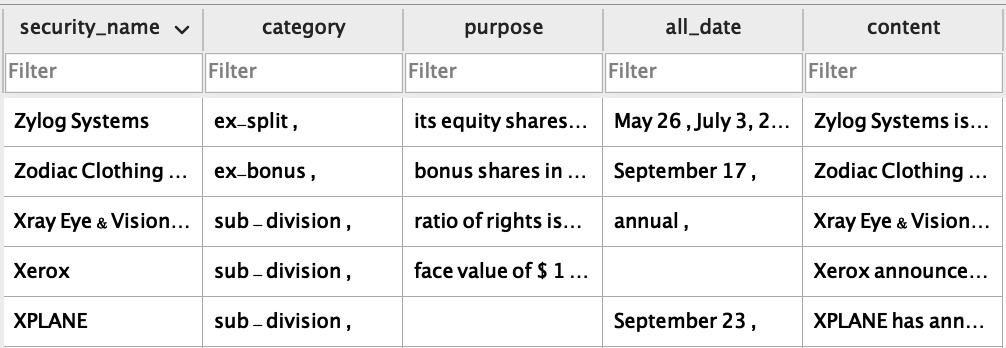
Final Structured Output

Storing structured data
Storing Unstructured data
Resolving Conflicting data
Inorder to resolve conflict between several entries, we design a key (Company + Data + Ca Type + Purpose). This key is uniques for each entry and cannot be replicated. This helps us with resolving the conflict between data entries.
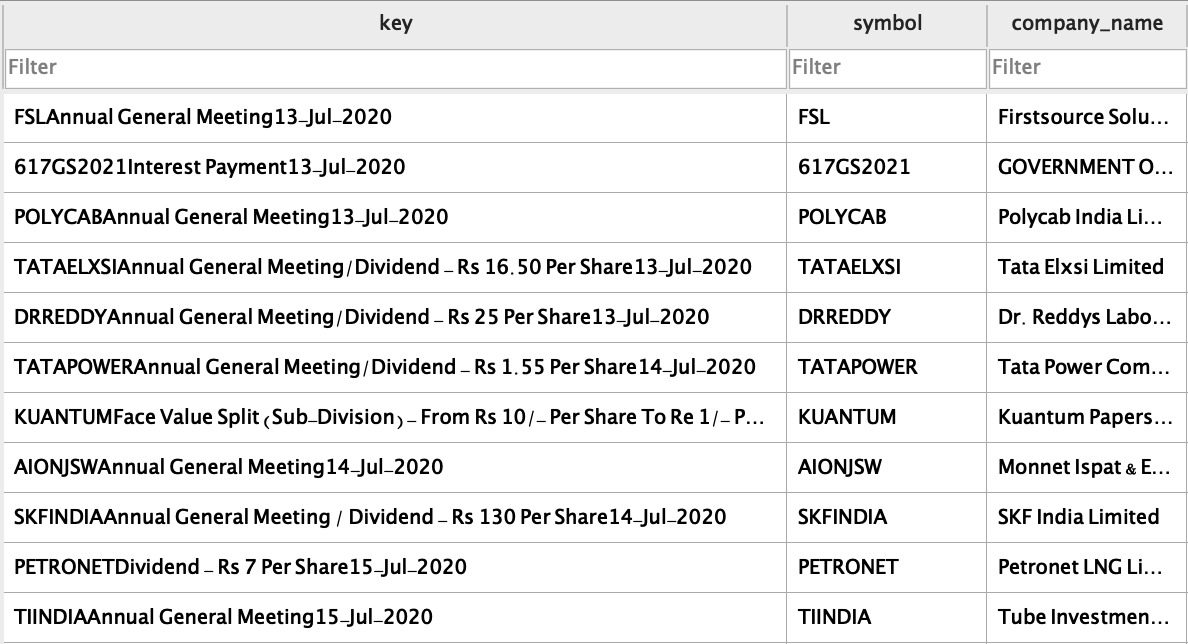
1. CA Type Supported :
-
Splits
-
Dividend
-
AGM
-
Extraordinarie GM
-
Rights
-
Issues
These CA Types are completly scalable, so adding new securities is possible
2. Financial Market Supported :
We do not have any specific target website to extract information from. Our crawler can extract information from any website in the world. Currently we use Google's Custom Search API to search for corporate action of each company and then scrape all the websites as returned by the API.
This part is entirely customizable and one can add as many number of websites they want. Once the data source is given to our intelligent crawler, it will go and scrape that website for any corporate actions information. The crawler has been designed as a DOM independent platform ie. it can be used to scrape any website and return a list of corporate action information it extracted. We used Google's Search Index to decide which sites to scrape as it may contain information pertaining to corporate actions for a company.
3. Historic /Current Data :
All the historic data for the Indian exchanges (BSE/NSE) have been stored for later use. Current data is being populated from the publically available information in the form on news and tabular data.
1. Verifying data
All the data that is being retreived from different sources are checked with the data available from BSE/NSE to determine its reliability. If a data has not been verefied, it is listed as predicted, after it has been verefied it is added to the official table.
2. Conflicting Informations
Inorder to resolve conflict between several entries, we design a key (Company + Data + Ca Type + Purpose). This key is uniques for each entry and cannot be replicated. This helps us with resolving the conflict between data entries.
1. Mobile Interfacing:
Mobile application for both Android and iOS
2. Web App:
Web application developed to be accessed anywhere
3. Email Subscription Service:
User can subscribe to daily mail of the corporate actions in the form of PDF/CSV
4. User Customisations:
User can select (Favourite) companies which they want to keep a track of and the information can be viewed and edited anytime.
5. Technoogies And Tools:
-Flutter for mobile -EJS for web -Flask and AWS for email service and data management
Data is being fetched from all possible locations and being merged and checked for conflict to generate a standard singular source of data. The intelligence of the web crawler provides for a scalable solution to extract information from any website in any format. The crawler intellegently identifies the websites that can provide the best information and uses those website to gather data. With the help of NLP/NER and machine learning algorithms , free text data can also be processed to gather information from it.