By Aviv Yaish and Adir Zagury
Our.best.Khet.AI.against.the.SDK.default.mp4
A nice project we did around April 2016 as a final project for the Introduction to Artificial Intelligence (67842) course.
Khet is a relatively new board game which is described as "Chess, only with lasers". It's rules are deceptively simple, but are enough to create a game that's not only enjoyable, but also quite hard - it's state and game tree complexity put it in the same league as Chess:
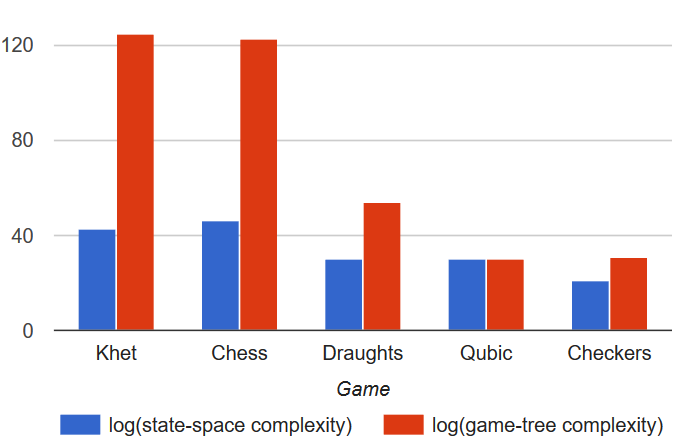
Seeing this, and that the game is "unexplored territory" AI-wise (only one academic paper on the subject!), we decided to review the success of the methods we saw in class and of our own devise in playing the game.
As Khet is an adversarial game where one's gain is the others loss, it is only natural we use an adversarial AI, alpha-beta search. We implemented two variants of this algorithm:
-
Regular alpha-beta search - an optimization of the minimax algorithm. The minimax algorithm determines the next move of a given player by going over all his possible moves and their outcome states, using a grading function to pick the move that maximizes the minimum value of the state resulting from the opponent's possible following moves. Alpha-beta pruning improves over this by pruning branches from the game tree as soon as it's apparent they can't affect the outcome of the search. The search is usually depth limited as game trees can be huge.
-
Heuristic-greedy alpha-beta search - a modification of the alpha-beta search that sorts moves based on the grading function before recursing into their branches. This allows the search to check more "promising" moves first, hopefully being able to finish the search faster. Also, giving up on the not promising moves allows the search to go deeper into the branches of the promising moves:
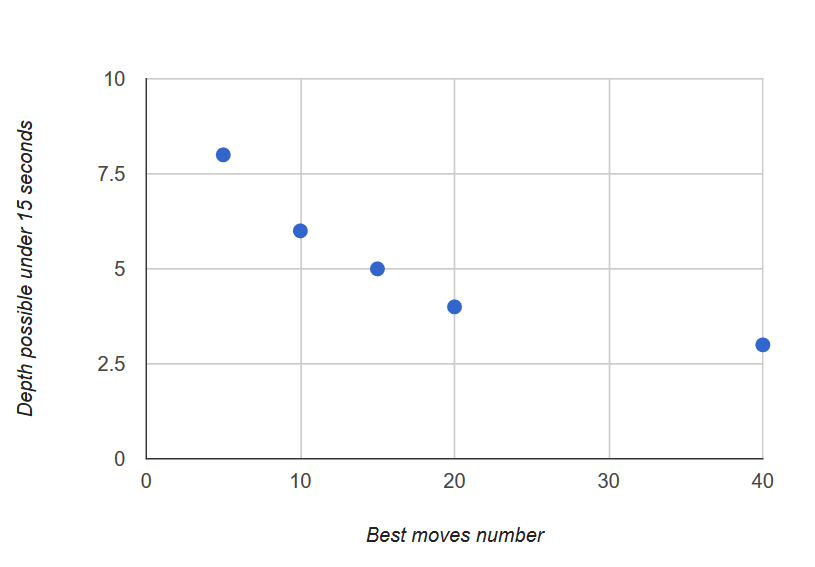 This might improve the search.
This might improve the search.
Both variants use a few heuristics we've developed to grade the states (which are the nodes of the game tree):
- Number of figures
- Number of available moves
- Number of protective figures around the Pharaoh
Note that at each state the heuristics are calculated both for the AI agent and for it's rival, and that the weights given to each is variable (the weight for the agent's number of figures might be lower than the weight it gives to it's rival number of figures, making the agent play more offensively). Also, each heuristic is raised to a certain power. If the power is a fraction lower than 1, it can cause "variable" grading - for example, giving a power of 0.5 to the number of figures of the agent, it means that losing a figure when he has a lot of figures isn't as bad as losing a figure when he has a few.
In order to optimize the weight of each heuristic, we implemented two local search algorithms:
-
Genetic algorithm - the genetic algorithm starts with a random population of grade vectors, and pits them against each other using an agent. Each grade's performance defines the probability it will get to pass it's "genes" to the next generation. This continues a predetermined number of generations.
-
Stochastic-steepest-ascent hill-climbing - this algorithm is given a a choice of a few random grade vectors, from which it picks the best (determined by pitting them against each other). Then, it chooses random neighbors for the location, and selects the best. This continues a predetermined number of steps. At the beginning, "far" neighbors are allowed to be generated, but as time goes on only closer and closer neighbors are allowed.
We ran the each of the optimization algorithms on each of the search agents, once with a high population/neighbor count but a low generation/steps count, and once with a low population/neighbor count and a high generation/steps count. We made sure that both runs would approximately take the same time, by using parameters that cause the same number of games to be played during the run. After getting the results from all runs, we pitted the resulting agents against each other, and against a grades vector we've hand tuned ourselves. For each game, each agent gets 1 point for each win, 0.5 for a draw and 0 for loosing. The results are:
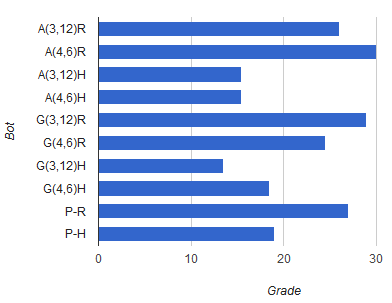
The naming scheme is X(a,b)Y, where X is the optimization algorithm, (a,b) are (kids in generation, number of generation), and Y is the game tree search algorithm used.
X can be of types:
- A: stochastic hill climbing
- G: genetic
- P: grades we hand tuned ourselves
Y can be of types:
- R: regular alpha-beta
- H: heuristic-greedy alpha-beta
Performing the optimizations takes a very long time, so we were able to make only a few runs. From the data we gathered we got:
- Regular alpha-beta is better than heuristic-greedy - either because the heuristic-greedy search misses out on moves that seem not promising at start but that turn out to be very good later on, or because our heuristics don't evaluate states well enough.
- Stochastic-steepest-ascent hill-climbing is slightly better than a genetic algorithm - both resulted with heuristic weights that gave very good results, but when a regular alpha-beta agent used the weights from the stochastic hill-climbing algorithm, it lost less.
- An offensive strategy works - analyzing the weights given by the A(4,6)R run, which produced the best agents, shows that an aggressive strategy works well - the weights encourage the agent to capture their opponent's figures while giving less weight to protecting their own.
- A computer can optimize the heuristic weights better than a human can - one optimization run by each optimization algorithm produced a better result than our hand tuned weights for the regular alpha-beta search.
- Regular alpha-beta tree search benefits from optimizing with a large generation/steps count.
- Our best agent (the white player) is much better than the default agent supplied with the SDK (the red player):
- J.A.M. Nijssen, Using intelligent search techniques to play the game Khet, 2009