Recommender systems have grown to be an essential part of all large Internet retailers, driving up to 35% of Amazon sales or over 80% of the content watched on Netflix. In general good recommender systems can help increase companies sales by majority.
In this project we will be building an end to end fashion recommender system for H&M products.
This project will help you to understand standard ML cycle and will teach you how to create an E2E ML system.

The system consists of three major steps like any other ML system and we will be using various tools, so that at you can use this project as an MLOps template for any project 💙
| Process | Tools |
|---|---|
| Data Collection | BeautifulSoup, Airflow, MinIO/AWS-S3 |
| Experimentation | PyTorch, Mlflow, Dagster, scikit-learn, Onnx |
| Backend Service | BentoML, Docker |
| Frontend Service | Streamlit |
| Deployment Service | Google container Registry (GCR), Google Cloud Run |
| Testing/Formatting, etc | Github actions, pre-commit, pytest |
Below figure shows the overall steps carried out in the process.
The data is collected by scraping the H&M website using BeautifulSoup and wrote a data orchestration pipeline using Airflow, so that our data collection jobs run according to a schedule. Basically I wanted my code to run on my local system when I was asleep :), plus Airflow provides a great way to automate your process.
The key things to remember during this process is a datastore (s3-bucket), you can use any s3-bucket I used AWS S3 bucket free tier to store all the product meta-data. The total time required to collect the data was around 2 days and the resulting dataset had information of around 14k products.
The data was collected for four categories: Men, Women, Babies and Kids
The following metadata was collected (empahsis on image data as I wanted to build an image based recommender system)
- Product IDs
- Product Image links
- Product Price
- Product page links
All the code for scraping is available in src/data_collection and the code for Airflow DAGs is available in src/airflow_jobs
The overall goal is to build an image based recommender system. There are multitude ways to do it, but I choose self-supervised learning to train a model in an unsupervised fashion.
Basically, the goal is to create a good enough model that can learn good representation of images thus giving us better image embeddings
SIMCLR was used to train two models: Resnet18 and Efficient-net B3.
All the code for training is available in : src/train_models and the parameters are available in configs folder.
- All the training can be orchestrated and all the steps can be shown via a Directed Acyclic Graph (DAG).
- Thankfully there is an orchestration tool called Dagster that can let us schedule our jobs on K8s services or locally.
- Overall dagster defines few core-concepts
- For our use case we mostly use Ops which are nothing but are the core unit of computation.
- All of the experiments we run and the metrics generated during that run are logged via mlflow with a model registry hosted on AWS S3 and local Sqlite db to track parameters.
Below figure shows and dagster DAG for our training process.
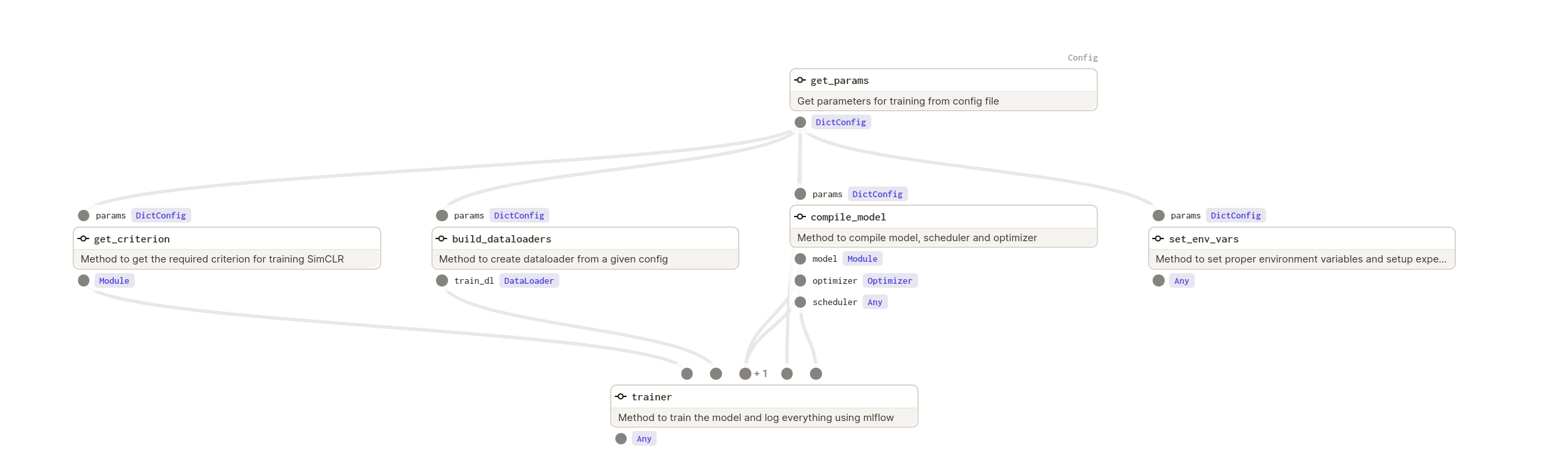
Nice talk on Dagster as an MLOps tool.
Once we the model is trained, we need to do build a backend API so that later we can deploy it to cloud. There are various tools available to do this, but one of the best one's is BentoML that provides an amazing way to package your API.
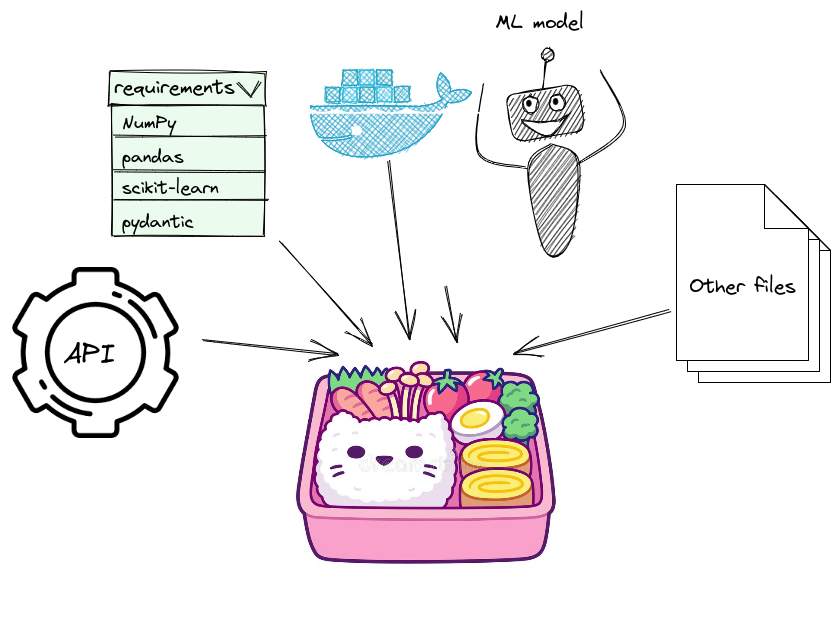
Here are the core components that go into a bento
-
Saving models using BentoML. The script is available in
src/post_training -
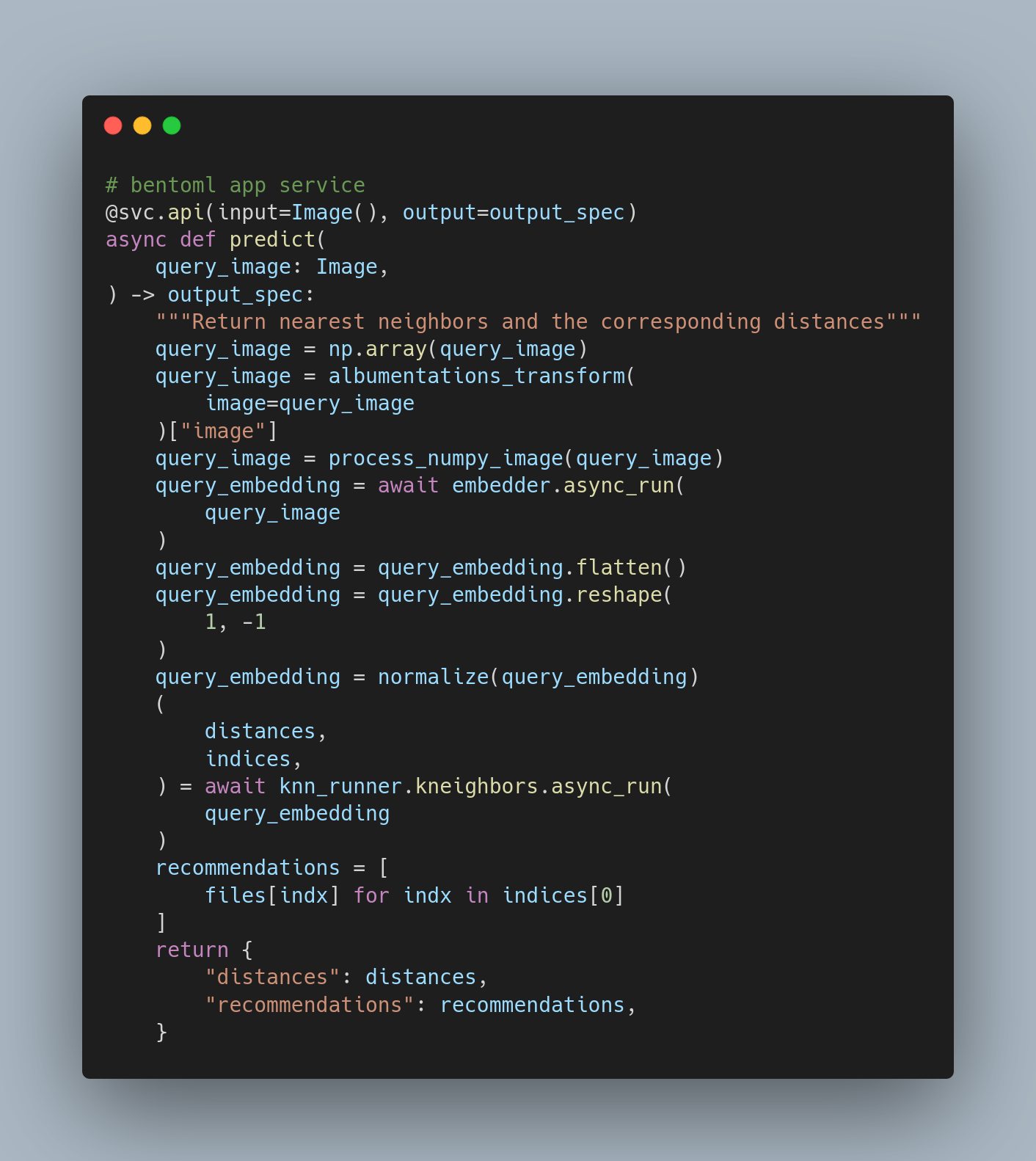
Write a bento service a.k.a the core logic of our model. Run service by following the below steps
cd src/bento_service
bentoml serve recommender_service.py:service --reload
- Define a benotfile.yaml to create a bento for the service.
bentoml build
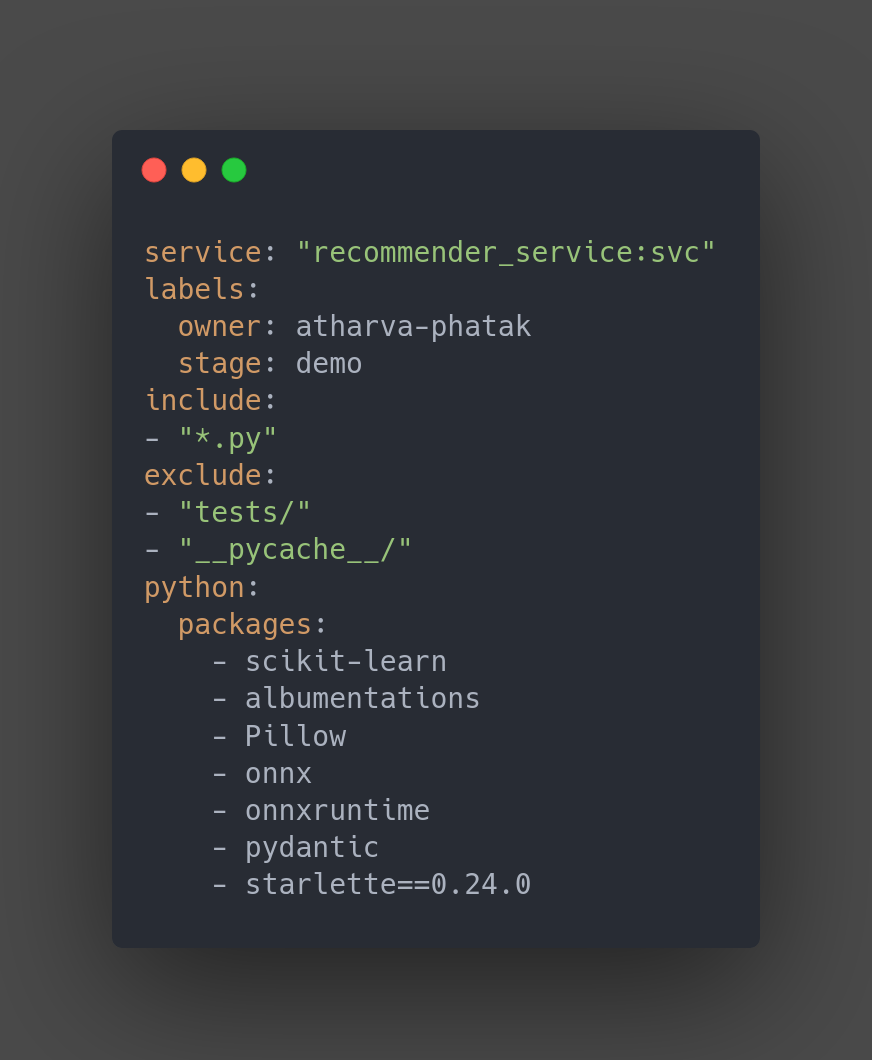
- Dockerize the bento and check if it runs locally. Bento also provides nice SwaggerUI so that you can interact with your API.
bentoml containerize fashion-recommender-service:latest
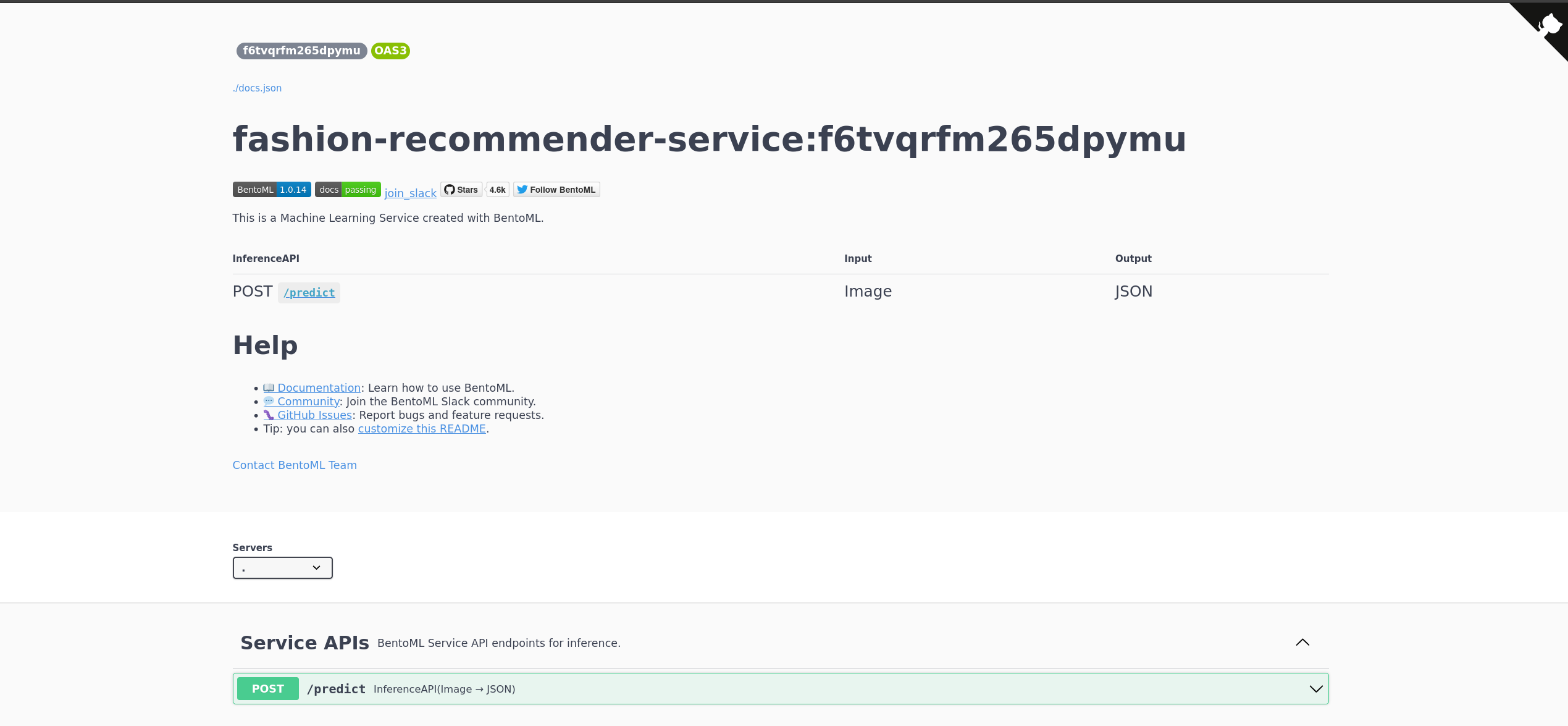
Voila our docker image is generated and you can check if its working by running
docker run -p 3000:3000 iris_classifier:latest serve --production
Kubernetes is an amazing tool to deploy your docker applications and provides amazing scaling capabilites. There are many cloud providers but I love GCP because of how easy it is to do.
-
Install gcloud sdk
-
Follow the steps to push docker image to GCR
-
Run
gcloud run <service-name> --image <name of the image in your project>

Once our backend is ready, creating a MVP application is really easy. For this projecy streamlit is used, but you can use something like ReactJS or NextJS.
Code for UI is available in src/app.py
As mentioned we used an ML orchestration tool called Dagster. One of the major advantages of Dagster over other orchedstration tools is
Dagster enables you to build testable and maintainable data applications. It provides ways to allow you unit-test your data applications, separate business logic from environments, and set explicit expectations on uncontrollable inputs.
Since our whole training process is bunch of Ops compiled together, it would make sense to write unit tests to check if every op is working or not. PyTest is the go to tool to write tests in Python.
THings like formatting/linting code, etc are important to properly format code. This can all be automated using tools like pre-commit, which basically runs a bunch of tools for formatting and other services once you push a git commit.
Note: Pre-commit is used very widely and can be customized according to need.
I am releasing the the bento services which I made using Resnet18 and Efficient-net-B3 as the models. They are available here.
Resnet18: https://hub.docker.com/r/athp456/fashion-recommender-service-resnet
Efficient-Net B3: https://hub.docker.com/r/athp456/fashion-recommender-service-effnet-b3
Here are good resources on MLops
- FSDL: https://fullstackdeeplearning.com/
- Made With ML
- O'reilly books on MLops