| page_type | ms.custom | ms.contributors | languages | products | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
sample |
|
|
|
|
This is a template or sample for MLOps for Python based source code in Azure Databricks using MLflow without using MLflow Project.
This template provides the following features:
- A way to run Python based MLOps without using MLflow Project, but still using MLflow for managing the end-to-end machine learning lifecycle.
- Sample of machine learning source code structure along with Unit Test cases
- Sample of MLOps code structure along with Unit Test cases
- Demo setup to try on users subscription
- This demonstrates deployment scenario of Orchestrate MLOps on Azure Databricks using Databricks Notebook
- Products & Technologies:
- Azure Databricks
- Azure Blob Storage
- Azure Monitor
- Languages:
- Python


- ml_experiment - sample ML experiment notebook.
- ml_data - dummy data for sample model
- ml_ops - sample MLOps code along with Unit Test cases, orchestrator, deployment setup.
- ml_source - sample ML code along with Unit Test cases
- Makefile - for build, test in local environment
- requirements.txt - python dependencies
- Azure Databricks workspace
- Azure Data Lake Storage Gen2 account
- Visual Studio Code in local environment for development
- Docker in local environment for development
git clone https://github.com/Azure-Samples/azure-databricks-mlops-mlflow.gitcd azure-databricks-mlops-mlflow- Open cloned repository in Visual Studio Code Remote Container
- Open a terminal in Remote Container from Visual Studio Code
make installto install sample packages (taxi_faresandtaxi_fares_mlops) locallymake testto Unit Test the code locally
make distto build wheel Ml and MLOps packages (taxi_faresandtaxi_fares_mlops) locally
make databricks-deploy-codeto deploy Databricks Orchestrator Notebooks, ML and MLOps Python wheel packages. If any code changes.make databricks-deploy-jobsto deploy Databricks Jobs. If any changes in job specs.
- To trigger training, execute
make run-taxi-fares-model-training - To trigger batch scoring, execute
make run-taxi-fares-batch-scoring
NOTE: for deployment and running the Databricks environment should be created first, for creating a demo environment the Demo chapter can be followed.
Check Logs, create alerts. etc. in Application Insights. Following are the few sample Kusto Query to check logs, traces, exception, etc.
-
Check for Error, Info, Debug Logs
Kusto Query for checking general logs for a specific MLflow experiment, filtered by
mlflow_experiment_idtraces | extend mlflow_experiment_id = customDimensions.mlflow_experiment_id | where timestamp > ago(30m) | where mlflow_experiment_id == <mlflow experiment id> | limit 1000
Kusto Query for checking general logs for a specific Databricks job execution filtered by
mlflow_experiment_idandmlflow_run_idtraces | extend mlflow_run_id = customDimensions.mlflow_run_id | extend mlflow_experiment_id = customDimensions.mlflow_experiment_id | where timestamp > ago(30m) | where mlflow_experiment_id == <mlflow experiment id> | where mlflow_run_id == "<mlflow run id>" | limit 1000
-
Check for Exceptions
Kusto Query for checking exception log if any
exceptions | where timestamp > ago(30m) | limit 1000
-
Check for duration of different stages in MLOps
Sample Kusto Query for checking duration of different stages in MLOps
dependencies | where timestamp > ago(30m) | where cloud_RoleName == 'TaxiFares_Training' | limit 1000
To correlate dependencies, exceptions and traces, operation_Id can be used a filter to above Kusto Queries.
- Create Databricks workspace, a storage account (Azure Data Lake Storage Gen2) and Application Insights
- Create an Azure Account
- Deploy resources from custom ARM template
- Initialize Databricks (create cluster, base workspace, mlflow experiment, secret scope)
- Get Databricks CLI Host and Token
- Authenticate Databricks CLI
make databricks-authenticate - Execute
make databricks-init
- Create Azure Data Lake Storage Gen2 Container and upload data
- Create Azure Data Lake Storage Gen2 Container named -
taxifares - Upload as blob taxi-fares data files into Azure Data Lake Storage Gen2 container named -
taxifares
- Create Azure Data Lake Storage Gen2 Container named -
- Put secrets to Mount ADLS Gen2 Storage using Shared Access Key
- Get Azure Data Lake Storage Gen2 account name created in step 1
- Get Shared Key for Azure Data Lake Storage Gen2 account
- Execute
make databricks-secrets-putto put secret in Databricks secret scope
- Put Application Insights Key as a secret in Databricks secret scope (optional)
- Get Application Insights Key created in step 1
- Execute
make databricks-add-app-insights-keyto put secret in Databricks secret scope
- Package and deploy into Databricks (Databricks Jobs, Orchestrator Notebooks, ML and MLOps Python wheel packages)
- Execute
make deploy
- Execute
- Run Databricks Jobs
- To trigger training, execute
make run-taxifares-model-training - To trigger batch scoring, execute
make run-taxifares-batch-scoring
- To trigger training, execute
- Expected results
- Azure resources

- Databricks jobs

- Databricks mlflow experiment
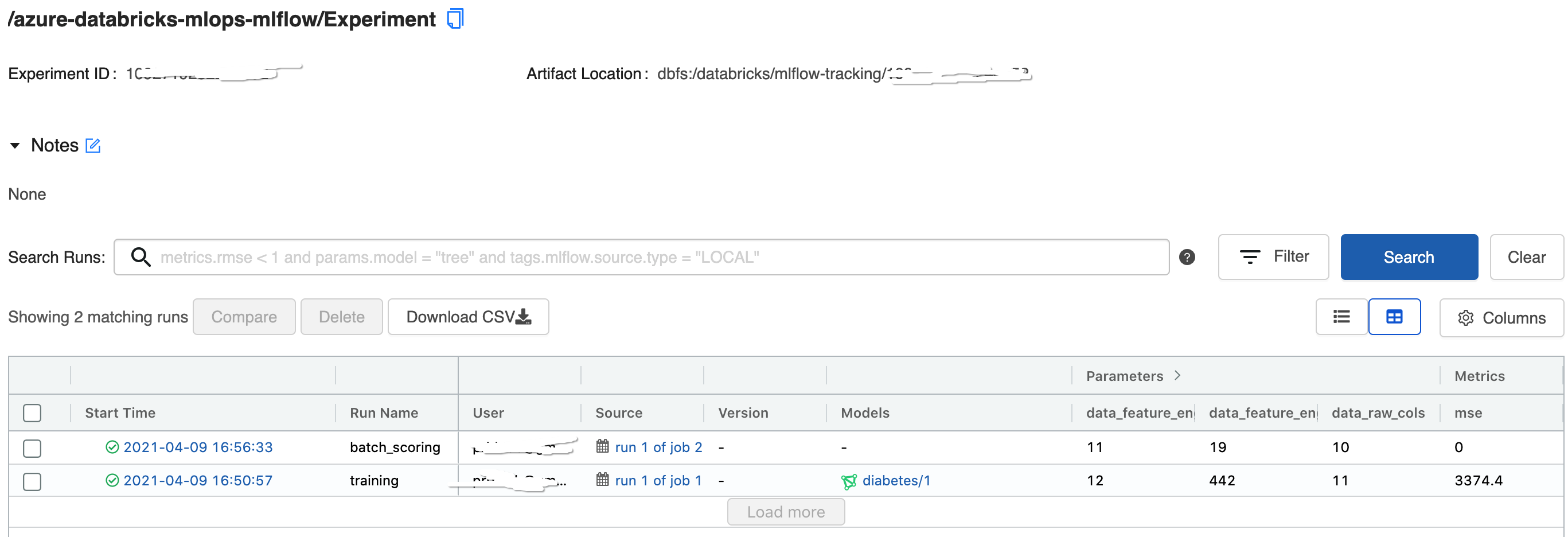
- Databricks mlflow model registry

- Output of batch scoring
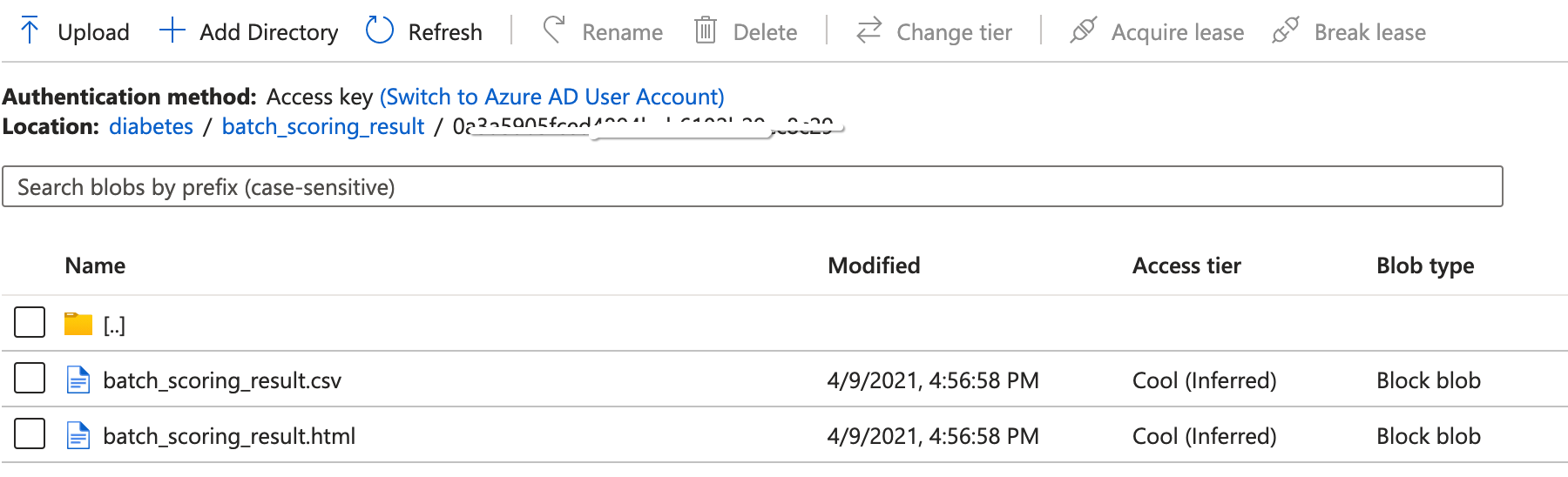
- Azure resources





- Azure Databricks
- MLflow
- MLflow Project
- Run MLflow Projects on Azure Databricks
- Databricks Widgets
- Databricks Notebook-scoped Python libraries
- Databricks CLI
- Azure Data Lake Storage Gen2
- Application Insights
- Kusto Query Language
- Application developer : It is a role that work mainly towards operationalize of machine learning.
- Data scientist : It is a role to perform the data science parts of the project