
Intra-Page Ranker is a tool for calculating the page rank of a website. It uses a Markov matrix to calculate the rank of each page on the website, and exports the results to a file.
-
Web crawling: The tool crawls a given domain to collect data about the pages and links on the site.
-
Page rank calculation: The tool uses a Markov matrix to calculate the page rank of each page on the site.
-
Command-line interface: The tool is run from the command line and accepts various flags to customize its behavior.
-
Exporting: The tool can export the calculated page rank data to a file in either JSON or CSV format.
-
Customizable parameters: The tool allows the user to customize various parameters, such as the maximum depth to crawl, the delay between requests, and the number of parallel requests to make.
- Clone the repository:
git clone https://github.com/Avash027/Intra-Page-Ranker.git - Install dependencies:
go get ./... - Run the project:
go run main.go
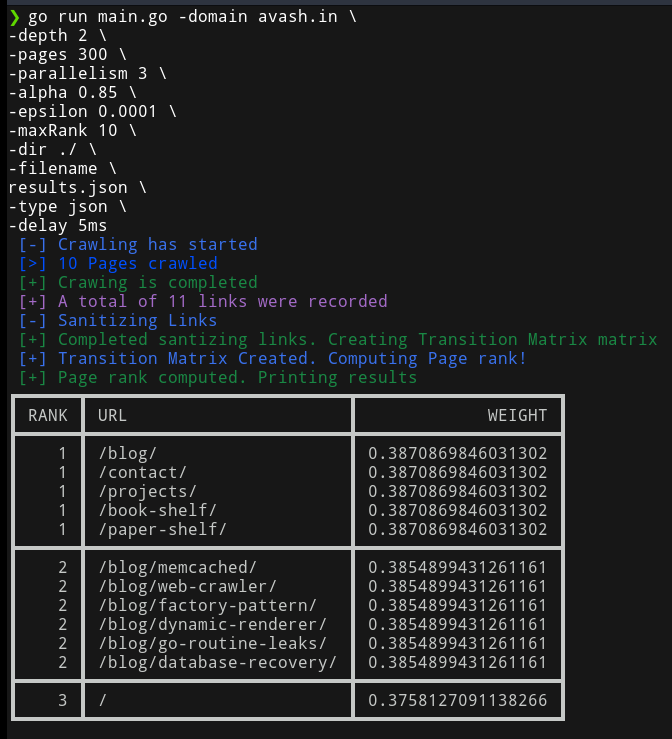
The following command line flags are available:
-domain: The domain name to crawl (default:example.com)-depth: The maximum depth to crawl (default:3)-pages: The maximum number of pages to crawl (default:100)-delay: The delay between requests (default:1s)-useragent: The user agent to use for requests (default:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36)-parallelism: The maximum number of parallel requests (default:10)-alpha: Constant used while calculating page rank (default:0.85)-epsilon: Directly proportional to accuracy of results but also consumes more time (default:0.0001)-maxRank: Max Rank upto which you want to see the result (default:10)-dir: The directory to export the data to (default:./)-filename: The name of the file to export the data to (default:results)-type: The type of exporter to use (json or csv) (default:json)
- The crawler starts from the given domain and crawls all the links on the page. It then crawls all the links on those pages, and so on until it reaches the maximum depth or maximum number of pages.
- It then maps the crawled pages to a unique integer ID, and creates a adjacency matrix of the links between the pages.
- It then create a Markov matrix from the adjacency matrix using the following rules:
- If a row of
$A$ has no 1's, then replace each element by 1/N. For all other rows proceed as follows. - Divide each 1 in
$A$ by the number of 1's in its row. Thus, if there is a row with three 1's, then each of them is replaced by$1/3$ . - Multiply the resulting matrix by
$1-\alpha$ . - Add
$\alpha/N$ to every entry of the resulting matrix, to obtain$P$ .
- If a row of
- Then it assumes the surfer starts from the first page and randomly surfs the web by clicking on links. It calculates the probability of the surfer being on each page after a large number of clicks.
- Let the vector for state 0 be
$v_0$ . - We multiply
$v_0$ with$P$ to get$v_1$ . - We keep repeating the process until difference between
$v_i$ and$v_(i-1)$ is less than$\Epsilon$
- Let the vector for state 0 be
Contributions are welcome! Please follow the Go Code Review Comments when submitting pull requests.