-
构建大型中文阅读预训练数据集。我们收集和爬取大量网络上开源的片段抽取式问答数据集和实体识别数据集,通过相似性匹配、掩码替换、模板生成、滑动窗口划分等方法整理获得百万级别的问答数据(包括文娱、社交、疫情、军事、医学、电商、新闻等领域)。
-
训练实现更加通用高效的机器阅读理解模型。基于RoBERTa中文语言模型训练机器阅读理解问答模型,利用语言模型强大语义建模能力,实现信息精准提取和答案精准定位。在通用领域和垂直领域,长文本和实体文本级上的效果优于现有网络开源的其他阅读理解预训练模型。
-
数据来源
-
中文MRC数据。网络收集大量比赛、研究所用的开源MRC数据集,主要类型为片段抽取任务。
-
实体级数据集。网络收集部分中文实体识别与槽值填充数据集。
-
领域数据集。结合团队项目应用,获取的特定应用领域的真实用户数据(用于微调)。
-
| 部分数据集 | 领域 | 类型 |
|---|---|---|
| 百度大规模的中文机器阅读理解数据集 DuReader | 百科 | 自由问答 |
| 中文片段抽取数据集 CMRC 2018 | 百科 | 片段抽取 |
| Squad中文翻译MRC数据集 ChineseSquad | 百科 | 片段抽取 |
| 中文法律阅读理解数据集 CJRC | 法律 | 片段抽取 |
| 开放域繁体中文机器阅读理解数据集 DRCD | 百科 | 片段抽取 |
| 金融事件抽取数据集 CCKS2020 | 金融 | 事件抽取 |
| 中文医疗信息处理挑战榜 CBLUE | 医疗 | 实体识别 |
| 搜狐新闻数据(SogouCS)-NER任务数据 | 新闻 | 实体识别 |
| 中文细粒度命名实体识别 CLUENER2020 | 百科 | 实体识别 |
| 微博命名实体识别数据集 WeiboNER | 社交 | 实体识别 |
-
数据构造方法
-
格式整理
- 参照sqaud格式定义数据格式核心为(问题-段落文本-问答组),依此调整不同格式的数据。
- 不以一个统一的JSON文件存储所有数据,而以每行一个JSON数据的形式存储在文本文件中,方便进一步调整和分段处理。
-
超长文本处理
- 部分数据中的文本、答案、问题均存在超长情况。对于answer>512和question>64的问题直接舍去。
- 对于文本超长的数据,以滑动窗口对长文本进行划分。主义保证包含答案和句子的完整性(以前后“标点符号”进行分割),包含答案的文本段落作为问答样例,其他数据可作为负样例。
-
答案区间定位
- 对于部分(不严格抽取式)数据只包含答案而不包含答案区间。通过模糊匹配在文本中寻找最相似的片段作为答案,并确定起始终止位置。
- 对于部分自由问答数据集。参照百度官方Dureader预处理构造伪答案的方法,通过遍历寻找包含答案的最优段落和答案。
-
实体级问答对生成
- 实体识别数据集结构与阅读理解数据差异较大,我们采用两种方式来构造实体数据。 1、参考MLM任务,利用实体选择进行[MASK]来构造数据样本。 2、依据实体类别构造模板,随机选择模板进行问句生成,以实体作为答案。
-
负例生成
- 负样本的一方面能提高模型泛化能力,防止过拟合,同时也是解决“能不能回答”问题的关键。基于正样本构造负样本,进一步提升了模型的理解能力、泛用性与鲁棒性。
- 针对问题question(若有title则保留),采用随机选择其他段落文本;通过BM25算法召回相似的段落文本;删除原段落文本中答案至其前后标点(尽量保留语义完整性)三种方式替换context来构造负例:
-
-
我们在各领域广泛选择数据,保证了训练数据具有代表性;通过模糊匹配寻找最相似文本片段为答案的方法,我们分别针对抽取式问答和实体类问答获取数据,保证了模型在长短文本表现更均衡;通过细致的格式整理,我们保证了来自不同领域的不同类型数据可以被统一训练;通过负例生成与训练,我们解决了“能不能回答”的问题,进一步提升了模型的理解能力、泛用性与鲁棒性。
-
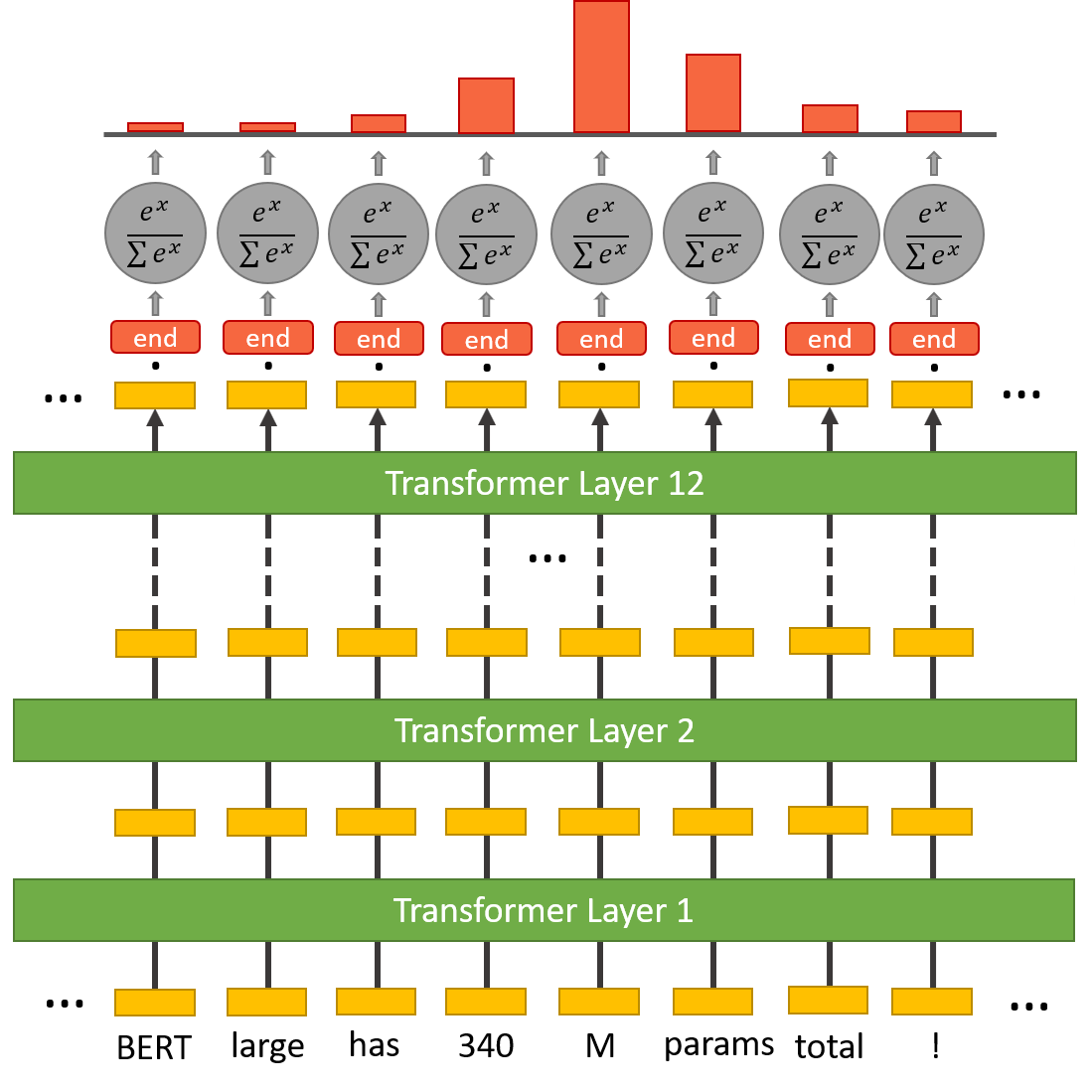
首先输入以[SEP]分割的问题与文本,利用BERT对其进行深度信息提取;
-
再输出上增加一个全连接层和非线性激活函数,训练起始词分类器和结束词分类器,两个分类器分别输出文章中每个token作为起始词/结束词的概率。
-
损失分别计算两个分类器的损失,再进行平均为整体损失。
 |
 |
项目代码已经上传,基于Hugginface上开源的中文MRC在训练代码,该代码基于谷歌官网的squad代码修改能较好的支持中文。
一、数据与缓存
由于项目数据量较大,为了减少重复数据加载,我们考虑提前进行数据处理,生成缓存文件。首先逐行读取数据文件的每个样例,得到全体example,再通过helper.py文件中的squad_convert_examples_to_features_orig函数对样本进行向量化并存储缓存。以上可通过per_cache.sh脚本一键运行。
二、训练
主程序为main_bert.py,可通过train_bert.sh一键运行。
-
重要参数:
--model_name_or_path/--config_name/--tokenizer_name:模型、配置文件、词表等文件地址--train_file/--predict_file/--test_file:训练、测试、验证集文件名--num_train_epochs:训练epoch数,与训练默认为2--learning_rate:学习率为$2e^{-5}$,优化器采用梯度集中化的AdamW_GC优化器--version_2_with_negative:是否进行无答案预测--data_start_point/--data_end_point/--data_example_span:训练 -
特别:
-
本项目采用的Roberta大型中文预训练语言模型(roberta-wwm-large),也可以采用其他中文bert与训练模型,如macbert。
-
由于数据量与计算资源所限,我们采用分段缓存和预训练的方式(如先预训练10w数据,再在此基础上继续训练新的数据)。此部分由参数data_start_point、data_start_end和data_example_span控制,默认时将不进行分段。
-
三、实验结果
| 模型/数据集 | 长文本验证集(F1-score) | 实体验证集(F1-score) |
|---|---|---|
| chinese_pretrain_mrc_roberta_wwm_ext_large | 32.08 | 20.87 |
| our model (partial data) | 45.95 | 28.57 |
| our model (all data) | 64.87 | 48.26 |
- 在大量通用领域数据上训练后,在长短文本上均由不错的表现,优于现有开源MRC模型。
- 基于预训练好的MRC模型,经过领域数据微调较好的完成相应任务,优于其他语言模型效果。
四、模型使用示例
import torch
from transformers import AutoTokenizer, AutoModelForQuestionAnswering # transformers==2.10.0
import json
model_path = "" # model path
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForQuestionAnswering.from_pretrained(model_path)
inputs = tokenizer.encode_plus(question, context, return_tensors="pt") # encode content with tokenizer
outputs = model(**inputs) # get outputs
answer_start = torch.argmax(outputs[0]) # get start point
answer_end = torch.argmax(outputs[1]) + 1 # get end point
result = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(inputs["input_ids"][0][answer_start:answer_end])) # get answer