数据集给了某一年1-6月得到数据,主要有两部分,线上和线下的用户消费行为的数据,包括用户id,商户id,优惠券id,折扣率,领券日期和消费日期,线下还会多一个距离的数据。问题是预测7月用户在领券后15天内消费的概率,评价指标为对每个优惠券coupon_id计算核销预测的AUC,是一个二分类问题
-
查看变量之间的分布,发现样本的标签不均衡,训练集中正负样本比例达到了1:8(少部分人用优惠券消费了,大部人没消费或没使用优惠券),针对不同的模型可能要考虑欠采样或者过采样(比如XGBoost就能很好处理不平衡的数据),正负样本数量差别很大,这也是为什么会使用 AUC 作为模型性能评估标准的原因。(如何解决样本不平衡问题? 使用StratifiedKFold和StratifiedShuffleSplit 分层抽样。 一些分类问题在目标类别的分布上可能表现出很大的不平衡性:例如,可能会出现比正样本多数倍的负样本。在这种情况下,建议采用如 StratifiedKFold 和 StratifiedShuffleSplit 中实现的分层抽样方法,确保相对的类别频率在每个训练和验证 折叠 中大致保留。)
-
画出箱线图,利用3sigma原则剔除异常数据
-
数据的变换(数据是怎么划分的——保持线上线下一致):发现test集没有时间的特征,所以采用了滑窗法,原因:训练集有消费的日期Date属性,但线上的没有这个字段,直接提取特征就不能用了,所以需要对该属性进行转换;可以这样想,其实最后提取出来的特征信息代表的是一种习惯或者叫做固有属性,比如个人的一些消费习惯啦,商家的受欢迎程度啦等等,这些其实是不会随着月份改变而改变的,那我们就用前三个月来提取这些特征,然后默认为7月份也是这种特征信息,依照这种规则方法,我们在给训练集提取特征的时候也都是统一用前三个月的特征来默认为本月的特征。其实就是将时间特征转化为了每个用户的行为特征。
关于时间窗口划分数据集为什么前15天只统计购买行为原因如下:

-
缺失值处理:
-
距离:此场景下距离范围为[0,10],相当于已经用分箱处理了数据,故将空值均设置为11
-
日期:用指定值“1970-1-1‘’填充,方便后续处理
-
折扣率:存在fixed特殊字段,表示限时优惠,统计后发现,fixed对应的全部消费了,所以将其设置为0;形式为"30:10",表示满30-10,故进一步将其分为3个字段man,jian,折扣率,原因是单纯的算折扣率会有缺陷,比如满30-10这个商品的折扣率一定是1/3吗?可能商品原价是40,那折扣率就是1/4,是有出入的,进一步可以将该字段用分箱,分到5个区间
-
-
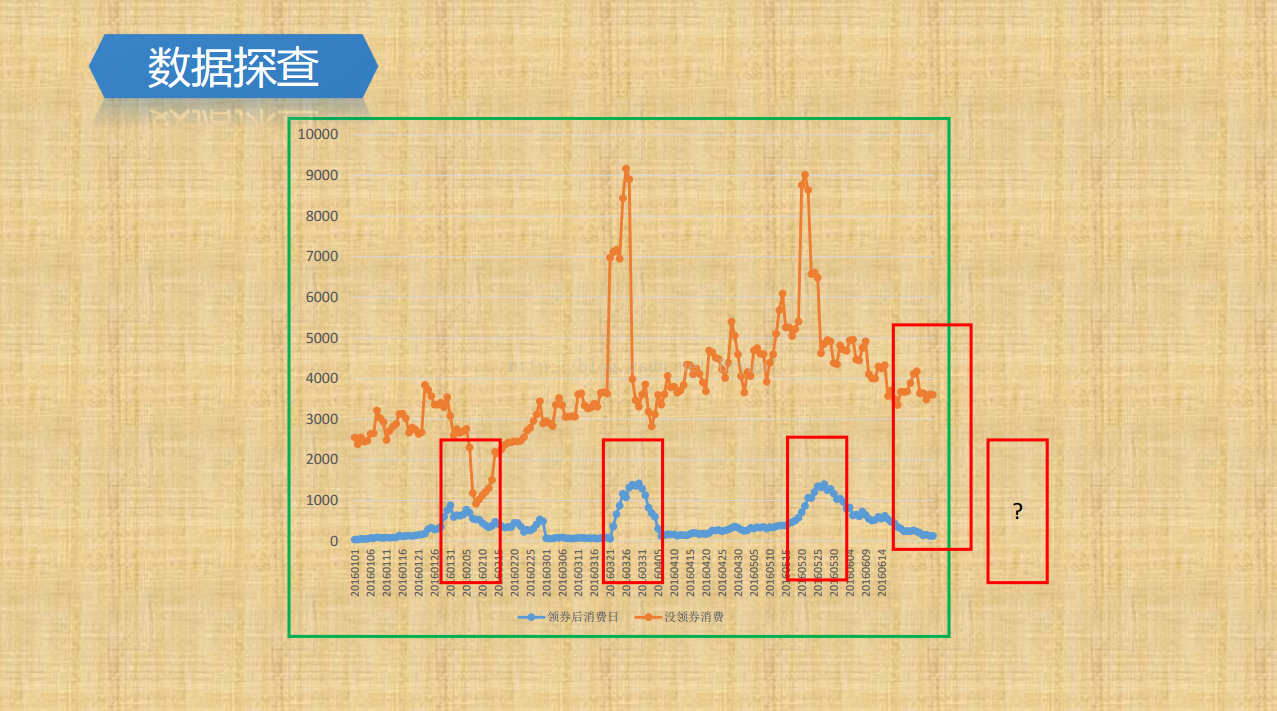
由于存在日期数据,通过pandas 的pivot进行数据重塑,指定相应的列分别作为行、列索引以及值,类似于数据透视表的功能,将日期作为行,列索引为消费的人群,值为size即可画出,消费情况和日期的变化图像,通过图像可以观察到消费行为和日期存在相关性,周末人们的消费行为明显多余工作日,故进一步提取特征:weekday和day,这里没有将其用one-hot编码,而是额外加了是否为工作日和是否为周末的tag
-
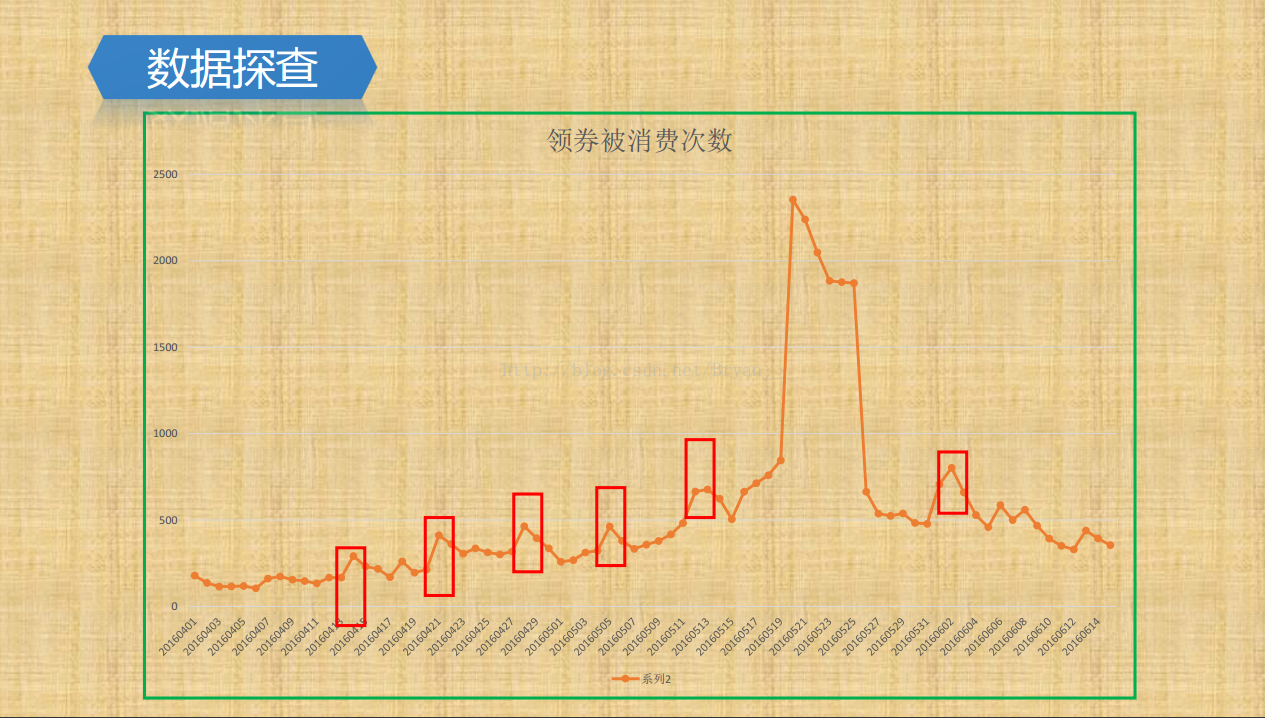
观察测试集还能发现有tricks,即穿越特征,赛题提供的预测集中,包含了同一个用户在整个7月份里的优惠券领取情况,这实际上是一种leakage,穿越特征,比如存在这种情况:某一个用户在7月10日领取了某优惠券,然后在7月12日和7月15日又领取了相同的优惠券,那么7月10日领取的优惠券被核销的可能性就很大了。我们在做特征工程时也注意到了这一点,提取了一些相关的特征。加入这部分特征后,AUC提升了10个百分点,相信大多数队伍都利用了这一leakage,但这些特征在实际业务中是无法获取到的。
-
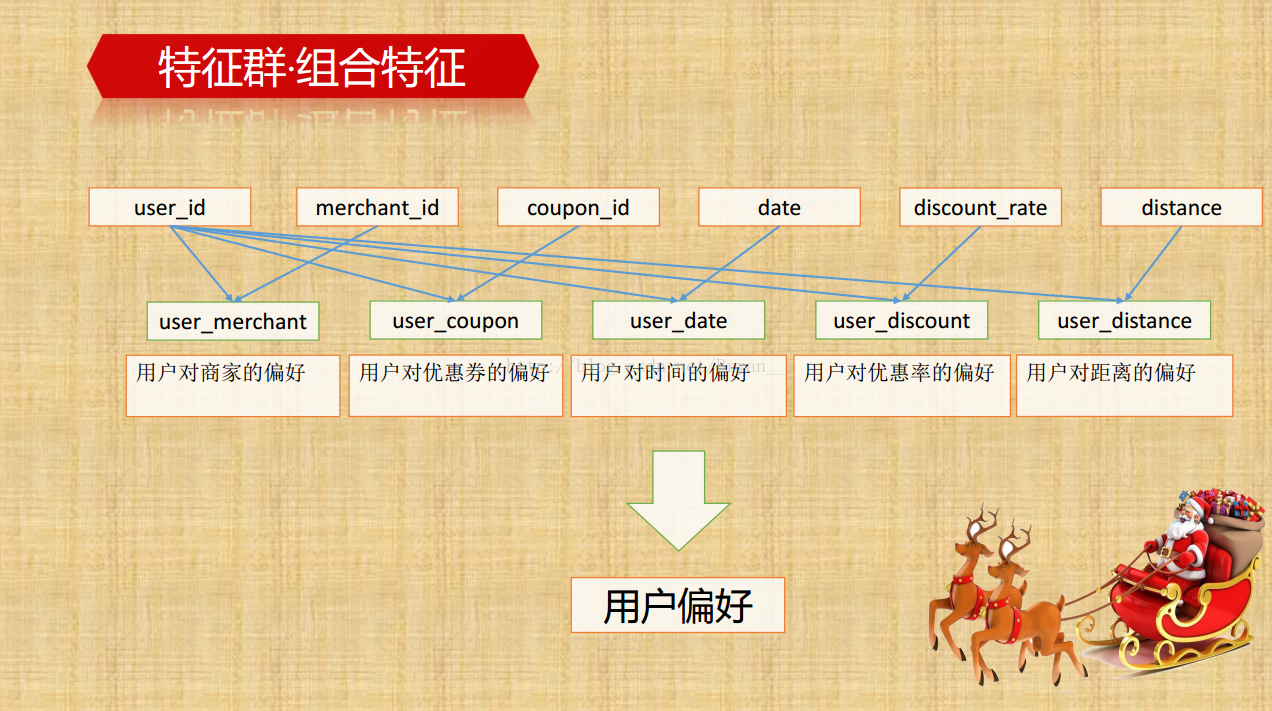
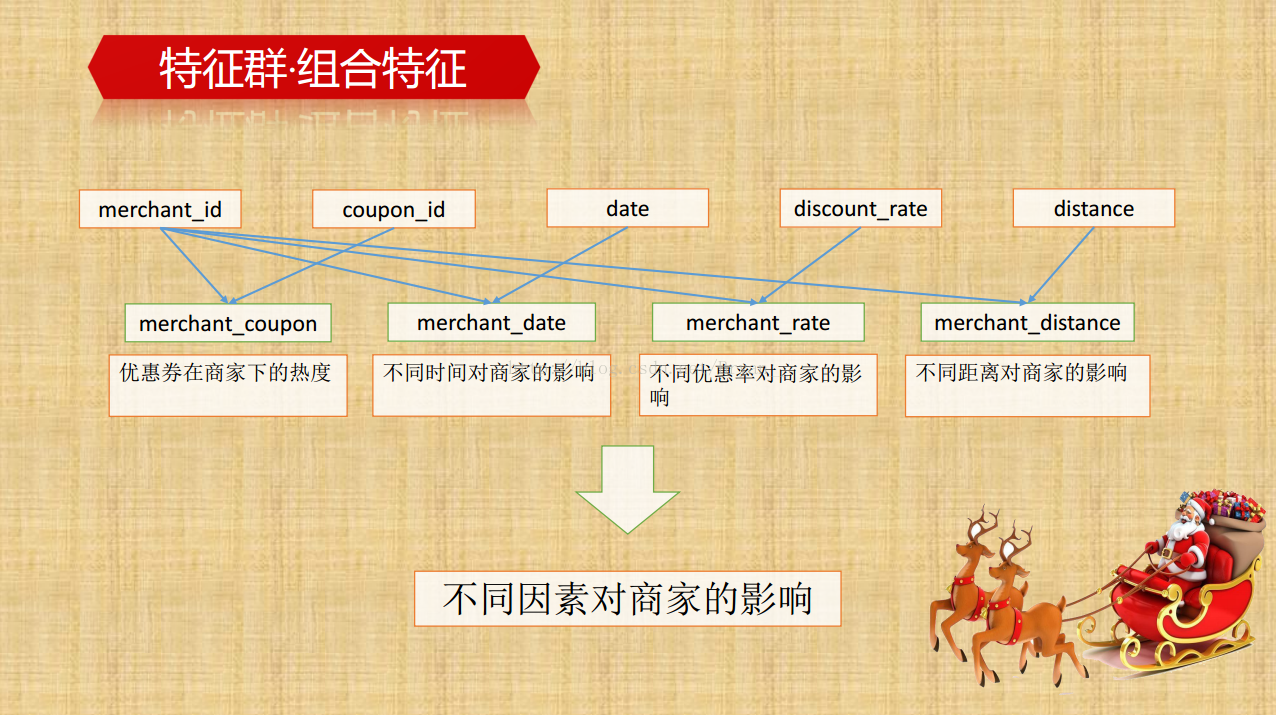
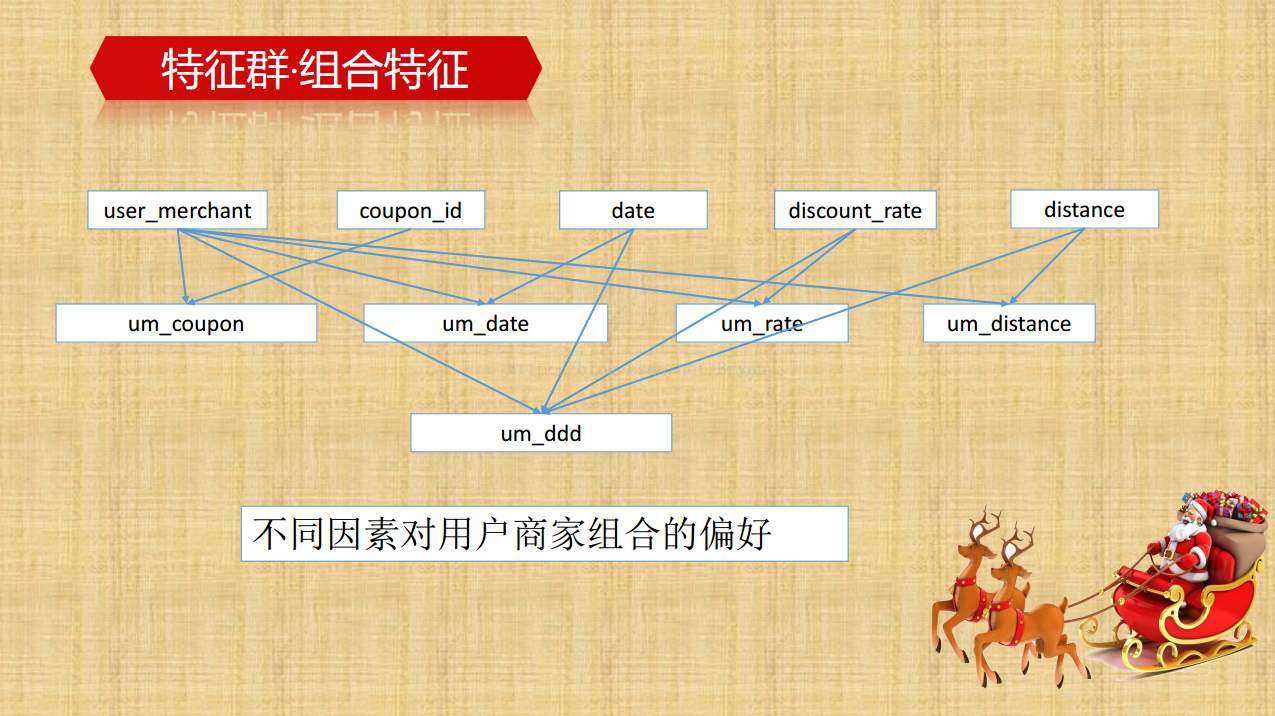
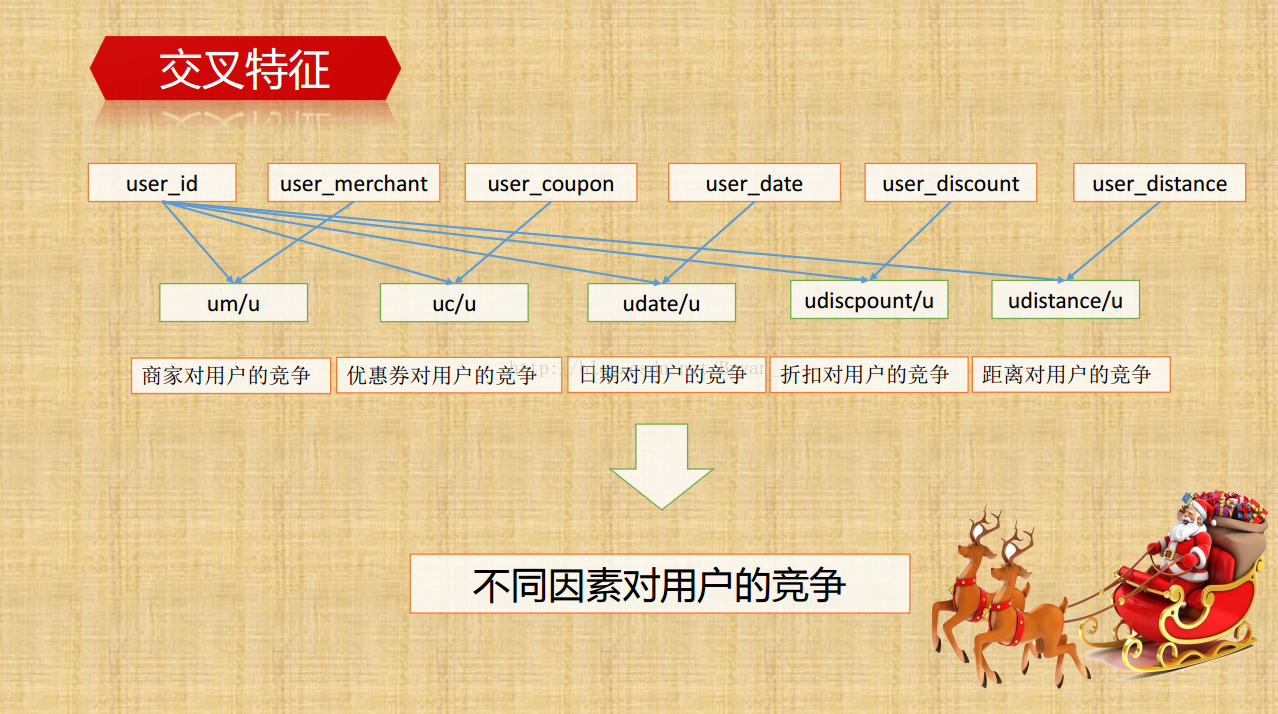
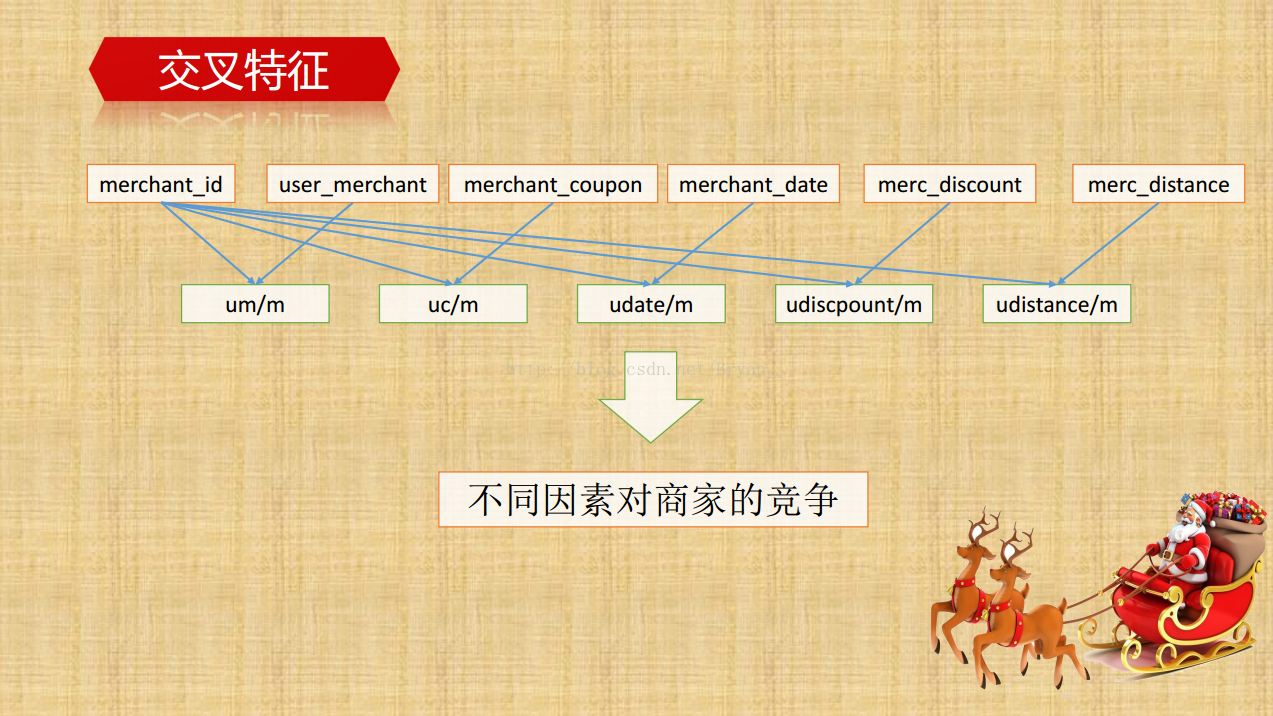
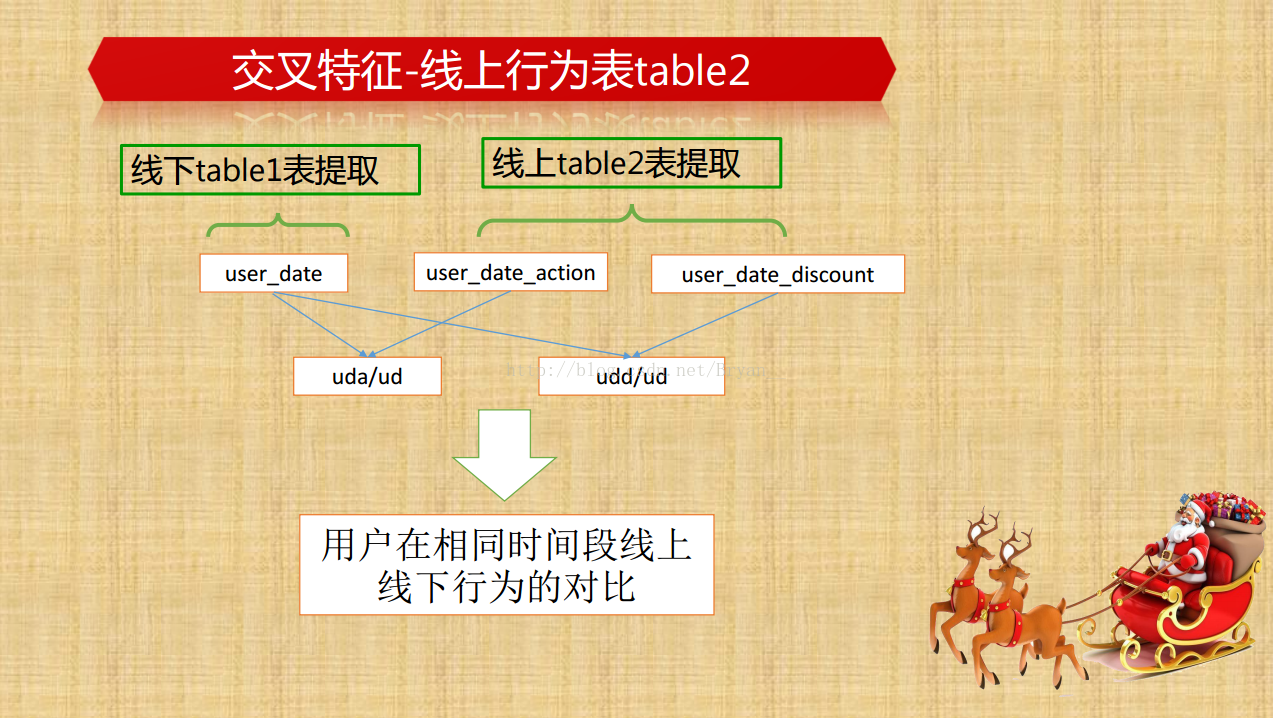
提取更多的线下/线上特征(组合特征,交叉特征):通过group by 进行深层次特征的挖掘,比如说用户侧里边,通过组合时间特征和消费情况可以得到用户的正常消费间隔,同样的能得到具体优惠券的平均消费间隔,用户领取/普通消费/优惠券消费/未消费/总消费的次数及相关的百分比等等,再深一点的比如消费率和弃用率的比例。
-
-
提取过程中也尝试了将矩阵拆分了用多进程加速并行计算【谈python的GIL机制】,发现性能的提升并不大,从提升的代码复杂度来讲不如pandas直接算好用。
-
针对线上数据的处理:
- 线上数据较多,且没有相同的商户、优惠券,所以首先做数据的筛选,将线下没有出现过的用户数据剔除掉
- 当月特征: 观察发现当用户领了某券消费后,大部分商店会在使用券的当天再发一张券,所以可以假定该用户领了该券的个数越多,用户使用的概率越大。另外如果某条记录是该用户最后一次领该券,很可能是因为这次没有使用所以没有再给该用户发券,则该记录不使用券的概率就很大
-
由于主体由树模型完成,没有进行数据的无量纲化处理和特征筛选,只是通过嵌入法,跑了一个Xgboost基模型得到特征的分数,发现最重要的特征依次为:“ 商家被领取的特定优惠券数目”,‘’领取优惠券到使用优惠券的平均间隔时间",‘用户领取优惠券平均时间间隔’,‘’weekday‘’,“不同打折优惠券使用率”,“商家被领取的优惠券数目”,其实可以发现用户对店铺的消费偏好具有惯性
-
数据量非常大,提取特征很慢时,可以参考分表的**,避免重复计算
-
temp = offline[offline.Coupon_id != 0] # 领了券的用户 coupon_consume = temp[temp.Date != date_null] # 领了券消费的 coupon_no_consume = temp[temp.Date == date_null] # 领了券没消费的 user_coupon_consume = coupon_consume.groupby('User_id')
-
最后的数据量,处理后训练集200万左右(特征提取过滤后剩下40万条),特征一百余个



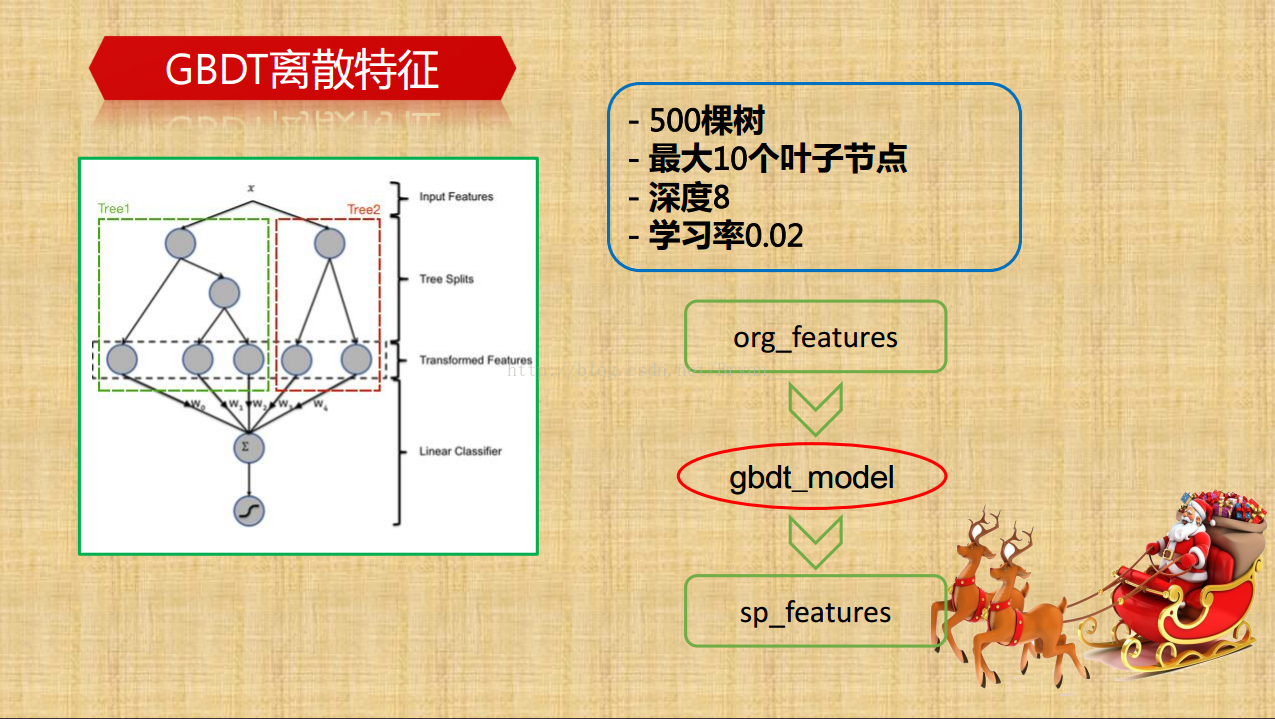
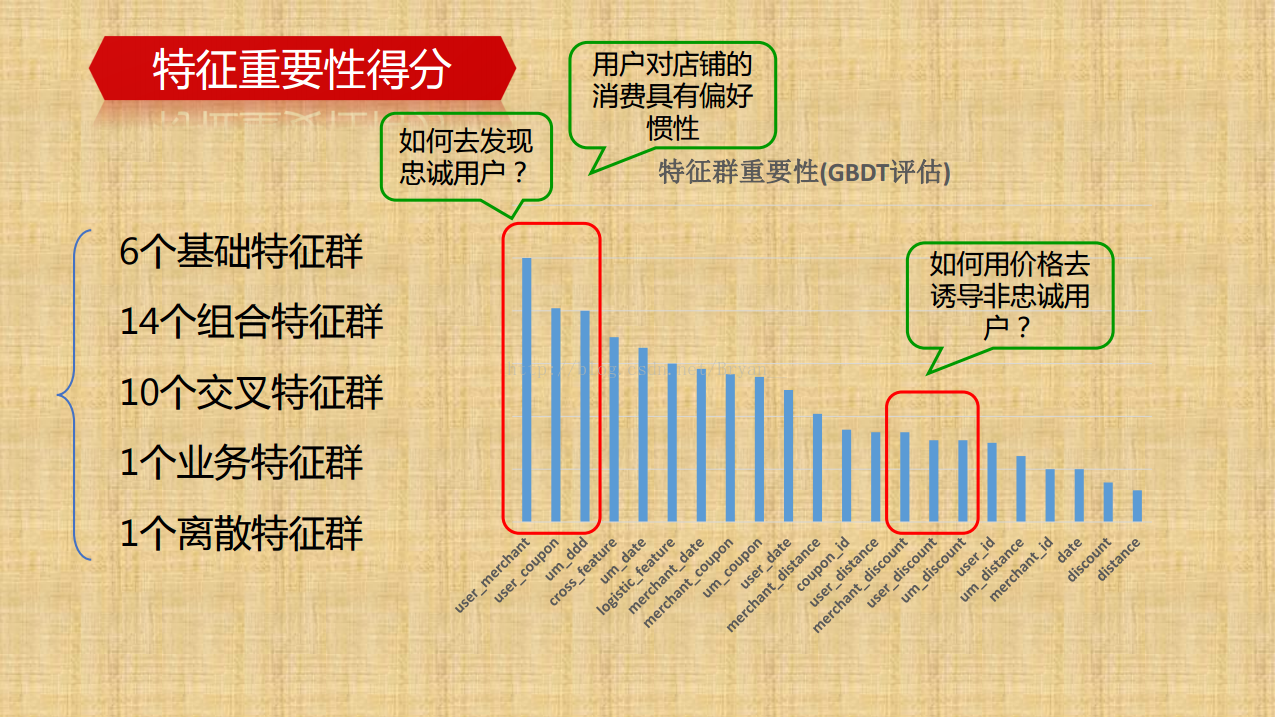
-
衡量损失的标准:优惠券侧的AUC,按优惠券id进行group,分别结算每个id对应的auc最后取平均值
-
自动化网格搜索,pipeline,三重循环:
-
最外层的while控制全局最优,任何一个参数发生了变化就要重新再调整,达到全局最优;
-
第二层for循环调整各个参数
-
最内层遍历单个参数的所有可能取值达到局部最优
-
和普通网格搜索的区别在于:普通网格只有两重循环,各个参数只达到了局部最优
-
-
用到的模型:
- 树模型: 'gbdt', 'xgb', 'lgb', 'cat','rf_gini', 'et_gini',rf_entropy.et_entropy
- FM:DeepFM + logistic
-
最后用 'gbdt', 'xgb', 'lgb', 'cat'四个模型做了两层的stacking,第二层用的logistic得到最后的预测