QATM: Quality-Aware Template Matching for Deep Learning

This is the official repo for the QATM DNN layer (CVPR2019). For method details, please refer to
@InProceedings{Cheng_2019_CVPR,
author = {Cheng, Jiaxin and Wu, Yue and AbdAlmageed, Wael and Natarajan, Premkumar},
title = {QATM: Quality-Aware Template Matching for Deep Learning},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2019}
}
Overview
What is QATM?
QATM is an algorithmic DNN layer that implements template matching idea with learnable parameters.
How does QATM work?
QATM learns the similarity scores reflecting the (soft-)repeatness of a pattern. Emprically speaking, matching a background patch in QATM will produce a much lower score than matching a foreground patch.
Below is the table of ideal matching scores:
| Matching Cases | Likelihood(s|t) | Likelihood(t|s) | QATM Score(s,t) |
|---|---|---|---|
| 1-to-1 | 1 | 1 | 1 |
| 1-to-N | 1 | 1/N | 1/N |
| M-to-1 | 1/M | 1 | 1/M |
| M-to-N | 1/M | 1/N | 1/MN |
| Not Matching | 1/||S|| | 1/||T|| | ~0 |
where
- s and t are two patterns in source and template images, respectively.
- ||S|| and ||T|| are the cardinality of patterns in source and template set.
- see more details in paper.
QATM Applications
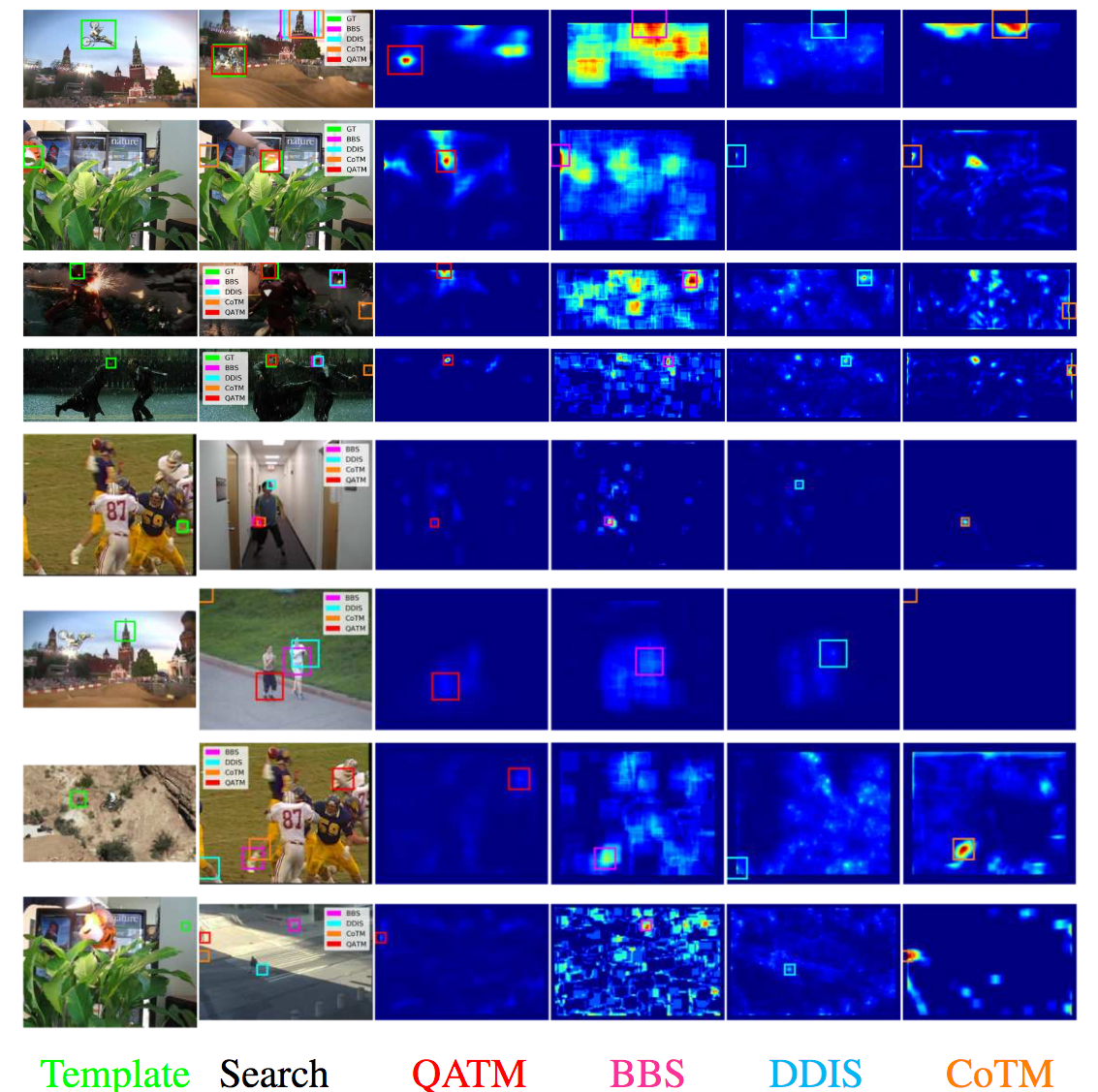
Classic Template Matching
Deep Image-to-GPS Matching (Image-to-Panorama Matching)

Deep Semantic Image Alignment

Others
See git repository https://github.com/kamata1729/QATM_pytorch.git
Dependencies
- Dependencies in our experiment, not necessary to be exactly same version but later version is preferred
- keras=2.2.4
- tensorflow=1.9.0
- opencv=4.0.0 (opencv>=3.1.0 should also works)